






大家好我是AIGC小王!
Stable Diffusion 3是由Stability AI公司开发的一款开源图像生成模型,它基于深度学习技术,能够在没有任何人类指导的情况下生成高质量、逼真的图像。与传统的图像生成技术相比,Stable Diffusion 3具有更高的生成质量和更快的生成速度。
为什么要在本地部署Stable Diffusion 3?
更好的性能:本地部署可以充分利用你电脑的硬件资源,提供更好的性能和更快的生成速度。
更安全:本地部署可以避免将你的数据上传到云端,从而保护你的隐私和数据安全。
更好的可控性:本地部署可以让你更好地控制模型的训练和生成过程,从而更好地满足你的需求。
但是下载模型需要先登录Hugging Face账户,并签署一份许可协议
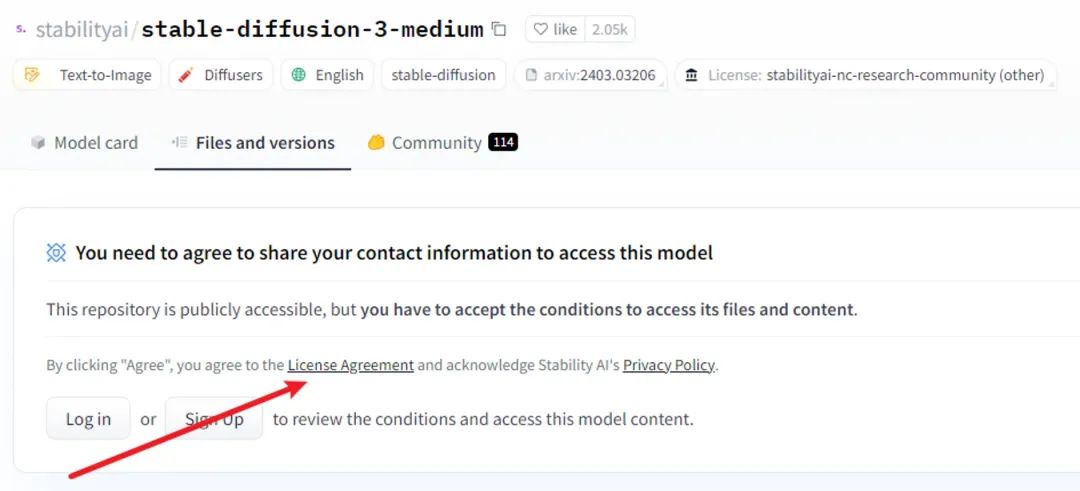
签署完毕之后就可以看到整个项目的文件列表了
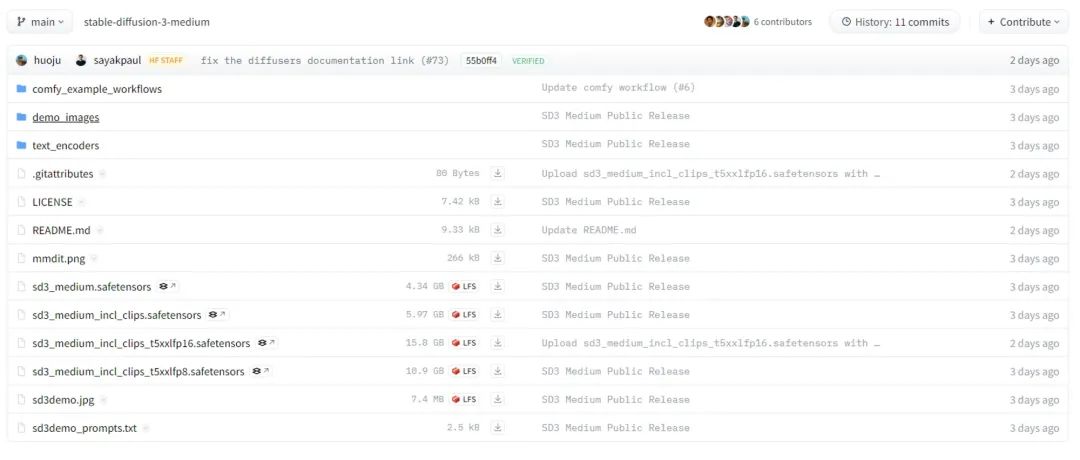
上面的文件大致可以分为三部分:
1、comfy_example_workflows
这部分主要是三份Comfyui的工作流文件,下面会用到。
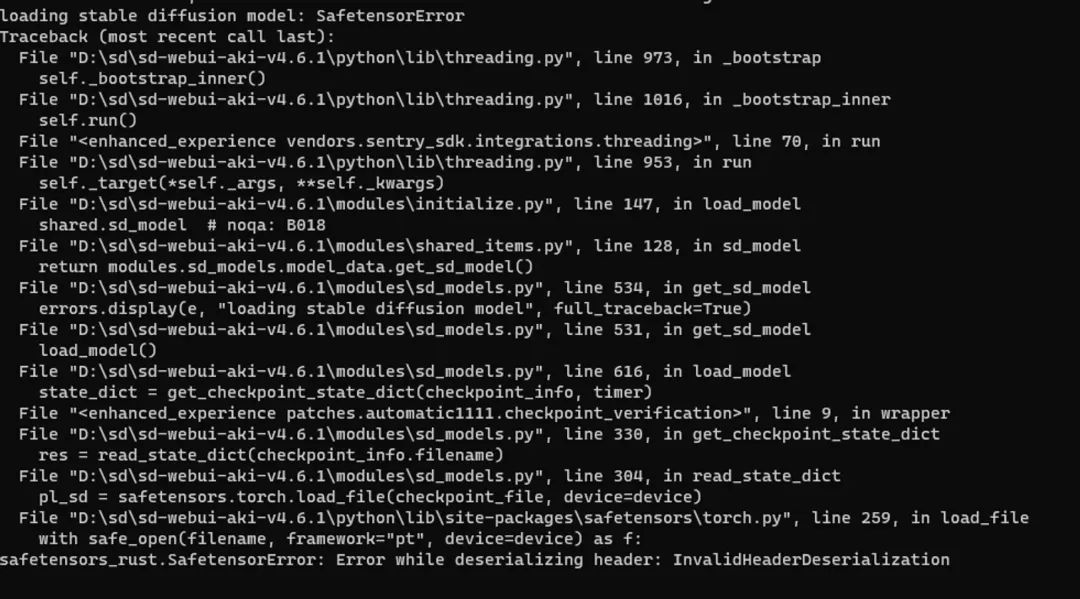
之所以用Comfyui,是因为目前(截止到文章发布时间)的Stable diffusion webui 还没支持SD3,所以并没办法运行SD3的大模型,我也浅试了一下,用目前的 Stable diffusion webui 加载 sd3_medium.safetensors ,但报这样的错。
