







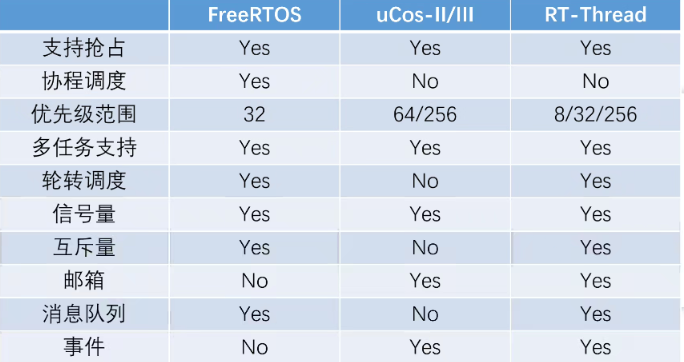
[RT-Thread 内核] 操作系统+启动流程+内核机制
文章为个人学习笔记,力求简洁用通俗易懂的话把事情讲清楚,但没想到还是写了这么多,不适合想要快速开发使用者
一、操作系统
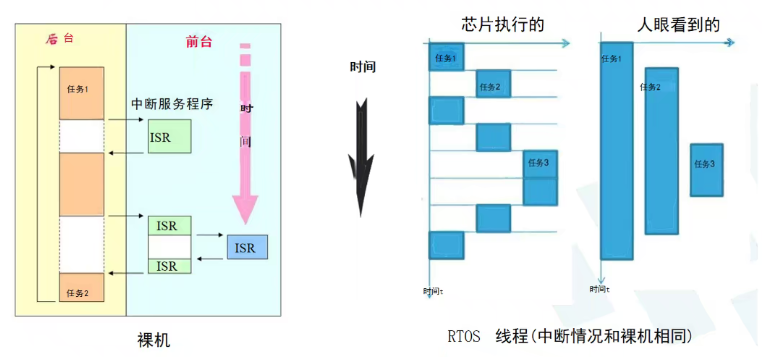
裸机开发-前后台顺序执行
在裸机开发中,应用程序通常是一个无限循环,通过在循环中调用不同的处理函数来完成相应操作,这部分内容可以看作
后台行为,它们之间相互制约影响,某一个函数的阻塞就会导致整个系统的稳定性和实时性受到影响。好在单片机引入了中断的概念,即遇到紧急事件时,我们优先去处理紧急事件,这部分内容可以看作
前台行为,通过定时触发中断或者遇到紧急事件时触发外部中断,系统的实时性以及稳定性得到了一定保证。
但是裸机开发的缺陷还是很明显:
- 单核CPU宏观上无法解决程序
并发性问题,举个例子funA()/funB()都需要执行2min,那么无论funA()还是funB()执行起来都是一顿一顿(实时性)的,常见的解决方法是对funA()/funB进行状态机设计,什么意思呢?就是把2min的执行时间分为好几个状态,来轮流执行,一顿一顿的感觉就会没有那么明显,但是这会给开发者带来巨大的代码工作量。 - 前面也提到后台行为之间是相互制约影响的,这导致我们简单的改动funA()程序,也需要考虑对funB()的影响,即应用程序之间或者说各模块之间没有做到“高内聚,低耦合”,这使得代码的
可重用性以及项目功能的扩展维护性就大幅度降低。
伪多线程or时间片轮转开发
当程序较为复杂,但是又没有必要上操作系统和硬件成本有限时会采取伪多线程的编程方式。
伪多线程,简单来说就是通过一个硬件定时器+tick计数器or多个Flag标志位,来构造出多个软件定时器周期的去执行不同模块代码(
需要保证执行周期时间大于模块执行所花费时间)。使用该方法时需要注意硬件定时器不可设置过短或过长,需要权衡执行效率与实时性,太短效率就低,太长实时性差。
- 简单用法
// 标准库
void TIM2_IRQHandler(void)
{
if (TIM_GetITStatus(TIM2, TIM_IT_Update) == SET)
{
tick++;
tick % 1 == 0? task_tick_falg = 1 : 0;
tick % 5 == 0? task_5tick_falg = 1 : 0;
tick % 5 == 0? task_10tick_falg = 1 : 0;
}
TIM_ClearITPendingBit(TIM2, TIM_IT_Update);
}
// HAL库
HAL_TIM_Base_Start_IT(&htim2);
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
if (htim->Instance == TIM2)
{
if (__HAL_TIM_GET_FLAG(&htim2, TIM_FLAG_UPDATE) != RESET)
{
cnt++;
cnt % 1 == 0? task_tick_falg = 1 : 0;
cnt % 5 == 0? task_5tick_falg = 1 : 0;
cnt % 10 == 0? task_10tick_falg = 1 : 0;
}
}
}
// main.c
while(1)
{
if(task_tick_falg)
{
task_tick_fun();
task_tick_falg = 0;
}
if(task_5tick_falg)
{
task_5tick_fun();
task_5tick_falg = 0;
}
if(task_10tick_falg)
{
task_10tick_fun();
task_10tick_falg = 0;
}
}
- 回调函数+表驱动
// task_fun.*
typedef struct{
uint8_t runFlag; // 标志位
uint16_t timer; // 定时器
uint16_t intervalTime; // 间隔时间
void (*taks_fun)(void); // 回调函数
}TASKINFO_t;
static TASKINFO_t g_TaskInfoList[] = {
{0, 1, 1, task_tick_fun},
{0, 5, 5, task_5tick_fun},
{0, 10, 10, task_10tick_falg},
};
#define TASK_INFO_LIST_LENGTH (sizeof(g_TaskInfoList)/sizeof(g_TaskInfoList[0]))
void task_traver_mark(void)
{
for(uint8_t i = 0; i < TASK_INFO_LIST_LENGTH; i++)
{
if(0 != g_TaskInfoList[i].timer)
{
if(0 == --g_TaskInfoList[i].timer)
{
g_TaskInfoList[i].timer = g_TaskInfoList[i].intervalTime;
g_TaskInfoList[i].runFlag = 1;
}
}
}
}
// *it.c
void TIM2_IRQHandler(void)
{
if (TIM_GetITStatus(TIM2, TIM_IT_Update) == SET)
{
task_traver_mark();
}
TIM_ClearITPendingBit(TIM2, TIM_IT_Update);
}
// main.c
while(1)
{
for(uint8_t i = 0; i < TASK_INFO_LIST_LENGTH; i++)
{
if(g_TaskInfoList[i].runFlag)
{
g_TaskInfoList[i].taks_fun(); // or (*g_TaskInfoList[i].task_fun)()
g_TaskInfoList[i].runFlag = 0;
}
}
}
实际使用中,回调函数+表驱动的应用场景还有很多,后续有时间总结下(挖坑…)。
