






参考:
Slurm installation and upgrading — Niflheim 2.0 documentation
0.环境准备
Ubuntu22.04 2机4卡4090节点,IP为192.168.1.250/251,其中250作为控制节点,250/251作为计算节点,安装CUDA、conda及创建相应的环境,保证不同主机的环境一致,为了方便后期验证GPU调用。所有命令均在root权限执行。
(1)设置主机名:
250:hostnamectl set-hostname node1
251:hostnamectl set-hostname node2
![]()
(2) 编辑/etc/hosts,添加以下两行:
192.168.1.250 node1
192.168.1.251 node2
(3)关闭防火墙(ufw, firewalld,iptables),保证后续端口访问的可用性,也可以根据后续服务使用的端口(6817,6818等)添加规则:
systemctl stop firewalld ufw iptables
systemctl disable firewalld ufw iptables
systemctl status firewalld ufw iptables
确保相应的服务处于关闭(inactivate)状态
(4)修改资源限制:
在/etc/security/limits.conf添加两行:

(5)同步所有节点的时钟:
timedatectl set-timezone Asia/Shanghai(6)250配置root用户所有节点的免密访问:
ssh-keygen
ssh-copy-id -i .ssh/id_rsa.pub node1
ssh-copy-id -i .ssh/id_rsa.pub node2
完成以上操作后,在250验证免密访问:
ssh root@node1
ssh root@node2
(7)创建munge及slurm用户:
因为munge安装后会自动创建munge用户,为了避免不同节点munge用户的uid、gid不一致,所以提前创建用户,所有机电需要执行,ID保持一致
#创建munge用户
export MUNGE_USER_ID=2000
groupadd -g $MUNGE_USER_ID munge
useradd -m -c “MUNGE User” -d /var/lib/munge -u $MUNGE_USER_ID -g munge -s /sbin/nologin munge
#创建slurm用户
export SLURM_USER_ID=2001
groupadd -g $SLURM_USER_ID slurm
useradd -m -c “SLURM workload manager” -d /var/lib/slurm -u $SLURM_USER_ID -g slurm -s /bin/bash slurm
1、安装munge
(1)源码编译安装
$ git clone https://github.com/dun/munge.git
$ cd munge
$ ./bootstrap
$ ./configure \
--prefix=/usr \
--sysconfdir=/etc \
--localstatedir=/var \
--runstatedir=/run
$ make
$ make check
$ sudo make install(2)控制节点生成密钥并修改权限:
dd if=/dev/urandom bs=1 count=1024 > /etc/munge/munge.key chown munge: /etc/munge/munge.key chmod 400 /etc/munge/munge.key
