






1.前置知识
1.1 python中的@
函数定义的上一行有@functionName的修饰,当解释器读到@这样的修饰符之后,会先解析@后的内容,把@下一行的函数或者类的返回作为@后边的函数的参数
按照自下而上的顺序把各自的函数结果作为下一个函数(上面的函数)的输入
def funcA(A):
print("in func A")
def funcB(B):
print(B)
print("in func B")
@funcA
@funcB
def func(c):
print("in func C")
return c**2
func(2) #进行函数调用输出结果如下:
in func C
4
in func B
in func A
整个程序的执行过程就是funA(funB(funC))
1.2 TORCH.JIT
JIT/Just In Time Compilation/即时编译
示例:在 Python 中使用正则表达式
prog = re.compile(pattern)
result = prog.match(string)或
result = re.match(pattern, string)两种写法从结果上来说是「等价」的。但注意第一种写法中,会先对正则表达式进行 compile,然后再进行使用。在Python 的文档中有建议:如果多次使用到某一个正则表达式,则建议先对其进行 compile,然后再通过 compile 之后得到的对象来做正则匹配。而这个 compile 的过程,就可以理解为 JIT(即时编译)。
在PyTorch中,TorchScript 是 Python 和 C++ 的桥梁,实现 JIT 。我们可以使用 Python 训练模型,然后将模型(torch.nn.Module)转换为 TorchScript Module,从而让 C++ 可以非常方便得调用,从此「使用 Python 训练模型,使用 C++ 将模型部署到生产环境」对 PyTorch 来说成为了一件很容易的事。而因为使用了 C++,我们现在几乎可以把 PyTorch 模型部署到任意平台和设备上:树莓派、iOS、Android 等等…
1.3 *args和kwargs
*args表示的是arguments,**kwargs表示的是keyword arguments。
*args在当传入的参数个数未知,且不需要知道参数名称时使用;
**kwargs当传入的参数个数未知,但需要知道参数的名称时使用。
def test(one, *args):
print("first element is %s" %one)
print("in args:",type(args))
for i in args:
print("%s" %i)
>>>test(1,2,3,4,5)
first element is 1
in args: <class 'tuple'>
2
3
4
5第一个参数one是必须传入的形参,而后面的四个参数作为可变参数传入到了函数中,并赋值为*args。
*args返回一个对象,这个对象是一个元组。
def test_kw(one, *args, **kwargs):
print("first element is %s" %one)
print("in kwargs:",type(kwargs))
for k,v in kwargs.items():
print("%s:%s" %(k,v))
>>>test(1,2,3,k1=4,k2=5)
first element is 1
in args: <class 'dict'>
k1:4
k2:5第一个参数one是必须传入的形参,2和3被作为可变参数传入到了函数中,并赋值为*args,4和5作为位置参数传递给了k1和k2。
**kwargs返回一个对象,这个对象是一个字典。
2. Message Passing 基类
图神经网络message passing的数学公式:
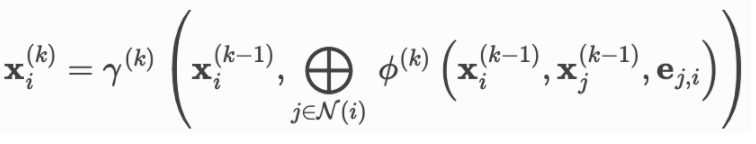
运行逻辑是:
在forward() 函数中调用 propagate() 函数
propagate() 函数内置自动调用 message()、aggregate() 和 update() 函数。
MessagePassing.propagate(edge_index, size=None, **kwargs)
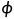 对应message() 方法,可考虑重写,源码中是直接返回输入的。
对应message() 方法,可考虑重写,源码中是直接返回输入的。
对应aggregate() 方法,这里可选sum, mean or max。
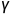 对应update()方法,可考虑重写,源码中是直接返回输入的。
对应update()方法,可考虑重写,源码中是直接返回输入的。
如果想重写聚合,或者某些场景下message() 和aggregate()可一起进行使运行更高效,可重写message_and_aggregate()函数,程序会自动检查,如果重写了,会调用message_and_aggregate(),而不是先后调用message() 和message() 。
3. GCN层的简单示例
数学公式:
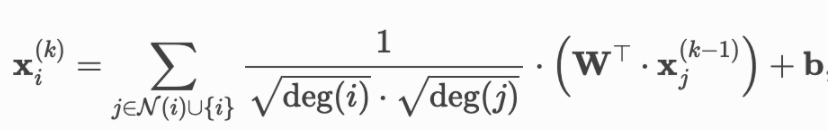
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add') # "Add" aggregation
self.lin = torch.nn.Linear(in_channels, out_channels)
#需要学习的权重矩阵,尺寸是l-1层的维度 X l层的维度
def forward(self, x, egde_index):
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
x = self.lin(x) #Linearly transform node feature matrix
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
#尺寸为[num_edges, ],num_edges是加上了自连边以后的
return self.propagrate(edge_index, x=x, norm=norm) #显式调用propagrate
def message(self, x_j, norm):
#x_j尺寸为E X out_channels,即每个边的source_node节点特征
return norm.view(-1, 1) * x_j
#把norm拉成[E,1]尺寸,这两个矩阵就broadcastable了,就可以进行乘法运算了
#对每个边,norm与x_j逐元素相乘。结果的尺寸是[E,out_channels]message()、aggregate() 和 update() 函数都会使用传入到propagate()中的参数。
源码中调用message:out = self.message(**msg_kwargs)。
对传入 propagate() 的Tensor(如 x),可以通过在变量名后分别加 _i 和 _j 来将其映射到不同的节点组上(如 x_i 和 x_j)。一般 i -指聚合信息的中心节点,j 指邻居节点,如公式所用。
_i 和 _j的映射在__collect__()函数中实现,默认flow是'source_to_target'。
参考:
https://www.jianshu.com/p/71489d0aa18b
https://blog.csdn.net/zbzckaiA/article/details/122494980
https://blog.csdn.net/PolarisRisingWar/article/details/118545695















 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









