







文章目录
- 题目:Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
- 时间:2016
- 会议:ISCA
- 研究机构:MIT/NVIDIA
1 缩写
- RS: row-stationary
- NoC: network on chip
- RF: register file
- ISP: image signal processing
- SA: Spatial architecture
2 abstract & introduction
本篇论文的主要贡献
- 对现有CNN dataflow的分类
- 基于row stationary的spatial architecture
- 对不同CNN dataflow的量化的分析框架
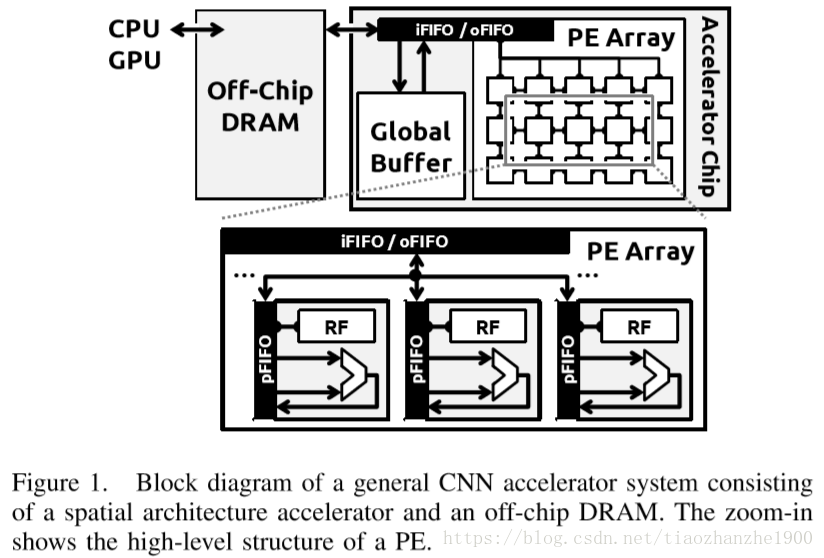
3 spatial architecture
Spatial architecture的定义: class of accelerators that can exploit high compute parallelism using direct communication between an array of relatively simple PE.
Spatial architecture的分类:
- 粗l粒度Spatial architecture
- 细粒度Spatial architecture
粗粒度Spatial architecture的优点:
- CNN层的操作都很uniform,可以大量并行
- inter-PE communication可以高效的利用
2 CNN background
2.1 CNN的挑战
CNN的挑战:
- 大量数据处理:计算资源、带宽、存储会有限制
- adaptive processing:同一网络不同层之间相差大
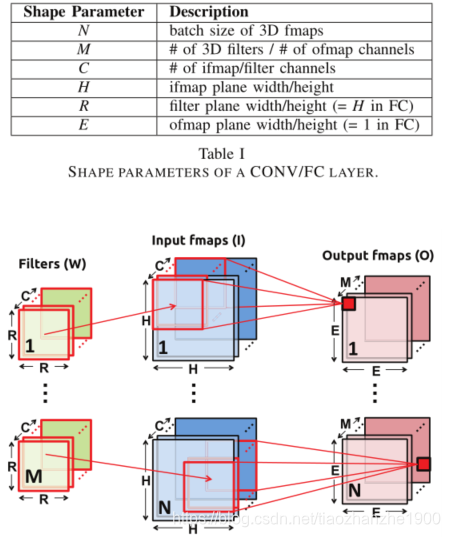
输入数据的复用:
- convolutional reuse:权重可以复用 E 2 E^2 E2次,输入特征图的一个像素可以复用 R 2 R^2 R2次
- filter reuse:一个batch有N个输入特征图,故权重可以复用N次
- ifmap reuse:一共M个kernel,故一个输入特征图可以复用M次
如何缩小存储空间: operation scheduling: C R 2 CR^2 CR2个部分和reduce成一个结果
2.2 CNN与传统图像处理的区别
- CNN的滤波器权重是训练得到的
- ISP主要用二维卷积
3 现有的CNN dataflows
3.1 weight stationary(WS) dataflow
Each filter weight remains stationary in the RF to maximize convolutional reuse and filter reuse.
3.2 output stationary(OS) dataflow
The accumulation of each ofmap pixel stays stationary in a PE. The psums are stored in the same RF for accumulation to minimize the psum accumulation cost.
