









1.简介
2. 概念
3. 安装
3.1 安装准备
3.1.1 安装curl
sudo apt-get install libcurl3-gnutls=7.47.0-1ubuntu2
sudo apt install curl
sudo apt-get install x11-xserver-utils
sudo apt-get remove docker docker-engine docker.io containerd runc
xhost +
3.2 安装 docker
3.2.1 安装
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
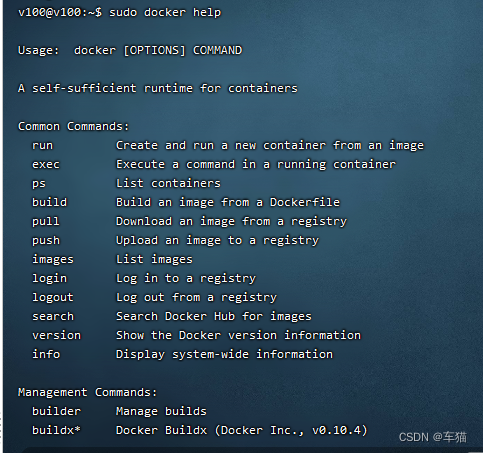
查看是否安装成功
sudo docker help
使用docker help命令可查看docker的所有命令,说明已安装成功。
3.2.3 安装docker2
# 1.
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
# 2.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
# 3.
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 4
sudo apt-get update
# 5
sudo apt-get install -y nvidia-docker2
修改文件:
sudo vim /etc/docker/daemon.json
红框是添加的参数
{
"registry-mirrors": ["https://xxxxxxx.mirror.aliyuncs.com"],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
3.2.2 镜像加速
3.2.2.1 阿里云加速
由于阿里云是单人单账号,因此可能加速效果更好。
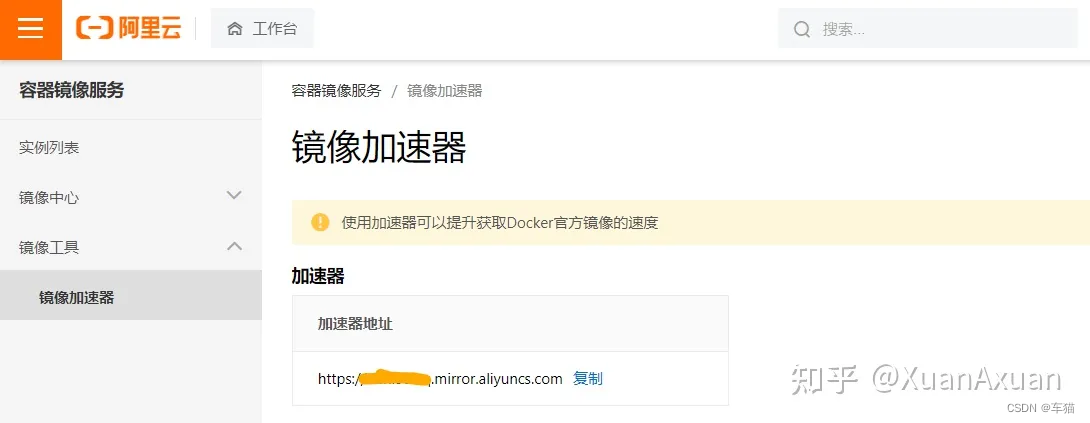
国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。例如:科大镜像,阿里云等等。以阿里云为例,阿里云镜像获取地址:,登陆后,左侧菜单选中镜像加速器就可以看到你的专属地址了:
然后在 /etc/docker/daemon.json 中写入如下内容(如果文件不存在请新建该文件):
{
"registry-mirrors": [
"https://XXX.mirror.aliyuncs.com/",
"https://dockerproxy.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://ccr.ccs.tencentyun.com"
]
}

之后重新启动服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
3.2.2.2 其他加速账号
1.、网易云镜像站:
http://hub-mirror.c.163.com
3、百度云镜像站:
https://mirror.baidubce.com
4、上海交大镜像站:
https://docker.mirrors.sjtug.sjtu.edu.cn
5、南京大学镜像站:
https://docker.nju.edu.cn
- 腾讯
https://ccr.ccs.tencentyun.com
以下连接不公开或已失效:
1、Docker 中国官方镜像:(已关闭)
https://registry.docker-cn.com
2、中国科技大学 USTC:(仅供内部访问)
https://docker.mirrors.ustc.edu.cn
3. docker中国区官方镜像加速:
https://registry.docker-cn.com
