










计划完成深度学习入门的126篇论文第七篇,多伦多大学的Geoffrey和Alex Graves发表关于End-to-End Deep RNN在Speech Recognition方向上的论文。
ABSTRACT&INTRODUCTION
摘要
Recurrent neural networks(RNNs)是一种强大的序列数据模型。端到端训练方法,如Connectionist Temporal Classification使训练神经网络用于输入输出对齐未知的序列标签问题成为可能。这些方法与长短期记忆RNN架构的结合被证明是特别富有成效的,在草书手写识别方面提供了最先进的结果。但迄今为止,RNN在语音识别中的表现一直令人失望,深度前馈网络的识别效果较好。
本文研究的是深度递归神经网络deep recurrent neural networks,它结合了在深度网络中已被证明是有效的多层表示,以及灵活使用赋予神经网络能力的远程上下文。经过端到端的规范化训练,我们发现深度长短时记忆RNNs在TIMIT音素识别基准上的测试集误差为17.7%,据我们所知,这是最好的记录分数。
Index Terms— recurrent neural networks, deep neural networks, speech recognition
介绍
神经网络在语音识别领域有着悠久的历史,通常与隐马尔可夫模型hidden Markov models相结合[1,2]。近年来,随着深度前馈网络deep feedforward networks在声学建模方面acoustic modeling yielded的显著改进,这些问题引起了人们的关注[3,4]。鉴于语音是一个固有的动态过程,将递归神经网络(RNNs)作为一种替代模型似乎是很自然的。HMM-RNN系统[5]最近也出现了复苏[6,7],但目前的表现不如深度网络。
与其将RNNs与HMMs结合起来,还不如对RNNs进行端到端RNNs ‘end-to-end’的语音识别训练[8,9,10]。该方法与HMMs相比,利用了RNNs更大的状态空间和更丰富的动力学特性,避免了使用可能不正确的对齐作为训练目标的问题。长短时记忆Long Short-term Memory[11]结合改进记忆的RNN架构,结合端到端训练,对草书笔迹识别特别有效[12,13]。然而,到目前为止,它对语音识别的影响甚微。
神经网络具有固有的深度,因为它们的隐藏状态是之前所有隐藏状态的函数。启发这篇论文的问题是RNNs是否也能从空间的深度中受益;这是将多个重复的隐藏层堆叠在一起,就像传统的深层网络中堆叠前馈层一样。为了回答这个问题,我们引入了深度长短期记忆神经网络deep Long Short-term Memory RNNs,并评估它们在语音识别方面的潜力。我们还对最近引入的端到端学习方法进行了改进,该方法将两个独立的RNNs作为声学和语言模型[10]联合训练。第2节和第3节描述了网络架构和训练方法,RNN第4节给出了实验结果,第5节给出了结论。


RECURRENT NEURAL NETWORKS
给定输入序列![]() ,标准递归神经网络(RNN)计算隐藏向量序列
,标准递归神经网络(RNN)计算隐藏向量序列![]() ,输出向量序列
,输出向量序列![]()
![]() 。将t = 1迭代到t,得到:
。将t = 1迭代到t,得到:

W项表示权重矩阵(如![]() 为输入隐藏权重矩阵),b项表示偏置向量,(如
为输入隐藏权重矩阵),b项表示偏置向量,(如![]() 为隐藏偏置向量),
为隐藏偏置向量),![]() 为隐藏层函数
为隐藏层函数
Long Short-Term Memory (LSTM)
![]() 通常是sigmoid函数的基本应用。但我们发现,Long Short-Term Memory (LSTM)架构[11]使用专门构建的内存单元memory cells来存储信息,它更善于发现和利用远程上下文。图1显示了一个LSTM内存单元。对于本文使用的LSTM版本,[14]。
通常是sigmoid函数的基本应用。但我们发现,Long Short-Term Memory (LSTM)架构[11]使用专门构建的内存单元memory cells来存储信息,它更善于发现和利用远程上下文。图1显示了一个LSTM内存单元。对于本文使用的LSTM版本,[14]。![]() 由以下复合函数实现:
由以下复合函数实现:

其中σ是sigmoid函数,和我,f, o和c分别input gate, forget gate, output gate, cell activation vectors。

