







数据仓库(Data Warehouse)
一、概念
数据仓库是这么定义的:数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。
这个定义中有一个定义比较容易含混,那就是“面向主题”。面向主题是指数据仓库围绕一些主题,排除对于决策无用的数据,提供特定主体的简明视图。近年提出的“面向专题”的分析和这个概念混淆的厉害,只能用用户熟悉的业务才能作出解释。
-
面向主题
-
面向主题跟面向应用相对应。面向应用是指实现某种功能,数据集合也是其单一功能的数据集。而面向主题是指为了实现某个主题而产生的一个或多个的面向应用的数据集合的整合。
-
举个例子,支付是一个面向应用的主体,而交易是一个面向主题的主体。因为交易是从下单,到支付等的一系列的过程的串联,支付只是其中的一环。
-
- 集成
- 数据仓库的一个重要的功能是把不同的数据源的数据汇总到一起。
- 集成是指把不同类型的数据源的数据进行整合,按照统一的形式进行集成。比如性别在一个数据源用男/女 另一个用1/2,那么在数据仓库中我们需要对其进行统一。
- 相对稳定
- 数据一般有一定的生命周期,历史的数据一般不会再改变,我们可以采用增量的策略进行数据的传输和计算。比如看订单的支付成功的相关信息,那么一旦订单支付成功之后,这个订单的支付成功相关的信息就不会在变更,所以此类的数据可以按天增量计算。
- 反映历史变化
- 由于在数据仓库中可以存储历史的信息,那么就可以根据这些历史信息进行数据的分析来反映历史的变化。而操作型数据库一般只会某些时间段的数据。
二、数据仓库发展历程
数据仓库的发展大致经历了这样的三个过程:
· 简单报表阶段: 这个阶段,系统的主要目标是解决一些日常的工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据。这个阶段的大部分表现形式为数据库和前端报表工具。
· 数据集市阶段: 这个阶段,主要是根据某个业务部门的需要,进行一定的数据的采集,整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供特定的领导决策数据。
· 数据仓库阶段: 这个阶段,主要是按照一定的数据模型,对整个企业的数据进行采集,整理,并且能够按照各个业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对对业务具有指导性的数据,同时,为领导决策提供全面的数据支持。
通过数据仓库建设的发展阶段,我们能够看出,数据仓库的建设和数据集市的建设的重要区别就在于数据模型的支持。因此,数据模型的建设,对于我们数据仓库的建设,有着决定性的意义。
三、数据库与数据仓库的区别
从数据仓库的概念中也可以看出来数据仓库做的事情确实跟数据库不一样。归纳起来如下
- 数据粒度不同。数据库存储的是操作型数据,是细节性的数据,事当前的数据,反应的是最后修改的结果。数据仓库是分析型的集成或者汇总的数据,面向主题,并且保存数据的所有历史状态。
- 数据生命周期不同。数据库存的数据的生命周期比较短,不会保存很久的数据。数据仓库则需要历史数据来反映趋势的变化和数据分析。
- 建模方法不同。数据库采用范式建模,不能有冗余。数据仓库的建模方法有DW范式建模(跟数据库的范式建模也不同)和DM维度建模等,可以存在冗余。
- 时间敏感度不同。数据库的数据要求及时性非常高。数据仓库可以容忍数据的一定的延迟。
- 目标不同。数据库主要面向业务处理的,而数据仓库则面向分析用户。
网上引用比较多的对比表格

四、 数据仓库的用途
- 整合公司所有业务数据,建立统一的数据中心
- 产生业务报表,用于作出决策
- 为网站运营提供运营上的数据支持
- 可以作为各个业务的数据源,形成业务数据互相反馈的良性循环
- 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果
- 开发数据产品,直接或间接地为公司盈利
五、数据仓库的存储与实现
1、数据存储的方式?
数据仓库的数据由两种存储方式:一种是存储在关系数据库中,另一种是按多维的方式存储,也就是多维数组。
2、存储何种数据?
数据仓库中存在不同的综合级别的数据。一般把数据分成四个级别,早期细节级数据,当前细节级数据,轻度综合级,高度综合级。不同的综合级别一般称为粒度。粒度越大,表示细节程度越低,综合程度越高。级别的划分是根据粒度进行的。
数据仓库中还有一种是元数据,也就是关于数据的数据。传统数据库中的数据字典或者系统目录都是元数据,在数据仓库中 元数据表现为两种形式:一种是为了从操作型环境向数据仓库环境转换而建立的元数据,它包含了数据源的各种属性以及转换时的各种属性;另一种元数据是用来与多维模型和前端工具建立映射用的。
3、粒度与分割
粒度是对数据仓库中的数据的综合程度高低的一个衡量。粒度越小,细节程度越高,综合程度越低,回答查询的种类越多;反之粒度越大,细节程度越低,综合程度越高,回答查询的种类越少。
分割是将数据分散到各自的物理单元中去以便能分别独立处理,以提高数据处理的效率。数据分割后的数据单元成为分片。数据分割的标准可以根据实际情况来确定,通常可选择按日期、地域或者业务领域等进行分割,也可以按照多个标准组合分割。
4、追加时数据的组织方式
这里说一种比较简单的情况,轮转综合文件。比如:数据存储单位被分为日、周、季度、年等几个级别。每天将数据记录在日记录集中;然后七天的数据被综合存放在周记录集中,每隔一季度周记录集中的数据被存放到季度记录集中,依此类推……这种方法把越早期的记录存放的综合程度越高,也就是粒度越大。
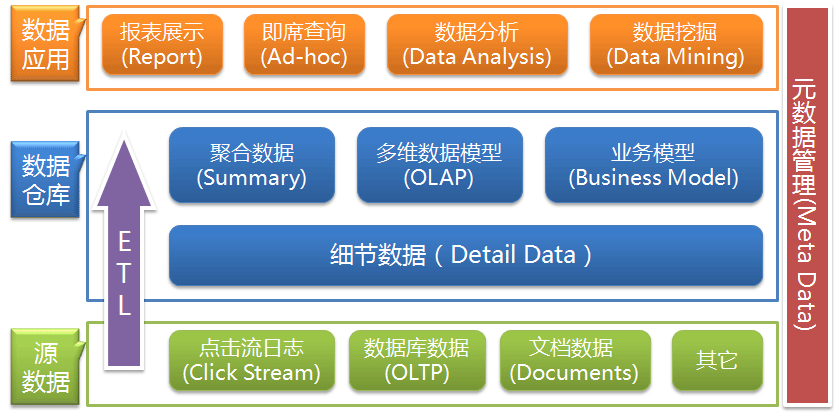
数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。其实数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。因此数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据应用:















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









