







什么是DSL ?
DSL(Domain Specific Language)的缩写,中文翻译为领域特定语言。
Wikipedia 对于 DSL 的定义还是比较简单的:
A specialized computer language designed for a specific task.
为了解决某一类任务而专门设计的计算机语言。
与 GPL 相对,DSL 与传统意义上的通用编程语言 C、Python 以及 Haskell 完全不同。通用的计算机编程语言是可以用来编写任意计算机程序的,并且能表达任何的可被计算的逻辑,同时也是 图灵完备 的。
但是在里所说的 DSL 并不是图灵完备的,它们的表达能力有限,只是在特定领域解决特定任务的。
A computer programming language of limited expressiveness focused on a particular domain.
另一个世界级软件开发大师 Martin Fowler 对于领域特定语言的定义在笔者看来就更加具体了,DSL 通过在表达能力上做的妥协换取在某一领域内的高效。
而有限的表达能力就成为了 GPL 和 DSL 之间的一条界限。
零、ES基本操作
1、查看索引/mapping
GET /inde_name
GET /[index_name]/_mapping
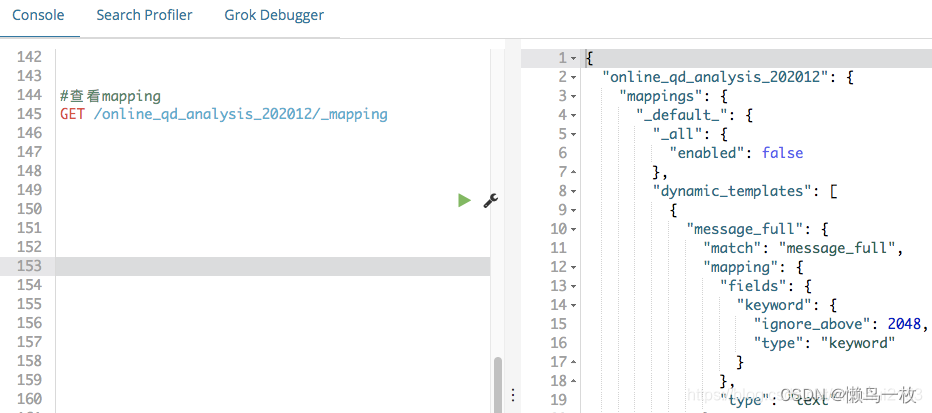
#例如
GET /online_qd_analysis_202012
GET /online_qd_analysis_202012/_mapping
2、查看集群健康状态
GET /_cat/health
GET /_cat/health?v #带"?v"就是列出列名的意思

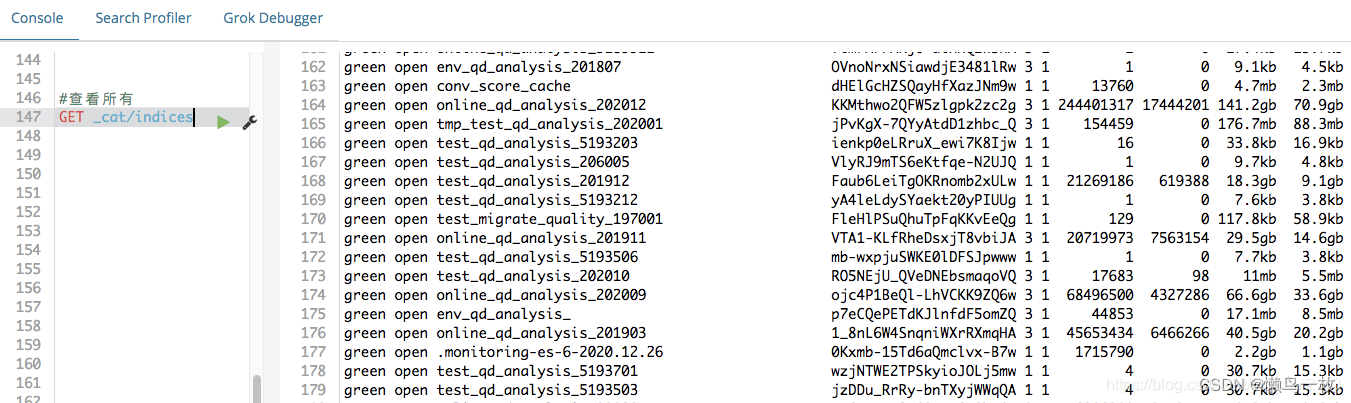
3、查询ES中所有的index
GET _cat/indices
GET _cat/indices?v #带"?v"就是列出列名的意思
4、删除索引
#删除指定索引
DELETE index_name
5、查看索引的分片情况
GET _cat/shards/index_name
GET _cat/shards/index_name?v

如上,每个分片是主副分片、状态、文档数、占用存储、ip等都一目了然。
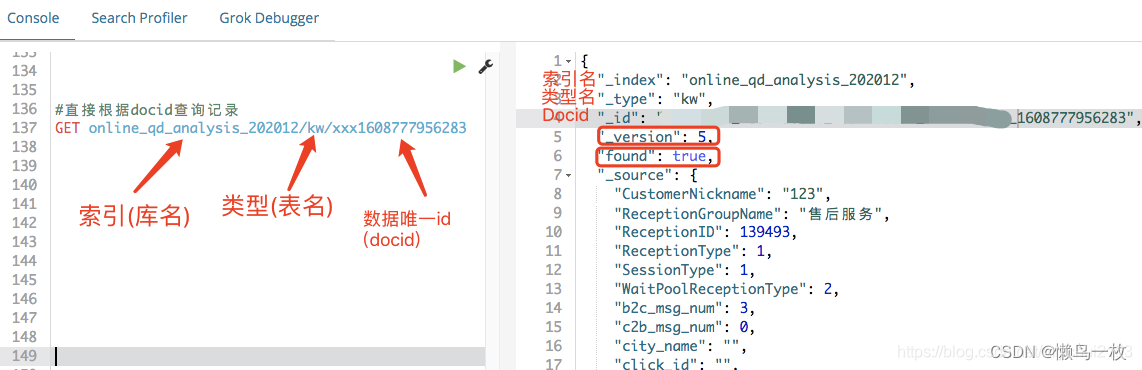
6、根据docid查询文档
GET /index_name/type_name/docid
#例如
GET /online_qd_analysis_202012/kw/corp_uin_2852156690_2852156690_1442795696_1608777956283
7、常规查找——在/index/type中查找
注:_search的含义是在所有数据中查找。
#指定index和type;就是在这个type_name中查找的意思
GET index_name/type_name/_search
{
"size":30,
"query":{
}
}
#指定index