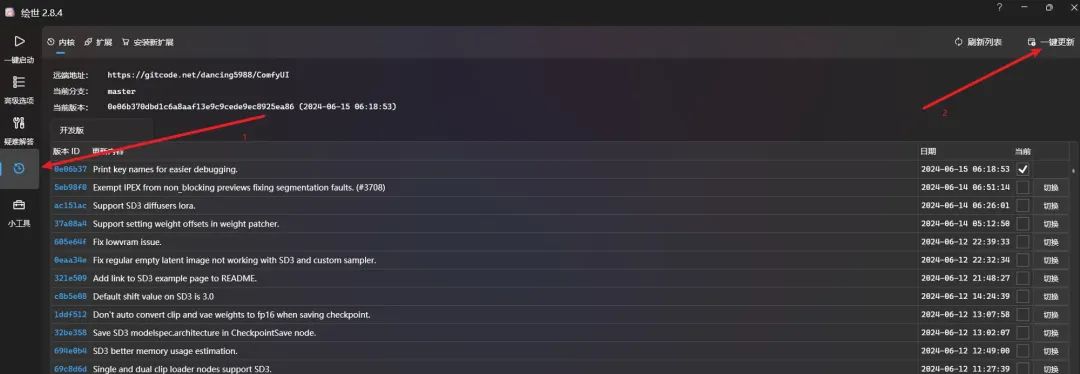
而Comfyui 目前已经支持了,不过需要注意升级内核版本,低版本的也是不支持的,可以从下面的图片中看到,6月11号的版本才刚开始支持SD3(可见Comfyui很早就收到消息)。
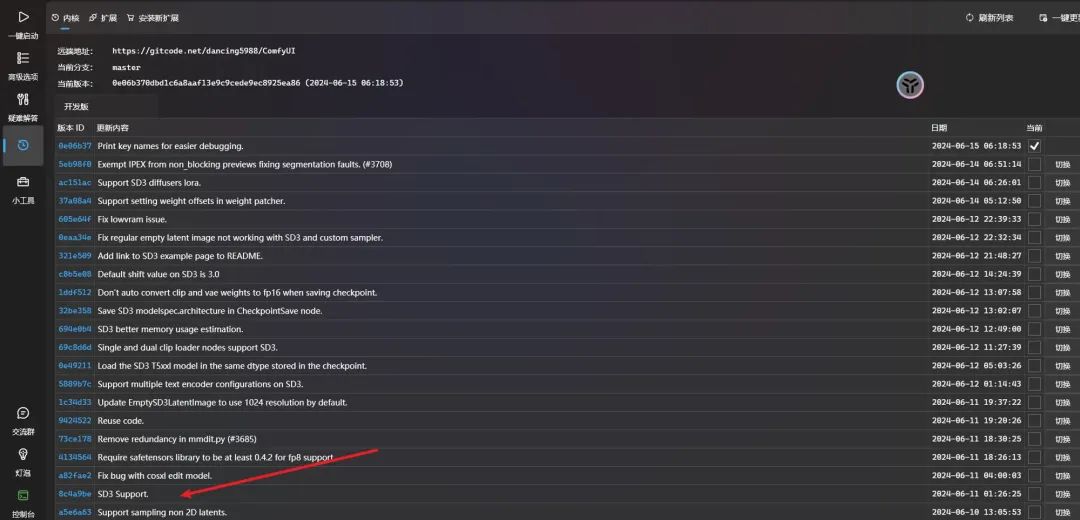
我个人不太建议就只升到 8c4a9be这个版本,因为后续的发布说明其实还有很多关于SD3的更新,可见 8c4a9be 只是一个比较粗糙的版本,我个人是直接升到了最新版。
2、text_encoders
text_encoders里面有四个模型文件,分别是:
├── text_encoders/
│ ├── clip_g.safetensors
│ ├── clip_l.safetensors
│ ├── t5xxl_fp16.safetensors
│ └── t5xxl_fp8_e4m3fn.safetensors
这里面是三种不同的文本编码器,即两个CLIP模型和T5模型,其中T5模型还提供了两个量化版本,一个16位量化(fp16),一个是8位量化(fp8)。
这里补充一下,**CLIP 模型[1]**最初由 OpenAI开发,它是一个多模态预训练模型,能够理解图像和文本之间的关系。CLIP 通过在大量的图像和文本对上进行训练,学习到了一种能够将文本描述和图像内容对齐的表示方法。这种表示方法使得 CLIP 能够理解文本描述的内容,并将其与图像内容进行匹配。
