







全文链接:http://tecdat.cn/?p=30726
在存在缺失数据的情况下,需要根据缺失数据的机制和用于处理缺失数据的统计方法定制变量选择方法。我们专注于可以与插补相结合的随机和变量选择方法的缺失方法(点击文末“阅读原文”获取完整代码数据)。
我们围绕自举Bootstrap插补和稳定性选择技术进行一些咨询,帮助客户解决独特的业务问题,后者是为完全观察的数据而开发的。所提出的方法是通用的,可以应用于广泛的设置。仿真研究表明,与几种针对低维和高维问题的现有方法相比,BI-SS的性能是最好的或接近最好的,并且对变量选择方面的参数值调整相对不敏感。
引言
变量选择已经广泛研究了完全观察到的数据,现有方法包括基于AIC的经典方法(Akaike,1974)和现代正则化方法,如套索(Tibshirani,1996)。与完全观测的数据相比,在存在缺失数据的情况下,变量选择出现了新的挑战。特别是,存在不同的缺失数据机制,对于每种机制,都有不同的统计方法来处理缺失数据。因此,变量选择方法需要根据缺失的数据机制和所使用的统计方法进行调整。Little和Rubin(2002)和Tsiatis(2006)一起对处理缺失数据的现有统计方法进行了全面回顾。
相关视频
本文重点研究了随机缺失(MAR)。根据MAR研究了变量选择,并对用于处理缺失数据的统计方法进行了研究。
### 具有非正态变量的示例数据集
set.seed(1000)
n <- 50
x1 <- round(runif(n,0.5,3.5))
x2 <- as.factor(c(rep(1,10),rep(2,25),rep(3,15)))Bootstrap插补
随机创建缺失值
dat <- mice(data1)
complete(dat)稳定性选择与自举插补相结合
train <- data[trainindex,1:6]
calibrate <- data[-trainindex,1:6]
plot(train)Bootstrap插补
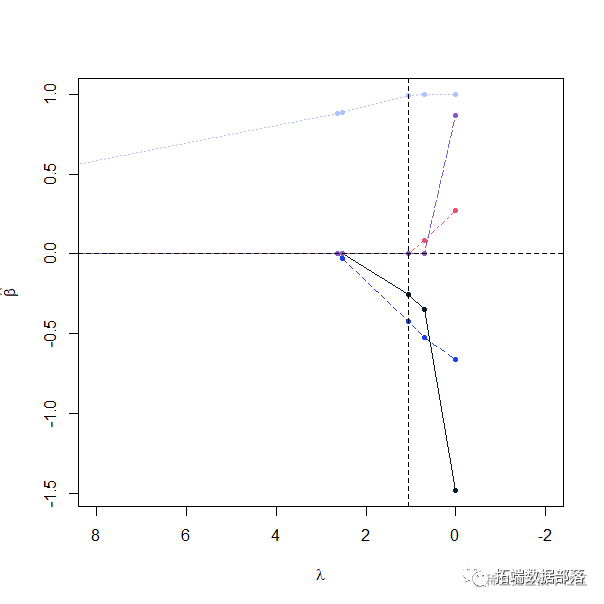
套索LASSO回归
lambda的最优值是通过交叉验证选择的。
点击标题查阅往期内容

PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