3.2.3 本地登录
Docker 官方维护了一个公共仓库 Docker Hub,里边包含了大多数我们需要的基础镜像。
首先注册一个账号,然后在本地登录:
注意使用的用户名,密码。非邮箱
sudo docker login
3.2.4 加入用户权限
- 创建名为docker的组,如果之前已经有该组就会报错,可以忽略这个错误:
sudo groupadd docker
- 将当前用户加入组docker:
sudo gpasswd -a ${USER} docker
- 重启docker服务(生产环境请慎用):
sudo systemctl restart docker
- 添加访问和执行权限:
sudo chmod a+rw /var/run/docker.sock
- 操作完毕,验证一下,现在可以不用带sudo了:
docker info
4. 操作
4.1 拉取镜像
4.1.1 使用pytorch官网镜像
- 查找镜像,参考网址
docker pull pytorch/pytorch:1.10.0-cuda11.3-cudnn8-devel
优势:
- 已经建立好conda环境
劣势
- 未找到cudnn文件
- 使用tensorrt 不可用
4.1.2 使用nvidia镜像
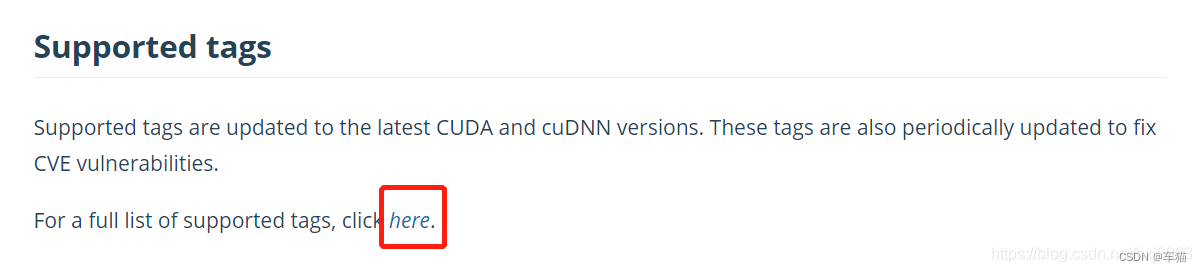
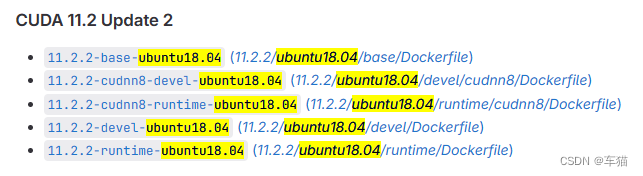
- 浏览 nvidia 官方的 dockerhub 镜像库: nvidia/cuda ,选择你使用的环境。如果没有的话,就点击这里,获取最全列表:
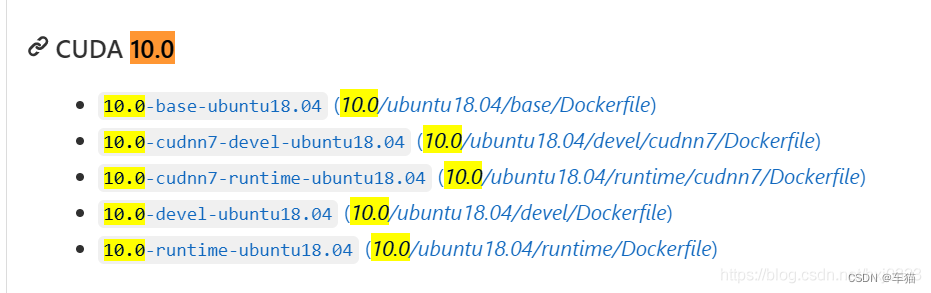
- 选择版本,例如:
11.2.2-cudnn8-devel-ubuntu18.04,使用命令拉取
docker pull nvidia/cuda:11.2.2-cudnn8-devel-ubuntu18.04
查看 cuda 和 cudnn 版本
cat /usr/local/cuda/version.txt
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
- 安装anaconda
需要先更新一下包
apt update
apt-get update
安装一下wget,用于下载anaconda包
apt-get install -y wget
下载anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
下载完毕后,安装,给一下执行权限
chmod +x Anaconda3-2023.09-0-Linux-x86_64.sh
#安装命令:
sh Anaconda3-2023.09-0-Linux-x86_64.sh
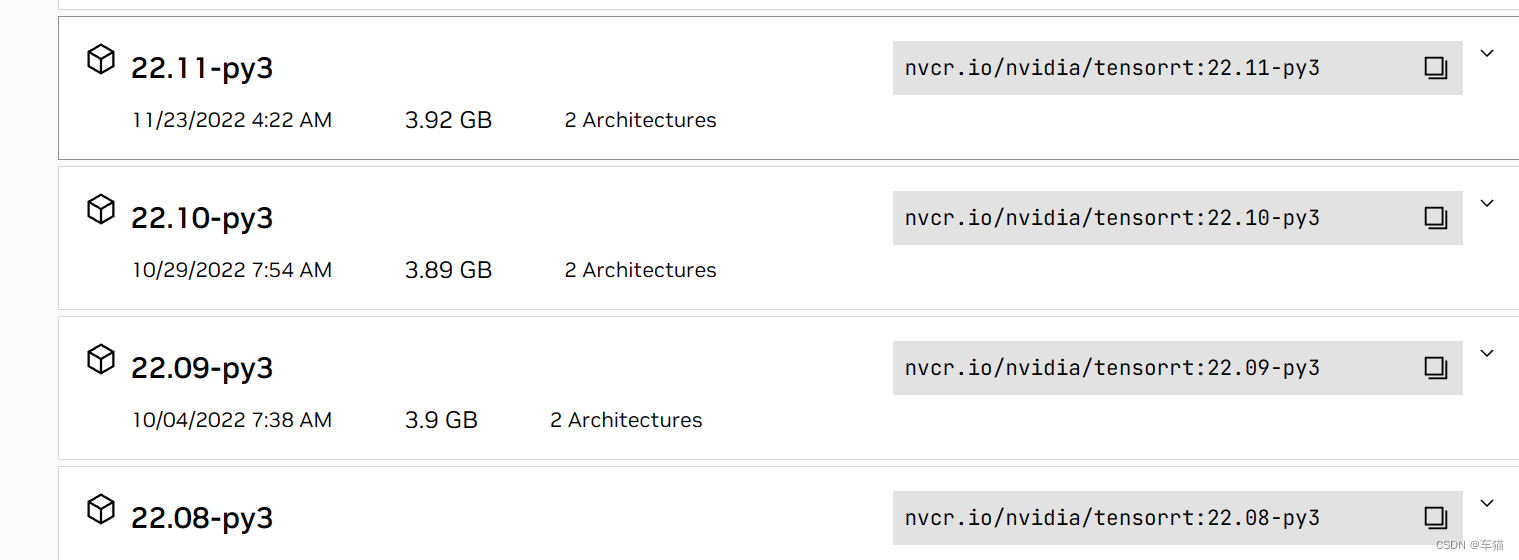
4.1.3 使用nvidia tensorrt镜像
docker pull nvcr.io/nvidia/tensorrt:22.11-py3
4.1.4 使用nvidia集成Tensorrt+torch
从官网下载

版本对应关系
| 容器 | tensorrt 版本 | cuda版本 | torch版本 |
|---|---|---|---|
| 22.08-py3 | 8.4.2-1 | cuda11.6 | 1.13.0 |
| 21.10-py3 | 8.0.3-1 | cuda11.3 | 1.10.0 |
| 21.08-py3 | 8.0.1-1 | cuda11.3 | 1.10.0 |
4.1.4 出现问题
问题一:Error response from daemon: Get "https://registry-1.docker.io/v2/": read tcp XXX->XXX read: connection reset by peer