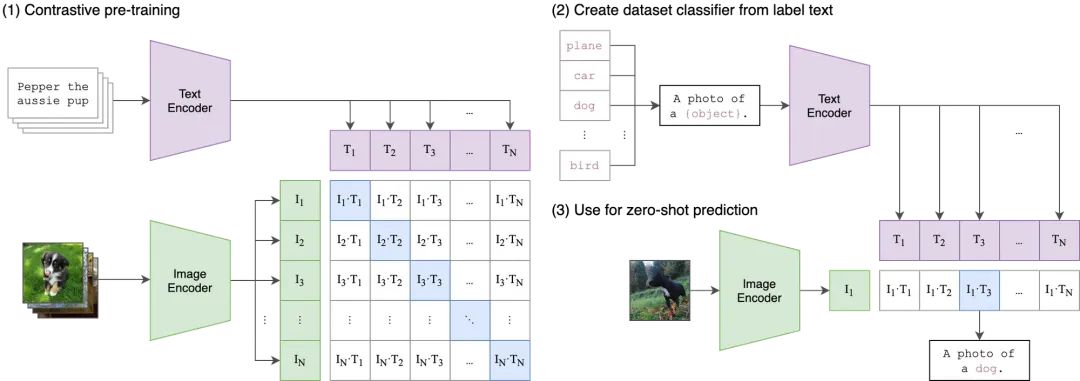
简单来说,**CLIP[2]**就是将我们的提示词转化为SD模型能够理解的“语言”(向量),从而让SD模型知道要生成怎样的图片。
3、checkpoints
本次SD3一共公开了四个大模型,分别是:
├── sd3_medium.safetensors (4.34G)
├── sd3_medium_incl_clips.safetensors (5.97 G)
├── sd3_medium_incl_clips_t5xxlfp8.safetensors (10.9G)
└── sd3_medium_incl_clips_t5xxlfp16.safetensors (15.8G)
sd3_medium.safetensors 就是一个比较纯粹的底模,只包含了 MMDiT和 VAE 的相关权重,但是不包含我们上面第2点提到的任何一个文本编码器。
sd3_medium_incl_clips.safetensors 则是 sd3_medium + clip_g + clip_l 的结合体,这个模型体积会小点,但是没有T5XXL编码器的模型性能会有所不同。
sd3_medium_incl_clips_t5xxlfp8.safetensors 则是 sd3_medium + clip_g + clip_l + t5xxl_fp8_e4m3fn 的结合体,是一个在质量和资源要求之间取得平衡的模型。
