






摘要
在本文中,我们提出了一个名为 **YOLA** 的新型框架,用于低光场景下的对象检测。与以往的工作不同,我们从特征学习的角度来应对这一具有挑战性的问题。具体而言,我们通过朗伯特图像生成模型学习光照不变特征。我们的观察表明,在朗伯特假设下,通过利用相邻颜色通道和空间相邻像素之间的相互关系,可以近似得到光照不变的特征图。通过引入额外的约束,这些关系可以通过卷积核的形式进行表征,并在网络中以检测驱动的方式进行训练。
为此,我们设计了一个专门用于从低光图像中提取光照不变特征的新模块,该模块可以轻松集成到现有的对象检测框架中。我们的实验证明,该方法在低光对象检测任务中表现出显著的性能提升,同时在良好光照和过度光照场景中也取得了令人鼓舞的效果。代码已开源,地址为 [https://github.com/MingboHong/YOLA](https://github.com/MingboHong/YOLA)。
1 introduction
在计算机视觉领域,对象检测作为一项基石技术,推动了从自动驾驶车辆到安全监控等众多应用的进步 [26, 51, 20]。准确识别和定位数字图像中的对象的能力在深度学习技术的推动下取得了显著进展 [16, 15, 40]。然而,尽管取得了这些进步,在低光条件下进行对象检测仍然是一项重大挑战。低光环境会导致图像质量差、可见性降低,并在夜间监控和黄昏驾驶中增加误检率 [48, 32]。
传统应对低光对象检测的方法主要依赖于图像增强技术 [17, 24, 53, 34]。尽管这些方法在提升视觉美感和感知质量方面表现出色,但通常难以直接转化为对象检测性能的提升。这种差异的原因在于,这些增强技术通常针对人类视觉感知进行了优化,而这种优化与机器学习模型高效、准确的对象检测需求并不总是相关。
除了图像增强策略外,另一种研究方向是针对低光条件对预训练模型进行微调。通常,检测器最初会在大量明亮图像数据集(如 Pascal VOC [11] 和 Microsoft COCO [28])上进行训练,随后在较小的低光数据集上进行微调 [48, 32]。为增强跨领域信息的利用,MAET 框架 [7] 被开发用于通过分离由图像质量退化引起的特征与对象特征,学习内在的视觉结构特征。同样的方法 [31, 25] 试图在检测器训练过程中恢复受损图像的正常外观。然而,这些技术往往过度依赖于合成数据集,从而可能限制其实际应用价值。
最近一些针对低光对象检测的方法(如 [36, 49])使用拉普拉斯金字塔 [2] 进行多尺度边缘提取和图像增强。FeatEnHancer [18] 进一步利用分层特征以改善低光视觉。然而,这些特定任务驱动的损失优化方法往往因光照效应的多样性而面临更大的解空间问题。
本研究提出了一种新颖的方法,显式利用基于朗伯特图像生成模型 [42] 的光照不变特征。在朗伯特假设下,我们可以将每个通道中的像素值表示为三个关键组成部分的离散组合:表面法线、光照方向(两者均与像素位置相关)、光谱功率分布,以及像素本身的内在属性。通过消除与位置相关和光谱功率相关的项,可以学习光照不变特征 [14]。我们将这种光照不变特征的提取引入低光检测任务,并证明结合该特征能够显著提高低光检测任务的性能。我们进一步通过任务驱动的核对该光照不变特征进行改进。我们的关键发现是,通过对这些核施加零均值约束,特征既可以发现更多下游任务特定模式,又可以保持光照不变性,从而提升性能。
为此,我们提出了**光照不变模块(IIM)**,这是一种多功能且自适应的组件,旨在将这些特定卷积核提取的信息与标准RGB图像的信息融合。IIM可以无缝集成到各种现有的对象检测框架中,无论是通过简单的边缘特征还是多样化的光照不变特征,都能增强其在低光环境下的检测精度(如图1所示)。