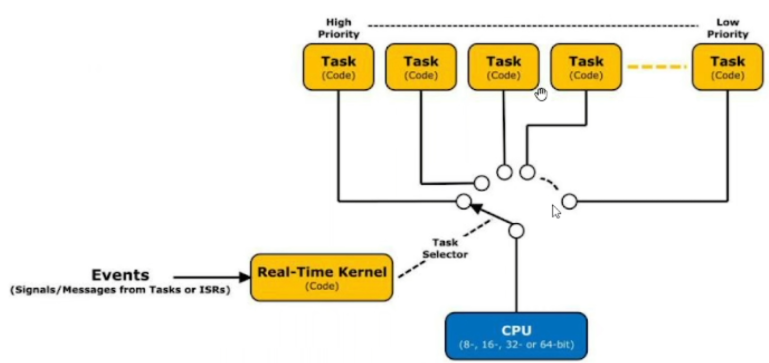
RTOS开发-时间片轮转+优先级抢占
RTOS操作系统国外主要有
uCOS、FreeRTOS,国内主要有LiteOS、AliOS、RT-Thread等,与国外操作系统不同的是,国内操作系统除了基本内核功能带的并发性、实时性、扩展性及可重用性优势外,它还提供了丰富的组件以及物联网生态,减少了开发者重复造轮子的时间。与伪线程不同的是,RTOS事件驱动机制除了
时间片轮转调度外,还可设置每个任务的优先级,在高优先级的任务就绪时,会抢占低优先级的任务。在RT-Thread中既可对线程设置不同的时间片大小,也可对线程设置不同的优先级,当存在不同优先级的线程时,线程时间片的大小就不那么重要,此时操作系统对线程的耗时没有过多的要求。注意:在RT-Thread系统中除了
中断处理函数、调度器上锁部分的代码和禁止中断的代码是不可抢占的之外,系统的其他部分都是可以抢占的,包括线程调度器自身。
- 硬实时与软实时概念介绍:以RT-Thread和Linux为例
首先实时系统指的是在确定的时间内完成规定功能,并能对外部异步事件作出正确响应的计算机系统。Linux作为一个通用操作系统,其所支持的功能如根文件系统、网络协议栈等都需要消耗大量的系统资源,为了保证系统的流程性,其对中断和事件的响应不是立刻马上确切的,只能称之为软实时系统(现在好像可以打RT补丁来缩短响应时间来提高实时性)。在一些军用/车载运动控制器场景,我们对响应时间是非常苛刻的否则就会带来灾难性的结果,所以就必须使用硬实时操作系统,如RT-Thread。
二、RT-Thread启动流程
流程概览
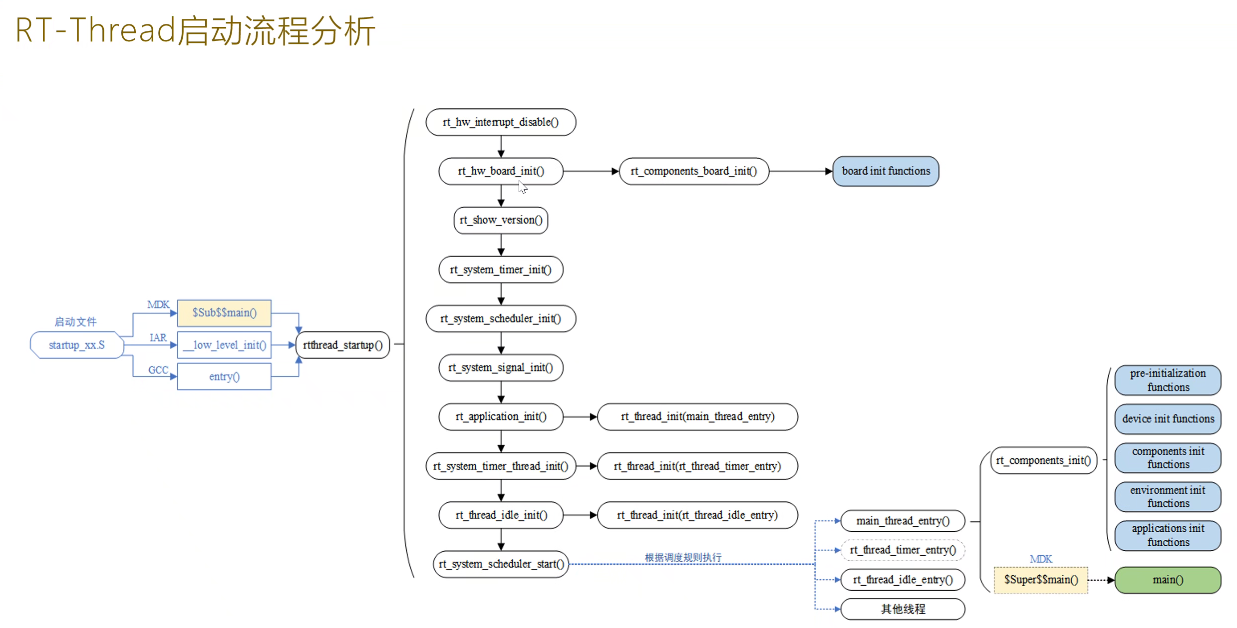
上图为从汇编代码到main函数的一个RT-Thread启动流程,这里使用到了一些机制,在main函数执行前启动了RT-Thread内核。如MDK采用的是
$Sub$$和“$Super$$,该机制常用于想修改程序的执行逻辑顺序,但又不想对已经封装好的代码进行太大的改动时使用。
下面是各个函数主要做的事情:
关闭中断- 硬件初始化 ( HAL(NVIC/SYSTICK/MSP)、时钟、
RT堆、PIN、串口、板级组件初始化) - 内核版本打印
软件定时器初始化调度器优先级列表初始化- app线程初始化(malloc rt_thread/stack、状态初始化、挂载到调度器列表进行管理、入口函数、初始化线程栈,这里涉及到ARM寄存器和线程第一次启动当作现场回复的知识、线程超时定时器、启动调度进入就绪态)
- 启动
系统定时器线程(可选) IDLE线程初始化 -> 最低优先级,提供钩子函数擦屁股,可用于功耗管理或者看门狗防宕机- 系统调度器启动开始运行工作(找到最高优先级线程、触发PendSV异常、
打开中断)- 开始调度->app线程:
main_thread_entry:组件初始化,进入main函数 - timer、idle、其他线程
- 开始调度->app线程:
代码追踪
接下来开始一步一步追代码,由于ENV环境默认采用ARM GCC作为工具链,我们以此为例:
找到project目录下的*.s文件,搜索entry打上断点F5烧录调式,点击单步执行进入rtthread_startup()
涉及内容比较多呀,作者仅对个人觉得比较重要的部分进行展开:
中断的关闭和开启、RT-Thread堆管理、软件定时器及调度器初始化、rtMain/Timer/Idle线程。
/* rtthread_startup()中的rt_hw_local_irq_disable()和rt_system_scheduler_start()中的rt_hw_interrupt_disable()
最终都是调用如下代码,不知道为何要关闭两次,上面贴的博客说后者支持中断嵌套,但是我实际调式并没有看到代码实现上的区别。*/
/* rt_base_t rt_hw_interrupt_disable(); */
.global rt_hw_interrupt_disable
.type rt_hw_interrupt_disable, %function
rt_hw_interrupt_disable:
MRS r0, PRIMASK
CPSID I
BX LR
/* 最终在rt_system_scheduler_start() -> rt_sched_remove_thread(to_thread) ->
rt_hw_interrupt_enable(level)开启中断, level为rt_hw_interrupt_disable的返回值,即之前的中断状态 */
/* void rt_hw_interrupt_enable(rt_base_t level); */
.global rt_hw_interrupt_enable
.type rt_hw_interrupt_enable, %function
rt_hw_interrupt_enable:
MSR PRIMASK, r0
BX LR
- RT-Thread堆管理
RTOS操作系统最重要的就是任务管理和内存管理,RT-Thread也不例外其开辟维护了自己的堆空间。
#if defined(RT_USING_HEAP)
/* Heap initialization */
rt_system_heap_init((void *)HEAP_BEGIN, (void *)HEAP_END);
#endif
/* 在rt_hw_board_init()中有上面这段代码,单步调式可以发现其最终调用了如下函数: */
void rt_system_heap_init_generic(void *begin_addr, void *end_addr)
{
/* 指定内存对齐大小并返回向大取整与向小取整数,简单来说就是保证内存对齐的情况下,
起始地址只能大不能小,终止地址只能小不能大,防止这个内存越界,RT_ALIGN_SIZE默认为8字节 */
rt_ubase_t begin_align = RT_ALIGN((rt_ubase_t)begin_addr, RT_ALIGN_SIZE);
rt_ubase_t end_align = RT_ALIGN_DOWN((rt_ubase_t)end_addr, RT_ALIGN_SIZE);
