







分桶背景
随着企业的数据不断增长,数据的分布和访问模式变得越来越复杂。我们前面介绍了如何通过对表进行分区来提高查询效率,但对于某些特定的查询模式,特别是需要频繁地进行数据联接查或取样的场景,仍然可能面临性能瓶颈。此外,随着数据的不断积累,可能会出现某些分区数据量过大,导致查询和处理效率受到影响。
为了更细粒度地管理和优化数据存储与访问,数据分桶(Bucketing)技术逐渐受到了关注,即对指定列的哈希值将其分配到固定数量的子集中(桶),保障数据的均匀分布,从而为复杂查询提供了更高效的处理方式。
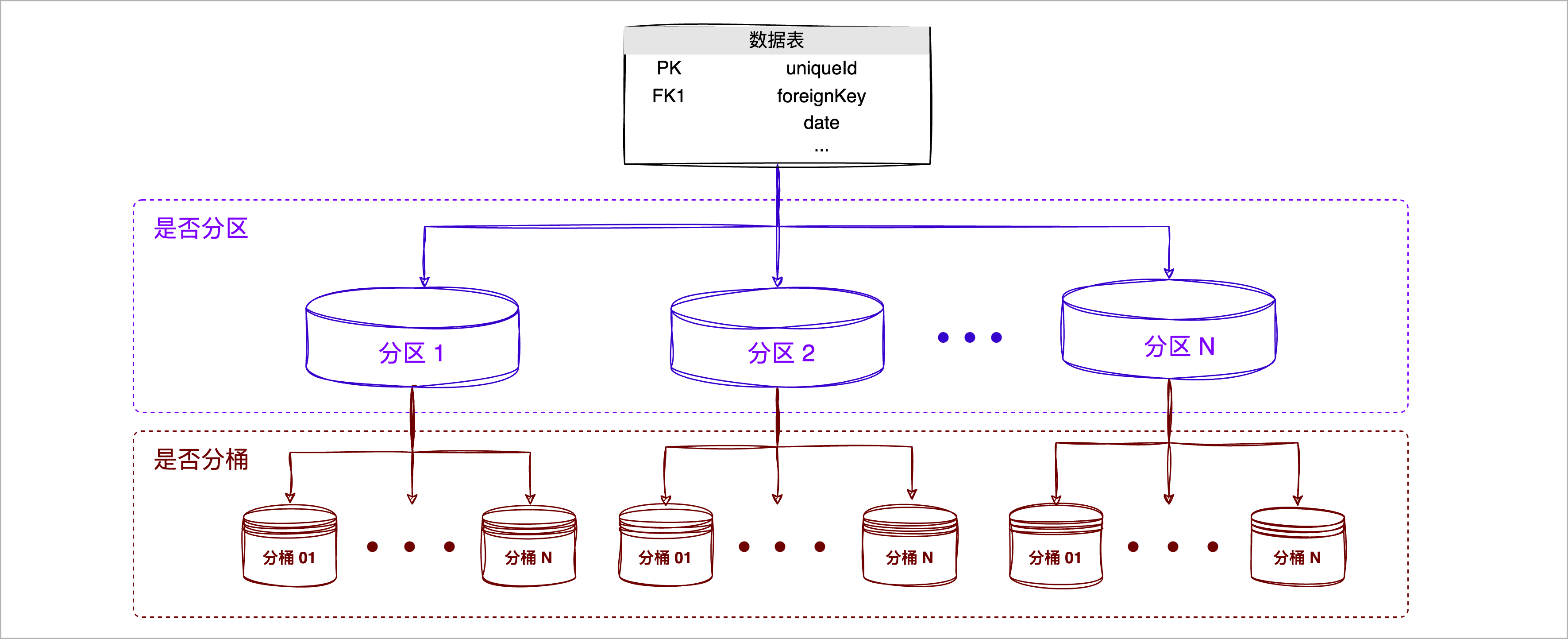
为什么要分桶
数据分桶通过对特定列的值进行哈希处理,帮助您更好地均匀分布数据、优化特定模式的查询,其优势如下:
- 优化特定查询模式: 对于涉及桶列的JOIN和过滤操作,分桶可以大大加速查询,因为它能确保只有相关的桶被访问和处理。例如,基于桶键的 JOIN 操作可以在 map 阶段执行,避免了 shuffle 和 reduce 阶段的开销。
- 此外,当查询的谓词包含分桶键时,可快速定位到具体的分桶,极大减少数据扫描范围,提升查询效率。
- 增加数据访问的预测性: 由于数据是基于哈希值进行分桶的,所以系统可以准确地知道哪些数据位于哪个桶中。这为数据访问提供了更高的预测性,从而进一步提高了查询性能。
何时分桶
数据分桶是一种大数据优化策略,主要目的是提高查询性能,在决定是否对表进行分桶时,需要综合考虑以下几个因素,以确保分桶对系统性能和数据管理带来实际的好处:
- 高频的连接操作: 当两个大表需要经常进行连接操作,并且连接基于某个特定的列,经常因为数据移动而产生大量的 Shuffle 读写,拖慢了查询效率。
- 频繁的聚合操作: 对于需要频繁执行的聚合操作,如果按照聚合的键进行数据分桶,可以大大提高查询性能,因为每个节点可以独立地完成其桶内的聚合操作。
设计表分桶策略
选择合适的分桶键是分桶优化成功的关键。以下是一些选择合适分桶键的指南和考虑因素:
| 步骤 | 说明 |
|---|---|
| 分析查询需求 | ● 常用的 JOIN 列:重点关注经常执行 JOIN 操作的列,基于桶键的 JOIN 可以在 Map 阶段执行,避免了 Shuffle 阶段的开销。 ● 常用的 WHERE 子句列:重点关注经被用作过滤条件的列,将其作为分桶键可避免全表或分区扫描,只需扫描特定桶,从而帮助提高查询效率,并确保数据在桶之间的均匀分布。 |
