







1 引言
在上一篇文章(运筹从业者也需要的因果推断入门:基础概念解析和体系化方法理解)中,已经对因果推断有了一个大致的认知,接下来该逐个深入学习了。
我打算从非试验场景中的潜在因果框架开始。
选择这个作为深入学习的起点,一方面是因为,我目前的工作中亟需这方面的内容来做一些因果效应的量化评估;另一方面是,我已经比较熟悉试验场景里的随机对照实验和双重差分法,所以现在学习潜在因果框架的话,应该不会有什么问题。
不过我发现自己有点飘了,写啥都想写的全面一些。这不,原想把潜在因果框架的基础理论、算法实现、模型评估和业务应用等内容都聚集到一篇文章里来,结果在各种地方卡壳,导致一个月了还是零产出。
所以说,学习还是要一步一个脚印呐。今天这篇文章,就先把潜在因果框架的基础知识搞明白,具体的算法实现等内容后续再逐一学习和总结。
2 框架描述
2.1 问题定义
潜在因果框架(Potential Outcome Framework,POF)是由Donald Bruce Rubin提出的一种针对观测数据进行因果推断的框架,也被称为Rubin因果模型。
举个简单的例子:有10名患者服用了药物,最终8名患者康复,2名患者未康复;另有10名患者没有服用药物,最终5名患者康复,5名患者未康复。我们的目标是:如何从已有的这些数据中探查出,药物是否能有效治疗患者。
有些人可能会说,这很简单呀,服用药物的康复率是80%,未服用药物的康复率是50%,药物提升了30%的康复率,所以是有效的。乍一看没啥问题,实际上这个结论经不起推敲:假如服用药物的10名患者的患病程度比较浅,而未服用药物的患者的患病程度比较深,那么这30%的康复率的提升就不一定是药物带来的,而有可能是患病程度的差异导致的。
潜在因果框架要做的事情就是:用一种科学和令人信服的方式,从已有的观测数据中得到量化的因果效应值。
为了能更一般化地描述问题,首先做出如下设定:
样本数据集为: D = { d 1 , d 2 , . . . , d n } D=\{d_1,d_2,...,d_n\} D={d1,d2,...,dn}, n n n为样本数量;策略变量为 t ∈ { 0 , 1 } t\in \{0, 1\} t∈{0,1}, t = 0 t=0 t=0表示不施加策略, t = 1 t=1 t=1表示施加策略;协变量 X X X,一般指与策略无关的变量;结果变量 Y Y Y: Y 0 i Y_{0i} Y0i表示无策略时第 i i i个样本的结果变量, Y 1 i Y_{1i} Y1i表示有策略时第 i i i个样本的结果变量。
那么在潜在因果框架下,问题可以简述为:基于数据集 D = { t i , X i , Y i } i n D=\{t_i,X_i,Y_i\}_i^n D={ti,Xi,Yi}in,估计 t t t和 Y Y Y之间的因果效应。
2.2 数学表达式
为了给出因果效应的数学表达式,还需要引入一些定义:
个体因果效应(Individual Treatment Effect,ITE)
I
T
E
i
=
Y
1
i
−
Y
0
i
ITE_i=Y_{1i}-Y_{0i}
ITEi=Y1i−Y0i
平均因果效应(Average Treatment Effect,ATE)
A
T
E
=
E
(
Y
1
−
Y
0
)
ATE=E(Y_1-Y_0)
ATE=E(Y1−Y0)
策略组平均因果效应(Average Treatment effect on the Treated group,ATT)
A
T
T
=
E
(
Y