换源,可选的目前有
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
在拉取时,使用如下命令替换
docker pull docker.m.daocloud.io/chaoyiyuan/tensorrt8:latest
m.daocloud.io/是源的名字chaoyiyuan/tensorrt8:是镜像名字latest:是版本tag
4.2 容器
4.2.1 创建容器
4.2.1.1 在终端设置docker可以显示相关可视化界面
- 宿主机终端运行
DISPLAY=:0.0
xhost +
- 查看环境变量
echo ${DISPLAY}
4.2.1.2 创建容器
- 推荐使用
sudo nvidia-docker run -it --privileged=true -p 7777:8888 --gpus all --net host --env NVIDIA_DISABLE_REQUIRE=1 --ipc=host -v /data:/data -e DISPLAY=unix$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -e GDK_SCALE -e GDK_DPI_SCALE --name test1 b7a4c /bin/bash
- 支持usb 热插拔:使用之后,未见效
sudo nvidia-docker run -it --privileged=true -p 7777:8888 --gpus all --ipc=host -v /dev/bus/usb:/dev/bus/usb -e DISPLAY=unix$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -e GDK_SCALE -e GDK_DPI_SCALE --name test1 b7a4c /bin/bash
-i:交互式操作-t:终端-p 7777:8888:把主机的7777端口映射到容器的8888端口- –privileged=true:调用GPU资源
-ipc=host:让容器与主机共享内存--name xxxxx:给容器定义一个个性化名字-v /home/shcd/Documents/gby:/gby:主机上的/home/shcd/Documents/gby地址挂载到容器里,并命名为/data文件夹- 这样这个文件夹的内容可以在容器和主机之间共享了
- 因为容器一旦关闭,容器中的所有改动都会清除,所以这样挂载一个地址可以吧容器内的数据保存到本地。 -
90be7604e476则是你安装的镜像的id- 可以在刚刚docker images命令后面查看,当然你也可以直接写全名ufoym/deepo:all-py36-jupyter
/bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash--net host保证代理网络连接,使用宿主机的网络NVIDIA_DISABLE_REQUIRE=1: 规避官方nvidia镜像对cuda的检查,因为cu118出现检查问题--net host:使用主机网络,共享VP
4.2.1.3 使用代理
-
首先在ubuntu上使用qv2ray设置好代理和端口,一般socks5默认是127.0.0.1:1088
-
然后设置全局代理,在容器内命令行中输入
export all_proxy="socks5://127.0.0.1:1088"
- 查看是否成功代理
默认网络是否使用代理
# 在命令行中输入curl cip.cc 查看ip地址是否已经成功代理
curl cip.cc
绕过大陆的情况下curl cip.cc会显示正确位置,curl ifconfig.me会显示代理地址
使用下面查看是否使用代理
curl ifconfig.me
4.2.2 进入已运行的容器
docker attach d6a0f155273a
