







 本文介绍了一种用于FPGA的CNN模型编译技术,该技术能够将CNN模型转换为可扩展的RTL代码,加速卷积神经网络的运行。论文详细阐述了包括卷积、池化、归一化等模块的编译策略,并展示了在Altera FPGA上实现AlexNet和NIN模型的效果。
本文介绍了一种用于FPGA的CNN模型编译技术,该技术能够将CNN模型转换为可扩展的RTL代码,加速卷积神经网络的运行。论文详细阐述了包括卷积、池化、归一化等模块的编译策略,并展示了在Altera FPGA上实现AlexNet和NIN模型的效果。
文章目录
- 题目:Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
- 时间:2016
- 会议:(International Conference on Field Programmable Logic and Applications (FPL)
- 研究机构:亚利桑那州立大学Yufei Ma
1 缩写 & 引用
- LRN: local response normalization
- cccp: convolution layer with K=1
2 abstract & introduction
本篇论文的贡献:
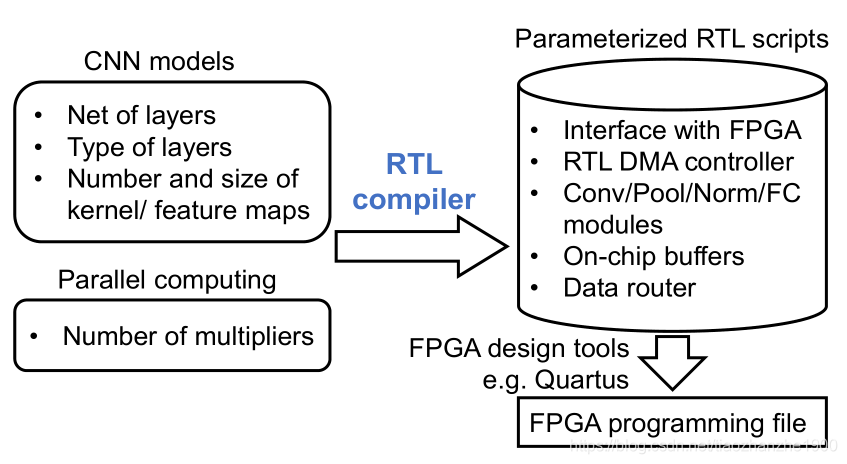
- CNN RTL编译器,输入CNN模型,输出模块化的,可扩展的RTL代码
- acceleration system generated by编译器
overview of CNN operations and structures - convolution
- pooling
- normalization
- fully-connected
3 compilation and parallel computation of scalable CNN modules
3.1 strategy to accelerate convolution

一共就这四个循环,作者先是展开loop3,再展开loop4
3.2 scalable convolution module(CONV)
控制逻辑有很多counter可以控制卷积的滑动,每个counter分别取决于kernel size, feature size和迭代次数