RT_ASSERT(end_align > begin_align);
/* Initialize system memory heap,调用了rt_smem_t rt_smem_init(const char* name,
void* begin_addr, rt_size_t size)这么一个函数,对内存进行小内存管理算法初始化 */
_MEM_INIT("heap", (void *)begin_align, end_align - begin_align);
/* Initialize multi thread contention lock */
_heap_lock_init();
}
这片内存区域在哪呢?如何定义的呢?在board.h有如下定义:
#define STM32_SRAM_SIZE (128)
#define STM32_SRAM_END (0x20000000 + STM32_SRAM_SIZE * 1024)
#define STM32_FLASH_START_ADRESS ((uint32_t)0x08000000)
#define STM32_FLASH_SIZE (1024 * 1024)
#define STM32_FLASH_END_ADDRESS ((uint32_t)(STM32_FLASH_START_ADRESS + STM32_FLASH_SIZE))
#if defined(__ARMCC_VERSION)
extern int Image$$RW_IRAM1$$ZI$$Limit;
#define HEAP_BEGIN ((void *)&Image$$RW_IRAM1$$ZI$$Limit)
#elif __ICCARM__
#pragma section="CSTACK"
#define HEAP_BEGIN (__segment_end("CSTACK"))
#else
extern int __bss_end;
#define HEAP_BEGIN ((void *)&__bss_end)
#endif
#define HEAP_END STM32_SRAM_END
这里我们要对ARM公司32位4GB地址空间所对应的内容有所了解,下面是一个简单示意图:
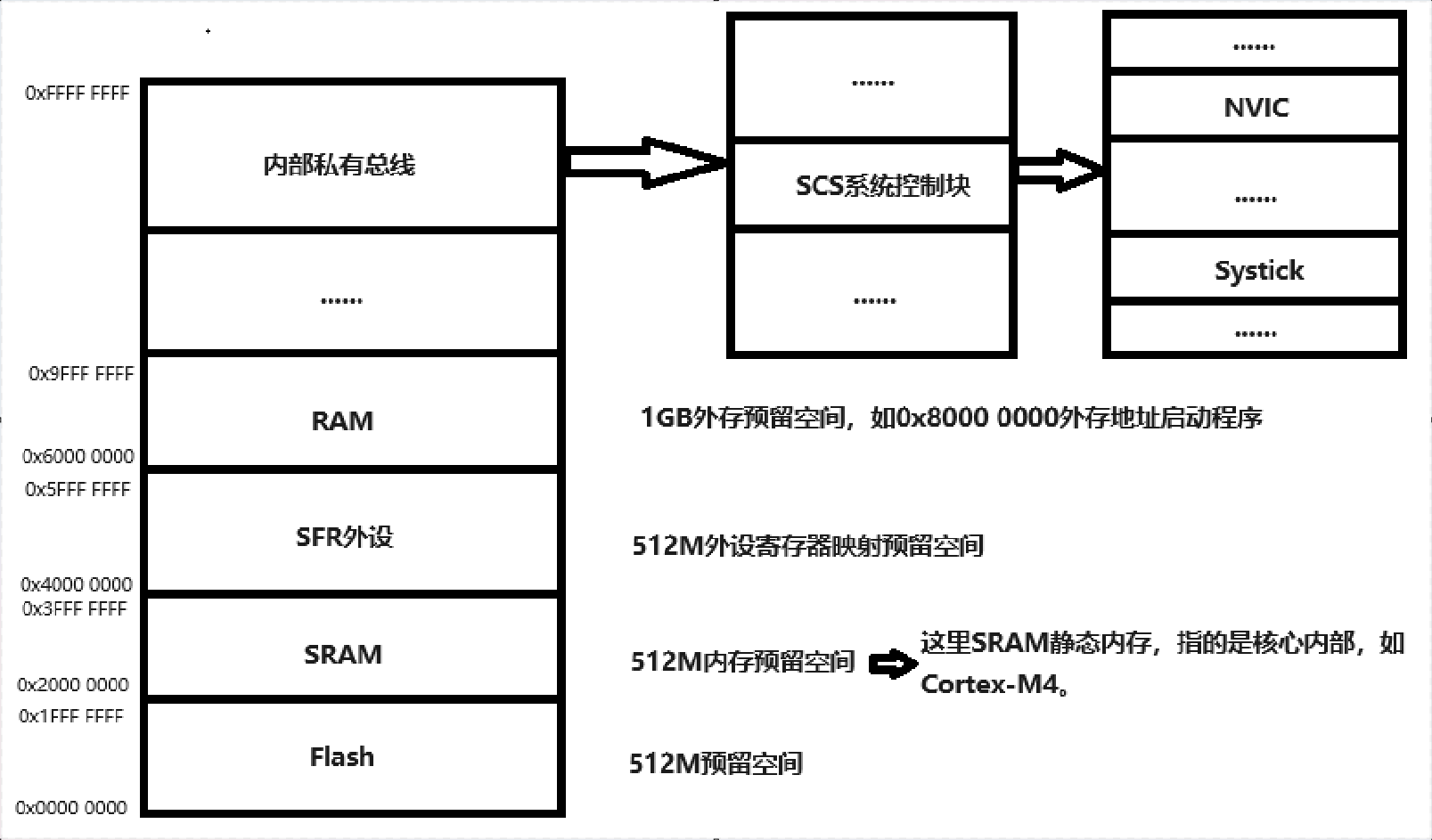
分析可以发现,STM32F407ZG只用了512M预留空间中的1M Flash以及128K SRAM,但是这里起始地址为0x08000000,这是因为STM32官方进行了地址重映射,boot0、boot1拉低至低电平后, 上电默认从0x08000000启动,进行MSP主栈读取、复位与向量表设置。
回到正题,可以看到RT堆的开始地址HEAP_BEGIN定义为BSS段的结束位置,BSS段又涉及到link.lds链接脚本知识,这里不做展开有兴趣的小伙伴可自行学习,RT堆的终止地址为SRAM结束地址。
- 软件定时器及调度器初始化,比较简单,直接看代码
/* timer system initialization */
rt_system_timer_init();
/* scheduler system initialization */
rt_system_scheduler_init();
rt_system_timer_init();
#define RT_TIMER_SKIP_LIST_LEVEL 1
static rt_list_t _timer_list[RT_TIMER_SKIP_LIST_LEVEL]; /* hard timer list */
void rt_system_timer_init(void)
{
rt_size_t i;
for (i = 0; i < sizeof(_timer_list) / sizeof(_timer_list[0]); i++)
{
rt_list_init(_timer_list + i);
}
rt_spin_lock_init(&_htimer_lock); // _htimer_lock未使用
}
rt_inline void rt_list_init(rt_list_t *l)
{
//将当前节点(头节点)的前驱指针指向自己,将当前节点的后继指针也指向自己
l->next = l->prev = l;
}
rt_system_scheduler_init();
#define RT_THREAD_PRIORITY_MAX 32 // 默认使用32种优先级,即0~31
void rt_system_scheduler_init(void)
{
rt_base_t offset;
rt_scheduler_lock_nest = 0;
LOG_D("start scheduler: max priority 0x%02x",
RT_THREAD_PRIORITY_MAX);
for (offset = 0; offset < RT_THREAD_PRIORITY_MAX; offset ++)
{
rt_list_init(&rt_thread_priority_table[offset]);
}
/* initialize ready priority group */
rt_thread_ready_priority_group = 0;
#if RT_THREAD_PRIORITY_MAX > 32
/* initialize ready table */
rt_memset(rt_thread_ready_table, 0, sizeof(rt_thread_ready_table));
#endif /* RT_THREAD_PRIORITY_MAX > 32 */
}
- rtMain/Timer/Idle线程
/* create init_thread */
rt_application_init();
/* timer thread initialization */
rt_system_timer_thread_init();
/* idle thread initialization */
rt_thread_idle_init();
rtMain线程:rtthread_startup() -> rt_application_init() -> main_thread_entry() -> main()