GET index_name/_search
{
"size":30,
"query":{
}
}
8、限制查找条数
#限制查找条数有两种方式.1)在get语句中限定 2)在内部参数中限定
#1)GET语句中限定
GET index_name/_doc/_search?size=100
{
"query": {
"match": {
"session_id": "1"
}
}
}
#2)内部参数限定
GET index_name/type_name/_search
{
"size":3,
"query": {
"match": {
"session_id": "1"
}
}
}
具体规则可以参见: CSDN
9、ES的基本CURD
下面以一个电商的例子,说明下es的增删改查。
(1)、插入一条数据
指定docid,POST/PUT都可以;不指定docid,貌似只能POST。
#PUT操作插入一条数据
PUT /my_index/my_type/docid1111
{
"name":"dior chengyi",
"desc":"shishang gaodang",
"price":7000,
"producer":"dior producer",
"tags":["shishang","shechi"]
}
#ES7及以后版本有所变更,格式如下。
PUT /my_index/_doc/docid1111
{
"name":"dior chengyi",
"desc":"shishang gaodang",
"price":7000,
"producer":"dior producer",
"tags":["shishang","shechi"]
}
注:es7以后格式为"PUT /index_name/_doc/",其中的_doc是必须的标识对文档的操作。
#ES7及以后 不指定docid
PUT /my_index/_doc/1
{
"name":"dior chengyi",
"desc":"shishang gaodang",
"price":7000,
"producer":"dior producer",
"tags":["shishang","shechi"]
}
注:es7以后格式为"PUT /index_name/_doc/",其中的_doc是必须的标识对文档的操作。
注:es7之后版本都要将type位置换成“_doc”;其实就是ES7将_doc作为默认type了。
PUT 必须要指定id值 ,POST 自动生成ID值
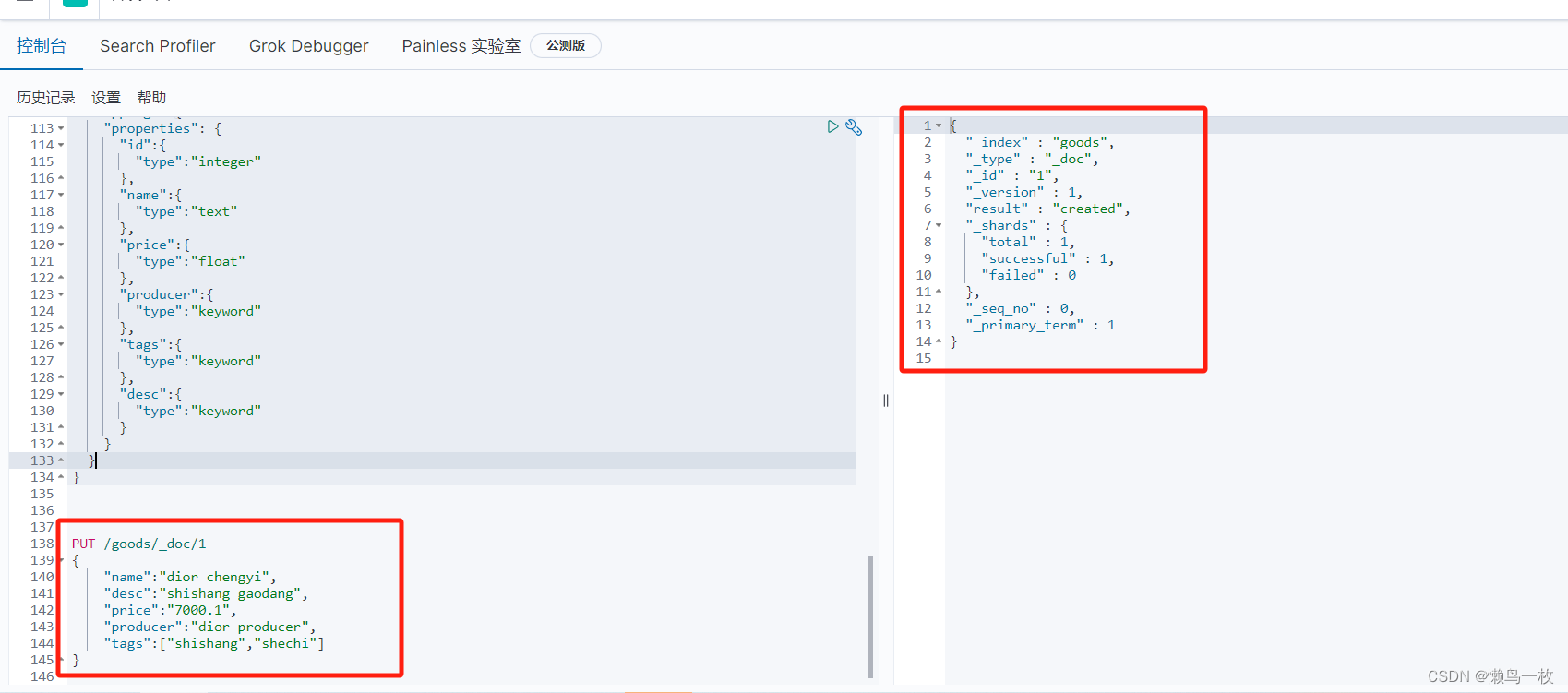
- PUT 操作
PUT /index_name/_doc/idValue
{
}
- POST操作
POST/index_name/_doc/
{
}
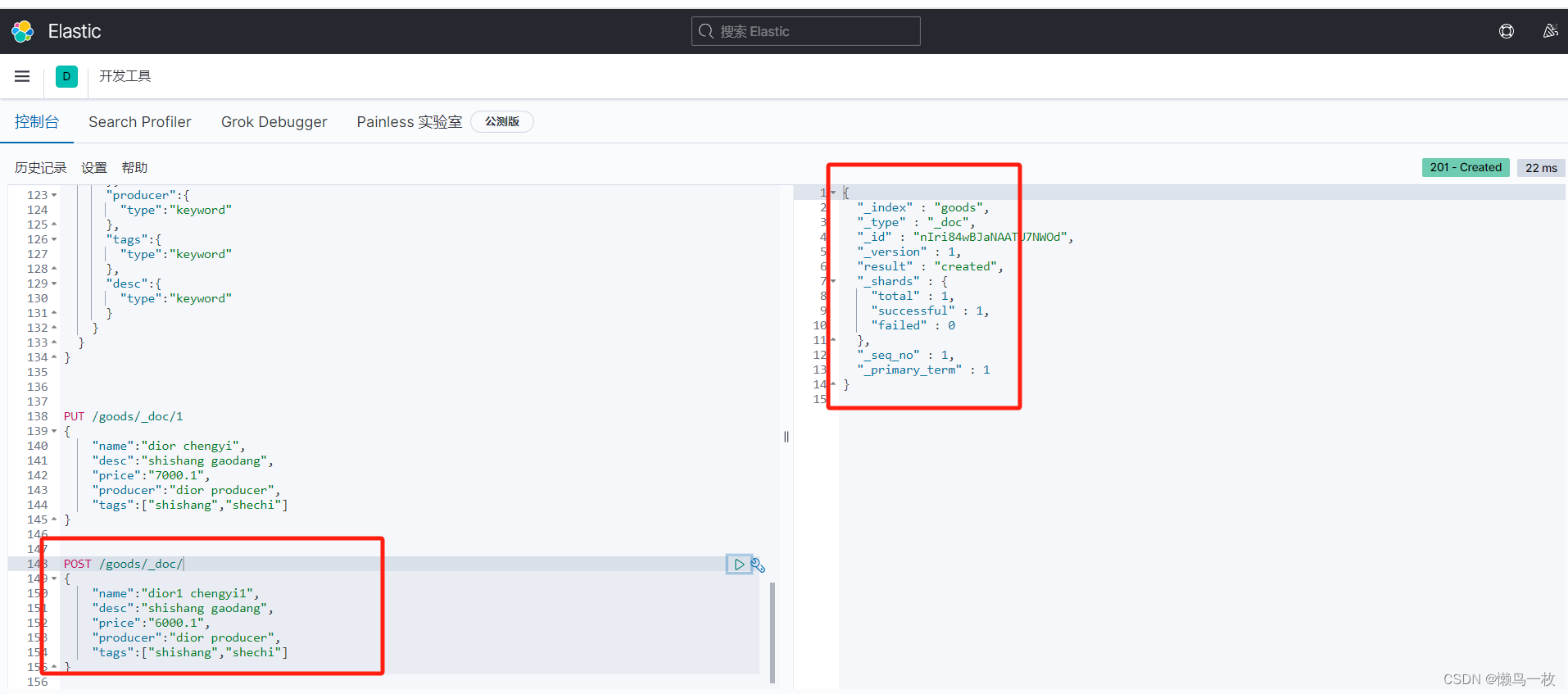
(2)、根据docid查询某条记录
#根据docid查询商品
GET /my_index/my_type/docid1111
GET /my_index/_doc/docid1111
(3)、根据其他字段查询记录
GET /my_index/my_type/_search
