







过去两年,我的主要工作都在Hadoop这个技术栈中,而最近有幸接触到了Ceph。我觉得这是一件很幸运的事,让我有机会体验另一种大型分布式存储解决方案,可以对比出HDFS与Ceph这两种几乎完全不同的存储系统分别有哪些优缺点、适合哪些场景。
对于分布式存储,尤其是开源的分布式存储,站在一个SRE的角度,我认为主要为商业公司解决了如下几个问题:
可扩展,满足业务增长导致的海量数据存储需求;
比商用存储便宜,大幅降低成本;
稳定,可以驾驭,好运维。
总之目标就是:又好用,又便宜,还稳定。但现实似乎并没有这么美好……

本文将从这三个我认为的根本价值出发,分析我运维Ceph的体会,同时对比中心化的分布式存储系统,比如HDFS,横向说一说。
一、可扩展性
Ceph声称可以无限扩展,因为它基于CRUSH算法,没有中心节点。 而事实上,Ceph确实可以无限扩展,但Ceph的无限扩展的过程,并不完全美好。
首先梳理一下Ceph的写入流程。Ceph的新对象写入对象,需要经过PG这一层预先定义好的定额Hash分片,然后PG,再经过一次集群所有物理机器硬盘OSD构成的Hash,落到物理磁盘。
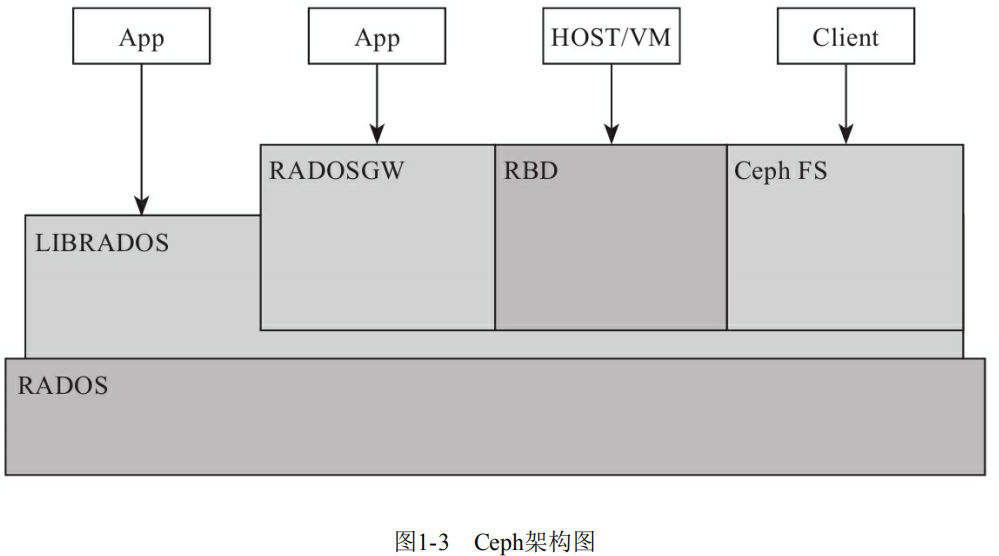
因此,Ceph的所有对象,是先被pre-hash到了一个固定数量的桶(PG)当中,然后根据集群的整体物理架构crushmap,选择落在具体的机器磁盘上。
这对扩容有什么影响呢?
1.扩容粒度
我给扩容粒度的定义是:一次可以扩容多少台机器。
Ceph在实践中,扩容受“容错域”制约,一次只能扩一个“容错域”。
容错域就是:副本隔离级别,即同一个replica的数据,放在不同的磁盘/机器/Rack/机房。
容错域这个概念,在很多存储方案里都有,包括HDFS。为什么Ceph会受影响呢?因为Ceph没有中心化的元数据结点,导致数据放置策略受之影响。
数据放置策略,即一份数据replica,放在哪台机器,哪块硬盘。
中心化的,比如HDFS,会记录每一个文件,下面每一个数据块的存放位置。这个位置是不会经常变动的,只有在1.文件新创建;2.balancer重
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









