








当微服务发生故障后怎么办?最近线上发生一起故障,一个接口的慢查询拖垮了整个应用,导致整个应用变得不可用。如果正好赶上流量高峰,应用重启都变得很困难,除非把入口整个关闭,再重启应用等待应用的恢复。
在复盘时,结论是增加上线审核流程和控制来试图阻止故障的再次发生,很少花费心思想想如何更加容易地在第一时间从故障中恢复过来。
在这次故障中我也做了一些思考,如果当时是我处理这起故障,我能做什么?本文因此而起,一部分来自于之前公司所做的稳定性建设方面的经验,一部分来源于《微服务设计》中所写的经验。分成技术实现前的思考和技术方面可以做的事情。
一 技术实现前的思考
思考一、假定故障会发生,如何去优雅地处理它。
假设一切都会失败,会让你从不同的角度去思考如何解决问题。我们可以在试图阻止不可避免的故障上少花一点时间,而花更多时间去优雅地处理它。假定故障会发生,如果以这种想法来处理你做的每一件事情,为其故障做好准备,那么就会做出不同的权衡。
了解你可以容忍多少故障,或者系统需要多快,了解系统的用户的负载能力。
思考二、系统的强弱依赖梳理
梳理系统下游接口强弱程度,哪些接口是强依赖,哪一些是弱依赖。强依赖一般指此服务有问题,流程会卡住,直接影响功能,否则为弱依赖。要有强弱依赖梳理工具,能够查询接口的调用链,根据业务场景去判断哪些接口是强依赖、哪些是弱依赖
强弱依赖接口治理:先去除没有必要、不合理的依赖;不影响核心业务的依赖全部变为弱依赖 ;弱依赖:增设降级开关,紧急情况直接降级处理;配置限流 ;强依赖:能加缓存的加缓存;加预案开关 ,可快速止血。
思考三、哪些功能业务上可以降级
构建一个弹性系统,尤其是当功能分散在多个不同的、有可能宕掉的微服务上时,重要的是能够安全地降级功能。我们需要做的是理解每个故障的影响,并弄清楚如何恰当地降级功能。如果购物车服务不可用,我们可能会有很多麻烦,但仍然可以显示列表清单页面。也许可以仅仅隐藏掉购物车,将其替换成一个新的图标“马上回来!”。如果下单依赖的红包服务不可用,降级后用户还可以正常的下单。对于每个使用多个微服务的面向用户的界面,或每个依赖多个下游合作者的微服务来说,你都需要问自己:“如果这个微服务宕掉会发生什么?”然后你就知道该做什么了。通过思考每项跨功能需求的重要性,我们对自己能做什么有了更好的定位。现在,让我们考虑从技术方面可以做的事情,以确保当故障发生时可以优雅地处理。
二 技术方面可以做的事情
在分布式架构下,准备好如何应对各种故障的发生是非常重要的。那么我们需要做什么来应对系统故障呢?
1.超时设置
超时是很容易被忽视的事情,但在使用下游系统时,正确地处理它是很重要的。在考虑下游系统确实已经宕掉之前,我需要等待多长时间?如果等待太长时间来决定调用失败,整个系统会被拖慢。如果超时太短,你会将一个可能还在正常工作的调用错认为是失败的。如果完全没有超,一个宕掉的下游系统可能会让整个系统挂起。给所有的跨进程调用设置超时,并选择一个默认的超时时间。当超时发生后,记录到日志里看看发生了什么,并相应地调整它们。
2.断路器
即使我们正确地设置超时,也需要等待很长时间才能得到错误。接着我们等下次请求进来时将再次尝试,同样等待。如果下游服务发生故障会拖慢我们的整个系统。
使用断路器时,当对下游资源的请求发生一定数量的失败后,断路器会打开。接下来,所有的请求在断路器打开的状态下,会快速地失败。一段时间后,客户端发送一些请求查看下游服务是否已经恢复,如果它得到了正常的响应,将重置断路器。
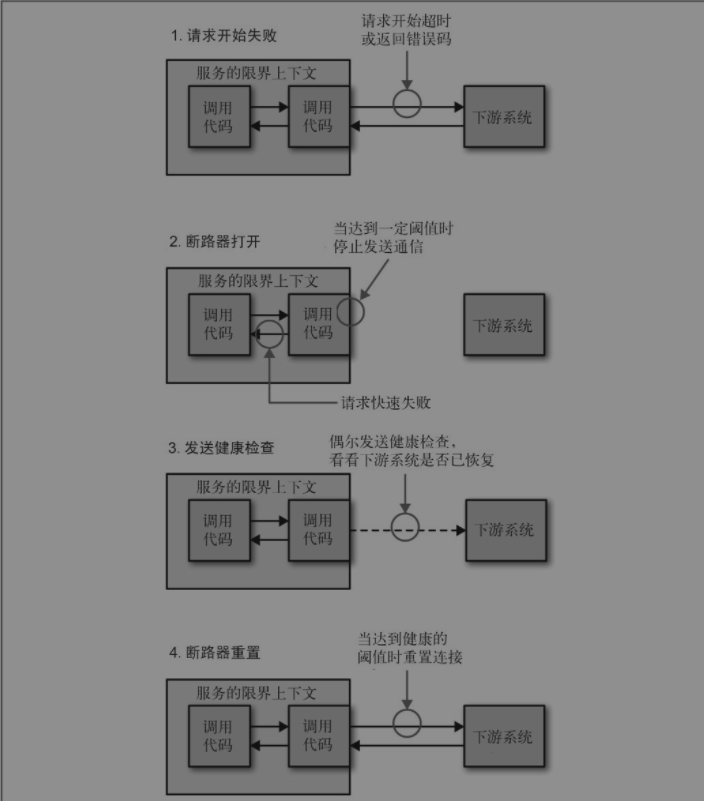
断路器概述(图片来自于《微服务设计》)
如何实现断路器依赖于请求失败的定义,但当使用HTTP连接实现它们时,我会把超时或5XX的HTTP返回码作为失败的请求。通过这种方式,当一个下游资源宕掉,或超时,或返回错误码时,达到一定阈值后,我们会自动停止向它发送通信,并启动快速失败。当它恢复健康后,我们会自动重新发送请求。
