







一、单节点部署前置准备
- 这里一直下一步就好了
接下来需要为该节点固定ip并配置相关网关还有dns解析
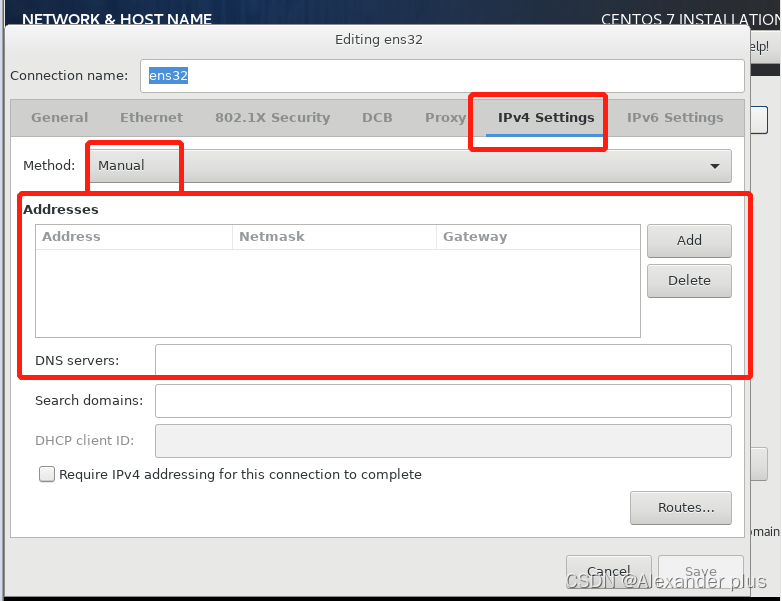
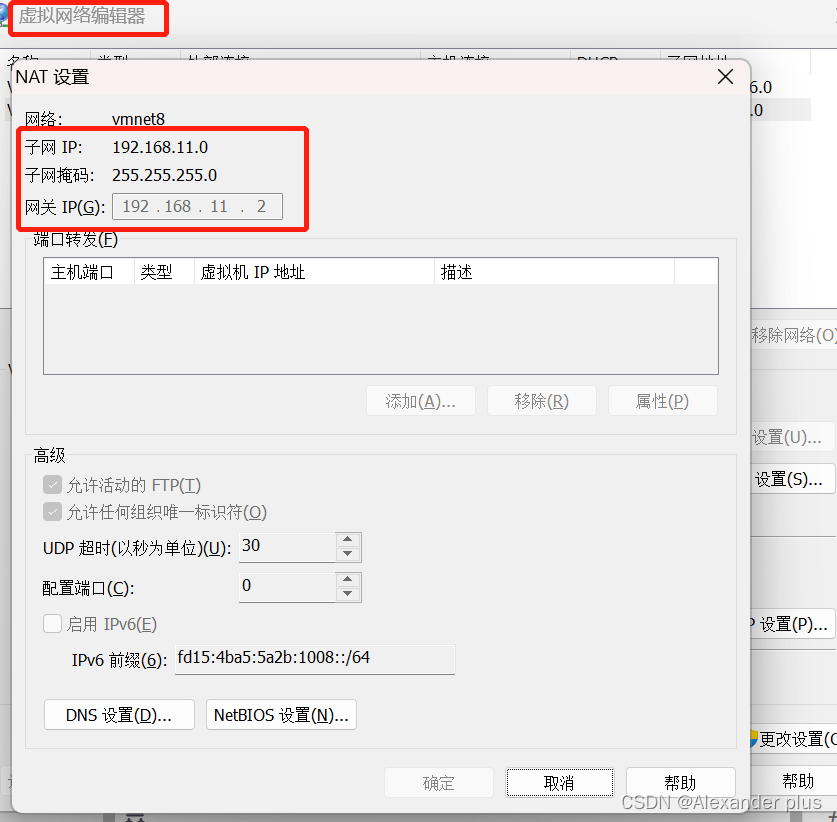

- 这里配置了一个本机dns解析,也配置了一个公网dns解析(主要目的还是为了固定ip)
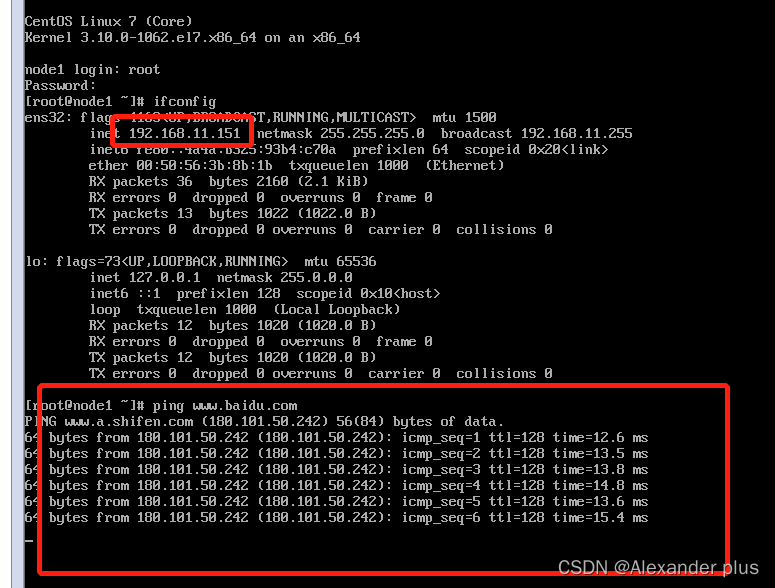
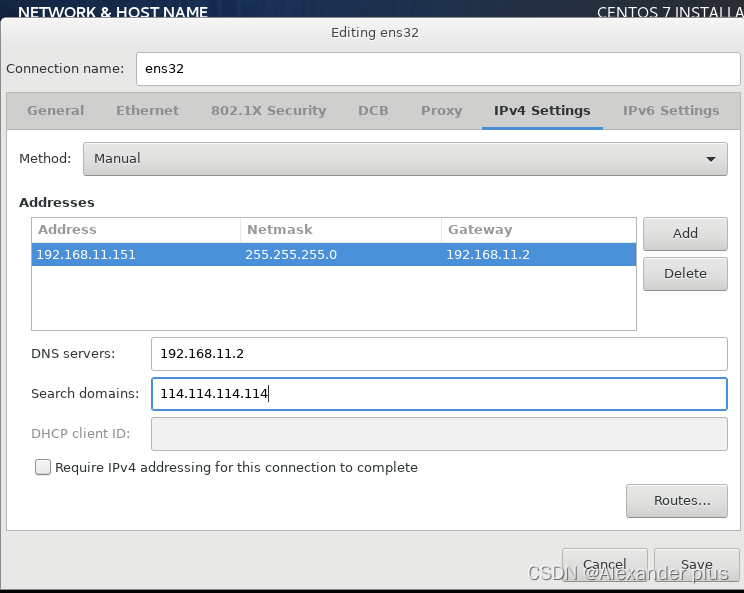
- 跟我们刚刚固定的ip一致且跟baidu官网能够进行通信
映射ip名称,方便后续操作
- 冷知识:G o写入;shift zz 退回
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.227.151 node1.itcast.cn node1
192.168.227.152 node2.itcast.cn node2
192.168.227.153 node3.itcast.cn node3
修改虚拟机网络设置
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet" #网卡类型 以太网
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33" #网卡名称
UUID="74c3b442-480d-4885-9ffd-e9f0087c9cf7"
DEVICE="ens33"
ONBOOT="yes" #是否开机启动网卡服务
IPADDR="192.168.227.152" #IP 地址
PREFIX="24" #子网掩码 等效: NETMASK=255.255.255.0
GATEWAY="192.168.227.2" #网关服务
DNS1="192.168.227.2" #网关 DNS 解析
DOMAIN="114.114.114.114" #公网 DNS 解析 114.114.114.114 谷歌:8.8.8.8 阿里百度 DNS
IPV6_PRIVACY="no"
systemctl restart network # 重启网络服务
#查看防火墙状态
systemctl status firewalld
#关闭防火墙
systemctl stop firewalld
