







论文题目:speech recognition with deep recurrent neural networks
作者:Alex Graves, Abdel-rahman Mohamed and Geoffrey Hinton
论文中第2部分,介绍关于RNN的一些知识:
对于一个给定的输入序列 x = (x1, ..., xT), 一个标准的RNN通过迭代下面一系列方程来计算隐层序列 h = (h1, ..., hT) 和输出层 y = (y1, ..., yT):
for t = 1 -> T:

W表示权重矩阵(例如Wxh表示输入层到隐层的权重矩阵),b表示偏置,H表示隐层函数,通常选择sigmoid function。
作者发现另一种结构Long Short-Term Memory (LSTM)在大范围内容中查找和利用更好(However we have found that the LSTM architecture, which uses puprpose-buit memory cells to store information, is better at finding and exploiting long range context.):

上图中描述了单个 LSTM memory cell,在[14]中的H通过下面一系列函数来表示:
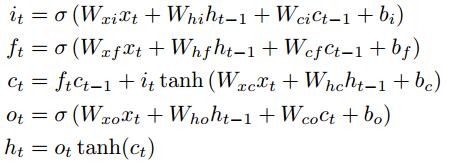
其中sigma是logistic sigmoid函数,然后i,f,o,c分别表示input, forget, output and cell.
传统的RNNs存在一个缺点,只能利用上层的内容。然后在说话识别中,整个说话被转录一次,没有理由不去利用后层的内容。[15]的BRNNs就考虑到了双向(用两个隐层)。然后[16]结合BRNNs和LSTM,直接利用大范围上下文的两个输入方向。而最近hybrid HMM-neural network systems成功的重要原因就是深度结构,所以作者考虑使用deep RNNs,也就是搞很多隐层(N层),然后每个隐层的函数相同,那么第n个隐层的序列计算如下:
for n = 1 -> N:
for t = 1 -> T:
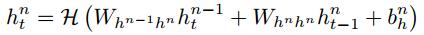
其中h0定义为x,也就是输入。
然后每个隐层也可以弄成双向的!也就是模仿[15,16]。也就形成了该论文的模型。
论文第3部分介绍网络训练:

















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