1
∣
t
=
1
)
−
E
(
Y
0
∣
t
=
1
)
ATT=E(Y_1|t=1)-E(Y_0|t=1)
ATT=E(Y1∣t=1)−E(Y0∣t=1)
对照组平均因果效应(Average Treatment effect on the Untreated group,ATU)
A
T
U
=
E
(
Y
1
∣
t
=
0
)
−
E
(
Y
0
∣
t
=
0
)
ATU=E(Y_1|t=0)-E(Y_0|t=0)
ATU=E(Y1∣t=0)−E(Y0∣t=0)
条件平均因果效应(Conditional Average Treatment Effect,CATE)
C
A
T
E
=
E
(
Y
1
∣
X
=
x
)
−
E
(
Y
0
∣
X
=
x
)
CATE=E(Y_1|X=x)-E(Y_0|X=x)
CATE=E(Y1∣X=x)−E(Y0∣X=x)
为了更清楚地理解这些概念,我们举个例子说明一下。

如上表所示,对于表中的实例,个体因果效应为表的最后一列,平均因果效应为
A
T
E
=
1
20
∑
i
=
1
20
[
Y
1
,
i
−
Y
0
,
i
]
ATE=\frac{1}{20}\sum_{i=1}^{20}[Y_{1,i}-Y_{0,i}]
ATE=201i=1∑20[Y1,i−Y0,i]
策略组平均因果效应为
A
T
T
=
1
10
∑
i
=
1
10
[
Y
1
,
i
−
Y
0
,
i
]
ATT=\frac{1}{10}\sum_{i=1}^{10}[Y_{1,i}-Y_{0,i}]
ATT=101i=1∑10[Y1,i−Y0,i]
对照组平均因果效应为
A
T
U
=
1
10
∑
i
=
11
20
[
Y
1
,
i
−
Y
0
,
i
]
ATU=\frac{1}{10}\sum_{i=11}^{20}[Y_{1,i}-Y_{0,i}]
ATU=101i=11∑20[Y1,i−Y0,i]
样本编号为偶数的平均因果效应为
C
A
T
E
=
1
10
∑
i
=
1
10
[
Y
1
,
2
i
−
Y
0
,
2
i
]
CATE=\frac{1}{10}\sum_{i=1}^{10}[Y_{1,2i}-Y_{0,2i}]
CATE=101i=1∑10[Y1,2i−Y0,2i]
严格定义下,我们要确定的是ATE的值;但在大多数情况下,我们计算的是ATT,并以此来代替ATE。
看起来,只要上表中的数据是完整的,因果效应的评估问题就完美解决了。但遗憾的是,针对任何样本,总有部分数据是无法观测到的:如果
t
=
1
t=1
t=1,即样本施加了策略变量,那么就只能观测到
Y
1
Y_1
Y1,此时上表的第4列是缺失的;如果
t
=
0
t=0
t=0,则样本未施加策略变量,那么就只能观测到
Y
0
Y_0
Y0,此时上表的第3列是缺失的。因此,无论是ATE、ATT、ATU、CATE还是ITE,都无法直接计算得到。
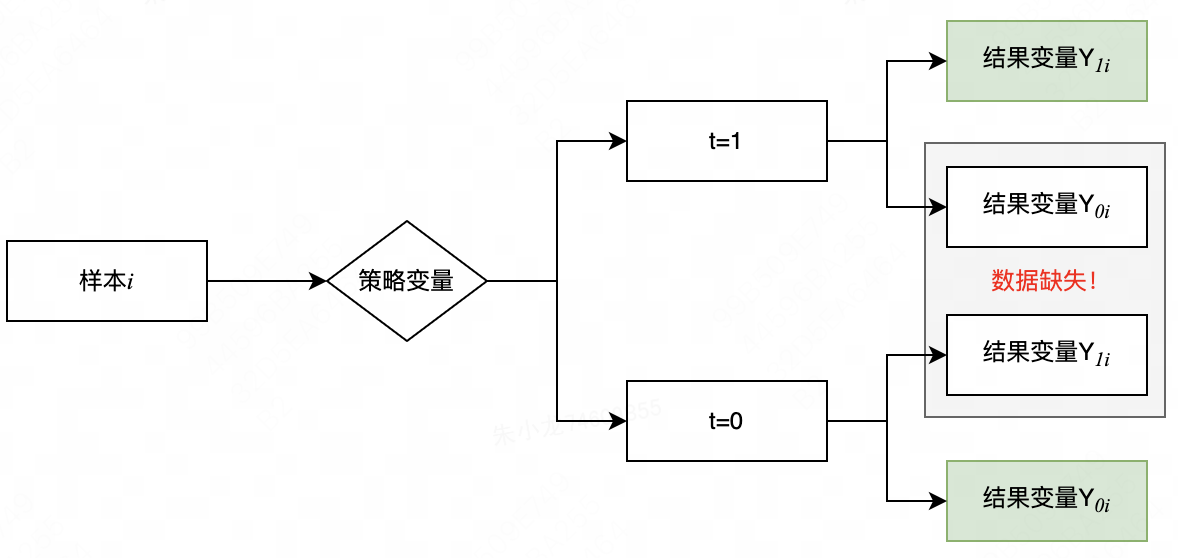
事实上,正因为有部分数据无法被观测,才需要“潜在结果”这次词。潜在因果框架认为,任何一个样本和一个策略变量,都存在一个潜在结果;进一步说,可以被观测到的结果为事实结果,无法被观测到的为反事实结果。
3 实现方案
3.1 随机实验数据
既然注定了会存在反事实结果,那么如果简单粗暴地使用 t = 0 t=0 t=0时的 Y 0 Y_0 Y0来替代 t = 1 t=1 t=1时的 Y 0 Y_0 Y0,以此计算ATT,会出现什么情况呢?