- d6a0f155273a: 容器 id
4.2.3 退出容器
ctrl+D
4.2.4 删除容器
1)首先需要停止所有的容器
docker stop $(docker ps -a -q)
2)删除所有的容器(只删除单个时把后面的变量改为container id即可)
docker rm $(docker ps -a -q)
4.2.5 启动容器
sudo docker start 容器id
其他
docker logs 容器id查看容器运行日志
docker logs -tf 容器id
docker logs --tail num 容器id # num为要显示的日志条数
docker top 容器id查看容器中进程信息
docker top 容器id
docker inspect 容器id查看容器的元数据
docker inspect 容器id
4.3 卸载
sudo apt-get purge docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin docker-ce-rootless-extras
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd
sudo apt-get purge -y nvidia-docker2
5 常用命令
5.1 命令
5.1.1 常用命令
sudo apt-get purge docker-ce docker-ce-cli containerd.io docker-compose-plugin
docker ps 查看当前运行中的容器
docker ps -a 查看所有容器
docker images 查看镜像列表
docker rm container-id 删除指定 id 的容器
docker stop/start container-id 停止/启动指定 id 的容器
docker rmi image-id 删除指定 id 的镜像
docker volume ls 查看 volume 列表
docker network ls 查看网络列表
docker ps -s 查看docker 容器大小
5.1.2 查看端口
docker port container_name
例:
7770/tcp -> 0.0.0.0:7779
表示容器的 7770端口已映射到宿主机上的 7779端口。
5.2 docker 查看容器和镜像大小
- 查看整体大小
docker system df
- 查看 每个 image、container 详细大小
docker system df -v
5.3 停止和杀死容器
- docker stop 执行时,首先给容器发送一个TERM信号,让容器做一些退出前必须做的保护性、安全性操作,然后让容器自动停止运行,如果在一段时间内容器没有停止运行,再执行 kill -9 指令,强制终止容器。
sudo docker stop test
-
test: 容器名
-
docker kill 执行时,不论容器是什么状态,在运行什么程序,直接执行 kill -9 指令,强制终止容器。
5.4 删除镜像
docker rmi image-id
5.5 拷贝文件至镜像中 Docker cp
参考
作用:将主机中的文件拷贝到目标docker容器中
# 将容器内的文件拷贝到主机内
docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH]
# 将主机内的文件拷贝到容器中
docker cp [OPTIONS] SRC_PATH CONTAINER:DEST_PATH|
实例
- 将主机/www/runoob目录拷贝到容器96f7f14e99ab中,目录重命名为www。
docker cp /www/runoob 96f7f14e99ab:/www - 将容器
96f7f14e99ab的/www目录拷贝到主机的/tmp目录中。docker cp 96f7f14e99ab:/www /tmp/
