







mapreduce标准流程
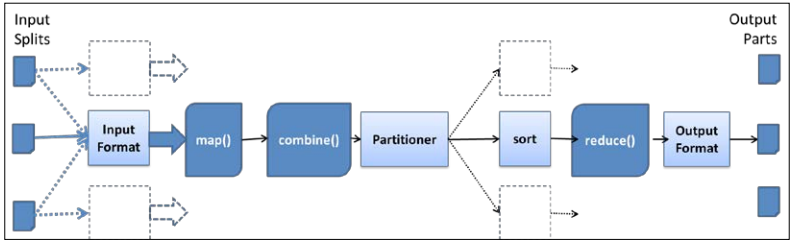
- InputFormat读取HDFS得到数据,并解析为key-value格式以供map函数使用
InputFormat同时perform(不知道怎么翻译,不是很理解)数据逻辑分区为Map task提供计算 - 标准的MR计算会对每个HDFS块创建Map 任务
- combine(参见note 1)
- Partitioner step:每个partitioner是按照key存储的键值对,并且partitioner的数量与reducer的数量相同。
- reduce 从相应的partitions中获取map阶段的数据(shuffing):按照key归并排序,按照key分组,将数据交给reduce function
- reduce计算结果会按照OutputFormatClass的个数输出到HDFS
数据格式
hadoop自己的数据格式(writable framework),比java自带的格式的好处在于: writable framework不写入typename,在序列化和反序列化上速度更快.
MR app的数据格式书写方式
- map 输入为 (key: LongWritable, value: Text) ,输出为: (key: Text, value: IntWritable)
public class SampleMapper extends Mapper
<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value,
Context context) … {
…… }
}- reduce输入为 (key: Text, value: IntWritable) ,输出为: (key: Text, value: IntWritable)
public class Reduce extends Reducer<Text, IntWritable,
Text, IntWritable> {
public void reduce(Text key,
Iterable<IntWritable> values, Context context) {
…… }
}- 如下设置同时设置map和reduce的输出格式
Job job = new Job(..);
….
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);- 也可以单独设置
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);一些数据格式
原始格式:
IntWritable, LongWritable, BooleanWritable, FloatWritable , and ByteWritable其他附加格式:
Text: This stores UTF8 text
BytesWritable : This stores a sequence of bytes
VIntWritable and VLongWritable : These store variable length integer and long values
NullWritable: This is a zero-length Writable type that can be used when you don't want to use a key or value type以上数据格式既可以用于key也可以用于value
还有一些其他特殊格式, 参见notebook 102
TwoDArrayWritable
MapWritable
SortedMapWritable书写自己的writable格式
若有如下格式需要处理 , 自己写一个Logwritable
192.168.0.2 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/
HTTP/1.0" 200 6245














 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









