







实验九 排序
【完成时间】2021年1月6日
【实验要求】
(1)至少要有一种排序算法的性能优于O(n2)
(2)对实现的排序算法进行实验比较,实验比较数据参见教材7.8章节
(3)排序算法要基于教材,测试输入的整数数据文件(5个,文件中数据规模分别是100,1K,10K,100K和1M),排序结果也要输出到文件中。
(4)要在屏幕上输出排序过程所花费时间。
(5)提交最终实验作业。用附件的形式,提交两个文件:一个压缩包(包含源码和5个用于排序测试的数据文件);一个pdf文档(文档中包含实验日志和一个根据基本要求(1)记录实验结果的表格,然后进行适当的实验结果分析)。
【实验构想】
本次采用快速排序和插入排序两种方法进行实验。在实验前分析,快速排序的速度应该高于插入排序,事实也证明了我的这一想法。
同时,
可以先看一下,各种排序算法性能比较

在此说一下快排。
动机:
分治思想:划分交换排序
基本思想:
在待排序记录中选取一个记录R(称为轴值pivot),
通过一趟排序将其余待排记录分割(划分)成独立
的两部分,比R小的记录放在R之前,比R大的记录
放在R之后,然后分别对R前后两部分记录继续进行
同样的划分交换排序,直至待排序序列长度等于1,
这时整个序列有序。
快速排序算法过程
快速排序过程:快速排序(划分过程)用递归实现。
若当前(未排序)序列的长度不大于1
返回当前序列
否则
在待排序记录中选取一个记录做为轴值,通过划分
算法将其余待排记录划分成两部分,比R小的记录放
在R之前,比R大的记录放在R之后;
分别用快速排序对前后两个子序列进行排序(注意轴
值已经在最终排序好的数组中的位置。无须继续处理)
快速排序算法过程(续)
选取轴值,划分序列的过程:
记录数组A,待排子序列左、右两端的下标i和j
选取待排序子序列中间位置的记录为轴值
交换轴值和位置j的值
依据在位置j的轴值,将数组i-1到j之间的待排序记录划分
为两个部分(i到k-1之间的记录比轴值小,k到j-1之间的
记录比轴值大)
从数组i-1到j之间的待排序序列两端向中间移动下标,
必要时交换记录,直到两端的下标相遇为止(相遇的位置记为k)交换轴值和位置k的值
快速排序算法举例

