






目的:要在hbase集群上来运行hbase shell
hbase要依赖HDFS(现在搭的暂时不依赖YARN)
【单节点的hbase是玩具,根本没法应用于生产环境】
先停掉单节点hbase:./stop-hbase.sh
再将HDFS启动起来,我们的HDFS也是个集群,有两个namenode,因此我们要先启动zookeeper:cd /itcast/zookeeper 然后./zkServer.sh start 然后在05上面也把zookeeper启动起来 再把06的ZK启动起来 第一台机器启动起来了要等别人,第二台是follower【不确定】
现在,我要在第一台机器上启动,因为我在第一台机器上设置了到其他机器上的 ssh免登陆,比较方便
我cd到/itcast/hadoop2.2.0/sbin下面,然后./start-dfs.sh
启动顺序:先启动namenode,再启动所有datanode,再启动journal,再启动ZKFC
在网络上看一眼,三个活着的datanode,等等blabla【这地方因为我没有配置集群,没那么多台机器,所以暂时没有发现毛病】
hbase的集群安装比单节点安装复杂。
我先在一台机器上修改配置文件,再拷贝到其他节点
cd到/itcast/hbase/conf 修改hbase-site.xml :vim hbase-site.xml
以前我是写了一个本地文件系统的存储路径

以后要将数据存储到HDFS上,因此我应该写一个HDFS路径,【我不能写具体的某个itcast01:9000或者02:9000】,应该写它的抽象。写nameservice hdfs://ns1/hbase这是它的根目录
还要配置分布式的属性,hbase中也有老大,小弟,老大和小弟协调用的是也是zookeeper,因此也要配置zookeeper地址。【一会儿通过复制粘贴配】
还要配hbase-env.sh【集群模式要配了】 vim hbase-env.sh
有一个 export HBASE_MANAGERS_ZK=TRUE,现在集群模式我要用外面的ZK,把这个改成false,不要使用自己的ZK了。保存退出
拷贝这个文件,然后用notepad找到hbase的安装目录/itcast/hbase/conf/hbase-site.xml 修改
我现在要告诉它:hbase集群distributed改为true,然后再复制下zookeeper地址就可以了。
3.配置hbase集群,要修改3个文件(首先zk集群已经安装好了)
注意:要把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
3.1修改hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_55
//告诉hbase使用外部的zk
export HBASE_MANAGES_ZK=false
vim hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- 指定hbase是分布式的,是一个集群模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址【zk的地址在前面配置好了】,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>itcast04:2181,itcast05:2181,itcast06:2181</value>
</property>
</configuration>
保存关掉hbase-site.xml
继续,还要配
我要指定hbase的小弟在哪个地方启动,在conf里:vim regionservers 这个就是hbase的小弟(hbase的老大是hmaster),它保存了一个区域的数据,这个配置文件和hadoop的slaves配置文件相似,因为都是小弟。
默认的文件是local host,我们要改。(假设hbase有4个节点,在03040506启动节点)
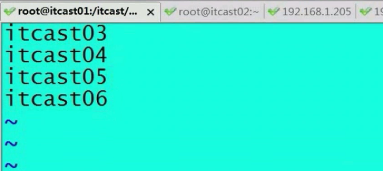
保存并退出。
现在hbase已经完全配置好了。现在将这台配置好的hbase拷贝到其它节点就可以了。拷贝方式:scp -r/itcast/hbase-0.9-hadooop2 / itcast02【换成03,04,05,06】:/itcast/
1上有0203040506免登陆,因此我在01上启动hbase:./start-hbase.sh 此时jps之后,hmaster启动起来了,但是regionserver没有启动起来。
原因:ns1下边有几个namenode,每个namenode都在哪台机器上,hbase不知道。
【有一个小问题】,
方法:我将那两个文件(core-site.xml,hdfs-site.xml)拷贝到hbase的conf目录里即可。
先停止./stop-hbase.sh
我要将决定映射关系的这两个配置文件拷贝到hbase的conf目录(所有的节点都要拷):scp /itcast/hadoop-2.2.0/etc/hadoop/ core-site.xml hdfs-site.xml itcast01【0203040506】:/itcast/hbase-/conf
下一次hbase启动之后,会读core-site.xml这两个配置文件。
./start-hbase.sh
再jps之后,就多了一个hregionserver (小弟)
通过管理界面来看:192.168.1.201:60010
在这种我们可以看到,backup master数目为0,意味着没有备用的hmaster

有一个老大不安全,我们应该再启动一个hmaster: cd/bin目录下 ./hbase-daemon.sh start master
再jps之后,里面有hmaster了。
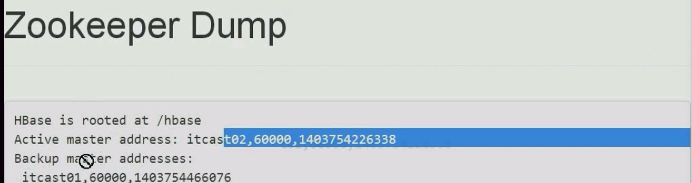
但是两个hmaster得一个活跃的,一个是stand by的。得需要zookeeper协调,再进入那个网站,可以看到backup master
Q:这两个hmaster能不能进行自动切换?
A:我试一试 先JPS 看一眼标签, kill -9 6182
现在再访问:192.168.1.202 (不是201)了 可以打开
打开“zookeeper dump”,可以看到02状态是active
现在把01的再打开 ./hbase-deamon.sh start master
此时02为active,01为backup
本地文件存放了数据 /root/hbase
集群模式,我的文件存放在hdfs上面,./hbase shell
进入shell模式,list显示表 现在没有表
create ‘user',指定两个列族'info','data'
再list一下,就能看到user了,详细地看 describe 'user'
发现,没有指定versions,就默认为1