sd3_medium_incl_clips_t5xxlfp16.safetensors 则是 sd3_medium + clip_g + clip_l + t5xxl_fp16 的结合体,质量应该会高些,但是占用的显存也是最高的。
接下来就进入到实操的环节了,如果已经装过Comfyui的朋友可以跳过第一部分。
一、安装Comfyui
第一步是下载安装包,这里我准备了夸克网盘和百度网盘两种形式(安装包和相关资料可文末扫描获取)
第二步就是解压安装,双击启动器,启动器的布局是和之前的SD启动器是基本差不多的

启动成功后,点击一键启动,出现这个画面就成功了一半了
第三步是升级内核版本,如果已经升级过的朋友可跳过
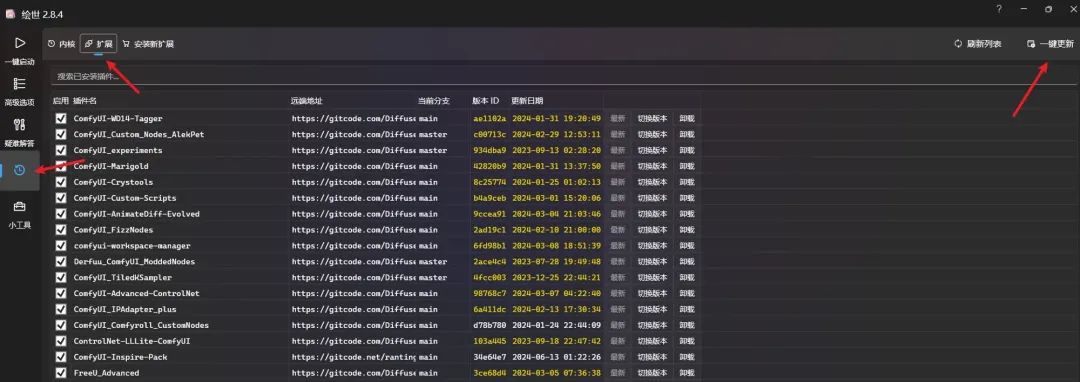
我这边是直接升到了最新版,包括扩展版本也都是升到了最新
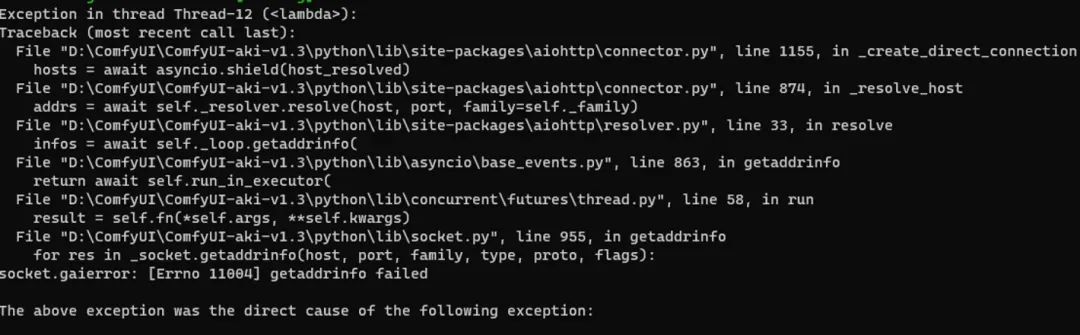
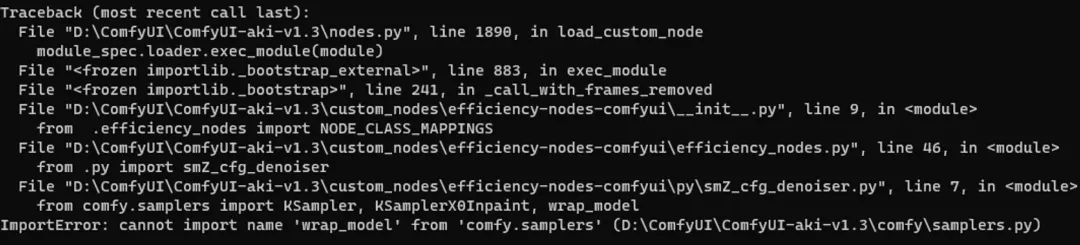
我这边启动的时候会有一些报错(可能是升了版本导致),但是实际测试后对SD3的出图不影响
二、下载模型
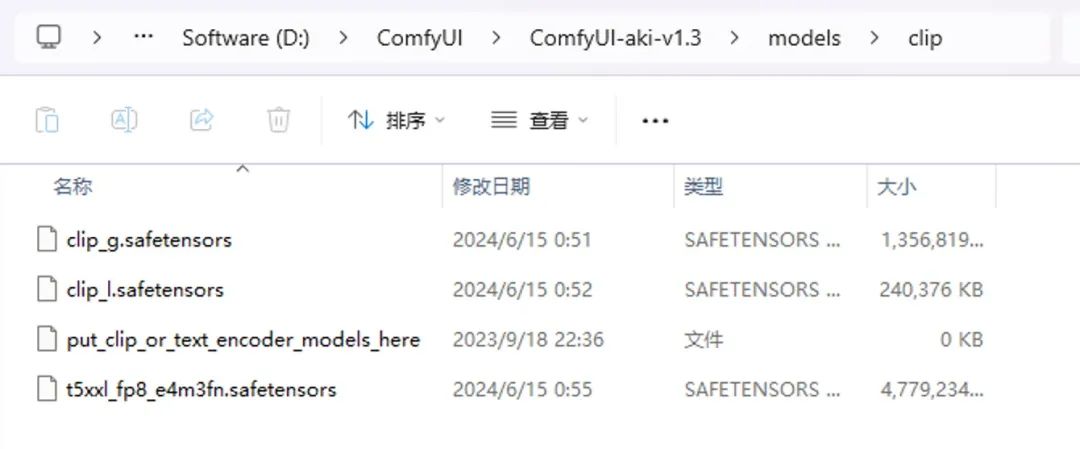
本次我们并不需要用到上述所有模型,只需要用到这四个模型即可:
-
sd3_medium.safetensors
-
clip_g.safetensors
-
clip_l.safetensors
-
t5xxl_fp8_e4m3fn.safetensors