两个重要的函数rt_thread_create和rt_thread_init,分别为动态创建和静态创建,两者存储区域不同,动态创建程序运行时执行主要使用RT堆空间,静态创建编译期完成主要使用数据段空间。默认使用动态创建,期间主要向内核对象系统申请分配了一个线程对象以及向RT堆进行栈空间申请,最后通过_thread_init将线程各个信息初始化到线程控制块中以及优先级等初始化到调度器中。
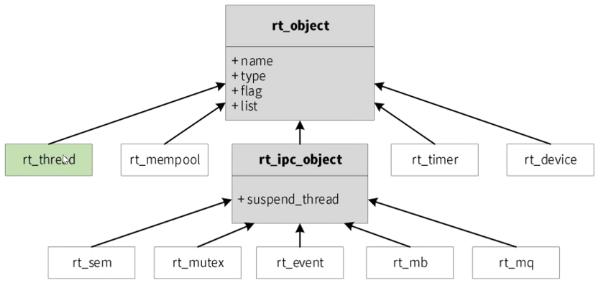
由于线程的调度切换本质上就是函数切换,这就涉及到现场保护与恢复,所以初始化时我们就需要伪造保护现场,以达到恢复时可以执行我们期望的行为,另外每个线程还有自己的软件定时器,用于记录执行时间与时间片作比较。
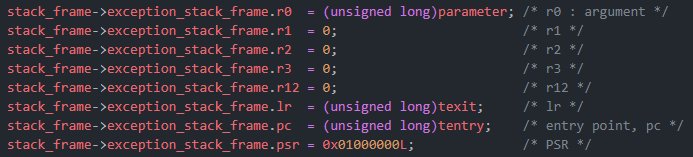
void rt_application_init(void)
{
rt_thread_t tid;
#ifdef RT_USING_HEAP
tid = rt_thread_create("main", main_thread_entry, RT_NULL,
RT_MAIN_THREAD_STACK_SIZE, RT_MAIN_THREAD_PRIORITY, 20);
RT_ASSERT(tid != RT_NULL);
#else
rt_err_t result;
tid = &main_thread;
result = rt_thread_init(tid, "main", main_thread_entry, RT_NULL,
main_thread_stack, sizeof(main_thread_stack), RT_MAIN_THREAD_PRIORITY, 20);
RT_ASSERT(result == RT_EOK);
/* if not define RT_USING_HEAP, using to eliminate the warning */
(void)result;
#endif
rt_thread_startup(tid);
}
注意:上方的 rt_thread_startup()并未真正启动,到了rt_system_scheduler_start()调度器启动各个线程才是真正开始工作。
Timer线程:rtthread_startup() -> rt_system_timer_thread_init() -> _timer_thread_entry()
默认没有开启,需要定义RT_USING_TIMER_SOFT宏来开启。
void rt_system_timer_thread_init(void)
{
#ifdef RT_USING_TIMER_SOFT
int i;
for (i = 0;
i < sizeof(_soft_timer_list) / sizeof(_soft_timer_list[0]);
i++)
{
rt_list_init(_soft_timer_list + i);
}
rt_spin_lock_init(&_stimer_lock);
rt_sem_init(&_soft_timer_sem, "stimer", 0, RT_IPC_FLAG_PRIO);
rt_sem_control(&_soft_timer_sem, RT_IPC_CMD_SET_VLIMIT, (void*)1);
/* start software timer thread */
rt_thread_init(&_timer_thread,
"timer",
_timer_thread_entry,
RT_NULL,
&_timer_thread_stack[0],
sizeof(_timer_thread_stack),
RT_TIMER_THREAD_PRIO,
10);
/* startup */
rt_thread_startup(&_timer_thread);
#endif /* RT_USING_TIMER_SOFT */
}
Idle线程:rtthread_startup() -> rt_thread_idle_init() -> idle_thread_entry() -> 可自定义idle_hook()
由于Idle线程优先级为PRIORITY_MAX-1最低优先级,所以一般用于擦屁股,如功耗管理or看门狗,如果看门狗无法及时进行喂狗,则说明要么宕机,要么高优先级线程一直占用CPU资源,应rt_thread_mdelay适当挂起该任务,释放CPU资源,使得Idle线程也有机会执行。
除此之外,空闲线程还担任一些线程资源回收工作,故其不能被挂起,永远处于就绪态。
#define RT_NAME_MAX 8
#define _CPUS_NR RT_CPUS_NR
#define RT_CPUS_NR 1
void rt_thread_idle_init(void)
{
rt_ubase_t i;
char idle_thread_name[RT_NAME_MAX];/* if RT_NAME_MAX > 0 */
for (i = 0; i < _CPUS_NR; i++)
{
rt_snprintf(idle_thread_name, RT_NAME_MAX, "tidle%d", i);/* if RT_NAME_MAX > 0 */
rt_thread_init(&idle_thread[i],
idle_thread_name,/* if RT_NAME_MAX > 0 */
idle_thread_entry,
RT_NULL,
&idle_thread_stack[i][0],
sizeof(idle_thread_stack[i]),
RT_THREAD_PRIORITY_MAX - 1,
32);
#ifdef RT_USING_SMP
...
#endif
/* update */
rt_cpu_index(i)->idle_thread = &idle_thread[i];
/* startup */
rt_thread_startup(&idle_thread[i]);
}
#ifdef RT_USING_SMP
...
