








TDH社区版家族迎来新成员
不知不觉社区版已经陪伴大家将近两年的时间了,在这两年里收获到了很多认可,同时也收获到了一些建议与意见,比如资源成本的问题。在去年我们发布了TDH社区开发版,仅需单台服务器即可一键安装部署Inceptor关系型分析引擎以及Hyperbase NoSQL宽表数据库,降低资源成本的同时充分提升了开发效率。
发布后获得了很多用户的关注与喜欢。为了进一步满足用户在多样化数据检索以及使用图模型探索复杂的关联关系等方面的需求,此次社区开发版正式推出Scope搜索引擎以及StellarDB图数据库。

社区开发版让众多开发爱好者可以0成本、低门槛快速的构建数据开发环境,无论您是想快速地体验企业级产品功能,亦或是想要学习了解相关技术,社区开发版都能很好地满足您的需求。
- 开箱即用:Scope社区开发版及StellarDB社区开发版同样采用了all-in-one全内置设计的产品包形式,将各类核心服务深度整合于一体,开箱即可用。免去了平台安装的步骤,只需三步即可一键启动。用户无需花费大量时间和精力来进行环境配置、安装部署,平台预先设置了最佳的默认参数配置,确保了用户在部署时能享受到前所未有的简便快捷;
- 低成本:社区开发版充分降低了用户的使用门槛以及资源成本,单台服务器即可一键部署。自研的统一SQL引擎更是进一步降低了用户的整体学习成本和应用开发门槛;
- 企业级管理套件:社区开发版同样配备了企业级管理套件,比如对所有组件与服务进行统一管理的平台Manager、全方位监控系统负载与任务运行状况的平台监控软件Aquila Insight、提供身份认证与精细化权限安全管理软件Guardian。通过完备的管理组件,用户得以全面而精确地把握产品环境整体的运行情况,真正做到运维无忧。
以下为相关资源链接:
- 产品下载地址: 下载官网
- 产品安装教程: 安装手册(内含视频教程)
- 产品升级教程: 升级手册(内含视频教程)
- Scope使用手册: 手册
- StellarDB使用手册: 手册
- 【0-1系列】快速了解搜索引擎Scope
- 使用图数据库进行人物关系探索Demo示例及教程
- 使用图数据库进行反洗钱之银行转账流水数据分析
版本全线更新,全面解决小文件、数据倾斜等问题
TDH社区开发版以及社区版让众多的开发爱好者可以“0成本”“低门槛”,快速的构建数据开发环境。无论用户是想快速体验企业级产品功能还是想要学习了解相关技术,都能够很好的满足用户的需求。
此次社区版家族还针对版本做了更新。
新版本特性可查看: ReleaseNotes


