






新部署了一套分布式文件系统,使用了3个节点,大致看一下底层还是ceph,多了一层管理界面。
在管理界面中配置了文件系统,并划分一个目录给NFS使用,需单独配置许可的客户端和数据狼配额,分配给k8s paas平台使用,同时PVE 环境也划分了一块空间作为备份,基本操作就这样。
1. 故障描述
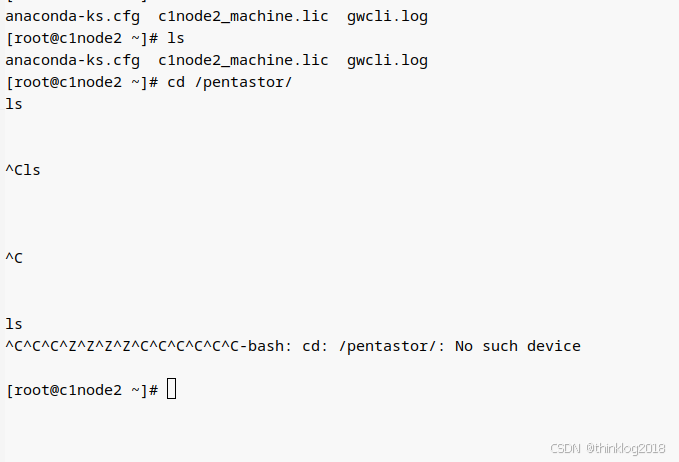
某天,k8s 使用人员反馈无法使用提供的NFS空间,在节点上能看到挂载的目录,但使用cd命令无法进入到这个挂载目录中。在分布式文件系统的节点上,偶尔能进入到该子目录,但ls和mkdir等操作均卡住无法执行,使用ctrl C和Z也无法退出。
这是在配VE上,点击查看挂载NFS的存储时,也会出现:
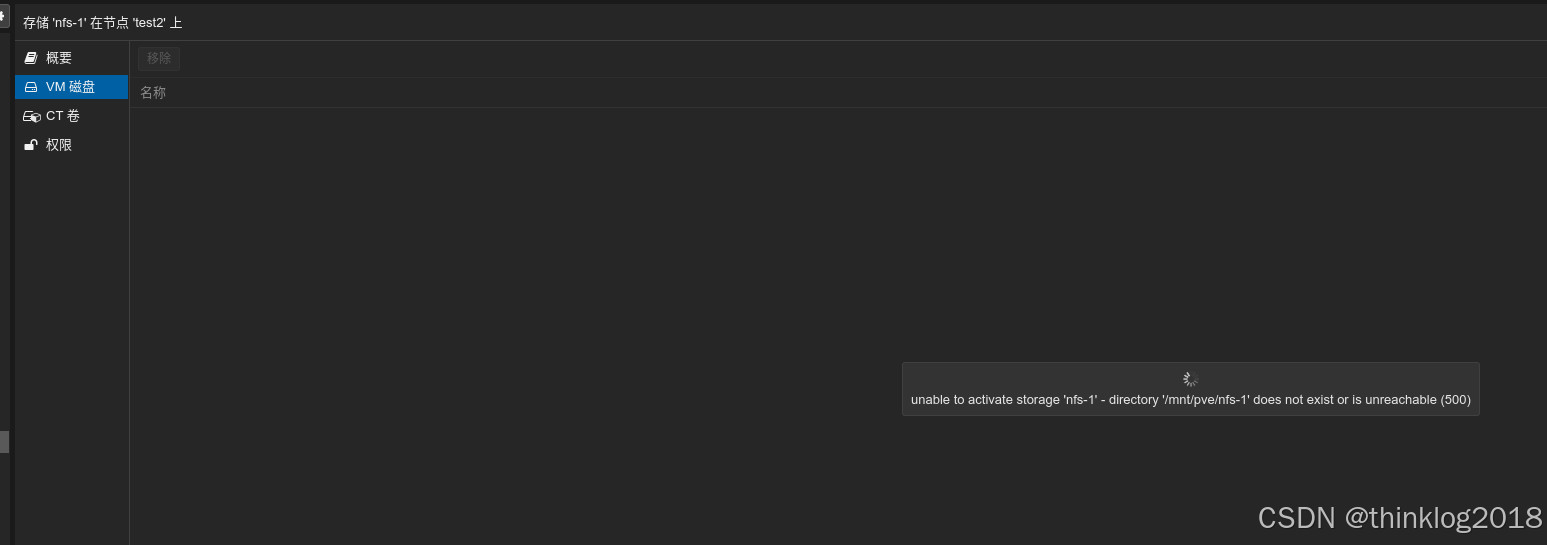
表示NFS磁盘无法正常挂载。
2. 故障排查
