







文章目录
前言
近来,deepseek火爆流行,席卷中国行业,引发了rag相关的智能体agent。然而,理解视觉丰富的文档中的信息对于传统的检索增强生成(Retrieval-Augmented Generation, RAG)方法来说仍然是一个重大挑战。现有的基准主要集中在基于图像的问题回答(QA),而忽视了在密集的视觉文档中进行高效检索、理解和推理的基本挑战。为了弥合这一差距,我们引入了ViDoSeek,一个旨在评估RAG在需要复杂推理的视觉丰富文档上性能的新数据集。为此,本篇文章解读ViDoRAG论文。

代码链接: https://github.com/Alibaba-NLP/ViDoRAG
参考解读文章:https://zhuanlan.zhihu.com/p/29145498785
摘要
Understanding information from visually rich documents remains a significant challenge for traditional Retrieval-Augmented Generation (RAG) methods. Existing benchmarks predominantly focus on image-based question answering (QA), overlooking the fundamental challenges of efficient retrieval, comprehension, and reasoning within dense visual documents. To bridge this gap, we introduce ViDoSeek, a novel dataset designed to evaluate RAG performance on visually rich documents requiring complex reasoning. Based on it, we identify key limitations in current RAG approaches: (i) purely visual retrieval methods struggle to effectively integrate both textual and visual features, and (ii) previous approaches often allocate insufficient reasoning tokens, limiting their effectiveness. To address these challenges, we propose ViDoRAG, a novel multi-agent RAG framework tailored for complex reasoning across visual documents. ViDoRAG employs a Gaussian Mixture Model (GMM)-based hybrid strategy to effectively handle multi-modal retrieval. To further elicit the model’s reasoning capabilities, we introduce an iterative agent workflow incorporating exploration, summarization, and reflection, providing a framework for investigating test-time scaling in RAG domains. Extensive experiments on ViDoSeek validate the effectiveness and generalization of our approach. Notably, ViDoRAG outperforms existing methods by over 10% on the competitive ViDoSeek benchmark.
理解视觉丰富的文档中的信息对于传统的检索增强生成(Retrieval-Augmented Generation, RAG)方法来说仍然是一个重大挑战。现有的基准主要集中在基于图像的问题回答(QA),而忽视了在密集的视觉文档中进行高效检索、理解和推理的基本挑战。为了弥合这一差距,我们引入了ViDoSeek,一个旨在评估RAG在需要复杂推理的视觉丰富文档上性能的新数据集。基于此,我们确定了当前RAG方法的一些关键局限:(i) 纯视觉检索方法难以有效整合文本和视觉特征,以及(ii) 之前的方法往往分配的推理令牌不足,限制了它们的有效性。为了解决这些挑战,我们提出了ViDoRAG,一种新型的多代理RAG框架,专为视觉文档间的复杂推理设计。ViDoRAG采用基于高斯混合模型(Gaussian Mixture Model, GMM)的混合策略以有效处理多模态检索。为了进一步激发模型的推理能力,我们引入了一个迭代agent工作流程,包括探索、总结和反思,为研究RAG领域的测试时扩展提供了一个框架。在ViDoSeek上的大量实验验证了我们方法的有效性和泛化能力。值得注意的是,ViDoRAG在竞争激烈的ViDoSeek基准上比现有方法高出超过10%。
一、引言
Retrieval-Augmented Generation (RAG) enhances Large Models (LMs) by enabling them to use external knowledge to solve problems. As the expression of information becomes increasingly diverse, we often work with visually rich documents that contain diagrams, charts, tables, etc. These visual elements make information easier to understand and are widely used in education, finance, law, and other fields. Therefore, researching RAG within visually rich documents is highly valuable.
检索增强生成(Retrieval-Augmented Generation, RAG)通过使大型模型(LMs)能够使用外部知识解决问题来提升其性能。随着信息表达变得越来越多样化,我们经常处理包含图表、图表和表格等视觉元素的视觉丰富文档。这些视觉元素使信息更易于理解,并广泛应用于教育、金融、法律等领域。因此,在视觉丰富的文档中研究RAG具有很高的价值。
In practical applications, RAG systems often need to retrieve information from a large collection consisting of hundreds of documents, amounting to thousands of pages. As shown in Fig. 1, existing Visual Question Answering (VQA) benchmarks aren’t designed for such large corpus. The queries in these benchmarks are typically paired with one single image(Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022) or document(Ma et al., 2024), which is used for evaluating Q&A tasks but not suitable for evaluating RAG systems. The answers to queries in these datasets may not be unique within the whole corpus.