我们进一步在 **ExDark** 和 **UG2+DARK FACE** 数据集上对该方法进行了实验评估。实验结果表明,IIM的集成显著提高了现有方法的检测精度,在低光对象检测中表现出显著的改进。
总结来说,我们的贡献如下:
- 我们提出了 **YOLA**,一个利用光照不变特征进行低光条件下对象检测的新型框架。
- 我们设计了一个新颖的 **光照不变模块(IIM)**,能够提取光照不变特征,无需额外的配对数据集,并且可以无缝集成到现有的对象检测方法中。
- 我们对提取的光照不变特征范式进行了深入分析,并提出了一个学习光照不变特征的范式。
- 实验表明,**YOLA** 在处理低光图像时能够显著提升现有方法的检测精度。
2 相关工作
2.1 目标检测
当前的现代对象检测方法可以分为基于锚点(anchor-based)和无锚点(anchor-free)两大类。基于锚点的检测器源于滑动窗口(sliding-window)范式,其中密集锚点可以视为在空间中排列的滑动窗口。随后,根据匹配策略(如交并比 (IoU) [16]、Top-K [52, 50])将锚点分配为正样本或负样本。常见的基于锚点的方法包括 R-CNN [16, 15, 40]、SSD [30]、YOLOv2 [38] 和 RetinaNet [27] 等。
相比之下,无锚点的检测器摆脱了手动设置锚点超参数的限制,从而增强了其在泛化能力方面的潜力。无锚点的代表性方法包括 YOLOv1 [37]、FCOS [44] 和 DETR [3]。
尽管基于锚点和无锚点的检测器在通用对象检测任务中取得了显著成就,但它们在低光条件下的表现仍不尽如人意。
2.2 暗光检测
在低光条件下进行对象检测仍然是一项重大挑战。一种常见的研究路径是利用图像增强技术,如 KIND [53]、SMG [46]、NeRCo [47] 以及其他方法 [17, 24, 22, 23],直接提升低光图像的质量。增强后的图像随后被用于检测的训练和测试阶段。然而,图像增强的目标与对象检测的目标本质上是不同的,这使得这种策略难以达到最优效果。
