







文章目录
差分进化算法(Differential Evolution,以下简称 DE)由Storn等人于1995年提出,其最初的设想是用于解决切比雪夫多项式问题,后来发现它也可用于求解复杂优化问题。当前,它已经成为求解 连续变量非线性全局优化问题的最有效方法之一。与遗传算法类似,DE是一种基于种群进化的元启发式算法。
PS:博主的博士课题以改进DE为主。研究过程中,走了很多弯路。以下内容,主要为这些年针对DE的相关总结。希望此文可以帮助朋友们降低了解和认识DE的准入门槛,若真如此,幸甚。若有相关问题,欢迎留言或私信讨论。
综合表现
下表列举了2005-2020年IEEE CEC 单目标参数优化竞赛的前三名优化算法。其中,2005年和2016年未针对算法进行总排名,不参与统计(用N/A表示); 2007年为多目标优化问题,不参与统计(用N/A表示);2009年和2014 年的第二名和第三名算法,未在网站上公布,表中也未列出(用N/A表示)。

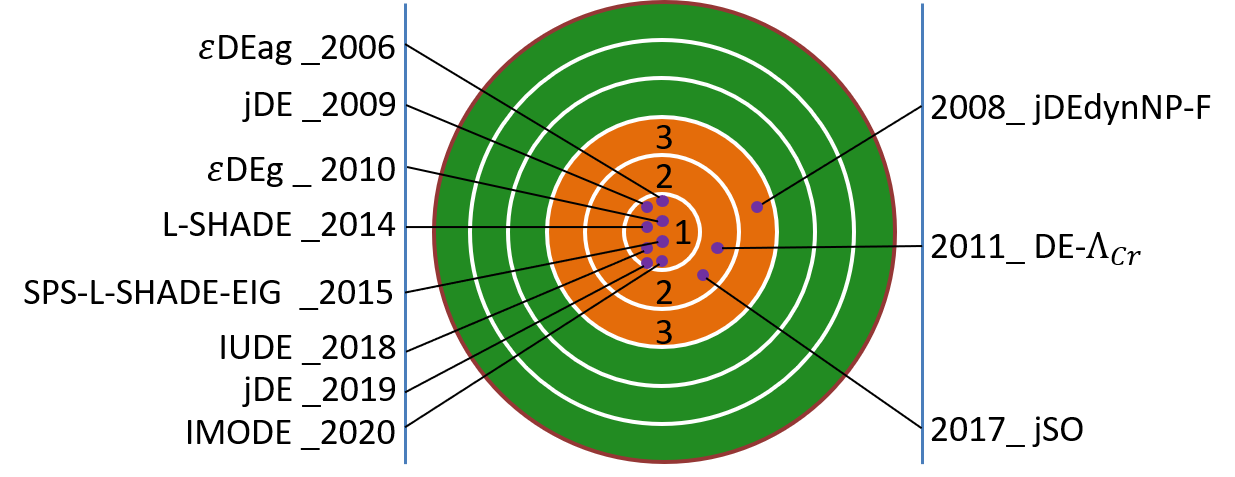
上表中的DE算法和改进DE算法用黑体标注。从表中可以看出,DE在求解标准测试算例时,具有较为明显的优势。下图汇总了DE在各届IEEE CEC竞赛中的最优排名及其对应的改进DE。除了2013年排名第4外(图中未标出),DE在其他所有年份的排名都位列前三。在2006和2009等7个年份中,DE取得了第一名的成绩。在最近三年的竞赛中,即2018年、2019年和2020年,DE依然保持着领先的地位。
流程概述
设定优化问题如下:优化变量为
x
\bm x
x,变量维度为
D
D
D,表示为
x
=
(
x
1
,
x
2
,
.
.
.
,
x
D
)
{{\bm{x}}}=\left( {{x}^{1}},{{x}^{2}},...,{{x}^{D}} \right)
x=(x1,x2,...,xD)
x
\bm x
x的上界
x
m
a
x
\bm x_{\rm{max}}
xmax和下界
x
m
i
n
\bm x_{\rm{min}}
xmin分别定义为
{
x
min
=
(
x
min
1
,
x
min
2
,
.
.
.
,
x
min
D
)
x
max
=
(
x
max
1
,
x
max
2
,
.
.
.
,
x
max
D
)
\left\{\begin{array}{l} {{\bm{x}}_{\min }}=\left( x_{\min }^{1},x_{\min }^{2},...,x_{\min }^{D} \right) \\ {{\bm{x}}_{\max }}=\left( x_{\max }^{1},x_{\max }^{2},...,x_{\max }^{D} \right) \\ \end{array}\right.
{xmin=(xmin1,xmin2,...,xminD)xmax=(xmax1,xmax2,...,xmaxD)
目标函数为最小化某一性能指标
min
f
(
x
)
\min \;f\left( {\bm{x}} \right)
minf(x)
针对以上的最小化问题,经典DE在求解过程中,一般包含4个步骤:初始化(Initialization)、变异(Mutation)、交叉(Crossover)和选择(Selection)。
初始化
DE的种群可以表示为
x
i
=
(
x
i
1
,
x
i
2
,
.
.
.
,
x
i
D
)
,
i
=
1
,
2
,
.
.
.
,
N
P
{{\bm{x}}_i} = \left( {x_i^1,x_i^2,...,x_i^D} \right), i=1,2,...,NP
xi=(xi1,xi2,...,xiD),i=1,2,...,NP
其中,
N
P
NP
NP是种群大小。
初始化第
i
i
i个个体
x
i
,
1
x_{i,1}
xi,1的常用方法为
