







总结汇总MySQL数据库面试题(2020最新版)_ThinkWon的博客-CSDN博客_mysql数据库面试题
1. 索引
(1)主键索引 唯一非空,属于聚簇索引
(2)唯一索引 unique 可为空(多个null也可)
(3)单值索引
(4)组合索引
(5)全文索引(MySQL5.7之前,MyISAM引擎才有)
a.聚簇索引(数据和索引放一块,索引结构叶子节点存储行数据)
b.非聚簇索引(数据和索引分开放,索引结构叶子节点存储数据对应的位置)
什么情况下不使用索引:
where中使用LIKE时,“%”在最前面不会使用索引(不以通配符%开头的常量);
组合索引不满足最左前缀时不会使用索引;
where中使用or时,如果有一个条件不是索引就不会使用索引。
组合索引,最左前缀
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配(该范围查询列会用到),比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,c还是会用到,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
例如组合索引 index a,b,c 相当于创建了[a] [a,b] [a,b,c]索引,则在使用时条件包含a或者a,b或者a,b,c才会用到该组合索引。
比如where a=1 and c=1会用到索引[a],where b=1 and a=1会用到索引[a,b]。
参考Mysql组合索引最左前缀原则_moni_mm的博客-CSDN博客_组合索引最左前缀
索引缺点:
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。还会占用磁盘空间的索引文件。
MyISAM索引与InnoDB索引的区别
InnoDB支持事务(默认隔离级别为可重复读)、外键、行级锁、更好的恢复性(redo log)。
MyISAM支持全文索引,5.7之后InnoDB也支持。
InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
使用场景:(where,order by,join on,索引覆盖)
order by:由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。
索引覆盖:如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不访问原始数据。
百万级别或以上的数据如何删除
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
B树和B+树的区别
-
在B树中,你可以将键和值存放在内部节点和叶子节点;因此可以把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率
-
但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
-
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,空间利用率更高,因此一次读取可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间。
hash索引适合等值查询(无序)、B树索引适合范围查询。
2. 三大范式:
1NF:原子性,表中每列不可拆分;
2NF:1NF+表中列完全依赖于主键,而不是依赖于部分主键;
3NF:2NF+表中列直接依赖于主键,而不是传递依赖于主键。
3. 什么情况下左连接后,最终的记录数大于左表的记录数:
如果B表符合条件的记录数大于1条,就会出现1:n的情况,这样left join后的结果,记录数会多于A表的记录数。
参考mysql 左连接查询记录数_mysql中左连接后,最终的记录数大于左边表的记录分析..._并非的博客-CSDN博客
4. 查找数据表中列是否为 NULL,必须使用 IS NULL 和 IS NOT NULL。
建议用0或空字符代替null,因为null值会占用更多的字节。
5. MySQL 正则表达式:
REGEXP 或者 RLIKE eg:SELECT name FROM user WHERE name REGEXP '^st';

6. 交叉连接(笛卡尔积)、内连接(等值连接、不等值连接、自连接)、自然连接、外连接(左连接、右连接)、全连接(左连接UNION右连接)
参考数据库中的内连接、自然连接、和外连接的区别_ly294687451的博客-CSDN博客_连接和自然连接
7. DDL DQL DML DCL
DDL(data definition language):CREATE、ALTER、DROP...
DQL(data query language):SELECT
DML(data manipulation language):UPDATE、INSERT、DELETE...
DCL(data control language):grant,deny,revoke、commit、rollback...
参考浅谈 DML、DDL、DCL的区别_奔跑de五花肉的博客-CSDN博客_dcl ddl dml
8. 服务器逻辑架构(连接层、服务层、引擎层)
SQL执行流程(mysql5.7,mysql8去掉了缓存)
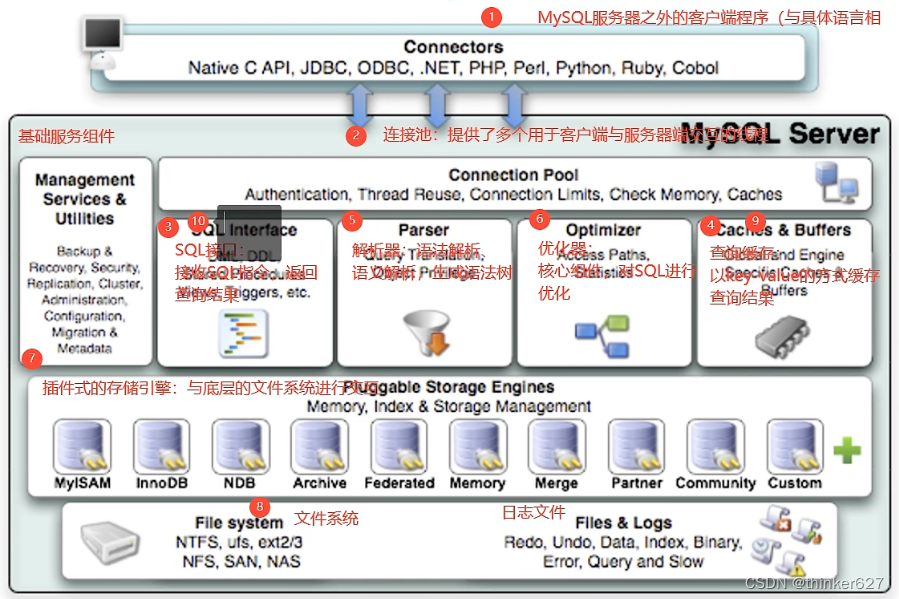
sql执行顺序:from(join)>where>group by>having>select>order by>limit
参考SQL 查询语句先执行 SELECT?兄弟你认真的么?__陈哈哈的博客-CSDN博客
9.数据类型
CHAR快,空间换时间;VARCHAR(20)20个字符(中英文一样)
对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
int(20)中20的涵义
是指显示字符的长度。20表示最大显示宽度为20,但仍占4字节存储,存储范围不变;
不影响内部存储,只是影响带 zerofill 定义的 int 时,前面补多少个 0,易于报表展示。
尽量使用timestamp,空间效率高于datetime。
10.事务
ACID 原子性、一致性、隔离性、持久性
强一致:事务要求各节点数据在任意时刻都是一致的。
DDL数据库定义语言不可回滚,事务不可以嵌套。
锁