{
"size":5,
"query":{
"match":{
"name":"dior chengyi"
}
}
}
#es7及之后版本
GET /my_index/_doc/_search
{
"size":5,
"query":{
"match":{
"name":"dior chengyi"
}
}
}
根据其他字段的全部匹配查询
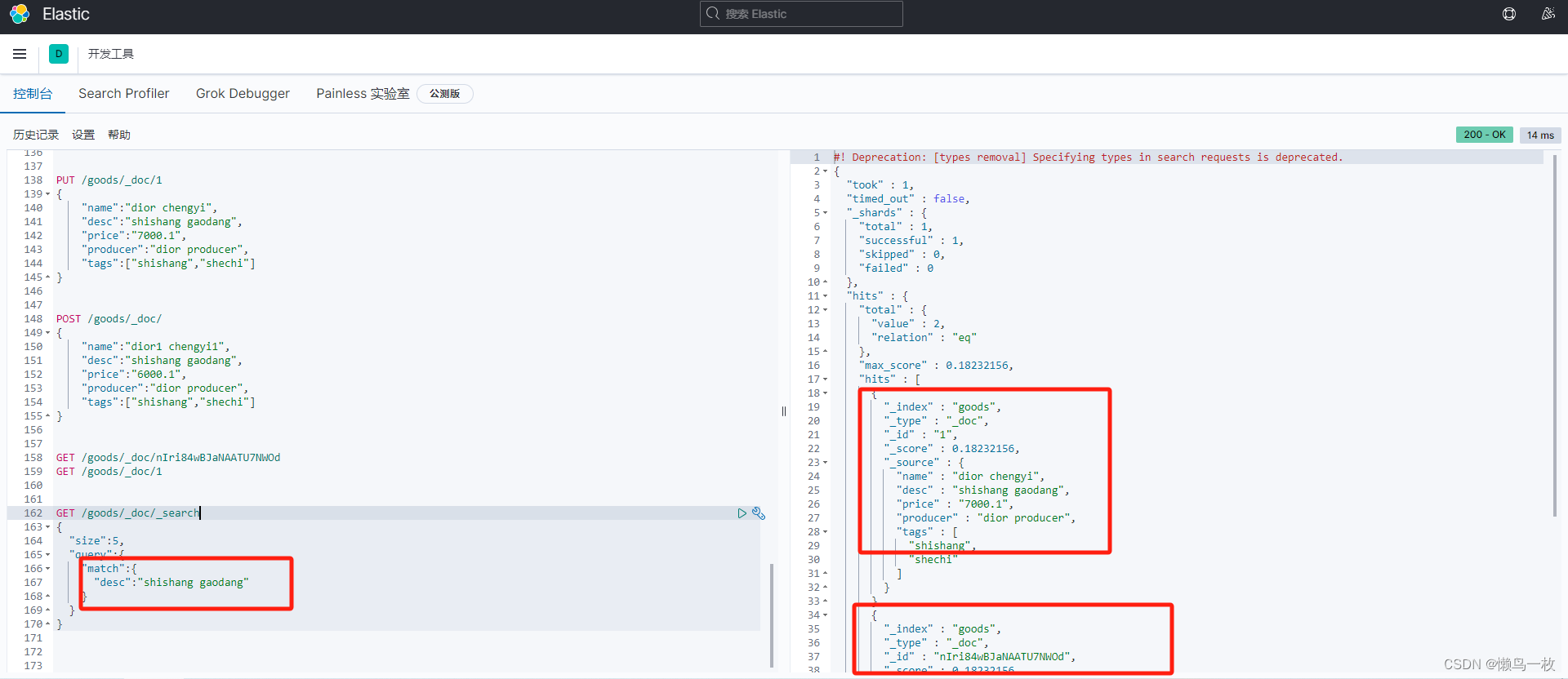
根据字段中的某个值查询
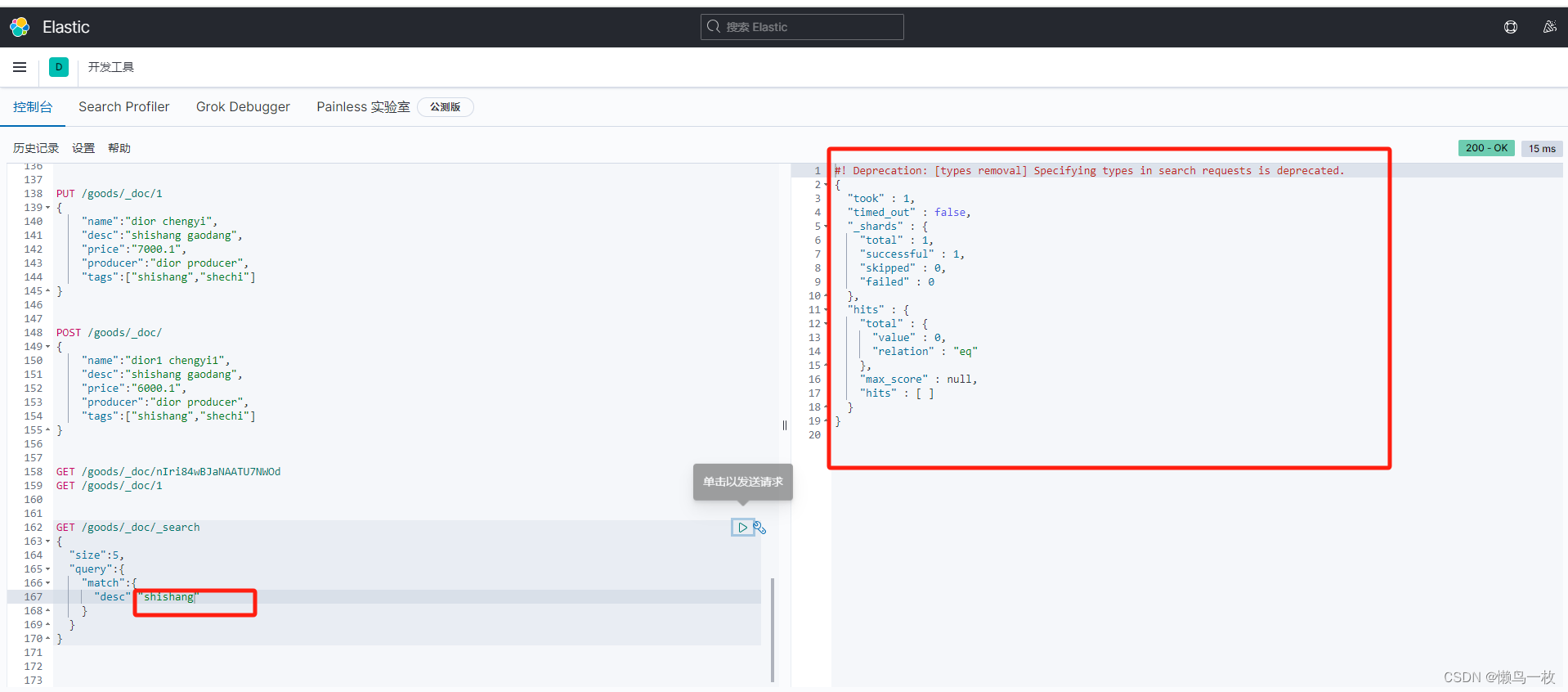
(4)、修改数据
(1)PUT方式修改字段——其他字段依然带上
#把price改成8000.如下是ok的
PUT /my_index/my_type/docid1111
{
"name":"dior chengyi",
"desc":"shishang gaodang",
"price":8000,
"producer":"dior producer",
"tags":["shishang","shechi"]
}
(2)PUT方式仅涉及修改字段——其他字段不带上(会覆盖原来所有)
修改数据要使用PUT 方式 ,带上ID 进行更新
#这样update是不行的.会把docid1111完全覆盖掉
PUT /my_index/my_type/docid1111
{
"price":9000
}
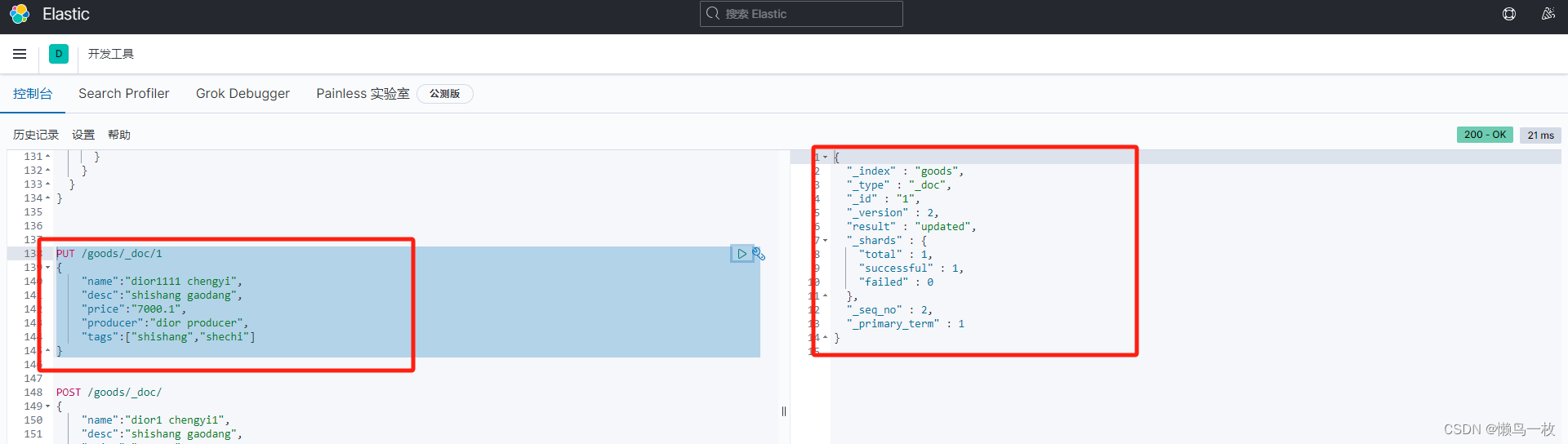
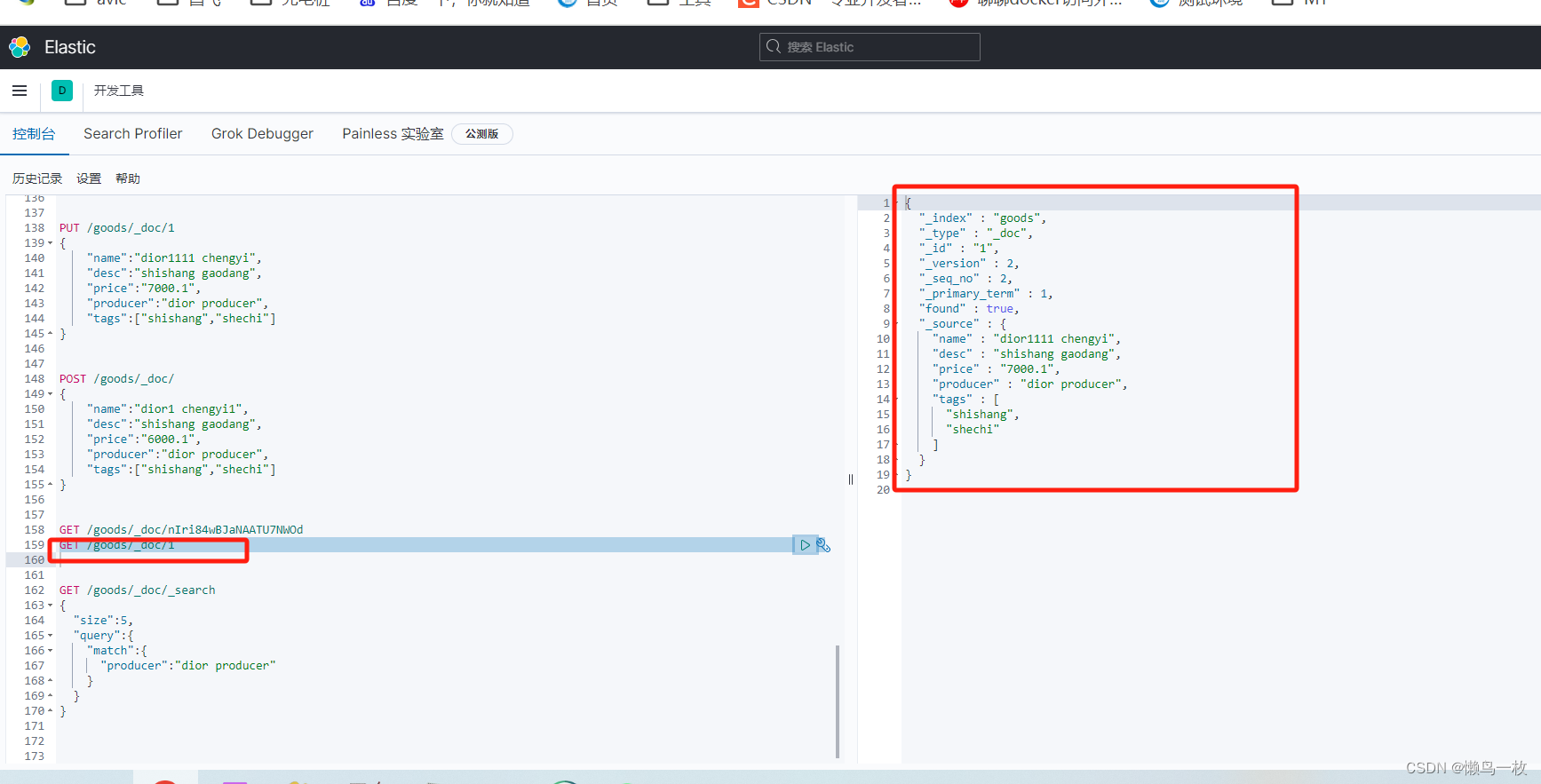
(3)POST/_update方式修改数据——比较理想的方法
注:先进行查询,查询后存储doc,然后在更新其中的指定的字段的字段值。
#POST方式进行update.注意:“_update”、"doc"等都要有
POST /my_index/my_type/docid1111/_update
{
"doc":{
"price":8500
}
}
POST /my_index/_doc/docid1111/_update
{
"doc":{
"price":8500
}
}
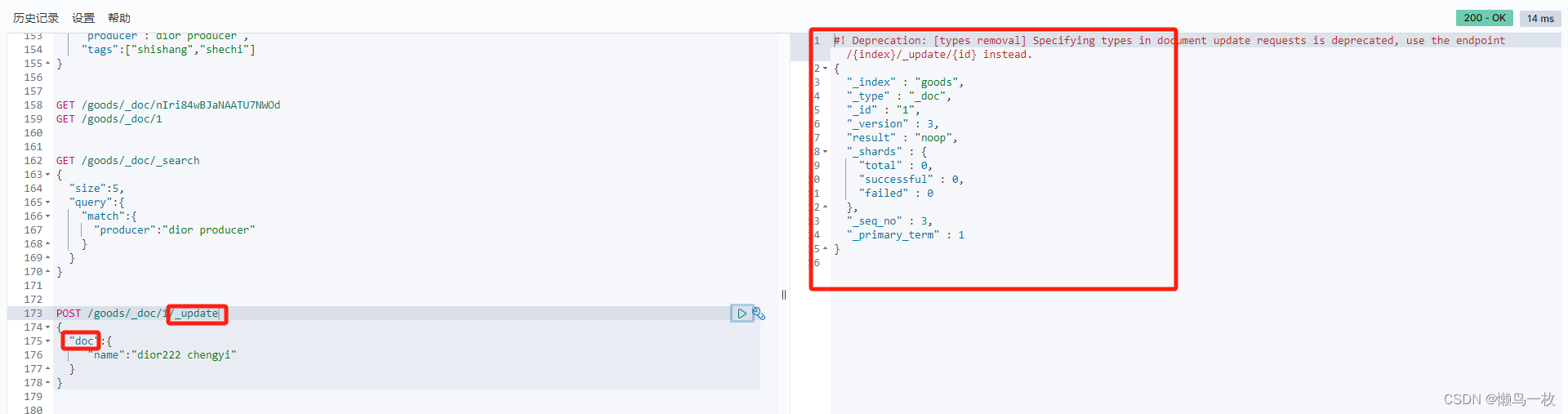

5、删除商品数据
#删除商品数据
DELETE /my_index/my_type/docid1111
6、继续插入两条数据
#再插入一条记录
PUT /my_index/my_type/docid1112
{
"name":"hailanzhijia chenyi",
"desc":"shangwu xiuxian",
"price":200,
"producer":"hailanzhijia producer",
"tags":["xiuxian"]
}
#在插入一条记录
PUT /my_index/my_type/docid1113
{
"name":"uniqlo chenyi",
"desc":"jujia xiuxian",
"price":150,
"producer":"uniqlo producer",
"tags":["jujia","xiuxian"]