正确地设置断路器会有点棘手。你不想太轻易地启动断路器,也不想花太多时间来启动。同样,你要确保在下游服务真正恢复健康后才发送通信。跟超时一样,我会选取一些合理的默认值并在各处使用,然后在特定的情况下调整它们。
当断路器断开后,你有一些选项。其中之一是堆积请求,然后稍后重试它们。对于一些场景,这可能是合适的,特别是你所做的工作是异步作业的一部分时。然而,如果这个调用作为同步调用链的一部分,快速失败可能更合适。这意味着,沿调用链向上传播错误,或者降级功能。
如果我们有这种机制(如家里的断路器),就可以手动使用它们,以使所做的工作更加安全。例如,如果作为日常维护的一部分,我们想要停用一个微服务,可以手动启动依赖它的所有系统的断路器,使它们在这个微服务失效的情况下快速失败。一旦微服务恢复,我们可以重置断路器,让一切都恢复正常。这里的机制在电商中会经常被使用,即使用开关来降级所依赖的功能。例如大促期间关闭一些功能来应对流量的洪峰。
3.舱壁模式
舱壁(bulkhead),是把自己从故障中隔离开的一种方式。在航运领域,舱壁是船的一部分,合上舱口后可以保护船的其他部分。所以如果船板穿透之后,你可以关闭舱壁门。如果失去了船的一部分,但其余的部分仍完好无损。
在软件架构术语中,有很多不同的舱壁可供我们考虑。
(1)为每个下游服务的连接使用不同的连接池
我们应该为每个下游服务的连接使用不同的连接池。这样的话,如果一个连接池被用尽,其余连接并不受影响。这可以确保,如果下游服务将来运行缓慢,只有那一个连接池会受影响,其他调用仍可以正常进行。
(2) 应用的拆分
关注点分离也是实现舱壁的一种方式。通过把功能分离成独立的微服务应用,减少了因为一个功能的宕机而影响另一个的可能性。这里拆分我们可以按功能拆分,也可以按应用的是否核心来拆分核心应用和非核心应用。
(3) 使用断路器
我们可以把断路器看作一种密封一个舱壁的自动机制,它不仅保护消费者免受下游服务问题的影响,同时也使下游服务避免更多的调用,以防止可能产生的不利影响。鉴于级联故障的危险,我建议对所有同步的下游调用都使用断路器。当然,不需要重新创造你自己的断路器。Netflix的Hystrix库(https://github.com/Netflix/Hystrix)是一个基于JVM的断路器,附带强大的监控。
在很多方面,舱壁是三个模式里最重要的。超时和断路器能够帮助你在资源受限时释放它们,但舱壁可以在第一时间确保它们不成为限制。例如,Hystrix允许你在一定条件下,实现拒绝请求的舱壁,以避免资源达到饱和,这被称为减载(load shedding)。有时拒绝请求是避免重要系统变得不堪重负或成为多个上游服务瓶颈的最佳方法。
4.隔离
一个服务越依赖于另一个,另一个服务的健康将越能影响其正常工作的能力。如果我们使用的集成技术允许下游服务器离线,上游服务便不太可能受到计划内或计划外宕机的影响。
服务间加强隔离还有另一个好处。当服务间彼此隔离时,服务的拥有者之间需要更少的协调。团队间的协调越少,这些团队就更自治,这样他们可以更自由地管理和演化服务。
这些都是发生故障前技术上需要准备好的事情。如果发生故障前什么也没有做,似乎只有重启应用,祈祷下游接口赶紧恢复这条路了,如果赶上流量高峰,恐怕连入口也需要关闭,应用才能起得来。所以架构性安全措施需要提前去做,它们可以确保如果事情真的出错了,不会引起严重的级联影响。在系统中把它们标准化,以确保不会因为一个服务的问题导致整个系统的崩塌。
















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