#endif
}
static void idle_thread_entry(void *parameter)
{
#ifdef RT_USING_SMP
...
#endif
while (1)
{
#ifdef RT_USING_IDLE_HOOK
rt_size_t i;
void (*idle_hook)(void);
for (i = 0; i < RT_IDLE_HOOK_LIST_SIZE; i++)
{
idle_hook = idle_hook_list[i];
if (idle_hook != RT_NULL)
{
idle_hook();
}
}
#endif
#ifndef RT_USING_SMP
...
#endif
#ifdef RT_USING_PM
...
#endif
}
}
三、RT-Thread内核机制
在生活中,我们遇到复杂棘手问题时往往会对进行拆解来分而治之,一部分一部分解决。RT-Thread也不例外其采用调度器基于时间片与优先级抢占的方式来对各部分任务进行管理,不过这样每部分之间都是独立的,我们就需要有一些相互交互的方式来协同工作,这里就要引出IPC机制等概念。
需要注意的是,在Linux中IPC一般是指进程间通信机制,但是标准版RT-Thread仅支持单核MCU,故没有进程的概念,所以这里的IPC也就是常说的线程间同步、互斥以及通信机制。
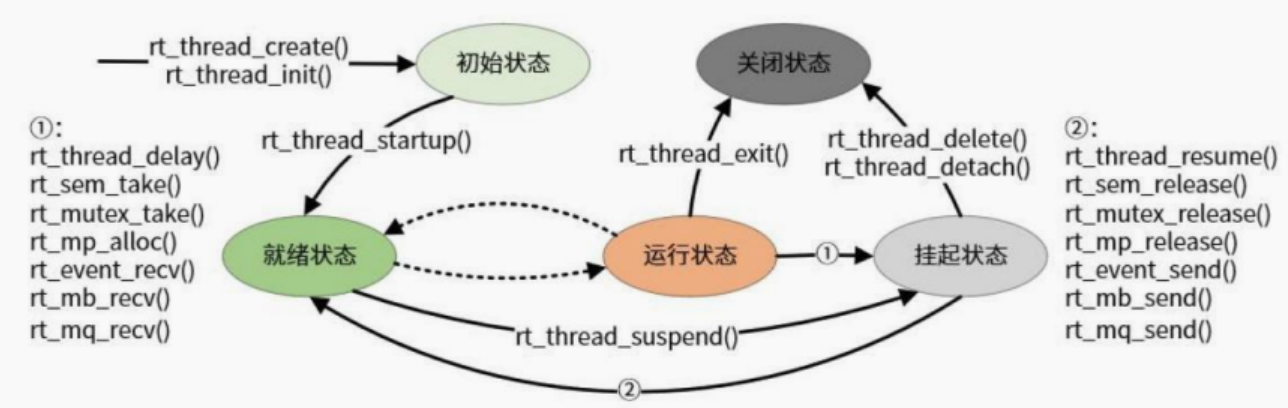
任务管理
官方的图就已经可以很清楚的说明任务的五个阶段分别在干什么以及各个阶段之间是如何进行切换。

rt_thread_t rt_thread_create(const char *name,
void (*entry)(void *parameter),
void *parameter,
rt_uint32_t stack_size,
rt_uint8_t priority,
rt_uint32_t tick)
rt_err_t rt_thread_init(struct rt_thread *thread,
const char *name,
void (*entry)(void *parameter),
void *parameter,
void *stack_start,
rt_uint32_t stack_size,
rt_uint8_t priority,
rt_uint32_t tick)
下文主要对一些注意点以及模糊的概念进行一些说明:
- 优先级:不同于FreeRTOS,RT-Thread优先级是
数字越小优先级越大,此外优先级最大可支持256。 - 时间片与优先级:时间片仅对优先级相同的就绪态线程有效,多个优先级存在时其设置不再那么重要。
- 挂起是什么?何时会挂起?
挂起机制主要是为了减少不必要的等待以及CPU资源浪费,这也是与裸机中最大的区别,有点事件驱动和轮询的意思,当线程执行完或者暂时获取不到资源,进入挂起态让出CPU的使用权,让其他线程得以运行。
一个处于就绪态或者运行态的线程,我们都可以让其进入挂起状态,挂起状态的线程可以继续进入就绪态,也可以删除/脱离进入关闭态。线程的挂起和唤醒除了suspend/resume以外,剩下函数主要为线程间同步、互斥、通信以及线程池相关API。
与FreeRTOS对比发现:主要是挂起态这里处理机制不同,RT-Thread把suspend/resume以及一些同步互斥通信函数获取不到资源时统称为挂起态,FreeRTOS则是做了分离,对于后面这些部分其称之为阻塞态。
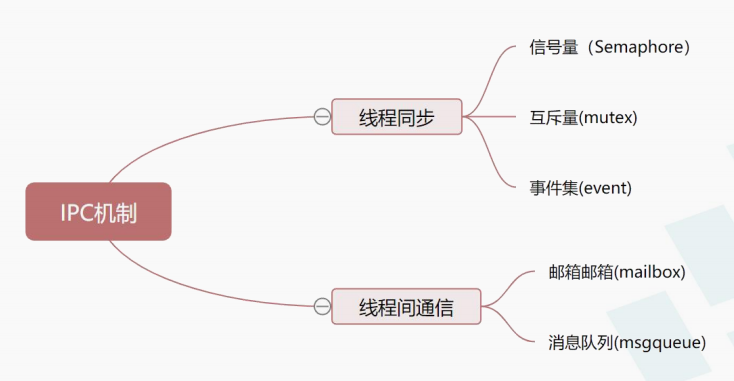
线程间同步、互斥、通信
正式开始介绍前先引入几个概念:
什么是临界区?、阻塞、非阻塞、挂起是什么?、死锁是什么?