}
7、查看所有数据
#查看所有数据
```bash
GET /my_index/my_type/_search
GET /my_index/_doc/_search
一、ES高级查询 DSL
1、ES mapping中的数据类型
字符串类型: keyword、text
数字类型: interger long
小数类型: float double
布尔类型: boolean
日期类型: date
①keyword一般用于关键字/词;text存储一段文本。本质区别是text会分词,keyword不会分词;
②所有类型中只有text类型会分词,其余都不分词;
③默认情况ES使用标准分词器。其分词逻辑为:中文单字分词、英文单词分词。
2. 新建索引
为了便于后续测试创建如下索引
PUT products
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings":{
"properties": {
"id":{
"type":"integer"
},
"title":{
"type":"keyword"
},
"price":{
"type":"double"
},
"create_at":{
"type":"date"
},
"description":{
"type":"text"
}
}
}
}
定分词器
注:discription字段以下形式即为指定分词器
"description":{
"type":"text",
"analyzer": "ik_max_word"
}
#并插入如下数据
POST /products/_doc/1
{
"id":1,
"title":"小浣熊",
"price":0.5,
"create_at":"2022-11-11",
"description":"小浣熊很好吃!!"
}
POST /products/_doc/2
{
"id":2,
"title":"唐僧肉",
"price":1.0,
"create_at":"2022-11-11",
"description":"唐僧肉真不错!!很好吃!!"
}
POST /products/_doc/8
{
"id":8,
"title":"大辣片",
"price":1.0,
"create_at":"2022-11-11",
"description":"大辣片好好吃!!很好吃!!"
}
POST /products/_doc/
{
"title":"大鸡腿",
"price":10,
"create_at":"2022-11-11",
"description":"good chicken"
}
POST /products/_doc/
{
"title":"日本豆",
"price":1.5,
"create_at":"2022-11-11",
"description":"日本豆很好吃!!"
}
POST /products/_doc/
{
"title":"鱼豆腐",
"price":3.5,
"create_at":"2022-11-11",
"description":"鱼豆腐nice!!很好吃!!"