x
i
,
1
j
=
x
min
j
+
r
a
n
d
(
0
,
1
)
⋅
(
x
max
j
−
x
min
j
)
,
j
=
1
,
2
,
.
.
.
,
D
x_{i,1}^{j}=x_{\min }^{j}+\mathrm{rand}\left( 0,1 \right)\cdot \left( x_{\max }^{j}-x_{\min }^{j} \right),j=1,2,...,D
xi,1j=xminj+rand(0,1)⋅(xmaxj−xminj),j=1,2,...,D
其中,
r
a
n
d
(
0
,
1
)
\rm{rand}(0,1)
rand(0,1)是0~1之间的均匀随机数。
变异
定义
x
i
,
G
\bm x_{i,G}
xi,G为第
i
i
i代种群的第
G
G
G个个体。
x
i
,
G
\bm x_{i,G}
xi,G通过以下的变异算子生成与之对应的变异向量
v
i
,
G
\bm v_{i,G}
vi,G
v
i
,
G
=
x
r
1
i
,
G
+
F
⋅
(
x
r
2
i
,
G
−
x
r
3
i
,
G
)
{{\bm{v}}_{i,G}}={{\bm{x}}_{r_{1}^{i},G}}+F\cdot \left( {{\bm{x}}_{r_{2}^{i},G}}-{{\bm{x}}_{r_{3}^{i},G}} \right)
vi,G=xr1i,G+F⋅(xr2i,G−xr3i,G)
其中,下标 r 1 i r_1^i r1i、 r 2 i r_2^i r2i 和 r 3 i r_3^i r3i是随机产生的整数值,范围是1~ N P NP NP,它们的数值互不相同,并且均不等于 i i i。对于每个变异向量,这些下标都只随机产生一次。此处, x i , G \bm x_{i,G} xi,G被称为 v i , G \bm v_{i,G} vi,G对应的目标向量, x r 1 i , G \bm{x}_{r_{1}^{i},G} xr1i,G为基向量, x r 2 i , G − x r 3 i , G {{\bm{x}}_{r_{2}^{i},G}}-{{\bm{x}}_{r_{3}^{i},G}} xr2i,G−xr3i,G是差分向量, F F F是缩放因子,范围是0~1。
交叉
交叉算子如下所示,其作用是通过组合
x
i
,
G
\bm x_{i,G}
xi,G和
v
i
,
G
\bm v_{i,G}
vi,G产生对应的试验向量
u
i
,
G
\bm u_{i,G}
ui,G
u
i
,
G
j
=
{
v
i
,
G
j
,
if
(
j
=
j
rand
)
or
(
r
i
j
≤
C
r
)
x
i
,
G
j
,
otherwise
u_{i,G}^{j}=\left\{ \begin{array}{l} v_{i,G}^{j},~~\text{if}\left( j={{j}_{\text{rand}}} \right)\text{or}\left(r_i^j\le Cr \right) \\ x_{i,G}^{j},~~\text{otherwise} \\ \end{array}\right.
ui,Gj={vi,Gj, if(j=jrand)or(rij≤Cr)xi,Gj, otherwise其中,
j
rand
{j}_{\text{rand}}
jrand是1~
D
D
D之间的随机整数,
r
i
j
=
r
a
n
d
(
0
,
1
)
r_i^j=\mathrm{rand}(0,1)
rij=rand(0,1) ,
C
r
Cr
Cr是交叉概率,范围是0~1。该方式下,至少存在1维变量从
v
i
,
G
\bm v_{i,G}
vi,G到
u
i
,
G
\bm u_{i,G}
ui,G。下图为生成试验向量
u
i
,
G
\bm u_{i,G}
ui,G的示意图。