所有这些都与隐藏向量h的大小相同。从cell到gate vector(如Wsi)的权矩阵是对角线的,所以每个gate vector中的元素m只接收cell vector的元素m的输入。
Bidirectional RNNs (BRNNs)
传统神经网络的一个缺点是它们只能利用以前的上下文。在语音识别中,所有的话语同时被转录,没有理由不利用未来的上下文。Bidirectional RNNs (BRNNs)[15]通过使用两个独立的隐藏层在两个方向上处理数据来实现这一点,然后将数据转发到相同的输出层。如图2所示,BRNN计算forward hidden sequence![]() ,backward hidden sequence
,backward hidden sequence![]() ,output sequence y。从t=T开始通过循环反向层,从t=1开始前向层循环,然后更新输出层:
,output sequence y。从t=T开始通过循环反向层,从t=1开始前向层循环,然后更新输出层:
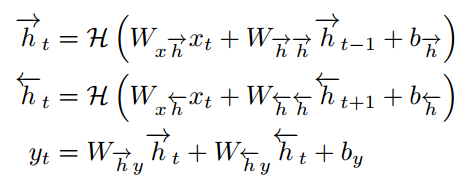
将BRNNs与LSTM结合,得到双向的LSTM[16],可以在两个输入方向接触到很远的上下文。
Deep RNNs
最近hybrid HMMneural network systems成功的一个关键因素是使用deep architectures,逐步建立更高层次的acoustic数据表示
Deep RNNs可以通过将多个RNN隐藏层叠加在一起创建,其中一个层的输出序列构成下一个层的输入序列。假设堆栈中所有N层都使用相同的隐含层函数,则从N = 1到N, t = 1到T迭代计算隐含向量序列:
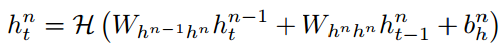
定义![]() ,新的输出
,新的输出![]() :
:
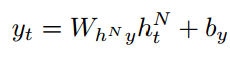
通过将每个隐藏序列![]() 替换为正向序列和反向序列
替换为正向序列和反向序列![]() 。如果将LSTM用于隐藏层,则得到了深层的双向LSTM,即本文使用的主要架构。据我们所知,这是第一次将深度LSTM应用到语音识别中,我们发现它比单层LSTM有了很大的改进。
。如果将LSTM用于隐藏层,则得到了深层的双向LSTM,即本文使用的主要架构。据我们所知,这是第一次将深度LSTM应用到语音识别中,我们发现它比单层LSTM有了很大的改进。
NETWORK TRAINING
我们专注于端到端训练,其中RNNs学习直接从声学序列映射到语音序列。这种方法的一个优点是,它不需要预先定义(且容易出错)对齐来创建培训目标。第一步是使用网络输出参数可微的分布![]() 。在所有可能的语音输出序列y给定一个声波输入序列x。对数概率
。在所有可能的语音输出序列y给定一个声波输入序列x。对数概率![]() 目标输出序列z可以分化对使用反向传播网络权重[17],整个系统可以用梯度下降优化。现在我们描述两种定义输出分布的方法,从而训练网络。我们把x的长度记作T, z的长度记作U,可能的音素数记作K。
目标输出序列z可以分化对使用反向传播网络权重[17],整个系统可以用梯度下降优化。现在我们描述两种定义输出分布的方法,从而训练网络。我们把x的长度记作T, z的长度记作U,可能的音素数记作K。
1. CTC:Connectionist Temporal Classification
第一种方法被称为CTC(Connectionist Temporal Classification, CTC)[8,9],它使用softmax层在输入序列的每一步t上定义一个单独的输出分布![]() 。这个分布包括K个音素和一个额外的空白符号
。这个分布包括K个音素和一个额外的空白符号![]() 。它表示一个非输出(softmax层因此大小为K + 1。直观地,网络决定是否在每个步骤中发出任何标签,或不发出任何标签。这些决策一起定义了输入序列和目标序列之间的分布。CTC然后使用一个向前向后的算法对所有可能的对齐求和,并确定给定输入序列[8]的目标序列的归一化概率
。它表示一个非输出(softmax层因此大小为K + 1。直观地,网络决定是否在每个步骤中发出任何标签,或不发出任何标签。这些决策一起定义了输入序列和目标序列之间的分布。CTC然后使用一个向前向后的算法对所有可能的对齐求和,并确定给定输入序列[8]的目标序列的归一化概率![]() 。在语音和手写识别的其他领域也使用了类似的程序来对可能的分段进行整合[18,19];然而,CTC的不同之处在于,它完全忽略了分割,而是对单步标签决策进行求和。
。在语音和手写识别的其他领域也使用了类似的程序来对可能的分段进行整合[18,19];然而,CTC的不同之处在于,它完全忽略了分割,而是对单步标签决策进行求和。
经过CTC训练的RNNs通常是双向的,以确保每个![]() 依赖于整个输入序列,而不仅仅是t之前的输入。在这里我们关注深度双向网络,
依赖于整个输入序列,而不仅仅是t之前的输入。在这里我们关注深度双向网络,![]() 定义为:
定义为:

![]() 是长度k + 1的未标准化输出向量
是长度k + 1的未标准化输出向量![]() 的第k个元素,N是双向层的个数。
的第k个元素,N是双向层的个数。
2. RNN Transducer
CTC定义了一个音素序列上的分布,该分布仅依赖于声学输入序列x。因此,它是一个声学模型。最近的一种增强,称为RNN传感器[10],它将类似ctc的网络与单独的RNN结合起来,后者预测给定前一个音素的每个音素,从而生成一个共同训练的声学和语言模型。联合低频声学训练在过去被证明对语音识别是有益的[20,21]。
CTC决定了每个输入时间步的输出分布,而RNN传感器决定了一个单独的分布![]() 对于输入时间步长t和输出时间步长u的每个组合。与CTC一样,每个分布包含K个音素
对于输入时间步长t和输出时间步长u的每个组合。与CTC一样,每个分布包含K个音素![]() 。直观地说,网络根据它在输入序列中的位置和它已经发出的输出来决定输出什么。对于长度为U的目标序列z, T U决策的完整集合共同决定了x和z之间的所有可能的对齐上的分布,然后将其与前向后的算法进行积分,确定
。直观地说,网络根据它在输入序列中的位置和它已经发出的输出来决定输出什么。对于长度为U的目标序列z, T U决策的完整集合共同决定了x和z之间的所有可能的对齐上的分布,然后将其与前向后的算法进行积分,确定![]() [10]。
[10]。
原公式![]() 由CTC网络中的声学分布
由CTC网络中的声学分布![]() 和预测网络中的语言分布
和预测网络中的语言分布![]() 定义,然后将两者相乘,再进行正演。本文提出的一种改进方法是将两种网络的隐藏激活输入到一个单独的前馈输出网络中,然后使用softmax函数对其输出进行规范化,从而生成
定义,然后将两者相乘,再进行正演。本文提出的一种改进方法是将两种网络的隐藏激活输入到一个单独的前馈输出网络中,然后使用softmax函数对其输出进行规范化,从而生成![]() 这为结合语言和声学信息提供了更丰富的可能性,而且似乎会带来更好的泛化。特别是我们发现在解码过程中遇到的删除错误的数量减少了。
这为结合语言和声学信息提供了更丰富的可能性,而且似乎会带来更好的泛化。特别是我们发现在解码过程中遇到的删除错误的数量减少了。
用![]() 表示CTC网络最上面的前向和后向隐藏序列,用p表示预测网络的隐藏序列。在每个t;输出网络通过将
表示CTC网络最上面的前向和后向隐藏序列,用p表示预测网络的隐藏序列。在每个t;输出网络通过将![]() 送入线性层生成向量
送入线性层生成向量![]() ,再将
,再将![]() 和
和![]() 送入tanh隐层生成
送入tanh隐层生成![]() ,最后将
,最后将![]() 送入;u至大小K + 1 softmax层确定
送入;u至大小K + 1 softmax层确定![]() :
:
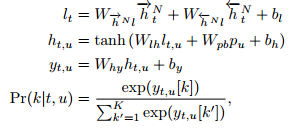
式中,![]() 为长度k + 1非标准化输出向量的第k个元素。为简单起见我们限制nonoutput层相同的大小
为长度k + 1非标准化输出向量的第k个元素。为简单起见我们限制nonoutput层相同的大小![]()
![]() 但是它们可以独立变化。
但是它们可以独立变化。
RNN传感器可以由随机初始权值进行训练。然而,当初始化一个预先训练过的CTC网络和一个预先训练过的下一步预测网络的权值时,它们似乎工作得更好(因此只有输出网络从随机权值开始)。训练前使用的输出层(和所有相关的权重)在再训练时被移除。本文利用语音训练数据的语音转录对预测网络进行预训练;但是,对于大型应用程序,在单独的文本语料库上进行预习更有意义。
3. Decoding
RNN transducers可以通过beam search[10]进行解码,得到n个最佳候选转录序列。在过去,CTC网络可以使用一种称为前缀搜索的最佳优先译码形式进行解码,也可以简单地在每一步[8]中获取最活跃的输出。然而,在这项工作中,我们利用了与传感器相同的beam search,并修改了输出标签概率Pr(kjt;u)不依赖于之前的输出(因此![]() )。我们发现波束搜索比前缀搜索CTC更快更有效。注意,传感器的n个最佳列表最初是按照长度标准化对数概率对数