}
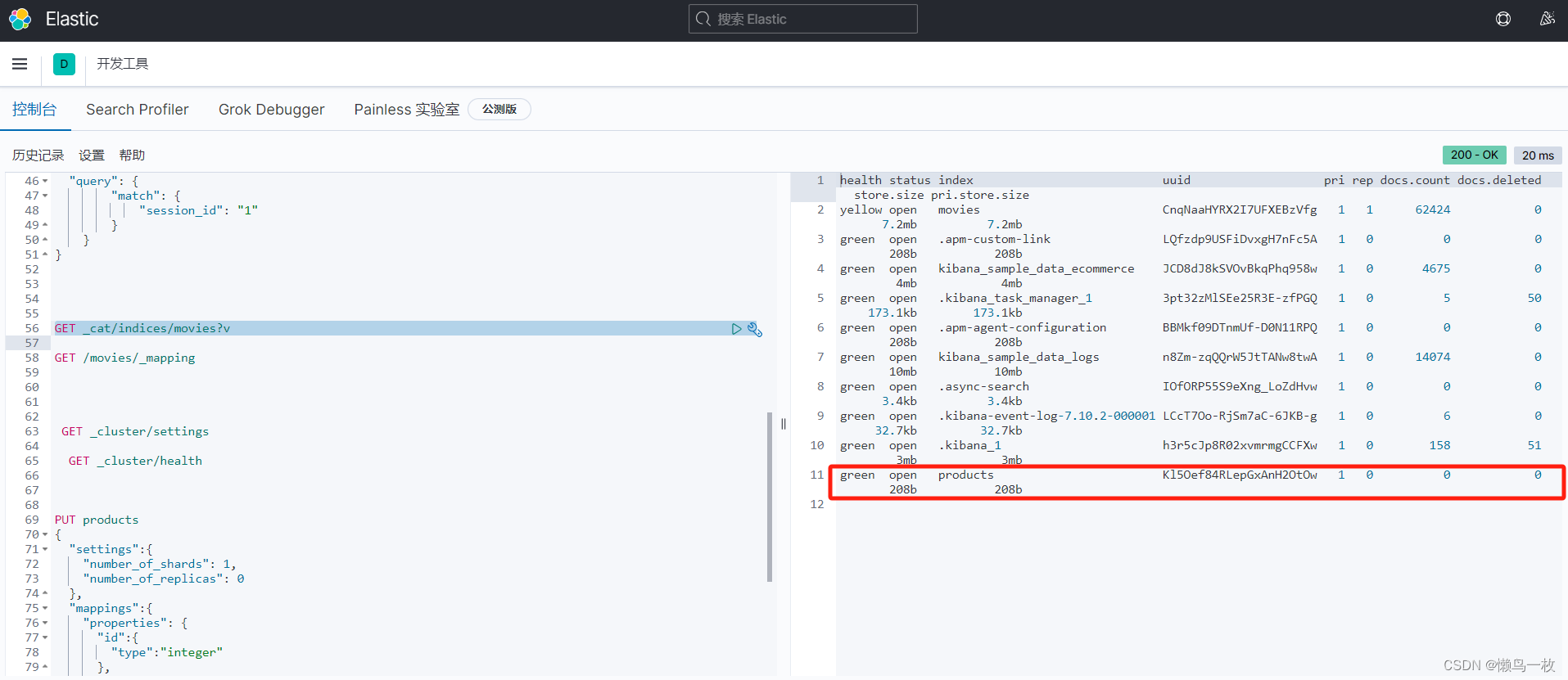
执行 查看索引语句
GET _cat/indices/movies?v
结果可以看到新建的索引
1、语法
#注:ES7之前_doc为实际type,之后为_doc;不过查询的时候_doc可省略。
GET /索引名/_doc/_search
{
json格式请求体数据
}
或者省略_doc(建议)
GET /索引名/_search
{
json格式请求体数据
}
2、query DSL——查询所有(match_all)
match_all关键字:返回索引中的全部文档。
GET /products/_search
{
"query":{
"match_all": {}
}
}
注:既然是match_all后面肯定不需要限定任何条件了;但是为了满足json格式所以这里要加个"{}"
3、query DSL——关键词查询(term)
重复三遍:文本匹配不要用term!文本匹配不要用term!文本匹配不要用term!(要用match)
term关键词:用来使用关键词查询。
①term搜索映射中的keyword类型应当使用全部内容搜索(如“大辣片”);
②text类型默认ES使用标准分词器;其分词逻辑为 对英文单词分词、对中文单字分词。
#keyword搜索完整关键词是能够搜到的
GET /products/_search
{
"query":{
"term": {
"title": "鱼豆腐"
}
}
}
注:上述描述json格式的K-V都可以换成如下。
"title":{
"value":"鱼豆腐"
}
#默认分词器下text搜索完整内容也是搜不到的
GET /products/_search
{
"query":{
"term": {
"description": "日本豆很好吃!!"
}
}
}
#默认分词器下text搜索单个汉字是能搜到的
GET /products/_search
{
"query":{
"term": {
"description": "好"
}
}
}
#默认分词器下text搜索单个英文单词也是能搜到的
GET /products/_search
{
"query":{
"term": {
"description": "nice"
}
}
}
4、query DSL——多关键词查询(terms)
terms关键词:用于某个关键词匹配多个值的查询。和 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配。
GET /products/_search
{
"query":{
"terms": {
"title": [
"大鸡腿",
"大辣片"
]
}
}
}
5、query DSL——范围查询(range)
range关键字:用来指定查询范围内的文档
#查询加个范围
GET /products/_search
{
"query":
{
"range": {
"price": {
"gte": 5,
"lte": 10
}
}
}
}
6、query DSL——前缀查询(prefix)
prefix关键字:用来检索含有指定前缀的关键词的相关文档。
#针对keyword类型是可以前缀查询到的
GET /products/_search
{
"query":{
"prefix": {
"title": {
"value": "小浣"
}
}
}
}
#针对text类型如果是英文的话也是可以前缀查到的
GET /products/_search
{
"query":{
"prefix": {
"description": {
"value": "goo"
}
}
}
}
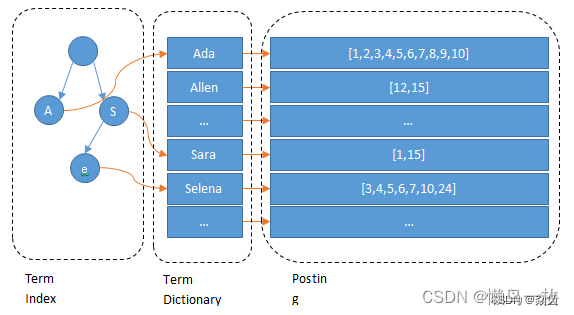
prefix查询不做相关度评分,它只是将所有匹配的文档返回,并为每条结果赋予评分值1。他的行为更像是filter而不是query,只不过这里不能像filter那样缓存罢了。在我们并没有对相应字段进行特殊处理还是以精确值的方式存的情况下,prefix查询是如何工作的呢?
个人理解应该是利用了Term Index和Term dictionary,对于邮编字段其对应的倒排表可能如下。为了支持前缀匹配就会去依次扫描Term Index中以目标前缀(如“W1”)为开头的term并收集关联文档(参见 这里 倒排索引部分)。显然,当倒排索引数据量很大的时候就会给集群带来很大的压力。总的来说当数据量比较小,或者数量不是很大但前缀又很长的情况下还是可以用的。
Term: Doc IDs:
-------------------------
"SW5 0BE" | 5
"W1F 7HW" | 3
"W1V 3DG" | 1
"W2F 8HW" | 2
"WC1N 1LZ" | 4
-------------------------
另外,为了加速prefix查询,还可以在设置字段映射的时候,使用index_prefixes映射。ES会额外建立一个长度在min_chars和max_chars之间索引,在进行前缀匹配的时候效率会有很大的提高。
Prefix query | Elasticsearch Guide [8.9] | Elastic
index_prefixes | Elasticsearch Guide [8.9] | Elastic
7、query DSL——通配符与正则表达式查询(wildcard/regexp)
wildcard 和 regexp 查询的工作方式与 prefix 查询完全一样,它们也需要扫描倒排索引中的词列表才能找到所有匹配的词,然后依次获取每个词相关的文档 ID ,与 prefix 查询的唯一不同是:它们能支持更为复杂的匹配模式。
wildcard关键字:通配符查询。 ?用来匹配一个任意字符 *用来匹配多个任意字符。
使用标准的shell通配符查询参考: ES官网点击直达
#对于text类型。这样是能查到的
GET /products/_search
{
"query":{
"wildcard": {
"description": {
"value": "goo?"
}
}
}
}
#这样是查不到的
GET /products/_search
{
"query":{
"wildcard": {
"description": {
"value": "go?"
}
}
}
}
注:因为good是description字段的一个分词。
这里 建议避免使用左通配的模式匹配(如 *foo 或 .*foo 这样的正则式),其原因应该就是匹配机制会尽量充分利用Term Index的数据。显然如果是左通配的话就利用不了Term Index了,此时很有可能就完全退化成遍历Term Dictionary。
8、query DSL——多id查询(ids)
ids关键字:值为数组类型,用来根据一组id获取多个对应的文档。
注:这里相当于指定字段就是docid,感觉用的不是很多了吧。
#注:这里就是限定死查询某些docid的数据,只能是docid。
GET /products/_search
{
"query": {
"ids": {
"values":["1","8"]
}
}
}
9、query DSL——模糊查询(fuzzy)
fuzzy关键字:用来模糊查询含有指定关键字的文档。
注意:fuzzy模糊 最大模糊错误必须在0~2之间
①搜索关键词长度为2不允许存在模糊
②搜索关键词长度为3~5允许一次模糊
③搜索关键词长度大于5最大2次模糊
#这样是可以查询到title为“小浣熊”的数据的
GET /products/_search
{
"query": {
"fuzzy": {
"title":"小浣猫"
}
}
}
10、query DSL——布尔查询(bool) 重要!!!!!
bool关键字:用来组合多个条件实现复杂查询,相当于逻辑操作。bool查询可以嵌套组合任意其他类型的查询,甚至继续嵌套bool查询也是可以的。
实际语法为:bool下面套filter/must/should/must_not实现逻辑效果(bool包含四种子句)。
①must:相当于&& 要求同时成立;
②should:1)相当于逻辑或的关系; 2)影响评分机制,会把匹配的更多的文档评分提高。
③must_not:相当于! 取非;
④filter: 可以将上述term、range等诸多条件都放在filter里面
注:关于filter参见下文专门的介绍。过滤查询(filter)不计算相关度速度非常快,一般都先用filter降低目标数据集后再去计算相关度。
注:filter可以放到bool条件下面,同样bool条件也可以放在filter下面。
#must 同时满足条件
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"term":{"title":"小浣熊"}
},
{
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
#should 满足一个条件即可
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"term":{"title":"小浣熊"}
},
{
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
#进一步组合也都是可以的
GET /products/_search
{
"bool": {
"filter":[
{"term":{"key1":value}}
{"range":{"key2":{"gt":value1,"lt":value2}}}
]
"must": { "term": { }},
"must_not": { "term": { }},
"should":
[
{ "term": { }},
{ "term": { }}
]
}
}
注:must可以是数组,即[];也可以不是数组,即{}.
