







参考资料:
Python3的urllib.parse常用函数小结
data=bytes(urllib.parse.urlencode({"name":"Jack"}),encoding="utf-8") #不理解
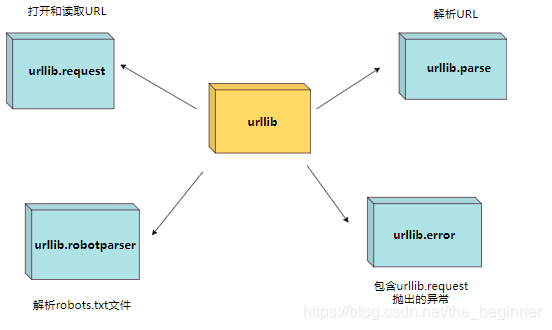
urllib.parse
urlparse(将url解析为组件,url必须以http://开头)
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme=’’, allow_fragments=True)
urlstring 为 字符串的 url 地址,
scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
from urllib.parse import urlparse
o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
print(o)
运行结果:
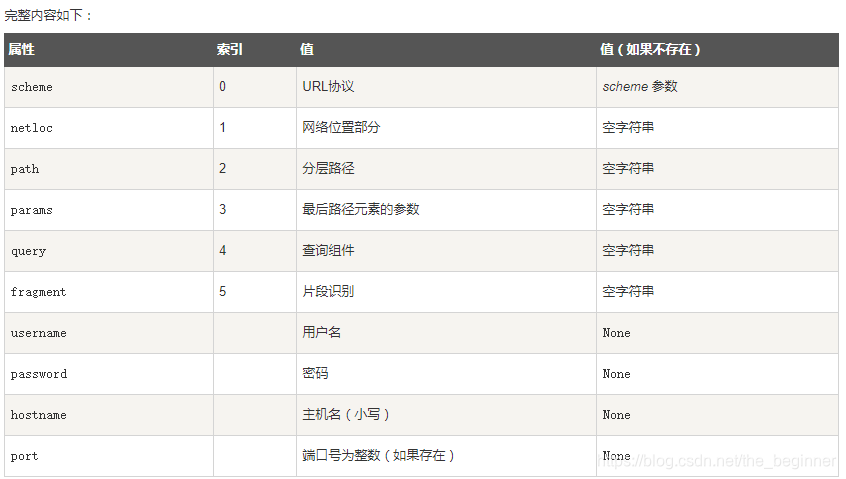
ParseResult(scheme='https', netloc='www.runoob.com', path='/', params='', query='s=python+%E6%95%99%E7%A8%8B', fragment='')
从结果可以看出,内容是一个元组,包含 6 个字符串:协议,位置,路径,参数,查询,判断。
我们可以直接读取协议内容:
from urllib.parse import urlparse
o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
print(o.scheme)
urlencode
参考资料:
Python之urlencode()使用
bytes
Python3 bytes 函数
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
url="http://httpbin.org/post"
data=bytes(urllib.parse.urlencode({"name":"Jack"}),encoding="utf-8") #不理解
headers = {'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'} #字典类型
req=urllib.request.Request(url=url,data=data,headers=headers,method="POST")
# req=urllib.request.Request(url=url,headers=headers,method="POST")
response=urllib.request.urlopen(req)
# print(response.read().decode("utf-8"))
print(data)
运行结果:
b'name=Jack'

















 7707
7707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