更新点1. 小文件问题救星来了
大数据场景下会产生海量文件,随着每日增量数据的插入以及可能的数据重复插入,HDFS上的文件数与日俱增,达到千万甚至上亿的级别。当小文件过多时,将会导致长GC、OOM、集群不稳定,增加计算资源的开支等一系列问题。因此小文件治理是必要的也是迫切的。
星环产品针对不同表格式均有对应的Compact机制,譬如针对Holodesk表用户可以使用Compact Service(小文件合并专用服务)进行小文件合并任务,该服务在组件级别做了隔离,开启后不会影响到Quark的查询计算性能,合并效果更好。
但是在Inceptor跑批场景下会涉及ORC等非事务表,其不像事务表有文件合并的逻辑。而且,开源产品的方案通常是在任务运行结束后再去起一个Job执行合并任务,但是在这个阶段,表无法对外提供服务,只能读不能写,相关业务会受到影响。
所以星环采用了全新的技术,针对这个场景做了设计了新的算法,在任务运行过程中动态的执行小文件合并操作,能够确保在合并过程中Quark端的业务,包括表的读,写,删除等操作能够不被长时间阻塞,并成功执行不报错。
社区版今年将企业版针对非事务表小文件治理方面的功能Galactus做了引入,社区版用户也可以高效治理自己集群内的小文件,无需担心因为处理不及时或有疏漏影响到业务系统。更多原理解析及使用教程可查看: Text/ORC非事务表合并最佳方式
除了非事务表小文件更新的能力之外,社区版此次也引入了归档分区功能,针对一些较少访问及更改的历史数据及分区信息,用户可以选择跨分区进行合并,从而进一步的去减少存储开销、元数据管理的开销以及处理时的任务调度开销。 归档分区介绍及使用方法
更新点2. 数据倾斜治理好帮手
数据倾斜指的是说在并行处理海量数据的时候,单个task上需要处理大量的数据。一些处理节点会比其他节点需要更长的时间运行才能完成数据计算,这样既限制了并行处理的效率,也造成了空闲处理节点的资源浪费,系统将无法充分利用节点进行并行处理,十分影响性能和效率。
当在计算过程中出现数据倾斜的问题时,通常可以通过采用针对倾斜的key单独处理或MapJoin等方式进行处理。但是比如像MapJoin主要适用于大小表关联的情况。
社区版此次针对大表与大表之间进行关联发布了新的SkewJoin功能,可以在一定程度缓解大表关联场景下的数据倾斜问题。
更多原理解析及使用教程可查看:SkewJoin原理解析及使用介绍
更新点3. 全新Manager
Manager是保障集群稳定运行最高效的方式,它为底层每个核心组件都提供了强大的统一管理及运维能力。所以这次Manager针对UI,监控服务的集成也做了全新的优化升级,解锁新增了各项创新功能之外,也做了系统范围内的性能提升。
比如说开源产品在管理大集群方面一直以来都存在一些挑战,社区版在管理集群的能力上跟企业版保持了一致,所以这次也针对大集群下的集群安装,节点上下线的管理,以及服务的配置,启动等方面做了全方位的性能提升,操作速度更快也更稳定了。即使是数百上千个节点,在生产上也不用担心。
更多Manager新版本特性可查看: ReleaseNotes
TDH社区订阅版迎来最强辅助,TDS开发套件强势来袭
企业在信息化过程中积累了大量的业务系统和数据,TDH社区订阅版的发布,为企业在整合已有的海量多维度、多样化数据、数据统一化等方面的业务需求提供了有力支持。那么在构建数据仓库或数据湖的过程中,除了需要构建统一的计算和存储平台,进行统一的元数据管理之外,利用数据开发套件支持数据汇聚和开发也是企业数据平台建设过程的关键。
星环科技大数据开发工具 Transwarp Data Studio (TDS)为企业提供了一个一站式统一的数据开发平台,各个套件可以支持多个场景的使用需求,如数据开发场景、数据治理场景或者综合性的数据中台场景。针对更加细化的细分场景如任务流调度、血缘分析或数据资产门户等,TDS可以支持任意组件组合的形式,提供产品能力服务。
此次社区订阅版上架的TDS数据开发套件(SQLBook/Workflow/Transporter)提供了数据集成、SQL开发和任务调度的能力,帮助企业将数据归集到数据仓库和数据湖,可以更高效地完成数据统一化。
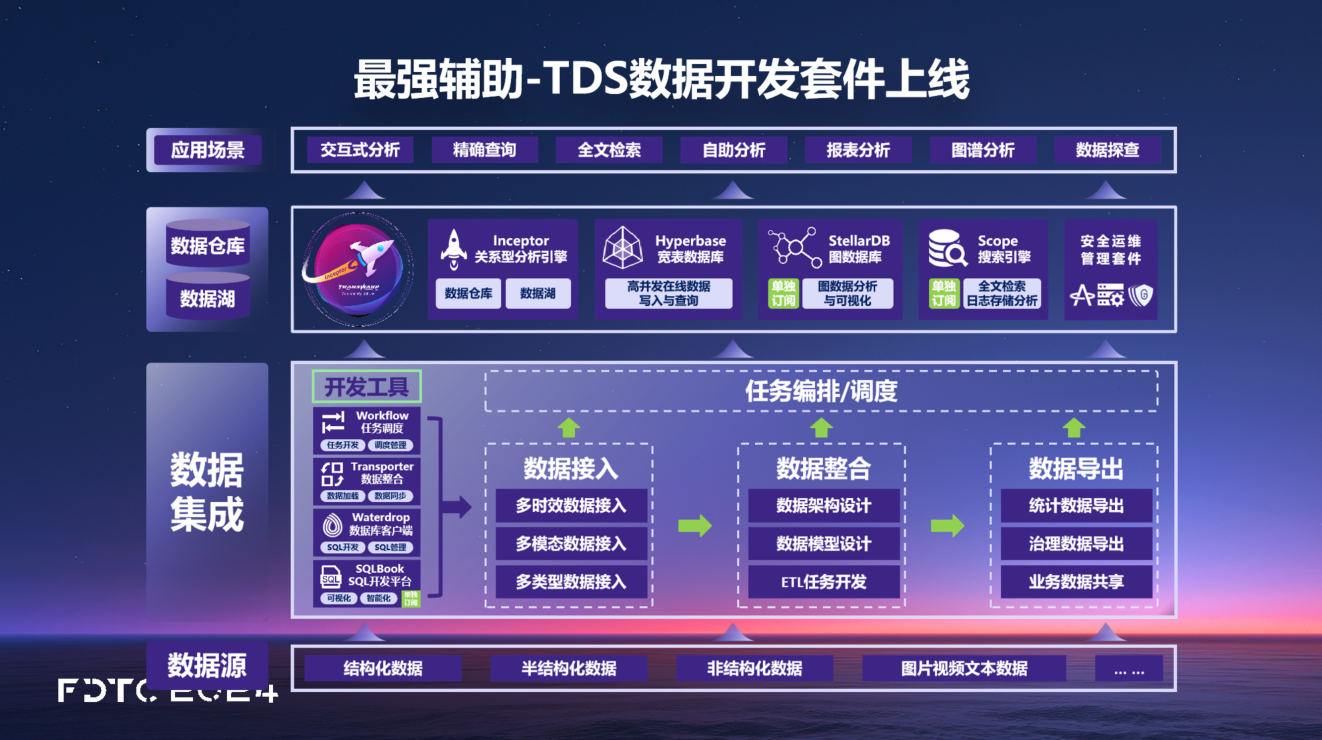
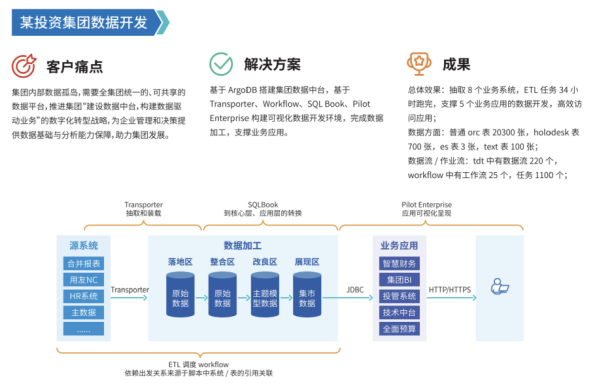
有关更多详细的产品能力介绍,感兴趣的读者可访问 TDS平台各功能能力一览 进一步查看。

















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









