







STL有全排列函数next_permutation:传送门
不过还是自己写写比较好啊~
自己写全排列:
#include <iostream>
#include <algorithm>
using namespace std;
const int MAXN = 105;
int a[MAXN];
int n,cnt;
inline void mySwap(int i,int j)
{
int temp;
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
inline void print(int *a)
{
for(int i = 0; i < n; i++)
{
cout<<a[i]<<" ";
}
cout<<"\n";
}
/*
全排列递归写法(非字典序)
基本思想:
每次固定该序列的某一个数(固定到s位置),
然后递归调用s之后构成的子序列全排列,
直到需要全排列的子序列只有一个数就先打印出整个序列
然后递归返回
*/
//去重
bool check(int cur)
{
for(int i = cur+1; i < n; i++)//当前交换的与它后面的数有重复,当前位置先不交换
{
if(a[cur] == a[i])
return false;
}
return true;
}
/*
解释“当前交换的与它后面的数有重复,当前位置先不交换”,而为什么不使用当前位置,而让后面重复的不使用呢?
这是为了判断效率,降低判断难度啊,要判断 当前序列中这个打算用来交换的数 在当前这个序列 这个数之前 有没有被使用,
是需要知道 这个子序列的 起始位置的,
因为是递归,而每个子序列的起始位置都不同,明显更不好处理,所以。。。
*/
void permutation(int *a,int s)
{
if(s == n)
{
cnt++;
print(a);
return;
}
for(int i = s; i < n; i++)
{
if(check(i))
{
mySwap(s,i);
permutation(a,s+1);
mySwap(s,i);
}
}
}
/*
全排列非递归算法,
并且字典序,
会去重
理解:
因为要字典序,首先就要让它第一个序列有序(升序),
(对于全是数字来说,全排列字典序就是要让能组成的数字从小到大排列)
要得到其他序列,
用例子来说明:
序列: 1 2 3 4
1 2 3 4 就是它的全排列的第一个序列
之后肯定要找到最后一对a[i]<a[i+1],pos = i,
再找pos之后最后一个a[i] > a[pos],k = i
交换pos ,k这两个位置上的值
a[pos] = 3
a[k] = 4
得到:
1 2 4 3
//这里好像交换后就不需要再做任何操作了,后面也是吗?
继续做下去:
a[pos] = 2
a[k] = 3
交换a[pos] 与a[k]
得到:
1 3 4 2
这里明显不是我们预先想得到的,我们要得到的是:1 3 2 4
我们发现交换后把pos位置之后的序列反转就是我们想要的
这到是否有通用性,或者是否是正确的做法呢?
仔细想一想,之前的交换总会使此时pos位置后的子序列,
如果把它看成一个数字,那么它会逐渐变为最大,
但是对于当前pos,后面的序列看成一个数字应该要是最小的,
所以此时pos位置后序列作反转一定是具有通用性,正确性!!
so:交换之后,一定要反转pos位置之后的序列
前面有看起来不用反转,是因为pos位置后的子序列只有一个数,当然看不出要反转~
概括总步骤:
1.如果原始序列无序,必须先排序,有序的序列为全排列的第一个序列
2.找最后一对a[i] < a[i+1] ,pos = i
3.pos后找最后一个a[i] > a[pos], k = i
4.交换a[pos],a[k]的值
5.反转pos之后的序列
6.打印当前序列(这个序列为全排列得到的下一个序列)
repeat上述步骤,直到找不到pos
*/
void permutationTwo(int *a)
{
sort(a,a+n);
//第一个要打印出来
cnt++;
print(a);
while(1)
{
int pos = -1;
/*
从前往后找最后一个:a[i]<a[i+1],pos = i,
现在从后往前找以提高效率,即转化为
第一个:a[i] > a[i-1],pos = i - 1;
*/
for(int i = n-1; i > 0; i--)//i > 0 防止数组越界
{
if(a[i] > a[i-1])
{
pos = i - 1;
break;
}
}
if(pos == -1) break;
int k = -1;
/*
找pos之后最后一个a[i] > a[pos],k = i,
从后向前找即第一个a[i] > a[pos],k = i
*/
for(int i = n-1; i > pos; i--)
{
if(a[i] > a[pos])
{
k = i;
break;
}
}
//交换pos,k两个位置元素的值
mySwap(pos,k);
//反转pos之后元素
for(int i = pos+1,j = n-1; i <= j; i++,j--)
{
mySwap(i,j);
}
cnt++;
//打印permutation
print(a);
}
}
int main()
{
cin>>n;
for(int i = 0; i < n; i++)
{
cin>>a[i];
}
cout<<"permutation:"<<endl;
permutation(a,0);
cout<<"permutation count = "<<cnt<<endl;
cnt = 0;
cout<<"permutationTwo:"<<endl;
permutationTwo(a);
cout<<"permutationTwo count = "<<cnt<<endl;
return 0;
}
测试结果:
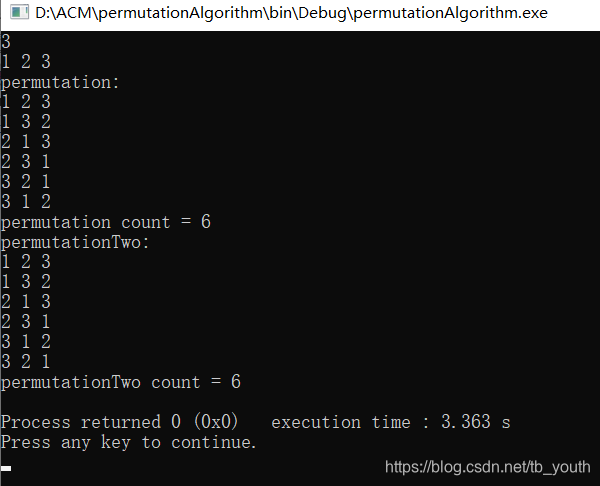
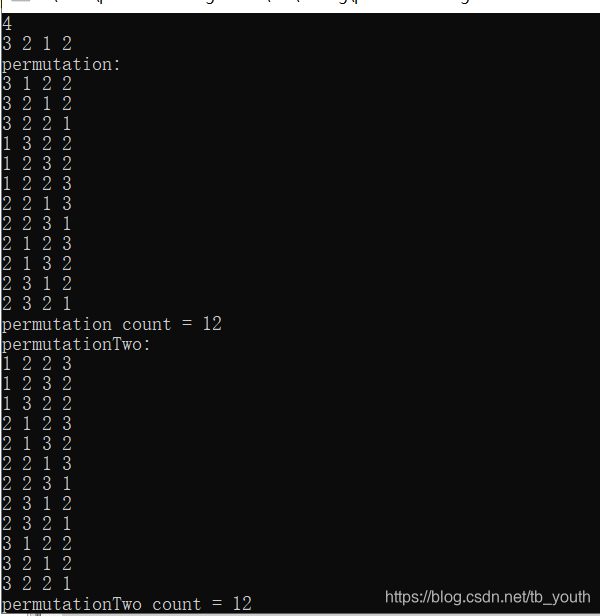
时间复杂度:
递归和非递归都近似O(n!)
但是非递归相对要慢一些,因为它在其他方面,
比如反转,查找等方面增加了时间消耗。















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