6. build镜像
6.1 运行
6.2 案例
下载以下三个
torch-1.8.2+cu111-cp38-cp38-linux_x86_64.whl
torchaudio-0.8.2-cp38-cp38-linux_x86_64.whl
torchvision-0.9.2+cu111-cp38-cp38-linux_x86_64.whl
- 打开dockerfile
gedit Dockerfile
- Dockerfile文件
#安装python运行环境
#
################################################
#基于哪个镜像生成新的镜像
FROM nvidia/cuda:11.1-cudnn8-devel-ubuntu18.04
RUN rm /etc/apt/sources.list.d/cuda.list
#作者名
MAINTAINER SunPengfei
#设置环境变量
ENV TZ Asia/Shanghai
ENV LANG zh_CN.UTF-8
# 拷贝下载好的whl文件到镜像中
#COPY torch-1.10.1+cu111-cp38-cp38-linux_x86_64.whl /tmp
#COPY torchaudio-0.10.0+cu111-cp38-cp38-linux_x86_64.whl /tmp
#COPY torchvision-0.11.0+cu111-cp38-cp38-linux_x86_64.whl /tmp
#执行命令
#替换为阿里源
RUN sed -i 's#http://archive.ubuntu.com/#http://mirrors.aliyun.com/#' /etc/apt/sources.list \
&& sed -i 's#http://security.ubuntu.com/#http://mirrors.aliyun.com/#' /etc/apt/sources.list
#更新软件源并安装软件
RUN apt-get update -y \
&& apt-get -y install iputils-ping \
&& apt-get -y install wget \
&& apt-get -y install net-tools \
&& apt-get -y install vim \
&& apt-get -y install openssh-server \
&& apt-get -y install python3.8 \
&& apt-get -y install python3-pip python3-dev python3.8-dev \
&& apt-get -y install libgl1 \
&& apt-get -y install git \
&& cd /usr/local/bin \
&& rm -f python \
&& rm -f python3 \
&& rm -f pip \
&& rm -f pip3 \
&& ln -s /usr/bin/python3.8 python \
&& ln -s /usr/bin/python3.8 python3 \
&& ln -s /usr/bin/pip3 pip \
&& ln -s /usr/bin/pip3 pip3 \
&& python -m pip install --upgrade pip \
&& cd /tmp \
&& pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html \
&& apt-get clean \
&& rm -rf /tmp/* /var/lib/apt/lists/* /var/tmp/* \
- build
sudo docker build -t ubuntu18:v0 .