为了解答这个问题,我们进行如下的公式推导:
A
T
T
=
E
(
Y
1
∣
t
=
1
)
−
E
(
Y
0
∣
t
=
0
)
=
[
E
(
Y
1
∣
t
=
1
)
−
E
(
Y
0
∣
t
=
1
)
]
+
[
E
(
Y
0
∣
t
=
1
)
−
E
(
Y
0
∣
t
=
0
)
]
ATT=E(Y_1|t=1) - E(Y_0|t=0) = [E(Y_1|t=1) - E(Y_0|t=1)] + [E(Y_0|t=1) - E(Y_0|t=0)]
ATT=E(Y1∣t=1)−E(Y0∣t=0)=[E(Y1∣t=1)−E(Y0∣t=1)]+[E(Y0∣t=1)−E(Y0∣t=0)]
前一项显然就是ATT的真值,而后一项可以理解为策略组和对照组间的选择偏差。即,如果在构造策略组和对照组时,两者之间已经有偏差,那么替代计算的结果确实是不合理的;但如果他们之间无偏差,那么替代计算的结果就是没问题的。
而随机实验,其实就是后者。
在随机实验中,一般会随机的将样本个体分成两组:一组为策略组,施加策略变量;另一组为对照组,不施加策略变量。
也就是说,样本是否被施加策略变量,不受任何因素影响,自然独立于
Y
0
Y_0
Y0,因此以下公式成立
E
(
Y
0
∣
t
=
1
)
=
E
(
Y
0
∣
t
=
0
)
=
E
(
Y
0
)
E(Y_{0}|t=1)=E(Y_{0}|t=0)=E(Y_{0})
E(Y0∣t=1)=E(Y0∣t=0)=E(Y0)
即,选择偏差为0。
因此如果已有数据是随机实验的数据,那么真实的因果效应就是:
E
(
Y
1
∣
t
=
1
)
−
E
(
Y
0
∣
t
=
0
)
E(Y_1|t=1) - E(Y_0|t=0)
E(Y1∣t=1)−E(Y0∣t=0)
。
3.2 一般数据
如果已有数据不是随机实验的数据,那么直接替代计算就会多出一项选择偏差。为了减少或去掉选择偏差,还需要研究其他的解决方案。
目前大部分的解决方案中, 都暗含了三个假设:
假设1:稳定性假设。任意个体的潜在结果不受其他个体接受的策略所影响,同时策略对个体的潜在结果是稳定的。
假设2:可忽略假设。除协变量 X X X的影响外,策略的分配与其潜在结果是无关的,即 t ⊥ Y ∣ X t\perp\!Y|X t⊥Y∣X。
假设3:正值假设。对于任意个体,任何策略的分配概率大于0,即 p ( t ∣ X = x ) > 0 , ∀ t , x p(t|X=x)>0, \forall t,x p(t∣X=x)>0,∀t,x。
在这些假设下,常用的解决方案有:重加权方法;分层方法;匹配方法;基于树的方法;基于表征的方法;多任务方法;元学习方法等。这些方案的含义、代表性算法以及它们之间的联系,目前我还处于一知半解的状态,暂且罗列在这里,后续再花时间去学习和总结。
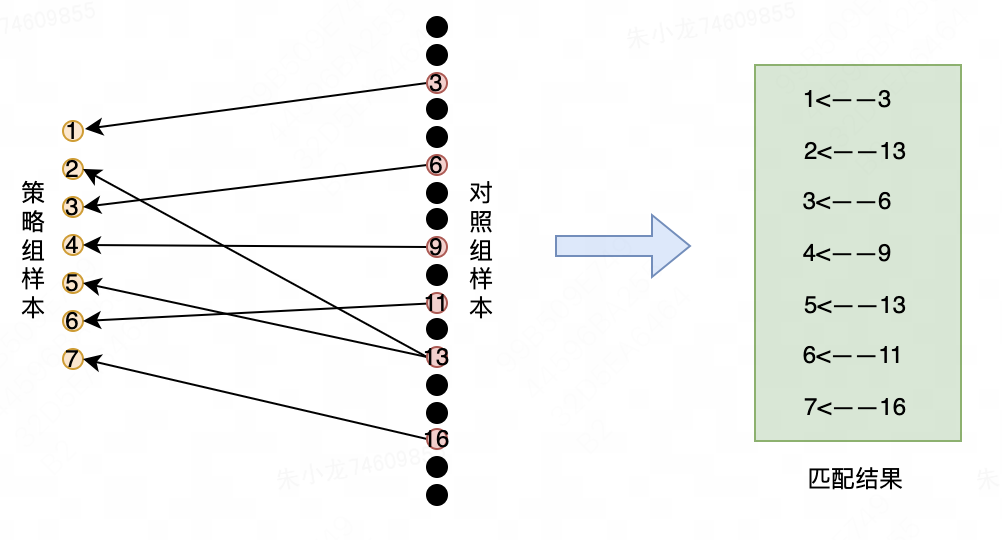
为了能对这些解决方案有个直观的理解,这里给出匹配方法的基本原理:简单来说,就是在对照组样本中,为策略组的每个样本都挑选出一个样本,该样本和策略组样本的相似度越高,便越能有效降低策略组和对照组之间的选择偏差。下图是一个匹配方案的实例。
4 方案评估
方案实现后,还需要评估方案的效果。
在机器学习领域,测试集中的每个样本都存在真值,因此可以逐一计算样本真值和模型预测值之间的偏差,然后评估算法好坏。但在因果推断中,由于反事实结果的存在,在测试集中不可能存在因果效应的真值,也就无法直接使用机器学习领域中的相关指标,还需要构建一些新的评估指标。