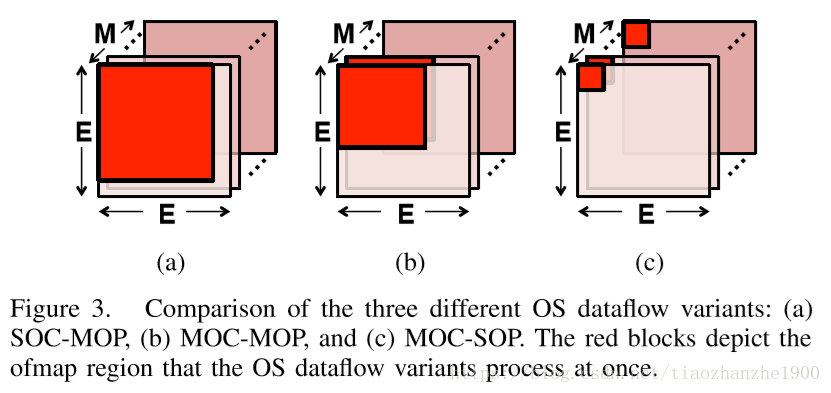
3.3 no local reuse(NLR) dataflow
通过inter-PE communication对输入特征图和部分和进行复用,有点像脉动阵列
4 Row stationary dataflow
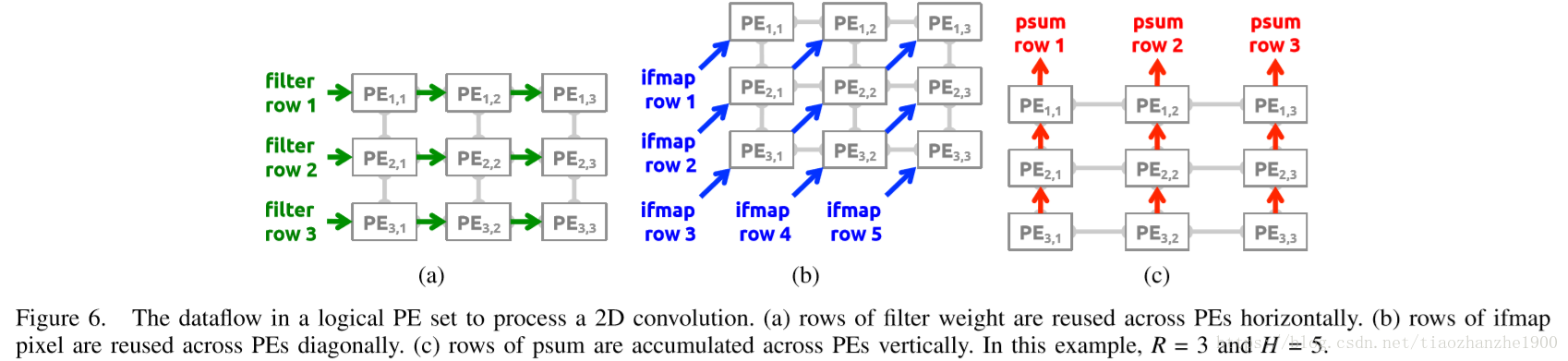
4.1 一维卷积primitives
每个primitive operates是对一行权重和一行输入特征图像素进行计算,产生一行的部分和,每个primitive是在一个PE上计算。
对于一个PE来说,这一行权重会被复用好几次,这里就是convolution reuse
4.2 two-step primitive mapping
先是logical mapping,理论上需要很多一维卷积的操作,数量会远大于硬件已有的PE阵列,然后是physical mapping,进行相应的折叠
假设输入特征图batch size是N,input channel为C,output channel是M,那么
- 同一个权重可以复用N次
- 同一个输入特征图像素可以复用M次
- C个通道的部分和输出可以累加到一起
4.3 energy-efficient data handling
数据流动会造成功耗,存储可以分成好几级
- register file:after the first phase folding, the RF is used to exploit all types of data movements
primitive内部计算的过程可以filter reuse,input data sharing between folded primitives可以实现ifmap reuse,primitive和primitive之间可以psum accumulation - array/inter-PE communication:having multiple sets mapped spatially across the physical PE array,估计是physical mapping折叠的时候
- global buffer: after the second phase folding
4.4 不同layer type的支持
- FC layer:跟卷积很像,就是kernel和输入特征图尺寸一样而已
- pool layer:把PE的MAC计算改成MAX比较就可以???
4.5 片上网络
NoC data type:
- 对ifmaps和权重的NoC多路广播
- 本地PE-to-PE NoC对部分和
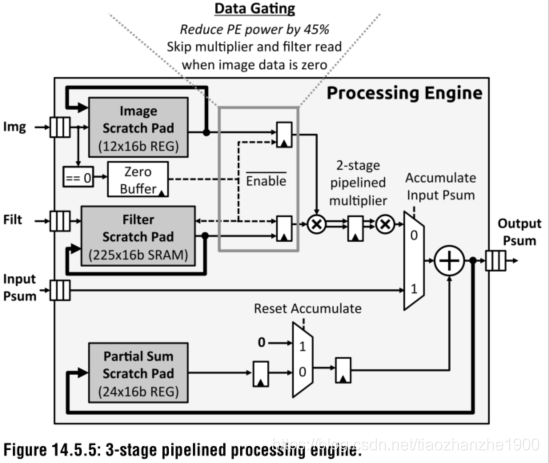
利用稀疏性:
- 只对非零值read和MAC
- 压缩数据
- 题目:Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks
- 时间:2016
- 会议:ISSCC
- 研究机构:MIT/NVIDIA
本篇论文的accelerator能耗很低,最后实现Alexnet,主要技术有
- spatial array,NoC,数据复用
- 数据压缩:游程编码
- zeros skipping/gating
权重从左往右移动;feature map从左下开始,斜着右向上移动;部分和从下往上移动
因为PE Array大小是固定的,而网络的shape是一直变化的,所以mapping需要相应的folding或者replication
因为不同层shape不一样,mapping策略也不一样,所以每个PE连哪个PE是未知的,这就需要NoC了
每个PE会分配一个id,如果想要实现多播,只需要多个PE的id一样

















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