- 临界区:简单来说就是有限资源的集合,如全局变量,同一时间只能被一个线程使用。
- 阻塞/非阻塞:一切阻塞其他任务继续执行的情况都称之为阻塞。
以接水为例,我拿了一个水杯在饮水机前接水,别人就必须阻塞等待我完成或者非阻塞先转身去做别的事时不时再回来看下。同样的我自身其实也被饮水机这个线程所阻塞着,这期间我只能等待水接满而不能做别的事,这称之为同步通信;如果饮水器可以自动放水并在接满时对我发出通知,那我就可以转身先去做别的事,这就是非阻塞,也称之为异步通信。
需要注意的是阻塞/非阻塞并没有优劣之分只有适合与不适合,就像轮询和中断一样,对分频繁发生的事如果采用中断反而降低了执行效率,同样有时我们稍微阻塞一会儿就可以得到执行,但是你非要立刻返回造成上下文切换然后再次判断反而得不偿失。
- 挂起:生活中我们暂且搁置某一件事的行为就称之为挂起,上面接水的例子中别人非阻塞转身去做别的事情,就是挂起了接水这件事。一般在获取不到资源或者线程主动让出CPU资源时,该线程会进入挂起状态,线程栈中记录的信息就像人脑的记忆一样,以便回过头时不会忘记上次执行到哪。
- 死锁:由于临界区资源竞争,各线程想要获取的资源无法释放,导致各线程无法进一步执行的现象就称之为死锁现象。具体怎么排查呢?-> ps/top查看CPU占用率 ;如何避免?->资源有序申请获取法
同步互斥
信号量、互斥锁、事件集
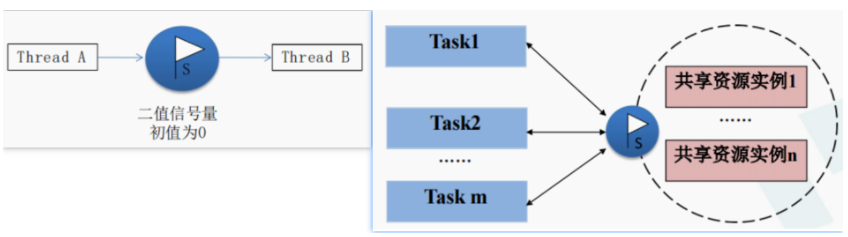
- 信号量:用于实现
任务与任务之间、任务与中断处理程序之间的同步与互斥
信号量一般有三种作用:
互斥信号量,其实就是用二值信号量来解决互斥问题,一般不使用,会引起优先级反转问题- 二值信号量,用于解决同步问题,在裸机中一般使用的是全局变量flag,但是当同步事件过多时,全局变量的修改很容易导致出现
一些错误和不可预料的结果,并且裸机一直轮询判断全局变量的状态是十分消耗CPU的资源的,影响实时性。 - 计数信号量,用于解决资源计数问题
// 动态创建
rt_sem_t rt_sem_create(const char *name, rt_uint32_t value, rt_uint8_t flag);
rt_err_t rt_sem_delete(rt_sem_t sem);
// 静态创建
rt_err_t rt_sem_init(rt_sem_t sem, const char *name, rt_uint32_t value, rt_uint8_t flag);
rt_err_t rt_sem_detach(rt_sem_t sem);
// 发送、获取
// time单位为tick,三种策略:直接返回、挂起等待一段时间、永久等待直到释放
rt_err_t rt_sem_take(rt_sem_t sem, rt_int32_t time);
rt_err_t rt_sem_trytake(rt_sem_t sem); // 直接返回,不想等待时,一般使用这个API,增加可读性
rt_err_t rt_sem_release(rt_sem_t sem); // 先有等待线程直接唤醒,无则对信号量加1
当调用创建函数时,系统会先从对象管理器分配一个rt_sem对象并初始化,然后初始化父类rt_ipc_object对象以及rt_sem相关内容,如flag选项RT_IPC_FLAG_FIFO和RT_IPC_FLAG_PRIO,决定多个线程挂起等待时,优先唤醒谁,一般只选用RT_IPC_FLAG_PRIO保证实时性。
当调用删除函数时,会先判断有无正在等待该信号量的线程,若有则先会唤醒该线程并返回-RT_ERROR错误,然后再删除信号量。
注意:静态动态创建不能混用,两者存储区域不同,动态是RT堆,静态是数据段,不能是BSS段,因为有断言(sem!= RT_NULL)卡死,动态delete是删除释放内存了,静态detach只是脱离不再使用了。
- 互斥锁:主要用于
任务与任务之间对临界区资源进行互斥访问,
互斥锁是从信号量上面引申出来的东西,是一种特殊的二值信号量,主要是为了解决二值信号量无法对临界资源进行互斥保护的问题。它和二值信号量不同的是,它新增了如下特性:
- 添加owner成员变量,使得
互斥量具有所有权,锁被谁获得就必须由谁释放,像二值信号量/计数信号量产生时,多个线程谁都可以获取。 可以递归访问,多层上锁再解锁。解决优先级反转问题,所谓优先级反转就是低优先级线程拿到资源时,高优先级没法打断只能等待,但是低优先级任务由于优先级过低一直轮不到执行(被不需要资源的中优先级任务抢占)或者执行的时间很少,一直持有着锁,此时高优先级线程不能得到及时执行,系统不再实时。
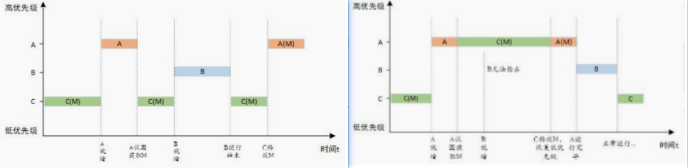
左图:优先级发转,最紧要的高优先级任务A未能最先拿到CPU资源的执行权,系统不实时了。
右图:提高C线程优先级,使得优先级不再发转,保证高优先级A的率先执行权,提高系统实时性。