怎么插入数据? put 'user','rk0001',【这是一个row key】,'info:name','zhangsan'
插入结束之后,scan 'user'
里面有数据。再刷新一下hbase管理界面
Tables里面有一个user table 看到一个user
附:hbase shell 的一些命令:
进入hbase命令行
./hbase shell
显示hbase中的表
list
创建user表,包含info、data两个列族
create 'user', 'info1', 'data1'
create 'user', {NAME => 'info', VERSIONS => '3'}
向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan
put 'user', 'rk0001', 'info:name', 'zhangsan'
向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female
put 'user', 'rk0001', 'info:gender', 'female'
向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20
put 'user', 'rk0001', 'info:age', 20
向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture
put 'user', 'rk0001', 'data:pic', 'picture'
获取user表中row key为rk0001的所有信息
get 'user', 'rk0001'
获取user表中row key为rk0001,info列族的所有信息
get 'user', 'rk0001', 'info'
获取user表中row key为rk0001,info列族的name、age列标示符的信息
get 'user', 'rk0001', 'info:name', 'info:age'
获取user表中row key为rk0001,info、data列族的信息
get 'user', 'rk0001', 'info', 'data'
get 'user', 'rk0001', {COLUMN => ['info', 'data']}
get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
获取user表中row key为rk0001,列族为info,版本号最新5个的信息
get 'people', 'rk0002', {COLUMN => 'info', VERSIONS => 2}
get 'user', 'rk0001', {COLUMN => 'info:name', VERSIONS => 5}
get 'user', 'rk0001', {COLUMN => 'info:name', VERSIONS => 5, TIMERANGE => [1392368783980, 1392380169184]}
获取user表中row key为rk0001,cell的值为zhangsan的信息
get 'people', 'rk0001', {FILTER => "ValueFilter(=, 'binary:图片')"}
获取user表中row key为rk0001,列标示符中含有a的信息
get 'people', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
put 'user', 'rk0002', 'info:name', 'fanbingbing'
put 'user', 'rk0002', 'info:gender', 'female'
put 'user', 'rk0002', 'info:nationality', '中国'
get 'user', 'rk0002', {FILTER => "ValueFilter(=, 'binary:中国')"}
查询user表中的所有信息
scan 'user'
查询user表中列族为info的信息
scan 'people', {COLUMNS => 'info'}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'persion', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
查询user表中列族为info和data的信息
scan 'user', {COLUMNS => ['info', 'data']}
scan 'user', {COLUMNS => ['info:name', 'data:pic']}
查询user表中列族为info、列标示符为name的信息
scan 'user', {COLUMNS => 'info:name'}
查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
查询user表中列族为info和data且列标示符中含有a字符的信息
scan 'people', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan 'people', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
查询user表中row key以rk字符开头的
scan 'user',{FILTER=>"PrefixFilter('rk')"}
查询user表中指定范围的数据
scan 'user', {TIMERANGE => [1392368783980, 1392380169184]}
删除数据
删除user表row key为rk0001,列标示符为info:name的数据
delete 'people', 'rk0001', 'info:name'
删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete 'user', 'rk0001', 'info:name', 1392383705316
清空user表中的数据
truncate 'people'
修改表结构
首先停用user表(新版本不用)
disable 'user'
添加两个列族f1和f2
alter 'people', NAME => 'f1'
alter 'user', NAME => 'f2'
启用表
enable 'user'
###disable 'user'(新版本不用)
删除一个列族:
alter 'user', NAME => 'f1', METHOD => 'delete' 或 alter 'user', 'delete' => 'f1'
添加列族f1同时删除列族f2
alter 'user', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
将user表的f1列族版本号改为5
alter 'people', NAME => 'info', VERSIONS => 5
启用表
enable 'user'
删除表
disable 'user'
drop 'user'
get 'person', 'rk0001', {FILTER => "ValueFilter(=, 'binary:中国')"}
get 'person', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info:name'}
scan 'person', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
scan 'person', {COLUMNS => 'info', STARTROW => '20140201', ENDROW => '20140301'}
scan 'person', {COLUMNS => 'info:name', TIMERANGE => [1395978233636, 1395987769587]}
delete 'person', 'rk0001', 'info:name'
alter 'person', NAME => 'ffff'
alter 'person', NAME => 'info', VERSIONS => 10
get 'user', 'rk0002', {COLUMN => ['info:name', 'data:pic']}
scan 'people', {COLUMNS => 'info',RAW => true, VERSIONS => 3}















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