11、query DSL——match查询(match) 重要!!!!
match:不仅会显示精确匹配的结果也会显示相似匹配的结果,非常强大。
原理:query可以输入关键词也可以输入一段文本。它会根据你实际查询的字段的类型决定是否对query内容进行分词。
①如果你查询的字段是分词的,它就会对你query的内容进行分词然后再去搜。
②如果该字段是不分词的就将查询条件作为整体进行查询。
#其本质是拿‘浣’去搜,现在就能匹配到数据;然后再拿‘猫’去搜。
GET /products/_search
{
"query": {
"match": {
"description": "浣猫"
}
}
}
#其本质是拿‘浣’去搜,现在就能匹配到数据;然后再拿‘鸡’去搜。显然就匹配到两条数据了。
GET /products/_search
{
"query": {
"match": {
"description": "浣鸡"
}
}
}
对于多个match语句组合的时候bool查询采取“more-matchs-is-better”(匹配越多越好)的方式,所以每条match语句的评分结果会被加在一起,从而为每个文档提供最终的_score。对于如下案例,显然能与两条语句同时匹配的文档比只与一条语句匹配的文档的得分更高。
12、query DSL——should
查询语句提升权重 | Elasticsearch: 权威指南 | Elastic
should是个很重要的语句,其包含两个层面的含义:
①或(or)的意思,可以同时匹配多个条件。
②影响评分机制,匹配should条件越多的文档评分就越高。
should影响相关度评分:
查询关于“full text search”的文档,同时希望为提及"Elasticsearch"和"Lucene"的文档给予更高的权重。这里“更高的权重”是指如果文档中出现了"Elasticsearch"或"Lucene"会比没有出现这些词的文档获得更高的相关度评分_score(出现在结果集的最前面) 。
#查询语句如下:
GET /_search
{
"query": {
"bool": {
"must": {
"match": {
"content": {
"query": "full text search",
#content 字段必须包含 full 、 text 和 search 所有三个词。
"operator": "and"
}
}
},
#如果content字段也包含 Elasticsearch 或 Lucene ,文档会获得更高的评分 _score。
"should": [
{ "match": { "content": "Elasticsearch" }},
{ "match": { "content": "Lucene" }}
]
}
}
}
should修饰符boost:
同样上述场景,如果我们想让包含 Lucene 的文档有更高的权重,并且包含 Elasticsearch 的文档与 Lucene的权重更高,此时如何处理?
此时可以通过boost来控制任何查询语句的相对权重,boost的默认值是1,大于1就会提升相对权重。
GET /_search
{
"query": {
"bool": {
"must": {
"match": {
"content": {
"query": "full text search",
"operator": "and"
}
}
},
"should": [
{ "match": {
"content": {
"query": "Elasticsearch",
"boost": 3 #这个条件更重要boost值为3
}
}},
{ "match": {
"content": {
"query": "Lucene",
"boost": 2 #这个条件比默认值重要boost值为2,但不及上面的Elasticsearch
}
}}
]
}
}
}
Note:
boost 参数被用来提升一个语句的相对权重( boost 值大于 1 )或降低相对权重(boost 值处于 0 到 1 之间,但是这种提升或降低并不是线性的.换句话说,boost值为2并不能获得两倍的评分 _score 。 相反,新的评分 _score 会在应用权重提升之后被 归一化 ,每种类型的查询都有自己的归一算法,细节此处不作介绍。简单的说,更高的boost值为我们带来更高的_score 。 如果不基于 TF/IDF 要实现自己的评分模型,我们就需要对权重提升的过程能有更多控制,可以使用 function_score 查询操纵一个文档的权重提升方式而跳过归一化这一步骤。
13、query DSL——multi_match查询(multi_match) 重要!!!!
原理同上,只不过换成了多个字段。
#如下是能搜到数据,本质上是从“description”字段搜到的。
GET /products/_search
{
"query": {
"multi_match": {
"query": "浣猫",
"fields": ["title","description"]
}
}
}
#确实这样去匹配keyword类型的title是不行的
GET /products/_search
{
"query": {
"multi_match": {
"query": "浣猫",
"fields": ["title"]
}
}
}
#description含有‘浣’和‘鸡’的都被搜出来了
GET /products/_search
{
"query": {
"multi_match": {
"query": "浣鸡",
"fields": ["title","description"]
}
}
}
14、query DSL——match_phrase查询(短语匹配) 重要!!!!
match和match_phrase的区别:
match是全文检索,这里的搜索条件是针对查询的字串分词后的所有项;只要发现和搜索条件相关的数据都会出现在结果集中。如果我们不想将我们的查询条件拆分,应该怎么办呢?这个时候就可以使用match_phrase。match_phrase是“短语搜索”,他会将给定的短语(phrase)当成一个完整的查询条件。举个简单的例子,如果你要查询的是“this is”。对于match来说会查询到含有“this”的数据和含有“is”的数据,但是对于match_phrase查到的则是必须含有“this is”的数据。
match_phrase一般用于短语匹配(Phrase Matching)!!
#插入如下三条数据
POST /products/_doc/
{
"title":"apple",
"price":"2.2",
"create_at":"2022-08-12",
"description":"this is apple"
}
POST /products/_doc/
{
"title":"orange",
"price":"2.0",
"create_at":"2022-08-12",
"description":"orange is sour"
}
POST /products/_doc/
{
"title":"banana",
"price":"1.5",
"create_at":"2022-08-12",
"description":"this fruit very delicious"
}
#返回所有包含“this”和“is”的三条数据
GET /products/_search
{
"query": {
"match": {
"description": "this is"
}
}
}
#仅返回了包含“this is”的一条数据
GET /products/_search
{
"query": {
"match_phrase": {
"description": "this is"
}
}
}
注:match_phrase也可以描述为类型为“phrase”的match
"match": {
"title": {
"query": "quick brown fox",
"type": "phrase"
}
}
举个例子对于匹配了短语"quick brown fox"的文档,意味着同时满足下面三个条件。
①quick、brown和fox必须全部出现在某个字段中。
②brown的位置必须比quick的位置大1。
③fox的位置必须比quick的位置大2。
如果以上的任何一个条件没有被满足,那么文档就不能被匹配。这样看来精确的短语匹配或许太严格了。
slop参数放松匹配条件:
也许我们想要包含“quick brown fox”的文档也能够匹配“quick fox”,此时我们可以使用slop参数将灵活度引入短语匹配中。
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick fox",
"slop": 1
}
}
}
}
slop参数告诉match_phrase查询词条相隔多远时仍然能将文档视为匹配。这个“相隔多远”的意思是为了让查询和文档匹配你需要移动词条多少次。显然,使用了slop后短语匹配的所有词项仍然都需要出现,但是这些词项不用按照相同的顺序匹配了。
看一个简单的例子。 为了让查询 quick fox 能匹配一个包含 quick brown fox 的文档, 我们需要 slop 的值为 1:

注:后面还会提到通过slop参数适当的放松匹配条件。
match_phrase匹配多值字段的问题及解决 —— position_increment_gap
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
#运行如下对"Abraham Lincoln"的短语查询,发现居然可以匹配到上面这条数据。
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
分析:这一切归根于ES对于数组的索引方式。
在分析 John Abraham 的时候, 产生了如下信息:
Position 1: john
Position 2: abraham
然后在分析 Lincoln Smith 的时候, 产生了:
Position 3: lincoln
Position 4: smith
换句话说, Elasticsearch对以上数组分析生成了与分析单个字符串 John Abraham Lincoln Smith
几乎完全相同的语汇单元。我们的查询示例寻找相邻的 lincoln 和 abraham,而且这两个词条确实存在,
并且它们俩正好相邻,所以这个查询匹配了。
注:这个也是nested要解决的问题,参见 6.ELK之Elasticsearch嵌套(Nested)类型-CSDN博客
解决:对于这个问题我们可以通过在数组元素之间添加“假的”间隙的方式进行避免。如下:
DELETE /my_index/groups/
#其含义是告诉ES应该为数组中的每个元素增加词条的position,相当于指定了数据元素之间的间隙。
PUT /my_index/_mapping/groups
{
"properties": {
"names": {
"type": "string",
"position_increment_gap": 100
}
}
}
于是,数据的实际组织样式如下,即abraham和lincoln之前的距离为100.