在实际应用中,RAG系统通常需要从由数百份文档组成的大型集合中检索信息,这些文档累计达数千页。如图1所示,现有的视觉问答(VQA)基准并非为如此庞大的语料库设计。这些基准中的查询通常与单一图像(Methani等人,2020;Masry等人,2022;Li等人,2024;Mathew等人,2022)或文档(Ma等人,2024)配对,用于评估问答任务,但不适合评估RAG系统。这些数据集中的查询答案在整个语料库中可能不是唯一的。
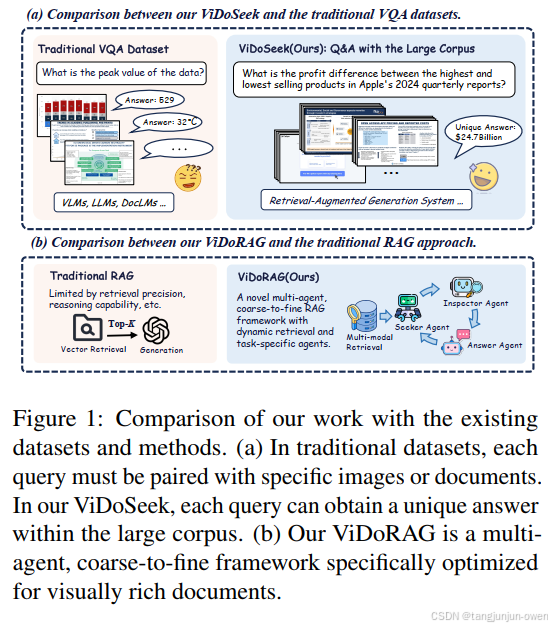
To address this gap, we introduce ViDoSeek, a novel dataset designed for visually rich document retrieval-reason-answer. In ViDoSeek, each query has a unique answer and specific reference pages. It covers the diverse content types and multi-hop reasoning that most VQA datasets include. This specificity allows us to better evaluate retrieval and generation performance separately.
为了弥补这一差距,我们引入了ViDoSeek,一种针对视觉丰富文档检索-推理-回答的新数据集。在ViDoSeek中,每个查询都有一个独特的答案和特定的参考页面。它涵盖了大多数VQA数据集所包含的多种内容类型和多跳推理。这种特定性允许我们更好地分别评估检索和生成性能。
Moreover, to enable models to effectively reason over a large corpus, we propose ViDoRAG, a multi-agent, coarse-to-fine retrieval-augmented generation framework tailored for visually rich documents. Our approach is based on two critical observations: (i) Inefficient and Variable Retrieval Performance. Traditional OCR-based retrieval struggles to capture visual information. With the development of vision-based retrieval, it is easy to capture visual information(Faysse et al., 2024; Yu
et al., 2024a; Zhai et al., 2023). However, there lack of an effective method to integrate visual and textual features, resulting in poor retrieval of relevant content. (ii) Insufficient Activation of Reasoning Capabilities during Generation. Previous studies on inference scaling for RAG focus on expanding the length of retrieved documents(Jiang et al., 2024; Shao et al., 2025; Xu et al., 2023). However, due to the characteristics of VLMs, only emphasizing on the quantity of knowledge without providing further reasoning guidance presents certain limitations. There is a need for an effective inference scale-up method to efficiently utilize specific action spaces, such as resizing and filtering, to fully activate reasoning capabilities.
此外,为了使模型能够有效地在一个大型语料库上进行推理,我们提出了ViDoRAG,一个专为视觉丰富文档设计的多代理粗到细检索增强生成框架。我们的方法基于两个关键观察:(i) 检索性能的低效性和可变性。传统的基于OCR的检索难以捕捉视觉信息。随着基于视觉的检索的发展,捕获视觉信息变得容易(Faysse等人,2024;Yu等人,2024a;Zhai等人,2023)。然而,缺乏有效的方法整合视觉和文本特征,导致相关内容检索不佳。(ii) 生成期间推理能力的激活不足。关于RAG推理解析扩展的先前研究主要集中在扩展检索文档的长度(Jiang等人,2024;Shao等人,2025;Xu等人,2023)。然而,由于VLMs的特点,仅强调知识量而不提供进一步的推理指导存在一定的局限性。需要一种有效的推理扩展方法,以高效利用具体操作空间,例如调整大小和过滤,以充分激活推理能力。
Building upon these insights, ViDoRAG introduces improvements in both retrieval and generation. We propose Multi-Modal Hybrid Retrieval, which combines both visual and textual features and dynamically adjusts results distribution based on Gaussian Mixture Models (GMM) prior. This approach achieves the optimal retrieval distribution for each query, enhancing generation efficiency by reducing unnecessary computations. During generation, our framework comprises three agents: the seeker, inspector, and answer agents. The seeker rapidly scans thumbnails and selects relevant images with feedback from the inspector. The inspector reviews, then provides reflection and offers preliminary answers. The answer agent ensures consistency and gives the final answer. This framework reduces exposure to irrelevant information and ensures consistent answers across multiple scales.