| 了解数据特征 | ● 分析数据在列上的分布情况,一个理想的分桶键应该有较大的基数和较少的重复值,避免桶中的数据不均衡。 |
| 选择分桶列数量 | ● 多分桶列:适用于处理高任务并行度的查询,假设数据的一个主要特征或多个特征经常被一起查询或用于 JOIN 操作,即使查询条件没有涵盖所有分桶列的等值条件,该查询也可通过扫描关联的分桶,提高任务执行的并行度。 ● 单分桶列:适用于高并发的点查询,使其只需扫描与该键匹配的特定桶,减少不同查询之间的 I/O 干扰,并提高系统的响应时间。 |
| 确认分桶数 | ● 默认情况下,分桶数由 ArgoDB 自动计算,可覆盖大部分业务场景,即 数据磁盘总数 * 5,然后取比起大的相邻质数,例如磁盘数为 12,先将其乘以 5,再取相邻质数,则默认分桶数为 61。 ● 如果表执行了分区操作,推荐单个分区中,分桶的数据规模为 50~100 MB,既可以避免文件过小触发小文件合并,给文件管理带来额外开销,同时也避免了 Block 文件数过多导致查询启动的 task 数过多影响执行和并发效率,需要注意应避免将分桶数设置为 31 及其倍数,减少潜在的哈希冲突。 |
在具体实践中,您也可以使用小规模数据量的表来尝试使用不同的分桶键,比较分桶获得到的查询收益,找出为您提供最佳性能的选择,此外,随着业务数据特性、查询需求的变化,可能还需要定期评估分桶键合理性。
最佳实践
创建分桶表
场景介绍
XYZ 是一家全球知名的电子产品零售商,主营智能手机、耳机、笔记本电脑等电子产品。近期,该企业注意到某些产品的退货率居高不下。高退货不仅影响了公司的利润,还可能导致顾客的不满和对品牌的不信任。为了深入研究这一问题,该企业希望通过分析历史业务数据,识别产品质量问题、优化库存管理,从而能够更加聚焦地改进其产品和服务,在竞争激烈的零售市场中保持领先地位。
接下来,我们以 TPC-DS 样例数据集为例,演示在搭建退货数据分析的数据仓库过程中,如何通过数据分桶来提升数据查询性能,我们用到的表分别为:
- store_sales*
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