这些counter的组合产生地址可以读input
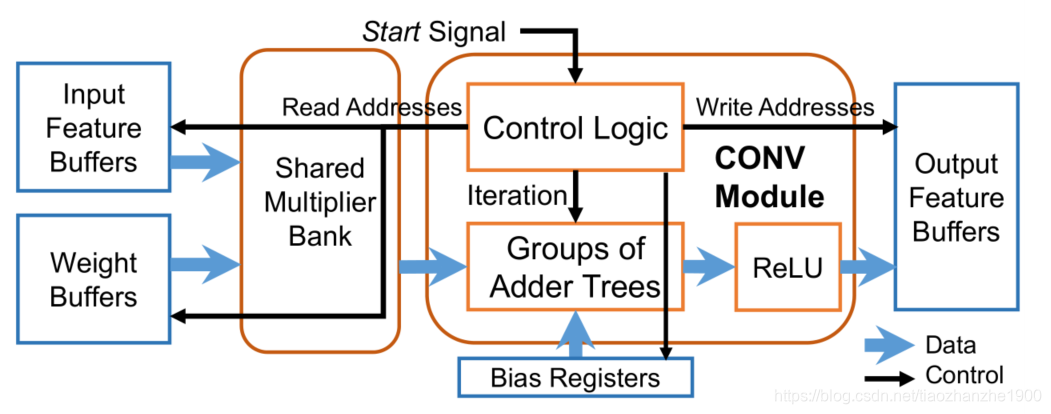
为了提高硬件利用率,最好是不同的CONV模块可以分给不同的层,这样可以实现整除
3.3 pooling module(POOL)
控制逻辑一样,也是扫描input feature来产生read/write地址,计算模块即编程取平均值或者取max
3.4 normalization module
需要从临近的channel中取数计算,非线性的操作通过查找表来计算
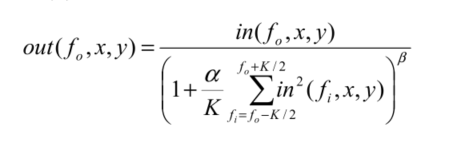
3.5 inner-product module
其实就是一个行向量乘矩阵,得到一个行向量,这里不用加法树,行向量来一个数就跟矩阵的一行相乘,后面的数在上面不断累加
3.6 DMA Configuratin module
用了Altera的Modular Scatter Gather DMA(mSGDMA)的IP
4 FPGA实现
总体框架图如下:
NIOS-II可以将weight和input image从flash搬到DDR3上,mSGDMA的IP负责将数据从DDR3搬运到片上的memory
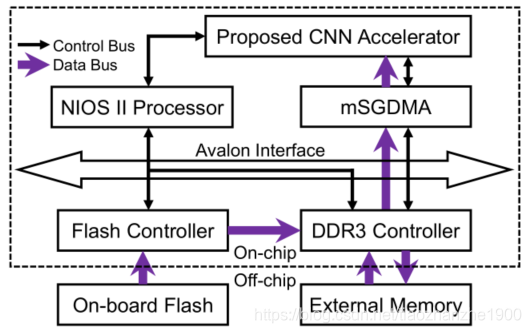
网络是一层一层计算的
feature data routers是由很多组的multiplexer组成的,可以
- convey feature data and address signals from different modules into feature buffers
- fetch the stored data to the multiplier bank or directly into the corresponding modules
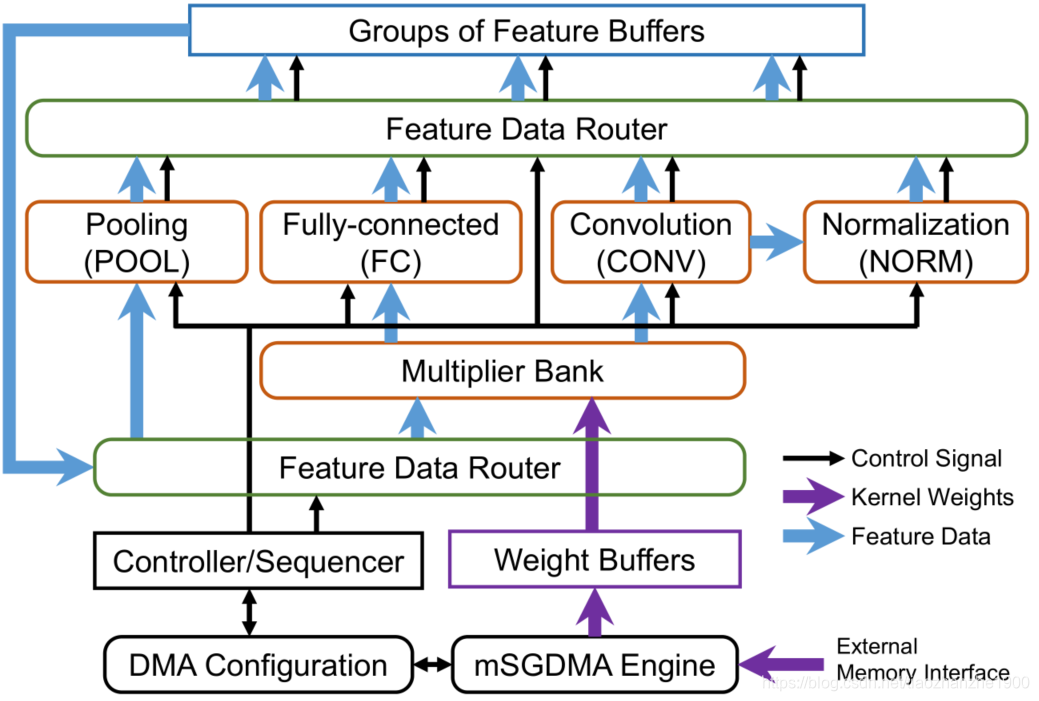
最后在Altera的板子上实现AlexNet和NIN的CNN模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