Position 1: john
Position 2: abraham
Position 103: lincoln
Position 104: smith
#此时除非指定slop为100,否则就不会匹配到这条数据了。
关于性能(强大肯定有强大的代价):
(1)一个match查询仅仅是看词条是否存在与倒排索引中,而match_phrase查询是必须计算并比较多个可能重复词项的位置;显然后者更慢。
(2)Lucene nightly benchmarks表明一个简单的term查询要比一个match_phrase快10倍,比相邻查询(有slop的短语查询)大约快20倍。
(3)如何限制短语查询和slop短语查询的性能消耗?一个可行的思路是减少短语查询检查的文档总数。具体来说可以通过代价更低的match查询获取含有搜索词条的文档,而且这个文档也是排序的;接下来在利用match_phrase对其中匹配了短语查询的文档做一个额外的相关度升级就可以了
#match查询决定了哪些文档会包含在最终结果集合中,并通过TF/IDF排序。
#windos_size是每一分片进行重新评分的顶部文档数量;
#然后在通过query查询进行重新打分。注:这个可能有其他方式了。
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "quick brown fox",
"minimum_should_match": "30%"
}
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"title": {
"query": "quick brown fox",
"slop": 50
}
}
}
}
}
}
注:关于rescore参见 官网
注:10倍、20倍的说法其实更大程度上表名term有多快,实际上短语查询的耗时也没有那么夸张是完全可用的。
15、query DSL——查询是否包含某个字段(exists)
exists 过滤可以用于查找文档中是否包含指定字段或没有某个字段
#查询包含“id”字段的数据
GET /products/_search
{
"query": {
"exists": {"field":"id"}
}
}
16、指定返回条数(size)
size关键字:指定查询结果中返回指定条数的数据。注:默认返回10条。
注:size的书写位置没有顺序,最前面、中间、后面都是可以的;符合json规范就成。
#满足条件的有三条,这里限定只返回2条
GET /products/_search
{
"query": {
"match": {
"description": "this is"
}
},
"size":2
}
17、分页查询(from)
from关键字:用来指定起始返回位置,和size连用可以实现分页效果。
#第一把
GET /products/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size":5
}
#翻页第二把
GET /products/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size":5
}
18、指定字段排序(sort)
注意:sort和最外层的query平齐!!!!
#desc:降序
#asc:升序
GET /products/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
注意:因为排序干扰了ES内部的默认搜索,所以一旦排序后ES的查询结果中就没有score得分了。
19、指定返回字段(_source)
_source关键字:是一个数组,在数组中指定展示哪些字段。
注意:这里的“_source”也是和最外层的“query”平齐的。
GET /products/_search
{
"query": {
"match_all": {}
},
"_source": ["title","price"]
}
20、更多的查询命令: ES官网点击直达
21、理解相关性(relevance score)
什么是相关性? | Elasticsearch: 权威指南 | Elastic
Elasticsearch 默认使用词频/逆向文档频率(TF/IDF) 相似度算法。词频
是计算某个词在当前被查询文档里某个字段中出现的频率,出现的频率越高,文档越相关。 逆向文档频率 将 某个词在索引内所有文档出现的百分数
考虑在内,出现的频率越高,它的权重就越低。
被破坏的相关度! | Elasticsearch: 权威指南 | Elastic
参照这篇文档我也也应该知道相关度还是建立在数据足够大、数据均化的情境下。如果认为的去制造数据我们很容易制造出无法满足相关度排序的数据集。
22、关于ES搜索的思考
其实ES的玩法就是以空间换时间,只不过在空间利用上会采用近乎极致的压缩算法。其思想就是在搜索之前就把供搜索的数据(其实是不分词条)提前准备好,建好索引等着你去用。关于究竟事先准备哪些词条这个其实就是分词器、分词算法要做的事情,关于怎么高效精炼的键索引就是倒排索引的设计优化。
二、Filter查询
结构化搜索 | Elasticsearch: 权威指南 | Elastic
Query and filter context | Elasticsearch Guide [8.11] | Elastic
准确来说ES中的查询实际上有两种:**查询(Query context)和过滤(Filter Context)。**
1、Query就是前面演示的用法,它默认会计算每个返回文档的得分然后还会根据得分进行排序;
2、Filter只会筛选出符合条件的文档(不计算相关度得分)所以执行速度非常快,而且Filter很容易被缓存。
记住:应当尽可能地使用过滤式(Filter)查询.
一般玩法都是会尽量优先使用过滤(filter)尽最大可能降低操作的数据量,然后在用query进行匹配查询(相关度排序)。

#filter可以放在bool内部
GET /products/_search
{
"query":{
"bool": {
"filter":[
{"term":{"key1":value}}
{"range":{"key2":{"gt":value1,"lt":value2}}}
],
"must":[
{ "term": { }}
],
"must_not":[
{ "term": { }}
],
"should":
[
{ "term": { }},
{ "term": { }}
]
}
}
}
#bool也可以放在filter内部
GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
}
}
#同时都存在也是可以的。如下:
#最外层的bool包括了filter和must;
#其中的filter又是一个bool语句,其中包括了should和must_not
#minimum_should_match: https://blog.csdn.net/qq_26322753/article/details/122536803
#注:这个case只是演示,实际使用的时候过滤性的条件应当尽量放在filter这样效率才高。
GET es_xx_flow_oa_v2_202310/session/_search?routing=2852199330
{
"size":300,
"query":{
"bool":{
"filter":{
"bool":{
"should":[
{
"term":{"kfext":3007458843}
},
{
"term":{"robotid":9936786511}
}
],
"minimum_should_match": 1,
"must_not":[
{
"term":{"robotid":10400}
}
]
}
},
"must":[
{
"range":{
"flow_time":{
"lt":1696930580
}
}
},
{
"match":{
"msg_content":"你好"
}
}
]
}
}
}
注意:在执行filter和query时,ES会先执行filter,后执行query。
注意:filter不一定针对keyword类型,对于text类型也一样可以先通过filter降低目标数据量。总之只要能降低目标数据集的范围就可以了,这才是使用filter的条件。
常见的过滤类型有:term、terms、range、exists、ids等filter。
三、聚合查询(Aggregation aggs)
简单来讲类似于sql中的group by。
注:text类型是不支持聚合的。
为了便于测试创建如下索引
PUT fruit
{
"mappings": {
"properties": {
"title":{
"type":"keyword"
},
"price":{
"type":"double"
},
"description":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
GET fruit
#并插入如下数据
POST fruit/_bulk
{"index":{}}
{"title":"面包","price":19.9,"description":"小面包很好吃"}
{"index":{}}
{"title":"大白兔","price":29.9,"description":"大白兔奶糖好吃"}
{"index":{}}
{"title":"日本豆","price":19.9,"description":"日本豆非常好吃"}
{"index":{}}
{"title":"旺仔小馒头","price":19.9,"description":"旺仔小曼斗很甜"}
{"index":{}}
{"title":"大辣片","price":9.9,"description":"大辣片很诱人"}
{"index":{}}
{"title":"脆司令","price":19.9,"description":"脆司令很管饿"}
{"index":{}}
{"title":"喜之郎果冻","price":19.9,"description":"小时候的味道"}
1、根据某个字段分组
语法:其语法就是在query平齐的位置加上一个aggs。
#如下为一个实例。
#其中"shuozhuo_price_group"为此次聚合的结果随便取的一个名字;这个名字是我们自定义的。
#terms也是写死的。其含义是基于那个字段进行分组。
GET /fruit/_search
{
"query": {
"match_all": {}
},
"aggs": {
"shuozhuo_price_group": {
"terms": {
"field": "price"
}
}
}
}
#仅返回结果,不返回原始数据
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0, #
"aggs": {
"shuozhuo_price_group": {
"terms": {
"field": "price"
}
}
}
}
返回结果如下:
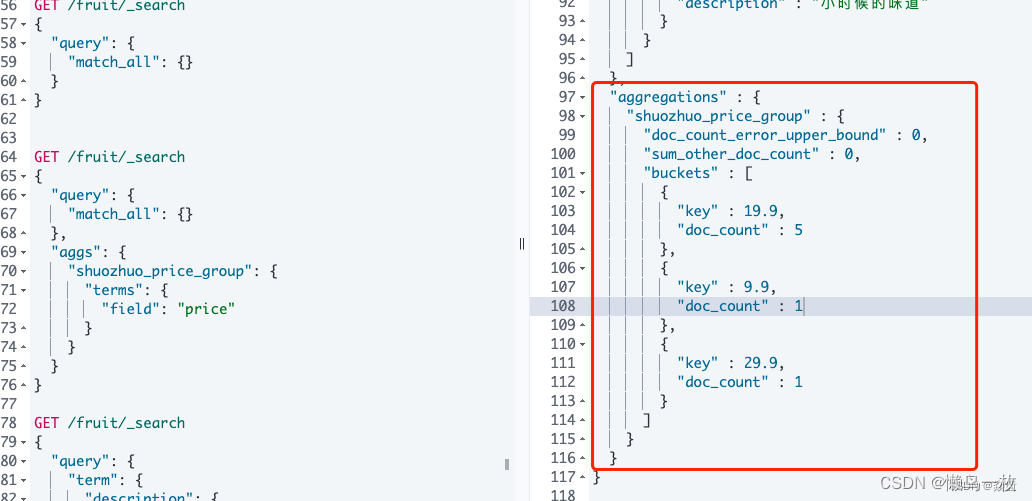
整个返回中的aggregations字段就是聚合结果;
buckets是一个数组表示的就是聚合后的数组;
注:如果只想返回聚合结果不想返回查询数据的话,利用size就好了。
2、求最大值/最小值/平均值
#最大值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_max_price": {