快速排序算法性能分析
时间开销:
找轴值:常数时间
划分:Θ(s),s是数列的长度
最差情况: 糟糕的分割Θ(n^2)
最佳情况: 每次将数列分割为等长的两部分 Θ(nlogn)
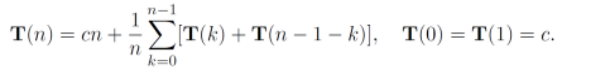
Θ(nlogn)
空间开销:
辅助栈空间,Θ(logn)
快速排序的特点
• 冒泡排序的改进,划分交换排序
• 轴值的取值影响性能
• 时间复杂度为(nlogn)
• 不稳定的排序方法
• 实际,快速排序是最好的内排序方法
快速排序的优化:
–更好的轴值
–对于小的子数列采用更好的排序算法
–用栈来模拟递归调用
【实验结果】
本次实验使用插入排序和快速排序进行测试,得到测试结果如下表所示: 单位(ms)
| 数据规模 | 100 | 1K | 10K | 100K | 1M |
|---|---|---|---|---|---|
| 插入排序 | 0 | 2 | 126 | 12397 | 1325554 |
| 快速排序 | 0 | 0 | 2 | 14 | 156 |
【结果分析】
数据来源是Excel中的数学公式“=RANDBETWEEN()”,每次从1到最大值开始随机生成相应规模的数据,将生成好的数据导入到对应的txt文本中。
下面我们看算法,从数据大小来看,100到1M中5个样本值比较,插入排序运行时间随数据规模10倍的增大每次以接近100倍的效率进行突变,时间复杂度为O(n²),在1M时,在测试时需要等待其运算结束,具有很明显的运行时间;而快速排序,随数据规模10倍的增大每次以接近10倍的效率进行突变,对于数据规模较小的100,1k快速排序的时间代价都要小于1ms,结合测试数据总体以及理论实现快速排序的时间复杂度为O(nlogn)。
从两个算法比较来看,100,1K小样本数据中插入排序和快速排序差别不大,若结合理论来分析,在特定的原始数据特征下,插入排序比快速排序还要快一点,不过这是微秒级的差距,很微小;但是从10K往上开始两者的排序效率就开始有明显的差异,在数据规模为10k时,两者运行时间人的感知不明显,但数值上可以看到明显差距,对于100k的数据规模,快速排序仍然能够很快的出结果,但在插入排序阶段可以感知到程序在运行的时间长度,对于1M的数据规模,快速排序在极短的时间内得到结果,但插入排序则需要等候几分钟,对于相对较差的处理器来说可能要几十分钟,nlogn与n²的差距还是非常明显。
源码如下
(创建txt 文件在实验8)
#include <iostream>
#include <fstream>
#include <ctime>
#include <iomanip>
#include <sstream>
using namespace std;
int A[1000000], B[1000000];
void swap(int A[], int i, int j) {
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
void insertsort(int A[], int n) {
for (int i = 1; i < n; i++) {
for (int j = i; j > 0; j--) {
if (A[j] < A[j - 1]) {
swap(A, j, j - 1);
} else {
break;
}
}
}
}
void quicksort(int A[], int i, int j) {
if (i >= j) {
return;
}
int dex = (i + j) / 2;
swap(A, dex, j);
int l = i, r = j;
while (l != r) {
while (A[l] <= A[j] && l < r) {
l++;
}
while (A[r] >= A[j] && l < r) {
r--;
}
swap(A, l, r);
}
swap(A, l, j);
quicksort(A, i, l - 1);
quicksort(A, r + 1, j);
}
int main() {
stringstream ss;
string limit[5] = {"100", "1k", "10k", "100k", "1M"};
int n = 0, k;
double start = 0, end = 0;
ifstream input;
ofstream output_ins;
ofstream output_qui;
string order;
for (int j = 0; j < 5; j++) {
n = 0;
ss << j + 1;
ss >> order;
ss.clear();
input.open("in_" + order + ".txt");
output_ins.open("out_ins_" + order + ".txt");
output_qui.open("out_qui_" + order + ".txt");
while (!input.eof()){
input >> k;
A[n] = k;
B[n++] = k;;
}
cout << "当数据规模是" << limit[j] << "时:\n";
start = clock();
quicksort(B, 0, n - 1);
end = clock();
cout << "快速排序消耗时间为:" << end - start << "ms" << endl;
for (int i = 0; i < n; i++) {
output_qui << left << B[i] << "\t";
if (i % 10 == 0 && i != 0)
output_qui << endl;
}
output_qui << "快速排序消耗时间为:" << end - start << "ms" << endl;
start = clock();
insertsort(A, n);
end = clock();
cout << "插入排序消耗时间为:" << end - start << "ms" << endl ;
for (int i = 0; i < n; i++) {
output_ins << left << A[i] << "\t";
if (i % 10 == 0 && i != 0)
output_ins << endl;
}
output_ins << "插入排序消耗时间为:" << end - start << "ms" << endl ;
input.close();
output_ins.close();
output_qui.close();
}
return 0;
}
最后是各种排序算法性能比较
| 最佳 | 平均 | 最差 | 空间 | 稳定性 | 排序方法 | |
|---|---|---|---|---|---|---|
| 直接插入排序 | n | n^2 | n^2 | 1 | 稳定 | 插入 |
| 冒泡排序 | n^2 | n^2 | n^2 | 1 | 稳定 | 交换 |
| 简单选择排序 | n^2 | n^2 | n^2 | 1 | 稳定 | 选择 |
| 希尔排序 | nlogn | nlog^2 n | nlog^2 n | 1 | 不稳定 | 插入 |
| 快速排序 | nlogn | nlogn | n^2 | logn~n | 不稳定 | 交换 |
| 归并排序 | nlogn | nlogn | nlogn | n | 稳定 | 归并 |
| 基数排序 | nk+rk | nk+rk | nk+rk | n+2^k | 稳定 | 非比较 |
| 堆排序 | nlogn | nlogn | nlogn | 1 | 不稳定 | 选择 |
| 桶式排序 | n+r | n+r | n+r | n+r | 稳定 | 非比较 |
时间关系不一一列举
















 2817
2817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