选择
生成
u
i
,
G
\bm u_{i,G}
ui,G后,计算和比较
u
i
,
G
\bm u_{i,G}
ui,G和
x
i
,
G
\bm x_{i,G}
xi,G对应的目标函数,目标函数较小的对应向量可以保留到下一代
x
i
,
G
+
1
=
{
u
i
,
G
,
f
(
u
i
,
G
)
≤
f
(
x
i
,
G
)
x
i
,
G
,
otherwise
{{\bm{x}}_{i,G+1}}=\left\{ \begin{array}{l} {{\bm{u}}_{i,G}},f\left( {{\bm{u}}_{i,G}} \right)\le f\left( {{\bm{x}}_{i,G}} \right) \\ {{\bm{x}}_{i,G}},\ \text{otherwise} \\ \end{array} \right.
xi,G+1={ui,G,f(ui,G)≤f(xi,G)xi,G, otherwise
算法特点
相比其他元启发式算法,DE的主要特点在于它使用差分向量来指导当前种群的进化方向。为了直观地展示差分向量(变异向量)的变化特点,本节结合经典DE求解2维Schwefel函数的优化实例,进行详细描述。
下图为2维Schwefel函数的3-D曲面图,其中
x
x
x和
y
y
y的范围均为-500~500。从图上可知,该函数中除了全局最优解外,还包含数量众多的局部最优解。

接下来,使用刚刚介绍的经典DE进行求解。设置种群大小
N
P
=
30
NP=30
NP=30,缩放因子
F
=
0.5
F=0.5
F=0.5,交叉概率
C
r
=
0.1
Cr=0.1
Cr=0.1。下图记录了不同代数时的变异向量末端点的所有可能位置。在初始化种群后,虽然种群大小
N
P
NP
NP仅为30,但是变异向量几乎可以覆盖所有的搜索空间。此时,个体差异较大, DE可以在较大范围内进行搜索,因此这个阶段的全局探索能力较强;12代时,优化过程逐渐摒弃中心位置,向边界附近搜索;19代时,搜索范围聚集到4个角落;23代时,优化区间已经减至2个小范围;25代时,只剩下一个搜索区域。此时,个体间差异也变小,局部开发能力更强,在40代时,基本收敛。因此,在优化过程中,差分向量可以利用个体差异的变化,自适应地调整DE的全局探索和局部开发能力,从而保证DE具有非常好的综合优化性能。

算法改进
经典DE虽然为求解全局优化问题提供了一种可行的途径,但是它还存在一些不足,比如易陷入局部最优、出现早熟收敛或搜索停滞等现象。为了提升DE的全局优化性能,许多学者致力于改进DE的相关工作。总的来说,改进DE的方法可以分别或同时从以下4个方面入手,包括:变异算子、种群大小 N P NP NP、缩放因子 F F F和交叉概率 C r Cr Cr。
变异算子
为了区分不同类型的变异算子,一般使用“DE/x/y”对其简述。其中,
x
x
x表示基向量,
y
y
y表示差分向量。经典DE中的变异算子通常被标记为DE/rand/1。此后,学者们又提出了DE/best/1、DE/rand/2、DE/best/2和DE/current-to-
p
p
pbest/1等变异算子。当前,DE/current-to-
p
p
pbest/1变异算子是各种改进DE的最常用算子之一,其表达式如下
v
i
,
G
=
x
i
,
G
+
F
i
(
x
best
,
G
p
−
x
i
,
G
)
+
F
i
(
x
r
1
,
G
−
x
~
r
2
,
G
)
\boldsymbol{v}_{i, G}=\boldsymbol{x}_{i, G}+F_{i}\left(\boldsymbol{x}_{\text {best }, G}^{p}-\boldsymbol{x}_{i, G}\right)+F_{i}\left(\boldsymbol{x}_{r 1, G}-\tilde{\boldsymbol{x}}_{r 2, G}\right)
vi,G=xi,G+Fi(xbest ,Gp−xi,G)+Fi(xr1,G−x~r2,G)式中,
x
best
,
G
p
\boldsymbol{x}_{\text {best }, G}^{p}
xbest ,Gp为第
G
G
G代种群前
N
P
∗
p
NP*p
NP∗p个最好的个体,
p
p
p的范围是0~1 。
x
r
1
,
G
\boldsymbol{x}_{r 1, G}
xr1,G为从1~
N
P
NP
NP范围内随机选取的个体,
x
~
r
2
,
G
\tilde{\boldsymbol{x}}_{r 2, G}
x~r2,G为从1~
N
P
NP
NP与A(Archive)组成的集合中随机选取的个体,
i
i
i、
r
1
r1
r1和
r
2
r2
r2互不相等。A中保存的是历史迭代过程中目标函数较差的个体。在优化开始阶段,A和第一代的种群相同;此后,逐渐向A中增加目标函数较差个体的数量;当A 中个体数量超过最大值时,将从中随机删除部分个体,并添加进新个体。下图为DE/current-to-
p
p
pbest/1变异算子下,生成试验向量的示意图, 差分向量1为
x
best
,
G
p
−
x
i
,
G
\boldsymbol{x}_{\text {best }, G}^{p}-\boldsymbol{x}_{i, G}
xbest ,Gp−xi,G,差分向量2为
x
r
1
,
G
−
x
~
r
2
,
G
\boldsymbol{x}_{r 1, G}-\tilde{\boldsymbol{x}}_{r 2, G}
xr1,G−x~r2,G。