注意:使用FreeRTOS时,在中断中我们一般不使用互斥锁,因为优先级反转问题不好处理,一般会断言卡死,个人觉得主要原因还是因为同步互斥机制中自旋锁只是关闭了抢占,某一任务获取到锁后,仍会被中断打断去获取释放(即使获取不到,也不会卡死,中断不允许阻塞),此时释放显然违背了互斥锁的所有权。RT-Thread是否如此,有待测试。

// 动态创建
rt_mutex_t rt_mutex_create(const char *name, rt_uint8_t flag);
rt_err_t rt_mutex_delete(rt_mutex_t mutex);
// 静态创建
rt_err_t rt_mutex_init(rt_mutex_t mutex, const char *name, rt_uint8_t flag);
rt_err_t rt_mutex_detach(rt_mutex_t mutex);
// 获取、释放
static rt_err_t _rt_mutex_take(rt_mutex_t mutex, rt_int32_t timeout, int suspend_flag);
rt_err_t rt_mutex_release(rt_mutex_t mutex);
使用基本一样,需要注意的是如果互斥锁已经被当前线程获得,take时则会对持有计数加1,release释放时只有已经拥有互斥锁的线程才能释放它,每释放一次互斥量,持有计数减1,减到零时它变为可用,对应上文的所有权、递归访问特性。
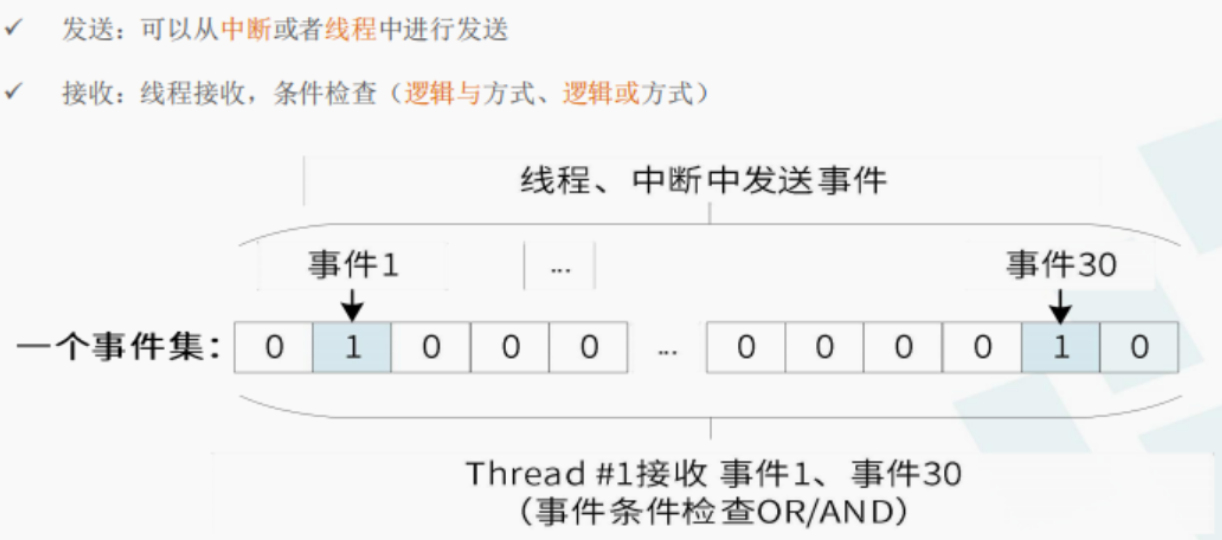
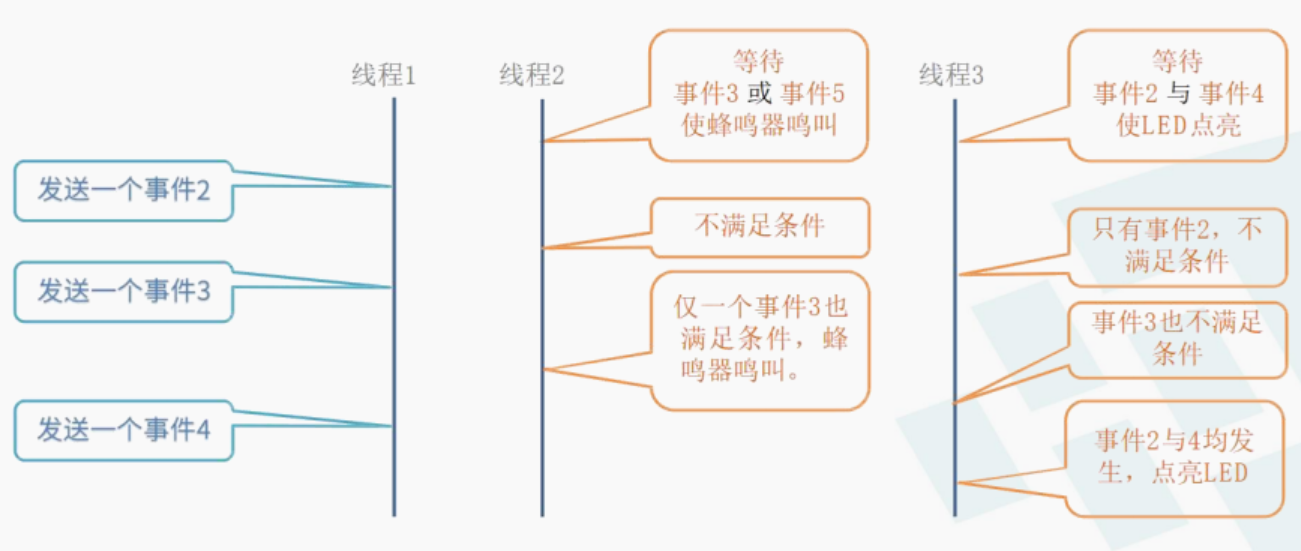
- 事件集:一个32位的整数,每一位代表一个事件,相当于多元信号量。
任务与任务、任务与中断
// 动态创建
rt_event_t rt_event_create(const char *name, rt_uint8_t flag);
rt_err_t rt_event_delete(rt_event_t event);
// 静态创建
rt_err_t rt_event_init(rt_event_t event, const char *name, rt_uint8_t flag);
rt_err_t rt_event_detach(rt_event_t event);
// 发送、接收
rt_err_t rt_event_send(rt_event_t event, rt_uint32_t set); // 唤醒
rt_err_t rt_event_recv(rt_event_t event, // 句柄
rt_uint32_t set, // 关心事件
rt_uint8_t option, // RT_EVENT_FLAG_AND、RT_EVENT_FLAG_OR
rt_int32_t timeout,
rt_uint32_t *recved); // 事件接到状态
使用rt_event_recv()时,系统根据set和option判断要接收事件集是否发生。若发生,根据option上是否有RT_EVENT_FLAG_CLEAR来决定是否重置各事件标志位,recved返回接收到的事件集;若未发生,则把set和option参数跳入线程控制块中,然后挂起线程在此事件集上,等待唤醒。
通信
消息邮箱、消息队列,注意并不是说消息邮箱、消息队列不能作为同步机制,只是不会传递这么复杂的结构体来只是为了进行同步。
- 消息邮箱:用于实现
任务与任务之间、任务与中断处理程序之间的通信。开销低,效率较高

// 动态创建
rt_mailbox_t rt_mb_create(const char *name, rt_size_t size, rt_uint8_t flag);
rt_err_t rt_mb_delete(rt_mailbox_t mb);
// 静态创建
rt_err_t rt_mb_init(rt_mailbox_t mb,
const char *name,
void *msgpool,
rt_size_t size,
rt_uint8_t flag);
rt_err_t rt_mb_detach(rt_mailbox_t mb);
// 发送、等待发送(因为邮箱满了)、紧急发送、接收
rt_err_t rt_mb_send(rt_mailbox_t mb, rt_ubase_t value);
rt_err_t rt_mb_send_wait(rt_mailbox_t mb, rt_ubase_t value, rt_int32_t timeout);
rt_err_t rt_mb_urgent(rt_mailbox_t mb, rt_ubase_t value);