#关闭防火墙开机自启动
systemctl disable firewalld
#centos 服务开启关闭命令
centos6:(某些可以在 centos7 下使用)
service 服务名 start|stop|status|restart
chkconfig on|off 服务名
centos7:
systemctl start|stop|status|restart 服务名
systemctl disable|enable 服务名 #开机自启动 关闭自启
# 关闭seliux
vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# 重启生效
reboot
# 安装mysql跟jdk
mkdir -p /export/server
mkdir -p /export/software
mkdir -p /export/data
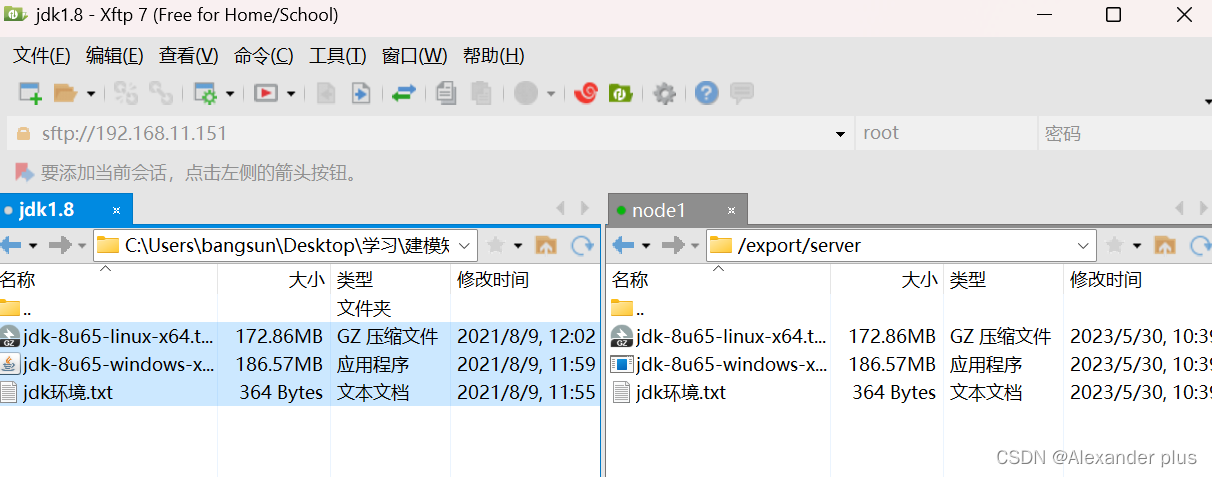
安装mysql跟jdk
#解压到当前目录
tar zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vim /etc/profile #G + o
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#重新加载环境变量文件 让配置生效
source /etc/profile
[root@node1 ~]# java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
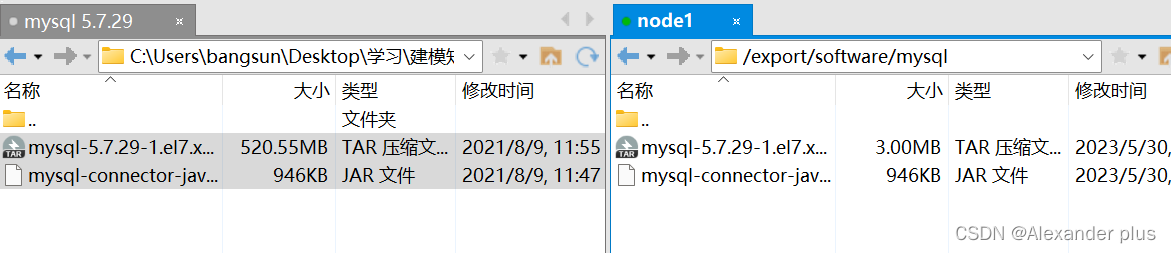
mkdir /export/software/mysql
#上传 mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压
tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
#执行安装
yum -y install libaio
rpm -qa|grep mariadb
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
mkdir /export/software/mysql
tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
yum -y install libaio
rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.29-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.29-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.29-1.el7.x86_64.rpm
mysqld --initialize
# 查看临时密码
chown mysql:mysql /var/lib/mysql -R
systemctl start mysqld.service
cat /var/log/mysqld.log
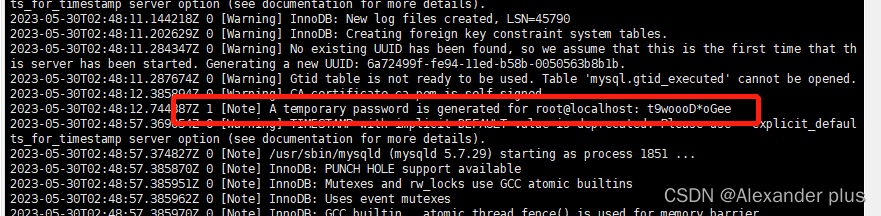
alter user user() identified by "hadoop";
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
FLUSH PRIVILEGES;
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
systemctl enable mysqld
时钟同步
ntpdate ntp4.aliyun.com
克隆其他节点
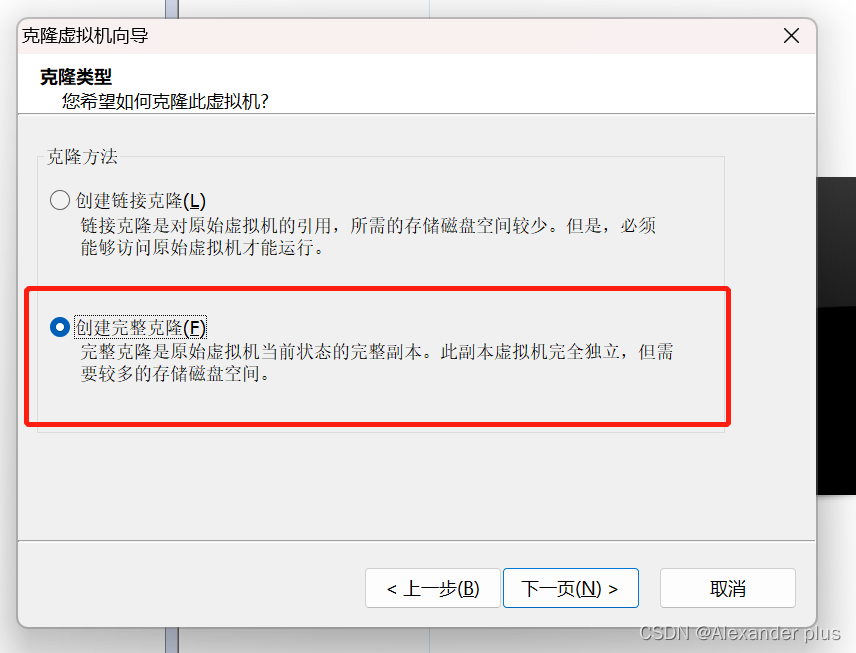
完成节点间相互免密切换
#实现 node1----->node2
#step1
在 node1 生成公钥私钥
ssh-keygen 一顿回车 在当前用户的 home 下生成公钥私钥 隐藏文件
[root@node1 .ssh]# pwd
/root/.ssh
[root@node1 .ssh]# ll
total 12
-rw------- 1 root root 1675 May 20 11:59 id_rsa
-rw-r--r-- 1 root root 402 May 20 11:59 id_rsa.pub
-rw-r--r-- 1 root root 183 May 20 11:50 known_hosts
#step2
copy 公钥给 node2
ssh-copy-id node2