目前比较常用的一个指标是AUUC(Area Under Uplift Curve),本节参考causalml工具包中(一个开源的因果推断工具包)的计算逻辑大致描述AUUC如何计算。
首先根据预估的因果效应值从大到小对数据集D排序,此时第
k
k
k个样本的uplift值
u
(
k
)
u(k)
u(k)定义为
u
(
k
)
=
R
T
(
D
,
k
)
N
T
(
D
,
k
)
−
R
C
(
D
,
k
)
N
C
(
D
,
k
)
u(k)=\frac{R^T(D,k)}{N^T(D,k)}-\frac{R^C(D,k)}{N^C(D,k)}
u(k)=NT(D,k)RT(D,k)−NC(D,k)RC(D,k)
其中,
R
T
R^T
RT和
R
C
R^C
RC分别为前
k
k
k个样本中策略组和对照组的结果变量之和;
N
T
N^T
NT和
N
C
N^C
NC分别为前
k
k
k个样本中策略组和对照组的样本数量。显然,
u
(
k
)
u(k)
u(k)可以理解为:前
k
k
k个样本中策略组的平均结果变量值-前
k
k
k个样本中对照组的平均结果变量值。
有了
u
(
k
)
u(k)
u(k)后,AUUC的计算表达式为
A
U
U
C
=
∑
k
=
1
n
[
u
(
k
)
⋅
k
]
n
⋅
n
⋅
u
(
n
)
AUUC=\frac{\sum_{k=1}^n[u(k)·k]}{n·n·u(n)}
AUUC=n⋅n⋅u(n)∑k=1n[u(k)⋅k]
这个公式也需要解释一下:分子不是我们常规理解上的uplift曲线下的面积,而是累积uplift值(多了一项
k
k
k);分母是为了做归一化,
n
⋅
u
(
n
)
n·u(n)
n⋅u(n)表征的是全量样本的因果效应累积值,在此基础上还有另一个
n
n
n是因为分子是累积值。
5 总结
文章正文到此就结束了,本节总结一下三个比较重要的内容:
-
潜在因果框架下,因果推断问题可以简述为:基于数据集 D = { t i , X i , Y i } i n D=\{t_i,X_i,Y_i\}_i^n D={ti,Xi,Yi}in,估计 t t t和 Y Y Y之间的因果效应。
-
由于存在反事实结果,ATE无法通过观测数据直接计算得到;如果是随机实验的数据结果,可以通过数据替代计算得到;如果是一般数据,则还需要其他算法辅助得到。
-
AUUC可以用来衡量因果模型的好坏。
6 相关阅读
因果推断(三): 潜在结果模型:https://zhuanlan.zhihu.com/p/494643196
基于潜在结果框架的因果推断入门(上):https://cloud.tencent.com/developer/article/1823149
弹性模型的评测指标AUUC:https://zhuanlan.zhihu.com/p/457689388
倾向得分匹配1/PSM/简介、鲁宾因果模型:https://www.bilibili.com/video/BV168411W77c/?spm_id_from=333.788&vd_source=f416a5e7c4817e8efccf51f2c8a2c704
赵永贺等编著.因果推断:原理解析与应用实践[M], 北京: 电子工业出版社, 2023:https://weread.qq.com/web/bookDetail/813326f0813ab873fg015d1a















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