rt_err_t rt_mb_recv(rt_mailbox_t mb, rt_ubase_t *value, rt_int32_t timeout);
内存的大小等于邮件大小(固定4字节,可以为一个指针来传递大量数据)与邮箱容量的乘积。
- 消息队列:相比于裸机中的全局变量,操作系统中为了更好的管理不同任务之间的消息传递引入了消息队列的机制。
任务与任务、任务与中断
RT-Thread这里与我以往所接触的最大不同是,其可以接收不定长数据。
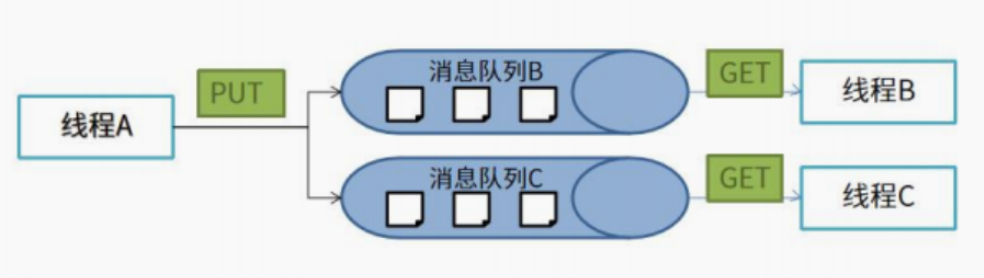
线程可以将一条或者多条消息放到一个或者多个消息队列中,同样一个线程或者多个线程也可以从一个或多个消息队列中获取消息,同时消息队列提供异步处理机制可以起到缓冲消息的作用。
// 动态创建
rt_mq_t rt_mq_create(const char *name, // 名字
rt_size_t msg_size, // 一条消息最大长度
rt_size_t max_msgs, // 消息队列的最大个数
rt_uint8_t flag); // RT_IPC_FLAG_FIFO or RT_IPC_FLAG_PRIO
rt_err_t rt_mq_delete(rt_mq_t mq);
// 静态创建
rt_err_t rt_mq_init(rt_mq_t mq, //
const char *name,
void *msgpool,
rt_size_t msg_size,
rt_size_t pool_size,
rt_uint8_t flag);
rt_err_t rt_mq_detach(rt_mq_t mq);
// 发送、等待发送(因为队列满了)、紧急发送、接收
rt_err_t rt_mq_send(rt_mq_t mq, const void *buffer, rt_size_t size);
rt_err_t rt_mq_send_wait(rt_mq_t mq, const void *buffer, rt_size_t size,
rt_int32_t timeout);
rt_err_t rt_mq_urgent(rt_mq_t mq, const void *buffer, rt_size_t size);
rt_ssize_t rt_mq_recv(rt_mq_t mq, void *buffer, rt_size_t size, rt_int32_t timeout);
API接口跟消息邮箱基本一致。
当创建消息队列时会先从对象管理器中分配一个rt_mq消息队列对象,然后分配内存空间组织成空闲消息链表,这块内存的大小 = 【最大消息大小 + 消息头(用于链表链接)的大小】* 消息队列最大个数,接着初始化消息队列。
当发送消息时,消息队列对象先从空闲消息链表上取下一个空闲消息块,然后把线程或者中断的消息内容复制到消息块上,最后把消息块挂到消息队列的尾部,当空闲消息链表上无可用消息块时,则说明消息队列已满。
注意:发送、接收中的参数size,需使用创建时的msg_size值,即一条消息最大长度,而不是实际值来接收发送不定长数据。
官网示例demo
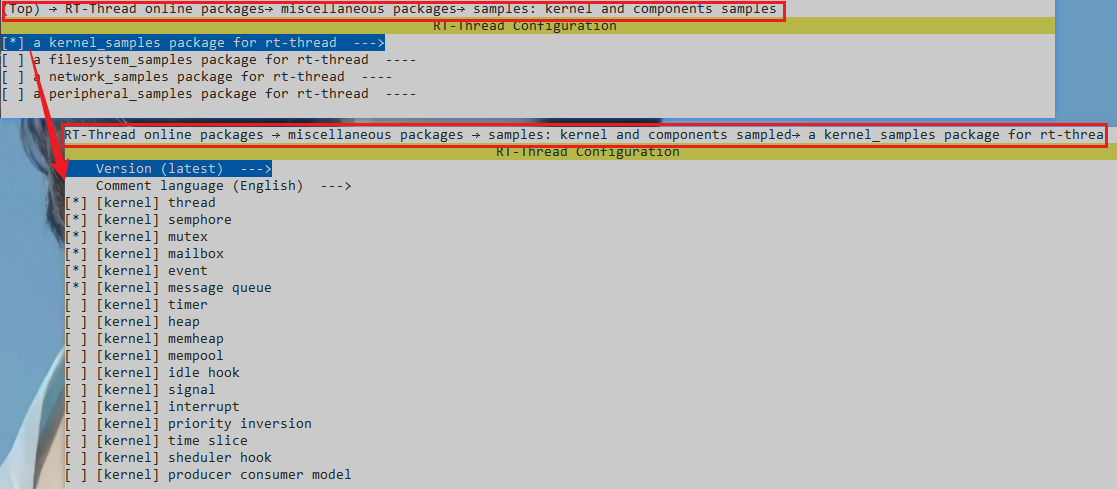
对于这些内核机制,官方已经提供了非常详细的demo参考,我们可以通过menuconfig进行配置。
选择需要的kernel_samples_package后,执行pkgs --update下载最新软件包,便可以在工程packages下看到相关文件,如:.\packages\kernel_samples-latest\en\semaphore_sample.c
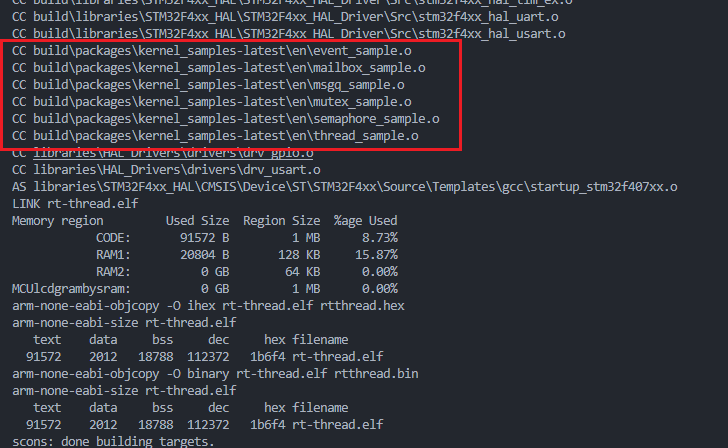
通过scons -j12编译,则可以发现相关demo已经加入了构建之中。
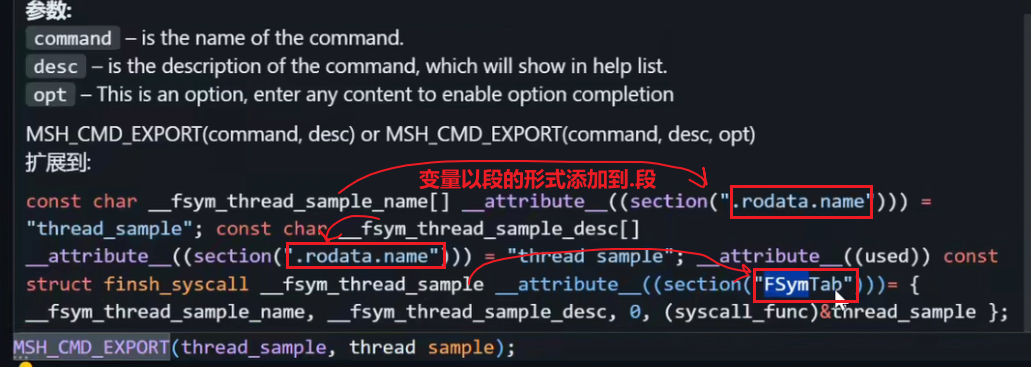
F5烧录运行,进入MSH界面,Tab键即可查看,随便选择一个输入执行,如:semaphore_sample,注意这个MSH_CMD_EXPORT导出的函数没有结束,只能手动硬件复位,具体代码内容大家自行查阅学习吧!!!
- 官方demo示例中多次用到MSH_CMD_EXPORT,那么它是干什么的? 为什么通过semaphore_sample就能执行semaphore_sample函数呢?
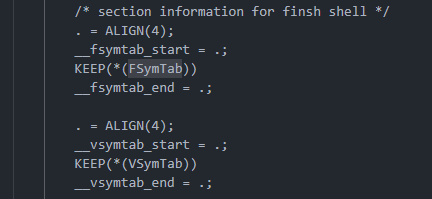
本质就是把函数的地址放到了RT-Thread特定的管理段,通过link.lds脚本可以看到相关内容,使得最终可以在终端打印段中内容即函数地址。
四、参考资料与说明
参考内容过多,如有侵权请联系作者。















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