注意第一次需要密码
#step3
[root@node1 .ssh]# ssh node2
Last login: Thu May 20 12:03:30 2021 from node1.itcast.cn
[root@node2 ~]# exit
logout
Connection to node2 closed.
正式安装Hadoop
- 编译hadoop
```shell
#上传解压源码包
tar zxvf hadoop-3.3.0-src.tar.gz
#编译
cd /root/hadoop-3.3.0-src
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
#参数说明:
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
-
编译之后的安装包路径
/root/hadoop-3.3.0-src/hadoop-dist/target -
Hadoop 完全分布式安装
-
集群规划
主机 角色 node1 NN DN RM NM node2 SNN DN NM node3 DN NM -
基础环境
# 主机名 hosts映射 vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.227.151 node1.itcast.cn node1 192.168.227.152 node2.itcast.cn node2 192.168.227.153 node3.itcast.cn node3 # JDK 1.8安装 上传 jdk-8u65-linux-x64.tar.gz到/export/server/目录下 cd /export/server/ tar zxvf jdk-8u65-linux-x64.tar.gz #配置环境变量 vim /etc/profile export JAVA_HOME=/export/server/jdk1.8.0_65 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #重新加载环境变量文件 source /etc/profile # 集群时间同步 ntpdate ntp5.aliyun.com # 防火墙关闭 firewall-cmd --state #查看防火墙状态 systemctl