(3)密钥发送至计算结点并修改权限:
scp /etc/munge/munge.key root@node2:/etc/munge
chown -R munge: /etc/munge/ /var/log/munge/ chmod 0700 /etc/munge/ /var/log/munge/ (4)所有节点启动munge服务:
systemctl enable munge systemctl restart munge
systemctl status munge
确保不报错
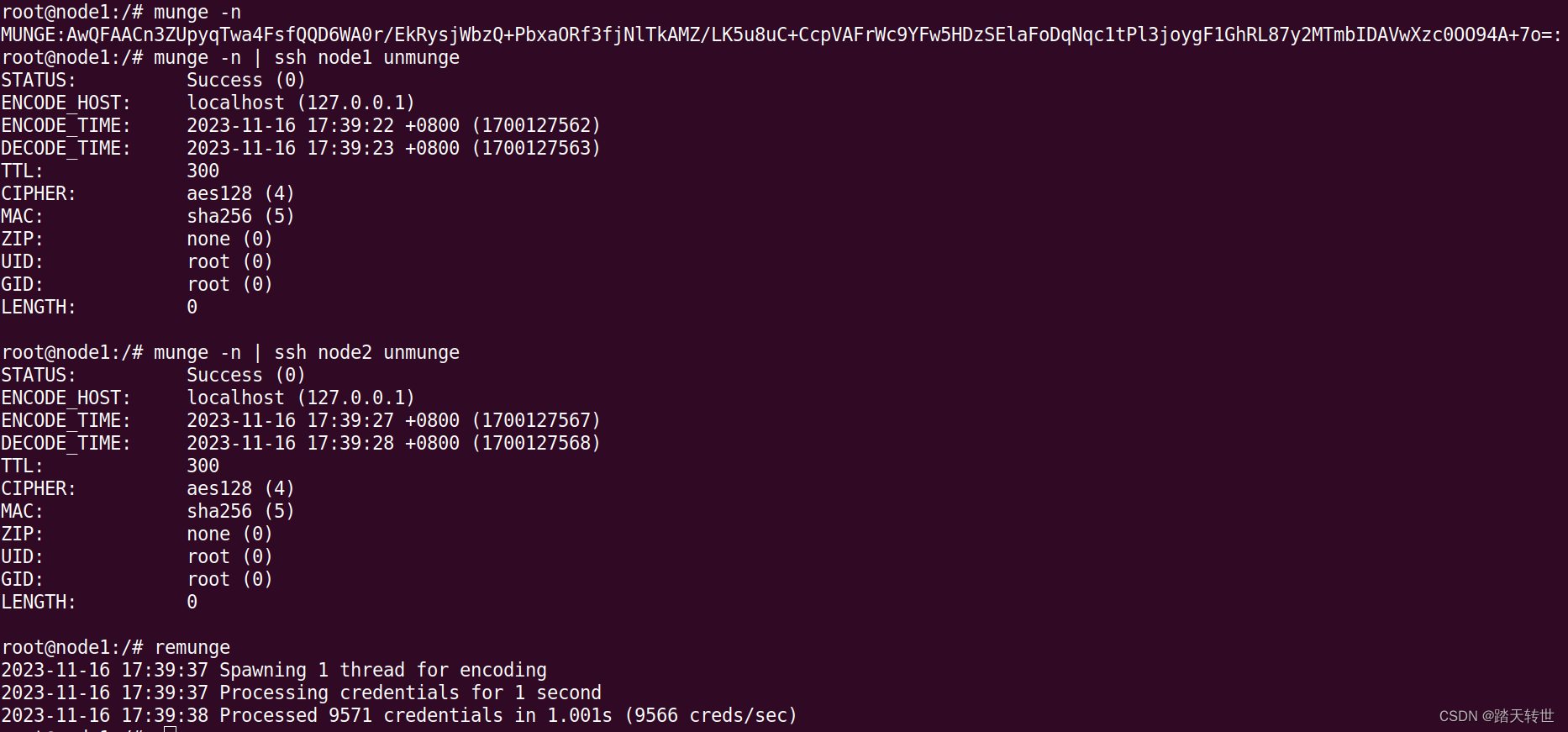
(5)在控制节点测试munge:
munge -n munge -n | unmunge # Displays information about the MUNGE key munge -n | ssh node1 unmunge remunge
2、安装mariadb
(1) apt install mariadb-server
(2)修改/etc/mysql/mariadb.conf.d/50-server.cnf,添加:
[mysqld]
bind-address = 192.168.1.250
innodb_buffer_pool_size = 1G
innodb_log_file_size = 64M
innodb_lock_wait_timeout = 900
(3)启动mariadb:
systemctl enable mariadb --now && systemctl start mariadb
(4)配置mariadb:
mysql
create database slurm_acct_db;
grant all on slurm_acct_db.* to 'slurm'@'node1' identified by '123456!' with grant option;
3、安装slurm:
(1)源码编译安装:
git clone https://github.com/SchedMD/slurm.git
cd slurm
./configure
make -j install
(2)相关服务拷贝至系统服务目录下:
find etc |grep service$ | xargs -i cp -v {} /usr/lib/systemd/system
(3)编辑/usr/local/etc/usrslurm.conf:
# slurm.conf file generated by configurator easy.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ClusterName=cluster-DT
SlurmctldHost=node1
#
MailProg=/bin/mail
MpiDefault=none
#MpiParams=ports=#-#
ProctrackType=proctrack/pgid
ReturnToService=1
SlurmctldPidFile=/run/slurmctld.pid
#SlurmctldPort=6817
SlurmdPidFile=/run/slurmd.pid
#SlurmdPort=6818
SlurmdSpoolDir=/var/lib/slurm/slurmd
#SlurmUser=slurm
SlurmdUser=root
StateSaveLocation=/var/lib/slurm/slurmctld