-t:- 写入镜像标签ImageName: - 这是您要为镜像指定的名称。TagName: - 这是您要为镜像指定的标签。dir: - Dockerfile所在的目录。
6.3 问题
6.3.1. gpg问题
参考一
问题描述:
GPG error: xxxInRelease: Thefollowing signatures couldn't beverified because the public key isnot available: NO PUBKEYA4B469963BF863CC
解决方案
如果出现没有次公钥,则在对应的DOCKER FILE中加入此公钥
RUN apt-key del 3bf863cc
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
6.3.2. 更换国内源
RUN sed -i 's#http://archive.ubuntu.com/#http://mirrors.tuna.tsinghua.edu.cn/#' /etc/apt/sources.list;
RUN apt-get update --fix-missing
6.3.3. 超时
问题描述

网络连接失败,需要在git和https反复尝试,加上kxsw。
措施:
RUN pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"
# or
RUN pip install "git+git://github.com/facebookresearch/pytorch3d.git@stable"
6.3.4. pip+git安装问题
问题:
docker中的会出现连接不上,下载不成功等问题
RUN pip install git+https://github.com/facebookresearch/pytorch3d.git@stable
解决方案:
可以先下载到本地,然后进行安装
RUN git clone https://github.com/facebookresearch/pytorch3d.git && cd pytorch3d && git checkout stable && pip install -e .
7. 提交和保存
7.1 容器提交生成镜像
docker commit -m="描述信息" -a="作者" 容器id 目标镜像名:[TAG]
-
-a:提交的镜像作者; -
-m:提交时的说明文字; -
-p:在commit时,将容器暂停。
7.2 保存
存在两种方式,一种是先提交,再保存;一种是直接导出容器
7.2.1 保存镜像
docker save ID > xxx.tar
docker load < xxx.tar
7.2.2 保存容器
docker export ID >xxx.tar
docker import xxx.tar containr:v1
8. Docker磁盘空间不足如何解决
8.1. docker 所在磁盘空间不足
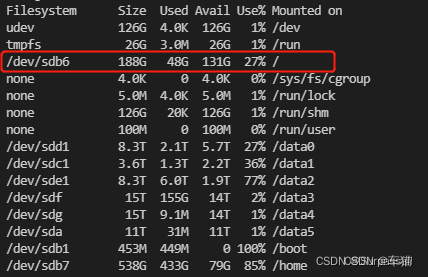
8.1.1 查看服务器所有磁盘的使用情况:
df -h
可以看到,红框处就是系统盘的大小,总大小是188G(相对其他盘小太多),之前是占满的,但是博主已经做了迁移,所以空出了很大的空间。
8.1.2 查看docker镜像和容器存储目录的空间大小
du -sh /var/lib/docker/
8.1.3 停止docker服务
service docker stop
8.1.4 将docker迁移到大容量的磁盘中
8.1.4.1 方法一:创建软连接(推荐)
- 进入root
su root
- 移动文件位置
#移动文件位置
cp -a /var/lib/docker /data/
- 创建软连接
#创建软连接
sudo ln -fs /data/docker /var/lib/docker
- 重新加载
#重新加载配置&查看位置
systemctl daemon-reload
systemctl restart docker
service docker start
- 验证
如果还在,则证明有效
docker images
8.1.4.2 方法二
- 首先创建目录
mkdir -p 大磁盘目录/docker/lib/
- 迁移
rsync -avz /var/lib/docker /mnt/docker/lib/
8.1.5 编辑/etc/docker/daemon.json,添加参数,将docker的目录迁移绑定
修改文件:
sudo vim /etc/docker/daemon.json
红框是添加的参数
{
"registry-mirrors": ["https://xxxxxxx.mirror.aliyuncs.com"],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
"data-root":"/data/docker/lib/docker"
}

8.1.6 重载和重启docker服务
systemctl daemon-reload && systemctl restart docker
但是systemctl我依然运行失败,所以我是使用以下命令重启docker的:
service docker restart
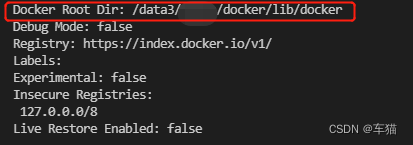
8.1.7 检查docker是否绑定新目录
docker info
如果Docker Root Dir由/var/lib/docker变为你指定的目录,说明迁移成功。
8.1.8 删除docker旧目录
rm -rf /var/lib/docker
8.2. docker运行容器添加硬盘
9. 其他设置
9.1 设置代理
9.1.1 有效
配置宿主机/etc/default/docker
export http_proxy="http://127.0.0.1:8889/"