基于这些见解,ViDoRAG在检索和生成方面都带来了改进。我们提出了多模态混合检索,结合了视觉和文本特征,并根据高斯混合模型(GMM)先验动态调整结果分布。这种方法实现了每个查询的最佳检索分布,通过减少不必要的计算提高了生成效率。在生成过程中,我们的框架包括三个代理:搜索者、检查员和回答代理。搜索者快速扫描缩略图并选择相关图像,同时接受检查员的反馈。检查员审查后提供反思并给出初步答案。回答代理确保一致并给出最终答案。此框架减少了接触无关信息的机会,并确保跨多个尺度的一致答案。
Our major contributions are as follows: We introduce ViDoSeek, a benchmark specifically designed for visually rich document retrieval-reason-answer, fully suited for evaluation of RAG within large document corpus.
• We propose ViDoRAG, a novel RAG framework that utilizes a multi-agent, actor-critic paradigm for iterative reasoning, enhancing the noise robustness of generation models.
• We introduce a GMM-based multi-modal hybrid retrieval strategy to effectively integrate visual and textual pipelines.
• Extensive experiments demonstrate the effectiveness of our method. ViDoRAG significantly outperforms strong baselines, achieving over 10% improvement, thus establishing a new state-of-the-art on ViDoSeek.
我们的主要贡献如下:
我们介绍了ViDoSeek,一个专门针对视觉丰富文档检索-推理-回答设计的基准,非常适合大规模文档语料库中的RAG评估。
我们提出了一种新的RAG框架ViDoRAG,它利用多智能体、行为者-批评者范式进行迭代推理,增强了生成模型的噪声鲁棒性。
广泛的实验表明了我们方法的有效性。ViDoRAG显著优于强大的基线,实现了超过10%的改进,从而在ViDoSeek上建立了新的最先进技术状态。
二、文献综述
Visual Document Q&A Benchmarks
Visual Document Q&A Benchmarks. Visual Document Question Answering is focused on answering questions based on the visual content of documents(Antol et al., 2015; Ye et al., 2024; Wang et al., 2024). While most existing research (Methani et al., 2020; Masry et al., 2022; Li et al., 2024; Mathew et al., 2022) has primarily concentrated on question answering from single images, recent advancements have begun to explore multi-page document question answering, driven by the increasing context length of modern models (Mathew et al., 2021; Ma et al., 2024; Tanaka et al., 2023). However, prior datasets were not wellsuited for RAG tasks involving large collections of documents. To fill this gap, we introduce ViDoSeek, the first large-scale document collection QA dataset, where each query corresponds to a unique answer across a collection of ∼ 6k images.
视觉文档问答基准。视觉文档问答专注于基于文档的视觉内容回答问题(Antol等人,2015;Ye等人,2024;Wang等人,2024)。尽管大多数现有研究(Methani等人,2020;Masry等人,2022;Li等人,2024;Mathew等人,2022)主要集中在从单个图像中进行问答,但随着现代模型上下文长度的增加,最近的研究已经开始探索多页文档问答(Mathew等人,2021;Ma等人,2024;Tanaka等人,2023)。然而,之前的数据集并不适合涉及大量文档集合的RAG任务。为了填补这一空白,我们引入了ViDoSeek,这是第一个大规模文档集合问答数据集,其中每个查询对应于约6,000张图像集合中的唯一答案。
Retrieval-augmented Generation
Retrieval-augmented Generation. With the advancement of large models, RAG has enhanced the ability of models to incorporate external knowledge (Lewis et al., 2020; Chen et al., 2024b; Wu et al., 2025). In prior research, retrieval often followed the process of extracting text via OCR technology (Chen et al., 20
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