SwitchType=switch/none
TaskPlugin=task/affinity
#
#
# TIMERS
#KillWait=30
#MinJobAge=300
#SlurmctldTimeout=120
#SlurmdTimeout=300
#
#
# SCHEDULING
SchedulerType=sched/backfill
SelectType=select/cons_tres
SelectTypeParameters=CR_Core
#
#
# LOGGING AND ACCOUNTING
AccountingStorageType=accounting_storage/slurmdbd
#JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/none
#SlurmctldDebug=info
SlurmctldLogFile=/var/log/slurm/slurmctld.log
#SlurmdDebug=info
SlurmdLogFile=/var/log/slurm/slurmd.log
#
#
# COMPUTE NODES,根据实际硬件情况进行修改
GresTypes=gpu
NodeName=node1 NodeAddr=192.168.1.250 CPUs=96 Sockets=2 CoresPerSocket=24 ThreadsPerCore=2 Gres=gpu:nvidia_geforce_rtx_4090:4
NodeName=node2 NodeAddr=192.168.1.251 CPUs=96 Sockets=2 CoresPerSocket=24 ThreadsPerCore=2 Gres=gpu:nvidia_geforce_rtx_4090:4
PartitionName=debug Nodes=ALL Default=YES MaxTime=INFINITE State=UP
(4)编辑/usr/local/etc/slurmdbd.conf
#
# Example slurmdbd.conf file.
#
# See the slurmdbd.conf man page for more information.
#
# Archive info
#ArchiveJobs=yes
#ArchiveDir="/tmp"
#ArchiveSteps=yes
#ArchiveScript=
#JobPurge=12
#StepPurge=1
#
# Authentication info
AuthType=auth/munge
AuthInfo=/var/run/munge/munge.socket.2
#
# slurmDBD info
DbdAddr=localhost
DbdHost=localhost
#DbdPort=7031
SlurmUser=root
#MessageTimeout=300
DebugLevel=verbose
#DefaultQOS=normal,standby
LogFile=/var/log/slurm/slurmdbd.log
PidFile=/run/slurmdbd.pid
#PluginDir=/usr/lib/slurm
#PrivateData=accounts,users,usage,jobs
#TrackWCKey=yes
#
# Database info
StorageType=accounting_storage/mysql
StorageHost=192.168.1.250
#StoragePort=1234
StoragePass=123456!
