







摘要:本文通过WordCount的几个关键点,把map部分的过程串起来,只是一个浅析。所谓,一滴水能够映现出整个太阳吧。
版本:hadoop1.0.1
以下是examples中的代码:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行例子: bin/hadoop jar hadoop-examples-1.0.0.jar WordCount /test/input /test/output
执行之后,main方法具体做了什么呢?
WordCount方法加载后,执行main方法,Configuration是配置类,Job是任务类。Job中设置了相关的方法类,最终都是采用映射的方式执行。如:
map方法:TokenizerMapper
reduce方法:IntSumReducer
Combiner方法:IntSumReducer
输入文件:otherArgs[0]
输出文件:otherArgs[1]
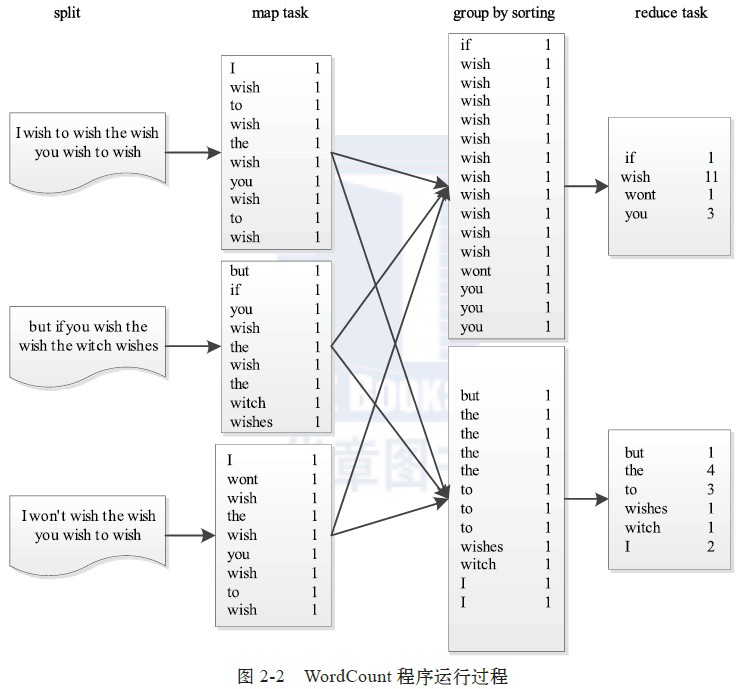
WordCount的功能是统计文章中字母的个数,执行过程如下图:
step2:TokenizerMapper
我们先看map方法:
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}那inupt中的文件是如何被拆分成一行字符串,并且被map执行的呢?
step3:Mapper
从TokenizerMapper的继承类Mapper看,key和value是通过Context中获取的。那Context是从何而来?
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}Context的继承类MapContext,我们可以看到key和value,都是从RecordReader中获取的。
public class MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
extends TaskInputOutputContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
private RecordReader<KEYIN,VALUEIN> reader;
private InputSplit split;
public MapContext(Configuration conf, TaskAttemptID taskid,
RecordReader<KEYIN,VALUEIN> reader,
RecordWriter<KEYOUT,VALUEOUT> writer,
OutputCommitter committer,
StatusReporter reporter,
InputSplit split) {
super(conf, taskid, writer, committer, reporter);
this.reader = reader;
this.split = split;
}
/**
* Get the input split for this map.
*/
public InputSplit getInputSplit() {
return split;
}
@Override
public KEYIN getCurrentKey() throws IOException, InterruptedException {
return reader.getCurrentKey();
}
@Override
public VALUEIN getCurrentValue() throws IOException, InterruptedException {
return reader.getCurrentValue();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
return reader.nextKeyValue();
}
}mapreduce默认采用TextInputFormat,作为输入流:
@SuppressWarnings("unchecked")
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}TextInputFormat中的LineRecordReader是什么呢?请看下一步。
package org.apache.hadoop.mapreduce.lib.input;
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
return new LineRecordReader();
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
return codec == null;
}
}
step6:LineRecordReader
RecordReader只是一个抽象类,从LineRecordReader中,我们大概可以看出一些端倪了。从FileSplit中获取路径,生成FSDataInputStream输入流,再封装成LineReader类,在nextKeyValue中,解析key和value。
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private int maxLineLength;
private LongWritable key = null;
private Text value = null;
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength",
Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
final CompressionCodec codec = compressionCodecs.getCodec(file);
// open the file and seek to the start of the split
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
boolean skipFirstLine = false;
if (codec != null) {
in = new LineReader(codec.createInputStream(fileIn), job);
end = Long.MAX_VALUE;
} else {
if (start != 0) {
skipFirstLine = true;
--start;
fileIn.seek(start);
}
in = new LineReader(fileIn, job);
}
if (skipFirstLine) { // skip first line and re-establish "start".
start += in.readLine(new Text(), 0,
(int)Math.min((long)Integer.MAX_VALUE, end - start));
}
this.pos = start;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
while (pos < end) {
newSize = in.readLine(value, maxLineLength,
Math.max((int)Math.min(Integer.MAX_VALUE, end-pos),
maxLineLength));
if (newSize == 0) {
break;
}
pos += newSize;
if (newSize < maxLineLength) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}
/**
* Get the progress within the split
*/
public float getProgress() {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (pos - start) / (float)(end - start));
}
}
public synchronized void close() throws IOException {
if (in != null) {
in.close();
}
}
}最后我们看下,mian启动后,如何将这些串联起来。MapTask中的几个关键点:
input初始化:
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, job, taskContext);mapper初始化:
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);mapperContext初始化,和执行:mapper.run(mapperContext);
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),
input, output, committer,
reporter, split);
input.initialize(split, mapperContext);
mapper.run(mapperContext);step8:MapTask
再逆回去看,JobClient是如何实现的,过程如下图:

step9:JobTacker
(1)为作业创建JobInProgress对象。
(2)检查用户是否具有指定队列的作业提交权限。
(3)检查作业配置的内存使用量是否合理。
(4)通知TaskScheduler初始化作业。
step10:JobInProgress
JobInProgress生成这几个TaskInProgress,相关代码如下:
TaskInProgress maps[] = new TaskInProgress[0];
TaskInProgress reduces[] = new TaskInProgress[0];
TaskInProgress cleanup[] = new TaskInProgress[0];
TaskInProgress setup[] = new TaskInProgress[0];TaskInProgress生成MapTask或者ReduceTask对象,相关代码如下:
public Task addRunningTask(TaskAttemptID taskid,
String taskTracker,
boolean taskCleanup) {
// 1 slot is enough for taskCleanup task
int numSlotsNeeded = taskCleanup ? 1 : numSlotsRequired;
// create the task
Task t = null;
if (isMapTask()) {
if(LOG.isDebugEnabled()) {
LOG.debug("attempt " + numTaskFailures + " sending skippedRecords "
+ failedRanges.getIndicesCount());
}
t = new MapTask(jobFile, taskid, partition, splitInfo.getSplitIndex(),
numSlotsNeeded);
} else {
t = new ReduceTask(jobFile, taskid, partition, numMaps,
numSlotsNeeded);
}
if (jobCleanup) {
t.setJobCleanupTask();
}
if (jobSetup) {
t.setJobSetupTask();
}
if (taskCleanup) {
t.setTaskCleanupTask();
t.setState(taskStatuses.get(taskid).getRunState());
cleanupTasks.put(taskid, taskTracker);
}
t.setConf(conf);
t.setUser(getUser());
if (LOG.isDebugEnabled()) {
LOG.debug("Launching task with skipRanges:"+failedRanges.getSkipRanges());
}
t.setSkipRanges(failedRanges.getSkipRanges());
t.setSkipping(skipping);
if(failedRanges.isTestAttempt()) {
t.setWriteSkipRecs(false);
}
activeTasks.put(taskid, taskTracker);
tasks.add(taskid);
// Ask JobTracker to note that the task exists
jobtracker.createTaskEntry(taskid, taskTracker, this);
// check and set the first attempt
if (firstTaskId == null) {
firstTaskId = taskid;
}
return t;
}这个时候再回到step7,整个map的过程就完整了。
最后:
Map Task的整体流程,可以概括为5个步骤:
1。Read:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
2。Map:该阶段主要将解析出的key/value交给用户编写的map()函数处理,并产生一系列的key/value。
3。Collect:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输入结果。在该函数内部,它会将生成的key/value分片(通过Partitioner),并写入一个环形内存缓冲区中。
4。Spill:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并,压缩等操作。
5。Combine:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
参考资料:
《Hadoop技术内幕》——董西成。















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