下载完毕后将 sd3_medium.safetensors 放入 models\checkpoints 文件夹,其余三个放入 models\clip 文件夹即可
三、导入工作流
这里用到的是 comfy_example_workflows文件夹下面的 sd3_medium_example_workflow_basic.json
点击左上角的文件夹图标,会弹出一个工作流文件列表
点击 Import 导入前面的 sd3_medium_example_workflow_basic.json 文件
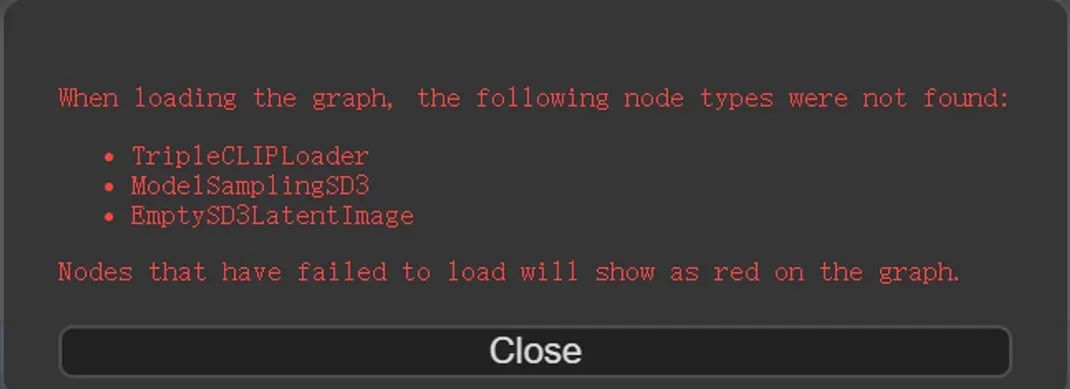
如果你是先导入工作流,没有放模型,可能会有这样的提示,其实就是告知你模型加载失败,或者你的内核版本没有升级也会导致
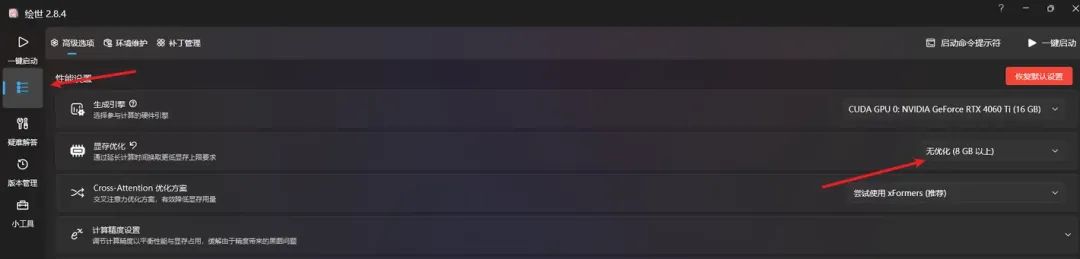
其次你可能还要调整显存优化的选项,不然出图可能会失败(看个人显存情况)
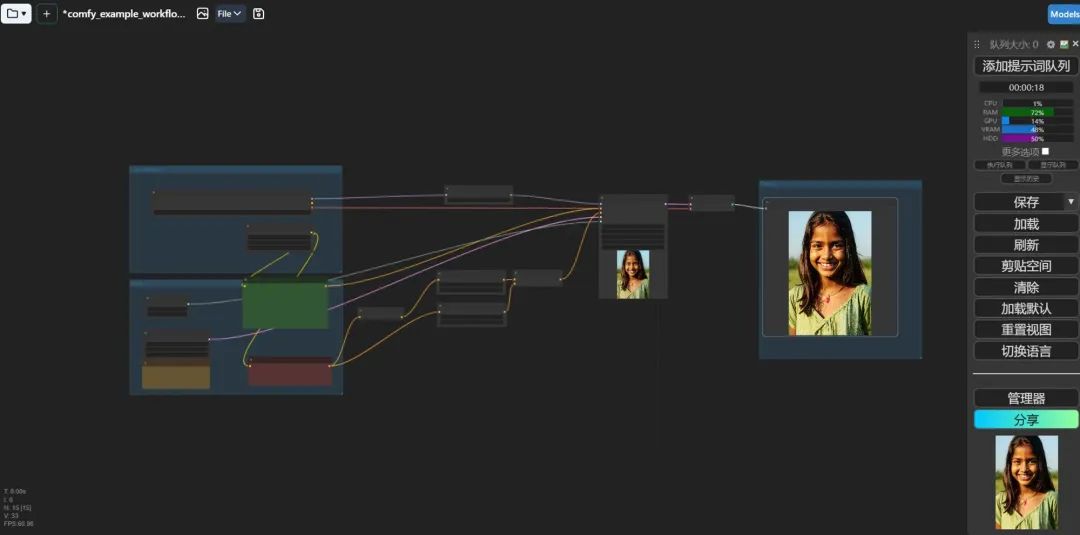
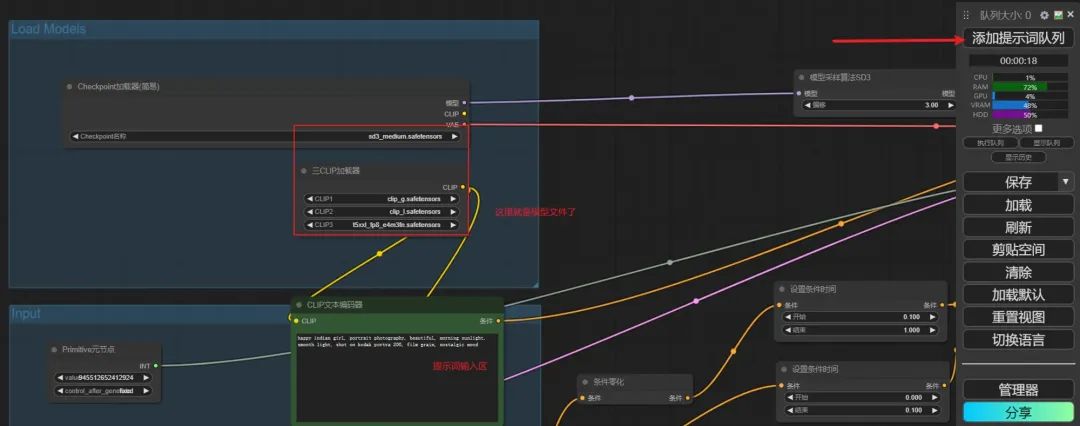
最后就是点击 “添加提示词队列” 按钮就会生成图片了
四、测试效果
我这里在面部绘画、手部绘画、字体书写排版、全身照、动物、植物都做了一个简单的对比,使用的SDXL(加了Refiner)和SD3进行对比,并控制图片尺寸大小都是1024,但是在一些细节参数(CFG Scale)还是略有差异,下面请看VCR。
注:左边的照片都是SDXL生成,右边都是SD3生成
