






一、研究背景与核心问题
1.1 视觉文档处理的挑战
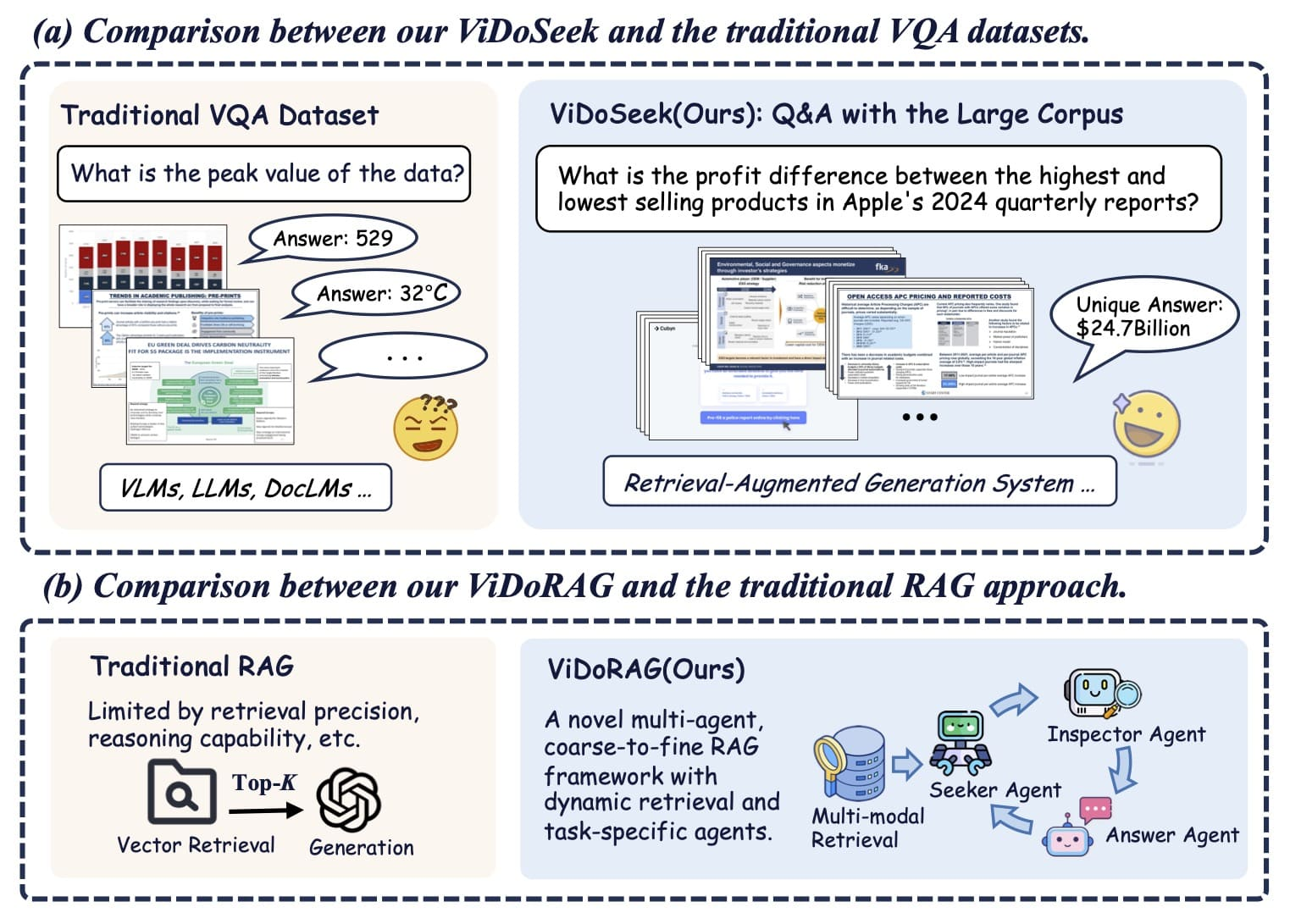
- 传统RAG的局限:现有检索增强生成(RAG)方法主要面向纯文本,对含图表、表格、流程图等视觉丰富文档(Visually Rich Documents, VRD) 的处理效率低下。
- 数据集缺陷:主流VQA数据集(如PlotQA、DocVQA)仅支持单图像/单文档问答,无法评估大规模跨文档检索能力(见表1对比)。
- 关键瓶颈:
- 模态割裂:文本OCR检索忽略视觉特征,纯视觉检索丢失语义信息。
- 推理不充分:固定Top-K检索导致噪声干扰或信息缺失,VLMs(视觉语言模型)在长上下文中的推理能力未被充分激活。
1.2 研究目标
构建面向大规模视觉文档库的RAG框架,实现:
- 高效跨模态检索:融合文本与视觉特征。
- 深度迭代推理:通过多智能体协作提升答案准确性。
- 可扩展评估基准:提出首个支持多文档检索的VRD数据集ViDoSeek。
二、核心创新:ViDoRAG框架
2.1 多模态混合检索(Multi-Modal Hybrid Retrieval)
- 动态自适应召回(GMM策略):
- 问题:固定Top-K检索导致噪声或信息遗漏。
- 方案:基于高斯混合模型(GMM)动态计算相似度分布,自动确定最优K值:
K={pi∈C∣pi∼N(μT,σT2)} - 优势:平均检索页数从10页降至6.76页,准确率提升0.7%(见表5)。
- 文本-视觉特征融合:
- 并行执行OCR文本检索(NV-Embed-V2)与视觉嵌入检索(ColQwen2)。
- 按原始页面顺序合并结果,保留空间关联性:
Rhybrid=Sort[F(RText,RVisual)]
2.2 多智能体迭代推理(Multi-Agent Generation)
-
三阶段智能体协作框架(见图3):
智能体 功能描述 技术亮点 Seeker 快速浏览缩略图,初步筛选相关图像 基于ReAct改进,结合Inspector反馈迭代优化选择:It+1c,Mt+1=Θ(Itc,Q,Mt,Ft−1) Inspector 高分辨率审查图像,生成草稿答案或反馈需求 动态决策:提供反馈 Ft 或草稿答案 A^(公式6-7) Answer 验证答案一致性,输出最终结果 基于参考图像修正草稿:A=Θ(Iref,Q,A^) -
核心价值:
- 降低噪声干扰:Inspector仅处理Seeker筛选的高价值图像。
- 激活深度推理:迭代机制提升VLMs在复杂问题(如多跳推理)的表现。
三、ViDoSeek数据集:填补评估空白
3.1 构建流程(见图2)
- 文档收集:从12个领域(经济、技术等)筛选300份含图表/布局的英文幻灯片(25-50页)。
- 查询设计:专家构建需跨文档检索的唯一答案问题(如布局类问题占比64%)。
- 质量审查:VLM辅助过滤模糊查询,确保答案唯一性。
