







蛇年已至,OpenKG衷心感谢大家的信任与支持。过去一年,我们一同见证了开源和知识图谱的力量。新的一年,愿你继续关注和支持OpenKG社区,巳巳如意,助力知识增强大模型,开启更加精彩的旅程!

导读
OpenKG新开设“TOC专家谈”栏目,推送OpenKG TOC(技术监督委员会)专家成员的观点文章。本期邀请到同济大学王昊奋特聘研究员介绍大模型时代的知识图谱年度进展报告,本文整理自王昊奋老师在“OpenKG年会”上的分享。
本报告深入梳理了2024年大模型与知识图谱协同发展的显著成果。大模型以其卓越的理解生成能力、少样本学习及泛化优势,助力知识图谱在抽取与推理环节突破瓶颈,显著提升知识图谱的准确性和全面性,解决了信息挖掘不充分、推理能力有限等问题。知识图谱则凭借结构化信息与严谨逻辑推理,增强大模型在问答和规划任务中的表现,提高模型可解释性,降低幻觉等错误,弥补慢思考和规划不足。神经符号迭代交互的探索,为二者深度融合与推理能力提升开辟新途径。报告还盘点了OpenKG在数据、模型、工具方面的积累,并预测知识图谱和大模型在2025年及未来深度融合的发展趋势。
大模型时代的知识图谱技术进展

在知识图谱构建方面,中国科学院计算技术研究所网络数据科学与技术重点实验室研发了知码大模型(KnowCoder)。该模型利用形式化编程语言统一表示结构化知识,实现了符号化知识图谱与神经网络大模型的完美结合,从而在统一知识抽取方面取得了突破,大大提升了知识抽取的精确度与泛化性。

针对大型语言模型在信息提取任务上难以应对复杂指令的问题,清华大学提出了ADELIE,通过利用包含83,000多个实例的专业数据集IEInstruct,并结合监督微调和直接偏好优化(DPO)策略,增强大型语言模型在信息抽取任务上的性能,使其在封闭式和开放式信息抽取任务中均取得显著成果。