)。我们发现波束搜索比前缀搜索CTC更快更有效。注意,传感器的n个最佳列表最初是按照长度标准化对数概率对数![]() 进行排序的;在当前的工作中,我们省去了标准化(只有在删除比插入多得多的情况下才会有所帮助)和按
进行排序的;在当前的工作中,我们省去了标准化(只有在删除比插入多得多的情况下才会有所帮助)和按![]() 排序。
排序。
EXPERIMENTS
在TIMIT语料库[25]上进行音素识别实验。去除所有SA记录的标准462扬声器集用于培训,50个扬声器的单独开发集用于早期停止。对24-speaker core test测试集的结果进行了报告。音频数据使用基于fourier -transform的滤波器组进行编码,滤波器组的系数(加上能量)分布在mel-scale上,同时还包括它们的一阶和二阶时间导数。因此,每个输入向量的大小为123。对数据进行归一化,使输入向量的每个元素在训练集上的均值和单位方差均为零。在训练和解码过程中使用了全部61个音素标签(因此K = 61),然后映射到39个类中进行[26]评分。注意,所有实验只运行一次,因此随机权值初始化和权值噪声引起的方差是未知的。
如表1所示,我们对9个神经网络进行了评估,这些神经网络沿着三个主要维度变化:所使用的训练方法(CTC、换能器或预训练换能器)、隐藏层的数量(15)和每个隐藏层中的LSTM细胞数量。除CTC-3l-500h-tanh为tanh单元而不是LSTM细胞,CTC-3l-421h-uni为单向LSTM层外,其他网络均采用双向LSTM。所有网络均采用随机梯度下降法进行训练,学习速率为104,动量为0:9,初始权值均为![]() 。所有网络除了CTC - 3 - l - 500 h -双曲正切和pretrans - 3 l - 250 h首次训练,没有噪音,然后从发展对数概率最高的点集,重新训练重量与高斯噪声(σ= 0:075)直到音素错误率最低的点发展集。pretrans - 3 - l - 250 h是初始化权重的CTC - 3 l - 250 h,连同一个音素预测网络的权重(还有一个隐藏层250 LSTM细胞),它们都是在没有噪声的情况下进行训练,再用噪声进行训练,并在最高对数概率点停止。在此基础上进行PreTrans-3l- 250h的训练,加入噪声。CTC-3l- 500h-tanh训练完全没有重量噪声,因为添加噪声后无法学习。所有网络均采用波束搜索译码,波束宽度为100。
。所有网络除了CTC - 3 - l - 500 h -双曲正切和pretrans - 3 l - 250 h首次训练,没有噪音,然后从发展对数概率最高的点集,重新训练重量与高斯噪声(σ= 0:075)直到音素错误率最低的点发展集。pretrans - 3 - l - 250 h是初始化权重的CTC - 3 l - 250 h,连同一个音素预测网络的权重(还有一个隐藏层250 LSTM细胞),它们都是在没有噪声的情况下进行训练,再用噪声进行训练,并在最高对数概率点停止。在此基础上进行PreTrans-3l- 250h的训练,加入噪声。CTC-3l- 500h-tanh训练完全没有重量噪声,因为添加噪声后无法学习。所有网络均采用波束搜索译码,波束宽度为100。
深度网络的优势是显而易见的,随着隐藏层的数量从1个增加到5个,CTC的错误率从23.9%下降到18.4%。CTC-3l-500h-tanh、CTC-1l-622h、CTC- 3l-421h-uni和CTC-3l-250h四种网络的权值基本相同,但结果截然不同。由此我们可以得出的三个主要结论是:(a) LSTM比tanh更适合这项任务;(b)双向的LSTM与单向LSTMand相比,LSTM有一点优势(c)深度比层大小更重要(这支持了之前对于深度网络[3]的发现)。虽然传感器的优点是轻微时,随机初始化的重量,它变得更重要时,预处理使用。

CONCLUSIONS AND FUTURE WORK
我们已经展示了深度的组合,双向的具有端到端的训练和权重噪声的长短期记忆RNNs在TIMIT数据库中的音素识别方面提供了最先进的结果。一个明显的下一步是将系统扩展到大词汇量语音识别。另一个有趣的方向是将频域卷积神经网络[27]与深度LSTM相结合。















 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