种群数量 N P NP NP
种群设置的方式主要包含2种,固定值和自适应方式。在固定值中,通常认为种群数 N P NP NP设置为变量个数5~10倍为宜;2006年,自适应的 N P NP NP设计技术首次被证明有利于提升DE的优化性能,2014年,L-SHADE(DE的改进算法)在IEEE CEC 2014 测试算例上的优化表现排名第一,它更直接地证明了自适应种群设计技术的显著优势。该算法使用的是线性减少种群大小 N P NP NP值的方法。此后陆续又提出了其他的自适应调整 N P NP NP值的方式,如基于小生境(Niching-based)的 N P NP NP减少方法等。
缩放因子 F F F和变异率 C r Cr Cr
设计缩放因子 F F F的方式可以分为四类:固定值、随机值、基于历史自适应和基于目标函数自适应。固定值指的是缩放因子 F F F在整个优化过程中,都保持不变。一般认为, F F F取0.5,0.6或0.9为宜。随机值指的是每一代缩放因 F F F的值通过随机函数来确定。在研究过程中,均匀分布函数和正态分布函数是最常用的两种方式。
历史自适应缩放因子
F
F
F的核心是借鉴以往迭代成功的缩放因子
F
F
F值,作为设定当前缩放因子
F
F
F值的参考基准。下图(a)给出了历史自适应缩放因子
F
F
F设计的示意图。该方法广泛应用于各种自适应DE算法,SHADE是其中最为典型的算法。目标函数自适应缩放因子
F
F
F是指利用当前种群的目标函数来确定当前的缩放因子
F
F
F。下图 (b)给出了目标函数自适应缩放因子
F
F
F设计的示意图。

交叉概率
C
r
Cr
Cr的设计方式与缩放因子
F
F
F类似,本文不再赘述。
改进DE排名
下图依据全局寻优能力的的区别,绘制了25种不同DE算法之间的相互关系 。各类改进DE从下到上,全局寻优能力逐渐提升。每两条红色虚线区间内的DE认为其全局寻优性能类似。DE之间的箭头指向表示来源关系,例如EsDEr-NR是JADEw的改进版。

发展方向
超参数改进
在DE算法中,超参数主要是指缩放因子 F F F、交叉概率 C r Cr Cr和 N P NP NP。针对 F F F和 C r Cr Cr的改进策略最近几年以历史自适应为主,如果不能从基本策略上有新的自适应设计,难以再有突破。博主针对该问题曾有部分新的想法,可惜不过限于时间约束,没能仔细研究透彻,略有可惜。
N P NP NP的改进设计具有通用性,可以用于DE的 N P NP NP自适应方案理论上也可以用于其他智能优化算法。如果能有技术突破,也是非常有价值的。
变异算子改进
DE的核心在于变异算子。不同的变异算子,具有不同的特点。现在还有很多学者去尝试提出新的变异算子。不过更有前途的,博主认为是去融合不同类型的变异算子。IMODE(IEEE CEC 2020冠军)是其中的一个典型代表。相信未来几年,这将成为DE的研究热点之一。
某种意义上,变异算子可以认为是不同智能优化算法融合的另一种体现。举个例子,DE/current-to- p p pbest/1的来源之一是粒子群算法。所以,强行想从概念上去融合DE与其他智能优化算法,不如直接去研究融合多个变异算子,更加有意义。
应用范围扩展
针对连续变量非线性全局优化问题,DE当前几乎可以判定为当之无愧的Number 1了。但是在其他问题类型上的综合表现,是否具有统治地位,并不明朗。一个显然的实例,针对组合优化问题,DE的全局搜索能力并不亮眼。大规模优化问题和多目标优化问题是近几年的热点优化问题,DE的表现,就有待各位大佬去探索了。














 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