最初是怀疑PaaS平台有问题,因为在其他节点上看不到挂载的NFS目录。但经过询问,PaaS平台是通过一个容器来支持外部存储的,这个容器也并没有做容错或者高可用,只在一个节点上有这个容器服务运行。 并重启了PaaS的节点,仍有问题。因此将注意力转移到分布式文件系统。
执行ceph -s 的结果,可以看到系统健康状态不正常,但没有直接提示是什么原因。
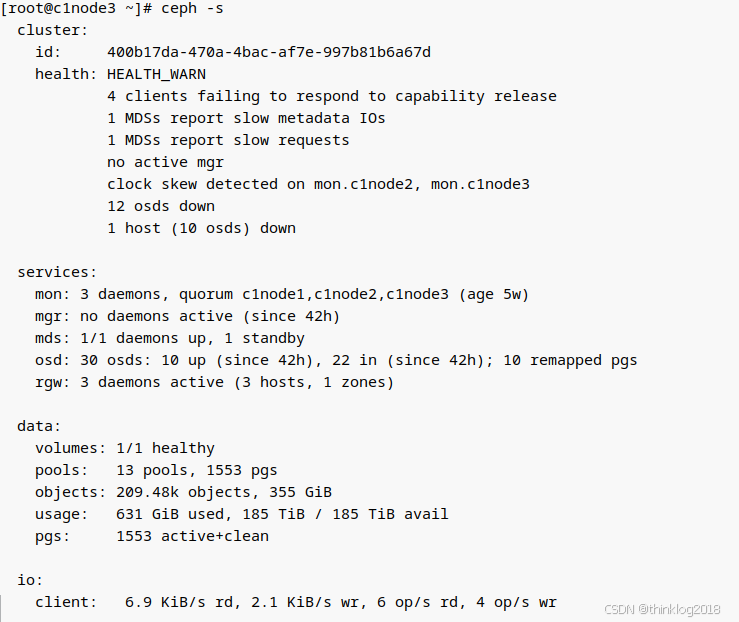
看起来是有一个主机的osds状态不对,处于down的状态。
既然没有直接原因,将这个输出扔给大模型看看:
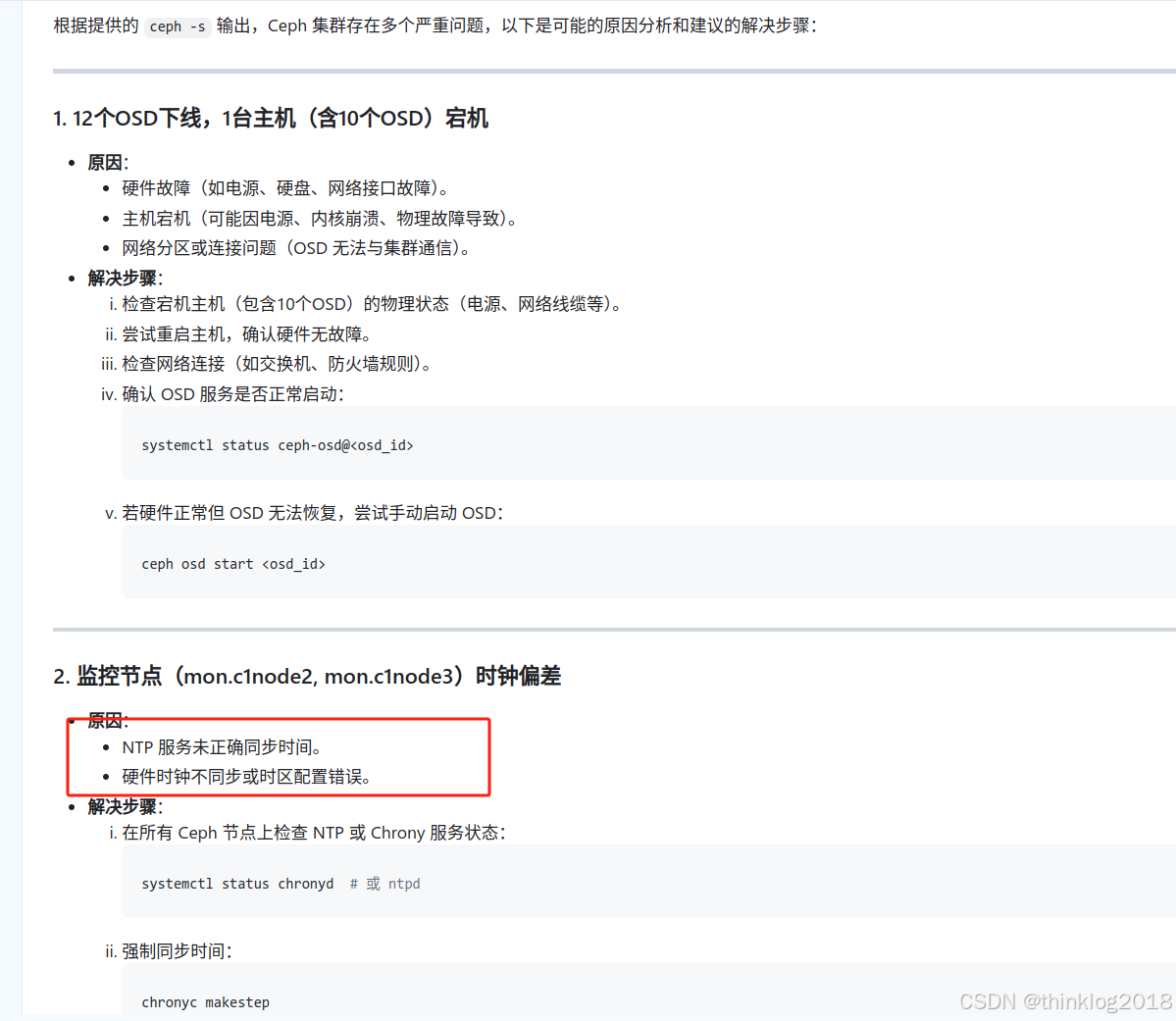
大模型首先仍未可能是服务未启动,其次是时钟不同步。检查服务都在启动状态,接着检查发现三个节点的时间同步真的有问题。
原因是某个节点的chronyd服务配置与其他不同,配置了外部时钟,而其他两个节点都采用了其中一个节点作为时钟源。外部和内部时钟有偏差,导致三个节点的时间不同步。
3. 解决办法
问题找到也就容易解决了:在每个节点上都配置2个时钟源:
server 192.168.1.1 iburst #外部时钟源
server 192.168.3.1 iburst # 分布式存储的某个节点
然后重启chronyd服务。
4. 后续
时间同步后,在节点上的NFS目录中可以cd、ls 或者mkdir了。 但这时客户端仍旧无法mount nfs的目录。
ceph -s发现数据还在同步过程中:
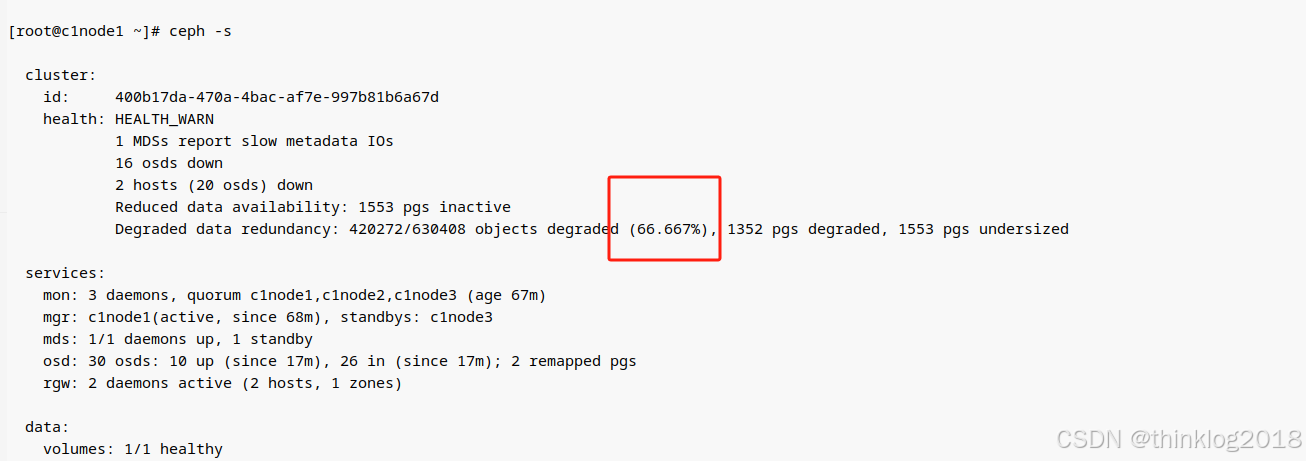
感觉这个同步过程很慢。之前在测试华为gauss分布式数据库时也遇到类似情况,就是分布式系统一旦发生不同步,则故障排除后,数据同步的效率会非常低,导致长时间无法恢复业务运行。 不知道是不是都是这种情况。 分布式有其优点,但也有其缺点,感觉类似于k8s ,需要一个强有力的运维团队才行。

















 7036
7036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