4.1 面部绘画
提示词:happy indian girl,portrait photography,beautiful,morning sunlight,smooth light,shot on kodak portra 200,film grain,nostalgic mood,

个人看法:SDXL稍微略逊一筹,因为看起来是一个小女孩,脸部却像一个中年妇女,不是很匹配
4.2 手部绘画
提示词:a girl sitting in the cafe, play guitar,comic, graphic illustration, comic art, graphic novel art, vibrant, highly detailed, colored, 2d minimalistic

个人看法:SDXL还是差一点,双腿绘画明显有问题,手部SD3稍微好点,但是也没有那么惊艳
4.3 字体书写排版
SD3提供的提示词:A vibrant street wall covered in colorful graffiti, the centerpiece spells “SD3 MEDIUM”, in a storm of colors

之前用的提示词:Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says “Stable Diffusion 3” made out of colorful energy

个人看法:从上面两组图可以看出,SD3的字体书写能力确实是高出SDXL一大截的,但是也不能保证很完美。
4.4 全身照
提示词:a full body portrait of an old hipster man with a ponytail, cigar in mouth, smoke, badass

个人看法:这里我其实是想让他们画全身照的,SD3稍微理解好一点,但是风格上我更喜欢SDXL
提示词:Editorial portrait,full body,1male,dynamic pose,futuristic fashion,cinematic,

个人看法:感觉差不多,但是SD3画出了全身
4.5 植物
提示词:a frozen cosmic rose, the petals glitter with a crystalline shimmer, swirling nebulas, 8k unreal engine photorealism, ethereal lighting, red, nighttime, darkness, surreal art

4.6 拟人化动物
提示词:full body,cat dressed as a Viking,with weapon in his paws,battle coloring,glow hyper-detail,hyper-realism,cinematic

资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