为了解决这一问题,一些研究者 [21, 6] 探索了在训练过程中将图像增强与对象检测相结合的方法。然而,要平衡视觉质量与检测性能之间的超参数设置是一项复杂的任务。最近,Sun 等人 [43] 提出了一个针对性对抗攻击范式,旨在将退化图像恢复为更有利于对象检测的图像。MAET [7] 则通过在低光合成数据集上训练,使预训练模型具备了内在结构分解能力,从而用于下游的低光对象检测。此外,IA-YOLO [31] 和 GDIP [25] 通过精心设计的可微分图像处理模块,自适应增强恶劣天气条件下的对象检测图像。
需要注意的是,上述方法通常需要专门的低光增强数据集或在训练中严重依赖合成数据集。为减轻这些限制,一些方法 [36, 49, 18] 采用多尺度分层特征,并完全依靠任务特定的损失驱动来改善低光视觉表现。
与这些方法不同,我们引入了光照不变特征,以减轻光照对低光对象检测的影响,而无需额外的低光增强数据集或合成数据集。这种方法从根本上改善了低光条件下的对象检测能力。
2.3 光照不变表示
不利的光照条件通常会降低下游任务的性能,因此研究人员探索了光照不变技术来减轻这一影响。在高层次任务中,Wang 等人 [45] 提出了一种用于人脸识别的光照归一化方法;Alshammari 等人 [1] 利用光照不变的图像表示来改善汽车场景理解和分割;Lu 等人 [33] 将 RGB 图像转换为光照不变的色度空间,以便为后续特征提取做好准备,从而在各种光照条件下实现交通对象检测。
在低层次任务中,一些基于物理的光照不变表示,例如颜色比率 [13] (CR) 和交叉颜色比率 [14] (CCR),被用于通过光照分解进行内在图像分解 [10, 9, 8]。然而,这些方法依赖于固定公式派生的光照不变表示,可能无法充分捕捉特定于下游应用的多样化和复杂光照场景。
相比之下,我们的方法能够以端到端的方式自适应地学习光照不变特征,从而增强与下游任务的兼容性。这种方法不仅能够更好地应对复杂光照场景,还显著提升了在各种环境下的任务性能。
3 方法
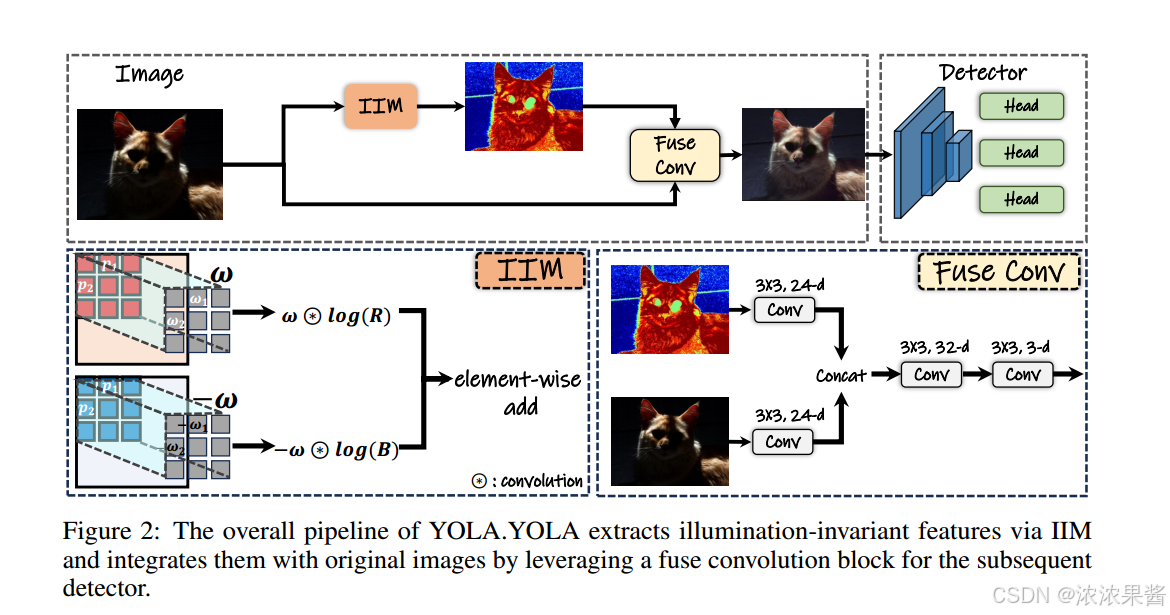
在本节中,我们正式介绍了一种用于低光对象检测的新方法——**YOLA**。如图2所示,YOLA 的核心组件是 **光照不变模块(IIM)**,该模块专注于特征学习,以提取面向下游任务的光照不变特征。这些特征可以与现有的检测模块相结合,从而增强其在低光条件下的检测能力。
接下来,我们将介绍光照不变特征的推导过程,并详细描述 IIM 的具体实现方式。
3.1 光照不变特征
符号说明
Lambertian假设