- 多模态修正:GPT-4o优化查询表述,增强指向性(见图9-10提示词)。
3.2 核心优势(表1, 表6)
| 特性 | ViDoSeek | 传统数据集(如SlideVQA) |
|---|---|---|
| 文档规模 | 多文档(约6k图像) | 单文档 |
| 问题类型 | 文本/图表/表格/布局 | 有限视觉类型 |
| 推理需求 | 单跳+多跳(43.5%) | 侧重单跳 |
| 答案唯一性 | 强制全局唯一 | 可能多文档重复 |
四、实验验证与性能突破
4.1 主要结果(表2)
- SOTA性能:ViDoRAG在ViDoSeek上超越最佳基线10%以上。
- 关键发现:
- 模态互补性:视觉检索在文本类问题表现优于纯文本检索(Qwen-VL: 84.9% vs 78.7%)。
- 布局类优势:ViDoRAG在最具挑战的布局类问题提升显著(Llama3: 74.7% vs 45.9%)。
- 开源模型适配:Qwen-VL-7B+ViDoRAG接近GPT-4o基线(69.1% vs 72.1%)。
4.2 消融实验(表4)
| 组件 | 贡献度 | 典型效果 |
|---|---|---|
| 动态检索(GMM) | ★★★ | 准确率↑0.7%,检索页数↓30% |
| 多智能体推理 | ★★☆ | 多跳问题准确率↑12% |
| 混合检索 | ★★☆ | 召回率@5达95.1%(表3) |
4.3 效率权衡(图5,7)
- 延迟增加:多智能体迭代使GPT-4o延迟增加37%,但准确率提升16%。
- 推理效率:强模型(如GPT-4o)需更少迭代轮次,验证框架普适性。
五、局限性与未来方向
- 查询偏差风险:专家构建的查询可能缺乏自然语言多样性(§Limitations)。
- 计算开销:多智能体迭代增加延迟(严格实时场景受限)。
- 幻觉问题:VLMs可能生成未基于检索结果的错误答案。
- 泛化性:当前框架在非幻灯片类文档(如扫描件)的适用性待验证。
未来工作:
- 优化延迟(智能体并行化)
- 探索跨域泛化(金融/教育场景)
- 集成反幻觉机制
六、总结
ViDoRAG通过多模态混合检索与多智能体迭代推理,首次系统解决视觉文档的大规模检索与深度推理问题。ViDoSeek数据集的发布填补了评估空白,实验验证中10%的性能跃迁标志着VRD处理进入新阶段。尽管存在计算开销等挑战,其模块化设计为后续研究提供坚实基础,在知识密集型场景(如学术研究、商业分析)具有明确应用前景。
附:核心图表索引
- 图1:ViDoRAG与传统方法对比
- 图3:框架工作流
- 表2:多模型性能对比
- 图6:跨查询类型性能分析
- 表5:动态检索效率验证
如需进一步探讨技术细节或应用场景,欢迎随时追问!


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