stop firewalld.service #停止firewalld服务 systemctl disable firewalld.service #开机禁用firewalld服务 # ssh免密登录 #node1生成公钥私钥 (一路回车) ssh-keygen #node1配置免密登录到node1 node2 node3 ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3 -
上传Hadoop安装包到node1 /export/server
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -
修改配置文件(配置文件路径 hadoop-3.3.0/etc/hadoop)
-
hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_65 #文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> -
hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property> -
mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> -
yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 保存的时间7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> -
workers
node1 node2 node3
-
-
分发同步hadoop安装包
cd /export/server scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD -
将hadoop添加到环境变量(3台机器)
vim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin scp /etc/profile root@node2:/etc/ scp /etc/profile root@node3:/etc/ source /etc/profile # 切换到其他节点并source
-
-
Hadoop集群启动
-
(首次启动)格式化namenode
hdfs namenode -format -
脚本一键启动
[root@node1 ~]# start-dfs.sh Starting namenodes on [node1] Last login: Thu Nov 5 10:44:10 CST 2020 on pts/0 Starting datanodes Last login: Thu Nov 5 10:45:02 CST 2020 on pts/0 Starting secondary namenodes [node2] Last login: Thu Nov 5 10:45:04 CST 2020 on pts/0 [root@node1 ~]# start-yarn.sh Starting resourcemanager Last login: Thu Nov 5 10:45:08 CST 2020 on pts/0 Starting nodemanagers Last login: Thu Nov 5 10:45:44 CST 2020 on pts/0 -
Web UI页面
- HDFS集群:http://node1:9870/
- YARN集群:http://node1:8088/
-
错误1:运行hadoop3官方自带mr示例出错。
-
错误信息
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> -
解决 mapred-site.xml,增加以下配置
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
-
-
-
finished
-
$HADOOP_HOME/bin/hdfs --daemon start namenode -
不知道为啥node1节点没法自启动,需要手动启动,不然namenode就没反应
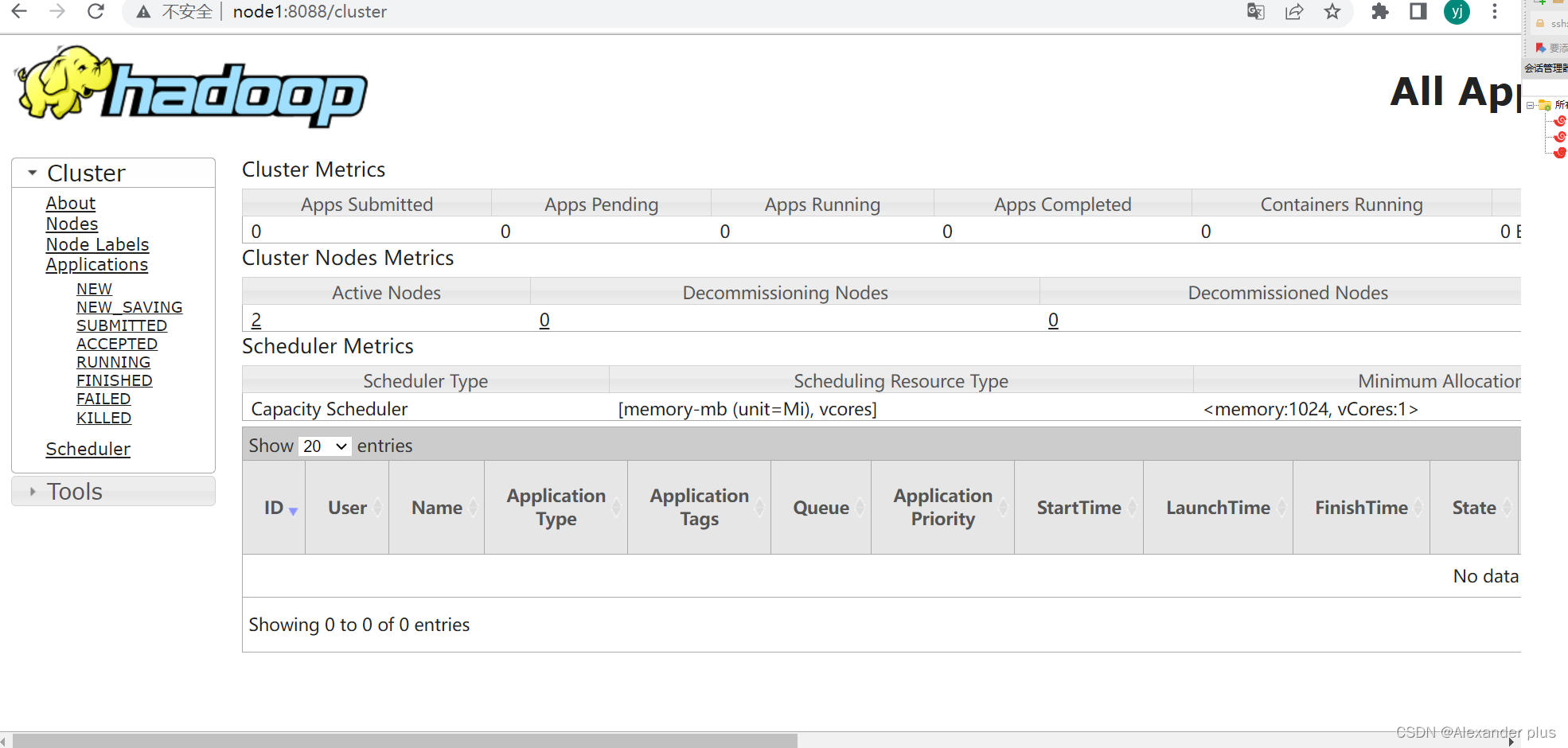
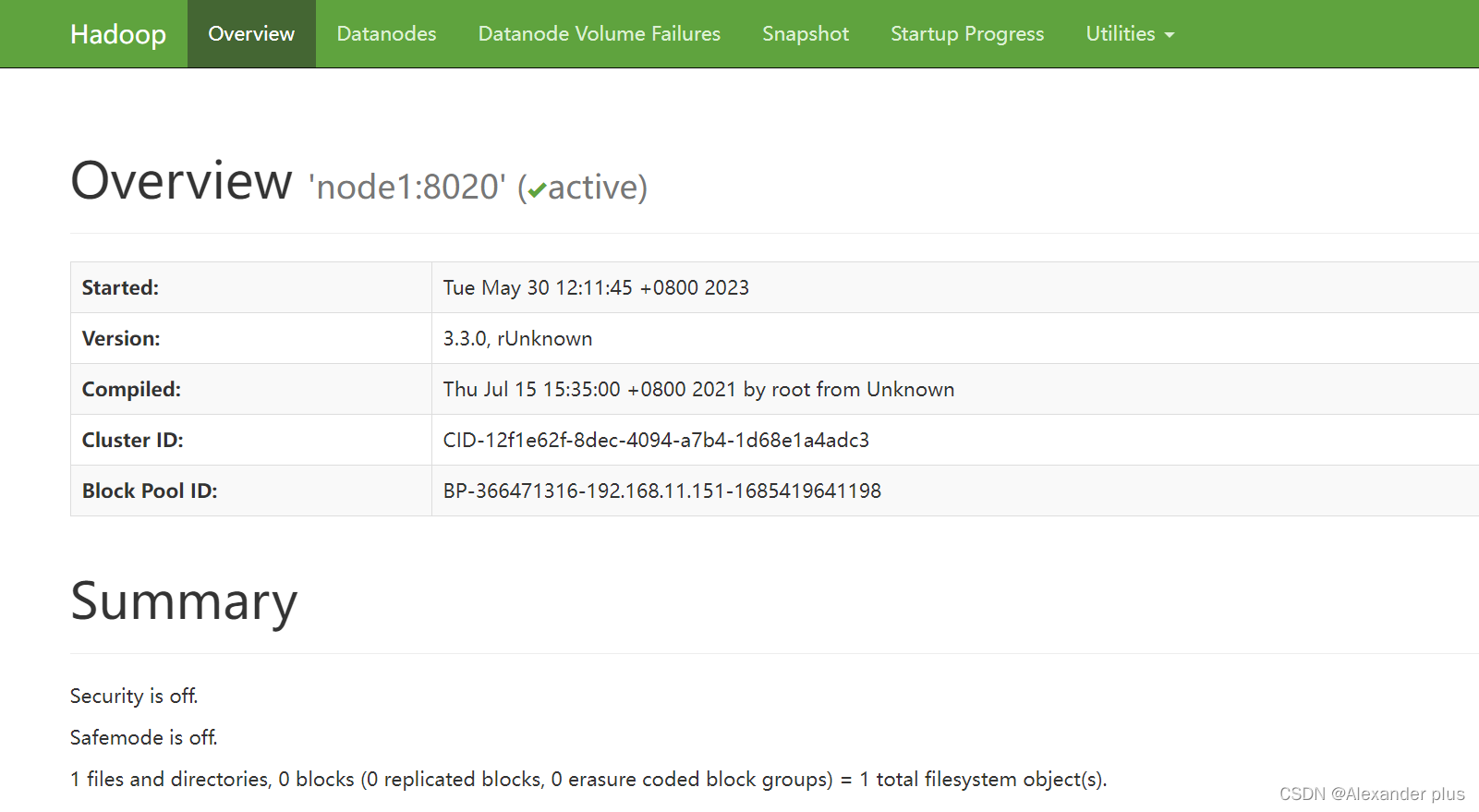
启用job_history任务:
mapred --daemon start historyserver















 1632
1632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