"max": {
"field": "price"
}
}
}
}
#最小值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_min_price": {
"min": {
"field": "price"
}
}
}
}
#平均值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_avg_price": {
"avg": {
"field": "price"
}
}
}
}
#求和
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_sum_price": {
"sum": {
"field": "price"
}
}
}
}
关于聚合还有很多其他字段,以如下为例说明每个字段的含义。参考 这里
#如下所示的查询语句就是先利用filter过滤目标数据,然后在用must
{
"size" : 0,
"query" : {
"bool" : {
"filter" : [
{"range" : {"time" : {"gte" : 1511924400, "lte" : 1551595501}}},
{"term" : {"kfuin" : 2852199336}}
],
"must" : {
"bool" : {
"should" : [
{"match_phrase" : { "msg.ik" : {"query" : "1", "slop" : 0}}}
],
"minimum_should_match" : 1
}
}
}
},
"aggs" : {
"customer_msgnum_aggs" : {
"terms" : {
"field": "acc_aggr_field", #根据acc_aggr_field字段聚合
"size" : 10, #指定返回的聚合结果数;默认返回前10个聚合结果。这个顺序是后面order指定的顺序
"collect_mode" : "breadth_first",
"execution_hint": "map" ,
"order" : {
"customer_max_time" : "desc"
}
},
"aggs" : {
"customer_max_time" : {
"max" : {
"field" : "time"
}
},
"customer_msg" : {
"top_hits" :{"size" : 1, "_source" : {"includes" : [ "msg", "flow_type", "time", "relation_type", "kfext"]}}
}
}
}
}
}
(0)query→bool→must→match_phrase。
①query:就是你要查询的短语;
②slop:精确短语(Exact-phrase)匹配也许太过于严格了。也许我们希望含有"quick brown fox"的文档也能够匹配"quick fox"查询,即使位置并不是完全相等的。slop参数就是用来引入一些灵活性的。slop参数告诉match_phrase查询词条能够相隔多远时仍然将文档视为匹配。相隔多远的意思是,你需要移动一个词条多少次来让查询和文档匹配?
(1)query→bool→must→minimum_should_match
举个例子,用户给定5个查询词想要查找包含其中3个term以上的文档,要如何控制?
minimum_should_match就可以实现精度控制。它表示查询语句在匹配分词的时候至少应该匹配几个term。这里设为1就能保证查询的语句和命中的数据中至少有一个term是匹配的。注:查询到的数据肯定要和查询字串要有一点相关才行,就是这里保证的了。
(2)customer_msgnum_aggs:为聚合结果自定义的一个名字。
(3)size :指定返回的聚合结果数;默认返回前10个聚合结果,这个顺序是后面order指定的顺序。
(4)collect_mode:通过参数 collect_mode = breadth_first 设置可以将子聚合计算延迟到上层父级被剪切之后再计算。注:这里应该是因为后面嵌套了一个 customer_max_time 子聚合所以才额外指定一下的。
①breadth_first 模式是优先进行广度遍历计算,计算完上层的聚合结果后,再进行每个桶的聚合结果计算;
②depth_first 模式是优先进行深度遍历计算,每个分支进行一次深度遍历计算,然后再进行剪切;
③如果某个字段的 cardinality 大小比请求的 size 大或者这个字段的 cardinality 是未知的,那么默认是 breadth_first,其它默认是 depth_first
(5)Execution hint:提供了两种聚合计算的方式,map 和 global_ordinals。
①global_ordinals 模式。对于海量的数据聚合计算,ES 使用一种 global ordinals 的数据结构来进行 bucket 分配,通过有序的数值来映射每一个 term 字符串实现内存消耗的优化。
②map 模式。直接将查询结果拿到内存里通过 map 来计算,在查询数据集很小的情况下使用 map会加快计算的速度。
默认情况下只有使用脚本计算聚合的时候才使用 map 模式来计算。即使你设置了 map,ES 也不一定能保证一定使用 map 去做计算,一般情况下不需要关心 Execution hint 设置,ES 会根据场景选择最佳的计算方式
(6)order:就是指定排序。这里指定time字段降序排列。
一个例子如下:
GET es_XXXXXX_flow_oa_20200623/session/_search?size=100
{
"size":30,
"_source":[
"qq_uin",
"start_time"
],
"query": {
#bool过滤:可以用来合并多个多虑天剑查询结果的布尔逻辑
"bool": {
#相当于and,里面包括多个term时要中括号
"must":[
{
"term": {
"session_id": "staff_2854099021_2852996969_2113136800_1592497021783"
}
},
{
"term":{
"msg_direction": 1
}
},
#精确匹配文本:用match_phrase替换term即可
{
"match_phrase":{
"CustomerNickname": "uidXXXX4759"
}
},
{
#允许按照指定范围查找
"range":{
"flow_time":{
"gt":1592842504,#gt:大于
"lt":1592842955 #lt:小于
}
}
}
],
#相当于not
"must_not":
{
"term":{
"flow_time":1592842726
}
}
}
}
}
四、条件更新/删除数据 —— _update_by_query/_delete_by_query
1、条件删除数据
(1)把GET方法换成POST方法
(2)把 _search 换成 _delete_by_query 。
(3)注意:这东西可能会有延迟,执行删除操作后query语句会完10s左右看到没有这些数据了。
POST es_xxxxx_flow_oa_20210625/session/_delete_by_query
{
"size":1000,
"query":{
"bool":{
"must":[
{
"term":{
"account_type":0
}
},
{
"term":{"kfuin":2852199234}
},
{
"range":{
"flow_time":{
"gte":1602642490,
"lte":1642642492
}
}
}
]
}
}
}
2、条件更新数据
如下所示查询语句能够查询到对应的两条数据。我现在想把其中的kfext字段更新成别的数值。
GET es_qidian_flow_oa_v2_202112/session/_search?routing=2852159342
{
"query":{
"bool": {
"must":[
{
"term":{
"kfuin":2852159342
}
},
{
"term":{
"kfext":321321321
}
}
]
}
}
}
更新语句如下:
POST es_qidian_flow_oa_v2_202112/session/_update_by_query?routing=2852159342
{
"script": {
"lang":"painless",
"source": "ctx._source.kfext=params.kfext",
"params":{
"kfext":321321321
}
},
"query":{
"bool": {
"must":[
{
"term":{
"kfuin":2852159342
}
},
{
"term":{
"kfext":123123123
}
}
]
}
}
}
注:其中的js语句写成如下也是可以的
"script": {
"source": "ctx._source['kfext']=321321321"
},
注意:_update_by_query关键词不要拼错了,这里拼错了es是不会给出报错的。
注意:更新操作后需要有个生效时间,理论上不超过1min就可以生效。
注意:我们可以单独根据docid来查询每条数据看看这条数据的更新情况,
#根据docid GET一条数据
GET es_qidian_flow_oa_v2_202112/session/AX8fyE9VFSj-ki1XGBzE?routing=2852159342
注:对于上述语句根据es版本的不同可能有的需要加type(我们这里就是session),有的可能有不需要。
#其中的_version就是这条数据的版本号,没改动一次就增加1.
{
"_index": "es_qidian_flow_oa_v2_202112",
"_type": "session",
"_id": "AX8fyE9VFSj-ki1XGBzE",
"_version": 3,
"_routing": "2852159342",
"found": true,
"_source": {
"account_type": 2,
"flow_time": 1640148231,
"session_id": "",
"relation_type": 0,
"kfuin": 2852159342,
"robotid": 0,
"account_aggr_field": "2_2852406034",
"qqpub": 0,
"flow_type": 2,
"kfext": 123123123,
"msg_content": "长时间未收到您的消息",
"retract_msg": 0,
"msg_type": 0,
"msg_direction": 1,
"account": "2852406034"
}
}
条件删除语句和上面差不多,如下为一个实例:
POST es_qidian_flow_oa_v2_202112/session/_delete_by_query
{
"query":{
"bool": {
"must":[
{
"term":{
"kfuin":2852159342
}
},
{
"term":{
"kfext":321321321
}
}
]
}
}
}

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