在大模型推理方面,来自澳大利亚格里菲斯大学等机构的学者在综述中以知识图谱的补全作为经典的推理任务,给出了LLM作为编码器和LLM作为生成器两种大语言模型增强知识图谱推理的方式。
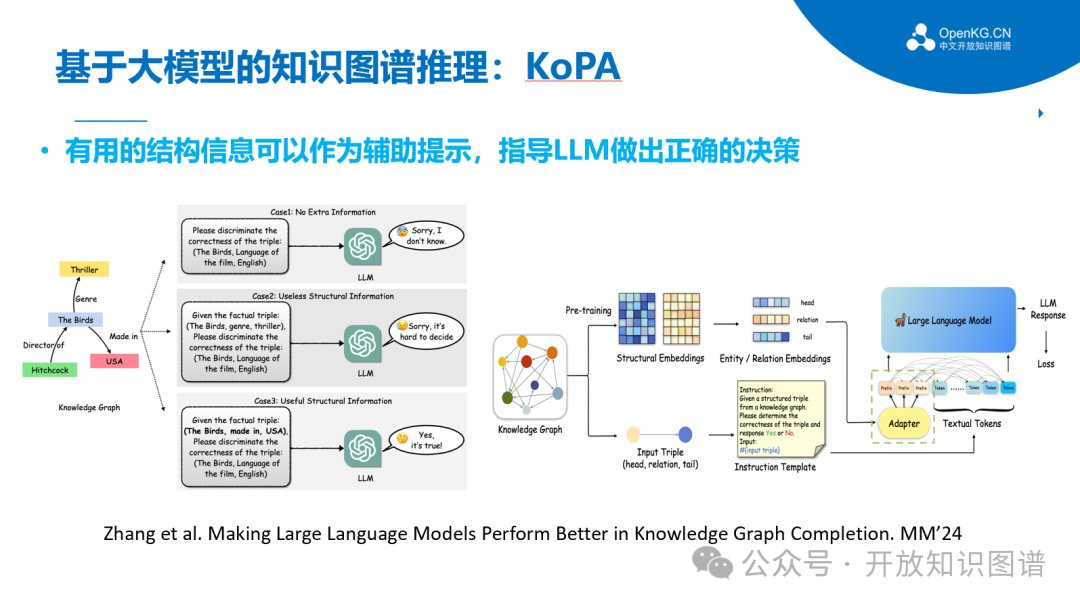
同样在知识图谱补全任务上,浙江大学团队针对现有的LLM方法没有充分利用KG中重要的结构信息,提出知识前缀适配器(KoPA)来实现结构感知推理。KoPA通过预训练理解KG中的实体和关系,并将其表示为结构嵌入向量。然后,KoPA通过知识前缀适配器将这些跨模态结构信息传递给LLM,使其在文本空间中投影并获得虚拟的知识标记作为输入提示的前缀。实验结果表明引入跨模态结构信息可以显著提高LLM的事实推理能力。
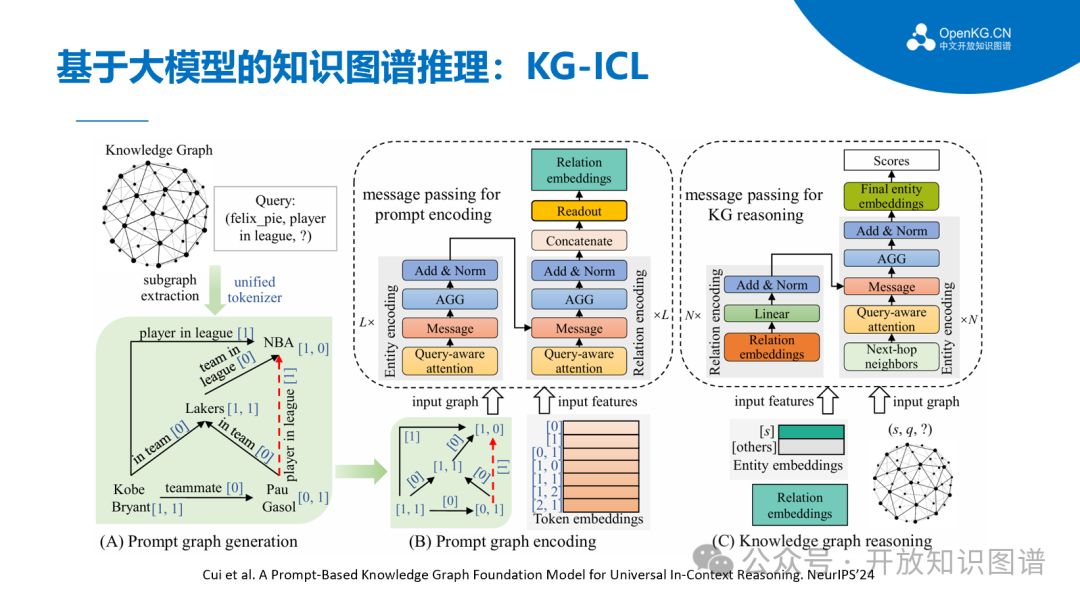
此外,现实世界的知识图谱是动态变化的,然而现有方法大多针对静态图谱,无法有效应对图谱的更新与变化。为此,南京大学团队提出了一种基于上下文提示的通用推理模型KG-ICL,该模型基于与查询关系相关的提示图(prompt graph)及其编码生成关系的提示向量,并利用提示向量初始化知识图谱中的实体和关系向量,从而避免了对特定实体和关系相关参数的依赖,实现了对新实体、新关系,甚至新图谱的通用泛化。与传统方法相比,KG-ICL 不需要为每个新的知识图谱重新训练,实现了图谱级的强泛化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