级别分:
意向共享锁,表示事务准备给数据行加入共享锁;共享锁(读锁),可以多个只读,不可写;
意向排他锁,表示事务准备给数据行加入排他锁;排他锁(写锁),只能一个只写,其他不可读写。
意向锁属于表级锁,存放表中所有行锁的信息。
粒度分:全局锁(锁住整个数据库实例,备份时用)、表锁(适合读、简单、快)、页锁、行锁(适合写、并发、易死锁)
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作,通过数据库锁实现。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性,通过版本控制实现。
参考面试让HR都能听懂的MySQL锁机制,欢声笑语中搞懂MySQL锁__陈哈哈的博客-CSDN博客
11.视图
视图特点
视图的列可以来自不同的表,是虚表。
视图的建立和删除不影响基本表。
对视图内容的更新(添加,删除和修改)直接影响基本表。
当视图来自多个基本表时,不允许添加和删除数据。
视图优点
查询简单化。视图能简化用户的操作
数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
12.其他概念
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理。
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后在该程序中就可以调用多次。
触发器是用户定义在关系表上的一类由事件驱动的特殊的存储过程。触发器是指一段代码,当触发某个事件时,自动执行这些代码。
执行计划 explain。
13.exists和in的区别
in:首先查询内表,然后将内表和外表做一个笛卡尔积,按照条件进行筛选。所以相对内表小的,in的速度较快;
exists:遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。
参考数据库中exists和in的一些区别_小飞猪在此的博客-CSDN博客_exists和in的区别
14.SQL优化及数据库优化
参考https://thinkwon.blog.csdn.net/article/details/104778621
15. count(*)、 count(1)、 count(列)
count(*) 跟 count(1) 结果一样,都包括对NULL的统计,而count(column) 是不包括NULL的统计。
假如表没有主键, 那么count(1)比count(*)快,如果有主键的话,那count(主键)最快,如果表只有一个字段那count(*)就是最快的。
16. 聚合函数不可用在where子句中,可用在select和having中。
17. 子查询中,from后面的临时表必须指定表名。
18. MySQL中字符串和数值型的隐式转换
- 当操作符左右两边的数据类型不一致时,会发生隐式转换。
- 当 where 查询操作符左边为数值类型时发生了隐式转换,那么对效率影响不大,但还是不推荐这么做。
- 当 where 查询操作符左边为字符类型时发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低。
- 字符串转换为数值类型时,非数字开头的字符串会转化为
0,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果。
19. group by 列1,列2 having 条件(条件必须为前面的列相关的)。
高性能优化 参考MySQL高性能优化规范建议总结 | JavaGuide
附 SQL编程
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
declare var_name[,...] type [default value]
这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。
-- 赋值
使用 set 和 select into 语句为变量赋值。
- 注意:在函数内是可以使用全局变量(用户自定义的变量)
--// 全局变量 ----------
-- 定义、赋值
set 语句可以定义并为变量赋值。
set @var = value;
也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。
还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。
select @var:=20;
select @v1:=id, @v2=name from t1 limit 1;
select * from tbl_name where @var:=30;
select into 可以将表中查询获得的数据赋给变量。
-| select max(height) into @max_height from tb;
-- 自定义变量名
为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。
@var=10;
- 变量被定义后,在整个会话周期都有效(登录到退出)
--// 控制结构 ----------
-- if语句
if search_condition then
statement_list
[elseif search_condition then
statement_list]
...
[else
statement_list]
end if;
-- case语句
CASE value WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result ...]
[ELSE result]
END
-- while循环
[begin_label:] while search_condition do
statement_list
end while [end_label];
- 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。
-- 退出循环
退出整个循环 leave
退出当前循环 iterate
通过退出的标签决定退出哪个循环
--// 内置函数 ----------
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 流程函数
case when [condition] then result [when [condition] then result ...] [else result] end 多分支
if(expr1,expr2,expr3) 双分支。
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();
--// 存储函数,自定义函数 ----------
-- 新建
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
函数体
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
- 多条语句应该使用 begin...end 语句块包含。
- 一定要有 return 返回值语句。
-- 删除
DROP FUNCTION [IF EXISTS] function_name;
-- 查看
SHOW FUNCTION STATUS LIKE 'partten'
SHOW CREATE FUNCTION function_name;
-- 修改
ALTER FUNCTION function_name 函数选项
--// 存储过程,自定义功能 ----------
-- 定义
存储存储过程 是一段代码(过程),存储在数据库中的sql组成。
一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。
而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。
-- 创建
CREATE PROCEDURE sp_name (参数列表)
过程体
参数列表:不同于函数的参数列表,需要指明参数类型
IN,表示输入型
OUT,表示输出型
INOUT,表示混合型
注意,没有返回值。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