交叉颜色比率(Cross Color Ratio)

取对数并代入公式(1)后得到:
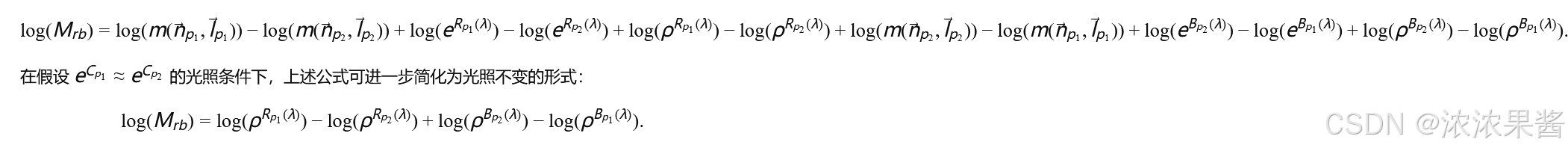
观察公式(4)可以发现:

3.2光照不变模块
尽管公式 (4) 提供了一种简单而有效的计算光照不变特征的方法,但其固定性也带来了一定的局限性。具体来说,该公式的固定形式可能无法充分捕捉不同场景中下游任务特定的多样化和复杂光照变化。为了解决这一问题,我们将公式发展为一种更加适应性的形式,采用卷积操作代替固定公式。我们的方法不再依赖单一的卷积核,而是学习一组卷积核。这种策略不仅增强了光照不变特征提取的鲁棒性,还提高了其效率。
为此,我们提出了一个 光照不变模块(Illumination Invariant Module,IIM),包括两个主要组件:可学习卷积核和零均值约束。需要注意的是,该模块在初始化时提取的特征本质上具有光照不变性。后续的卷积核学习则旨在生成针对下游任务的特定光照不变特征,以满足任务需求。
可学习卷积核(Learnable Kernel)


零均值约束(Zero Mean Constraint)

4 实验
4.1 实现细节

4.2 数据集

4.3 低光目标检测
表 1 展示了在 ExDark 数据集上,YOLOv3 和 TOOD 检测器的定量结果。我们报告了低光图像增强 (LLIE) 方法(如 KIND、SMG、NeRCo)以及先进的低光对象检测方法(如 DENet 和 MAET)的结果。
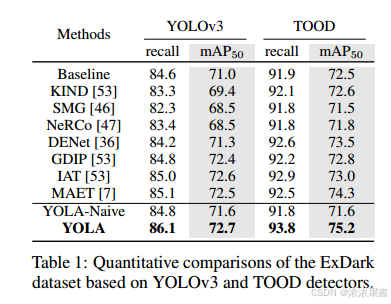
与低光对象检测方法相比,LLIE 方法在对象检测任务中表现不佳,这主要归因于人类视觉感知与机器感知之间的不一致。尽管某些 LLIE 方法在视觉美感方面表现出色,但未必与优化的对象检测性能对齐。相比之下,基于端到端学习的 DENet 和 MAET 在检测性能方面表现出色。
值得注意的是,与 YOLA-Naive 相比,YOLA 展现出更优的性能,因为其提取的特征本质上具有光照不变性,并且相比 YOLA-Naive 使用了更小的解空间。具体来说,我们的方法在 YOLOv3 和 TOOD 上分别超越基线 1.7 和 2.5 个 mAP,展现了其优越性和高效性。
4.4 暗光人脸检测

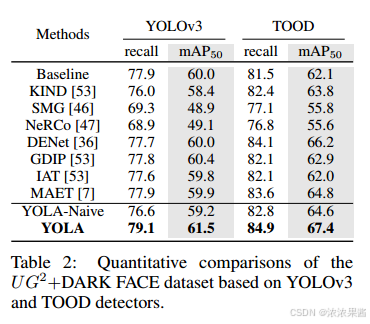
4.5 定量结果


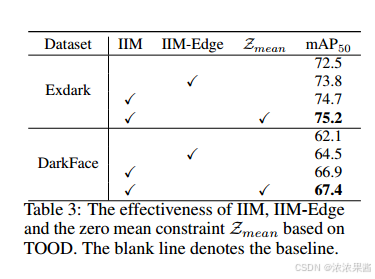
4.6 消融实验



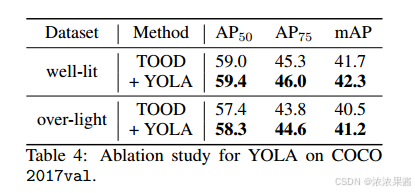
4.7 泛化能力

5 结论
在本研究中,我们重新审视了低光照条件下目标检测的复杂挑战,并展示了光照不变特征在提升此类环境中检测准确性方面的有效性。我们的关键创新——光照不变模块(Illumination-Invariant Module, IIM)充分利用了这些特征。通过在框架中引入零均值约束,我们成功地学习了一组多样化的核函数,这些核函数擅长提取光照不变特征,从而显著提高了检测精度。我们相信,所开发的 IIM 模块将对未来低光照目标检测任务的推进具有重要意义。
致谢:本研究部分得到了中国国家自然科学基金(NSFC)项目(项目编号:62372091)以及四川省自然科学基金(项目编号:2023NSFSC0462 和 2023NSFSC1972)的资助。

















 4496
4496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