StorageUser=slurm
StorageLoc=slurm_acct_db
(5)编辑/usr/local/etc/cgroup.conf
###
#
# Slurm cgroup support configuration file
#
# See man slurm.conf and man cgroup.conf for further
# information on cgroup configuration parameters
#--
CgroupPlugin=cgroup/v1
CgroupAutomount=yes
ConstrainCores=no
ConstrainRAMSpace=no
(6)编辑/usr/local/etc/gres.conf,此处根据硬件情况进行修改,与slurm.conf对应:
NodeName=node[1-2] Name=gpu Type=nvidia_geforce_rtx_4090 File=/dev/nvidia[0-3]
(6)拷贝相关配置文件到计算结点:
scp /usr/local/etc/*.conf node2:/usr/local/etc/

(7)控制节点启动服务:systemctl enable slurmdbd slurmctld && systemctl restart slurmdbd slurmctld && systemctl status slurmdbd slurmctld,确保不报错

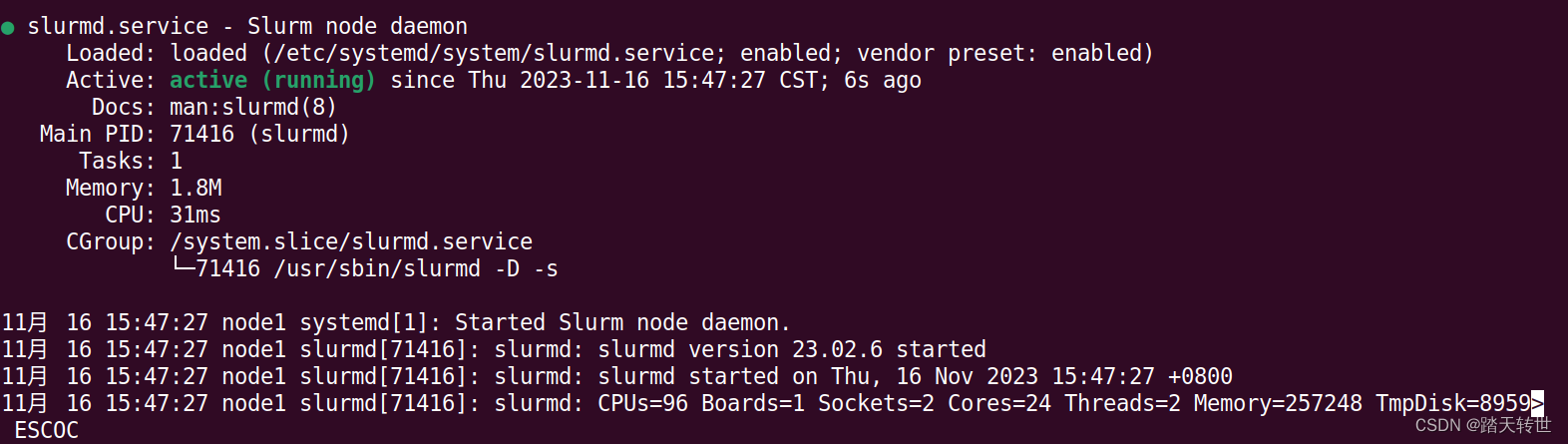
(8)计算节点启动服务:systemctl enable slurmd && systemctl restart slurmd && systemctl status slurmd,确保不报错
4、安装验证:
(1)验证slurm分布式执行:
srun -N 2 hostname
显示如下:
node1
node2
说明分布式成功
(2)验证GPU 调度:
测试脚本test_gpus.py如下:
import torch
import os
print('hostname', end=' ')
os.system('hostname')
# Check if GPU is available
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"GPU device name: {torch.cuda.get_device_name(0)}")
print(torch.cuda.device_count())
else:
print("No GPU available, switching to CPU.")
device = torch.device("cpu")
# Sample tensor operations
x = torch.rand(3, 3).to(device)
y = torch.rand(3, 3).to(device)
z = x + y
print(z)
运行测试脚本如下:
srun -N 2 /home/ai_group/anaconda3/envs/ds/bin/python test_gpus.py
输出为:
node1
node2
hostname GPU device name: NVIDIA GeForce RTX 4090
4
tensor([[0.2323, 1.9275, 1.7250],
[0.2598, 0.8294, 0.3233],
[1.5031, 1.1501, 1.1733]], device='cuda:0')
hostname GPU device name: NVIDIA GeForce RTX 4090
4
tensor([[0.8475, 1.9455, 1.1381],
[1.1546, 1.5055, 1.6784],
[0.9629, 0.0842, 0.8493]], device='cuda:0')
也可以使用sinfo,scontrol show node等命令确认节点信息。
TIPS: srun -n 2 hostname
srun: error: Unable to confirm allocation for job 23: Invalid job id specified
srun: Check SLURM_JOB_ID environment variable. Expired or invalid job 23
Solution: for env in "${!SLURM*}"; do unset $env














 2817
2817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