export https_proxy="http://127.0.0.1:8889/"
export HTTP_PROXY="http://127.0.0.1:8889/"
export HTTPS_PROXY="http://127.0.0.1:8889/"
export all_proxy="socks5h://localhost:1089"
export ALL_PROXY="socks5h://localhost:1089"
重启docker
sudo systemctl daemon-reload
sudo systemctl restart docker
9.1.2 方法二
无效
在宿主机打开文件
sudo vim ~/.docker/config.json
加入代理
9.1.3 测试无效
export ALL_PROXY='socks5://127.0.0.1:1080'
这里ip地址使用的是宿主机的ip
2. 共享网络
与宿主机共享网络时直接在容器内使用
创建容器时使用--network=host参数
sudo nvidia-docker run -it --privileged=true -p 7777:8888 --network=host --gpus all --ipc=host -v /data:/data --name test1 b7a4c /bin/bash
然后在docker内设置代理,比如全局代理
export ALL_PROXY='socks5://127.0.0.1:1080'
- 映射代理端口后直接在容器内使用
docker run时带参数-p映射代理的端口到容器, 在容器里面使用即可,比如:
docker run -p 1080:1080 .....
export ALL_PROXY='socks5://127.0.0.1:1080'
9.2 docker库的配置
9.2.1. libGL
报错
ImportError: libGL.so.1: cannot open shared object file
安装
apt-get update && apt-get install libgl1
9.2.2. ping安装
apt-get install -y iputils-ping
9.2.3. apex安装
安装:RuntimeError: Error compiling objects for extension
git clone https://github.com/NVIDIA/apex
cd apex
python setup.py install --cpp_ext --cuda_ext
- 报错一:
再进行编译
git checkout f3a960f80244cf9e80558ab30f7f7e8cbf03c0a0
9.2.4. boost
报错
fatal error: boost/geometry.hpp: No such file or directory
解决办法
apt-get update
apt-get install libboost-all-dev
9.2.5. cudnn
- 到对应网址下载对应版本的cudnn,linux 电脑端为X86-64

- 解压
tar -xzvf cudnn-10.1-linux-x64-v8.0.5.39.tgz //XXX.tgz是下载的cudnn的压缩包
- 移动对应的文件
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/include/cudnn_version.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
9.3 docker 清除缓存
docker system prune 命令:
- 用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)
- 已停止的容器(container)
- 未被任何容器所使用的卷(volume)
- 未被任何容器所关联的网络(network)
- 所有悬空镜像(image)
docker system prune -a 命令
- 清理得更加彻底,可以将没有容器使用Docker镜像都删掉。
注意,这两个命令会把你暂时关闭的容器,以及暂时没有用到的Docker镜像都删掉了……所以使用之前一定要想清楚
10. docker远程调试
10.1 vscode插件安装
remote-sshremote development
10.2 docker container配置
10.2.1 ssh安装
-
ubutnu 服务器终端安装ssh
apt-get update -
查看SSH服务是否安装或启动的方法:
sudo ps -e |grep ssh查看SSH的版本:ssh -V
-
SSH 服务器的安装:
sudo apt-get install openssh-server -
SSH 客户端的安装:
sudo apt-get install openssh-client -
启动SSH服务
sudo service ssh restart -
关闭SSH服务
service ssh start service sshd stop
10.2.2 配置远程登录密码
- 设置远程登录的密码
如果希望直接使用root账户登录容器,则设置root密码passwd
增加root账户登录许可
10.2.3 配置更改
- 编辑文件
vim /etc/ssh/sshd_config
修改如下
#注释掉
PermitRootLogin prohibit-password
#添加
PasswordAuthentication yes
PermitRootLogin yes
#Port 写容器端口
Port 9901

10.2.4 重启ssh
service ssh restart
10.3 vscode配置
ctrl+shift+p

- 打开配置

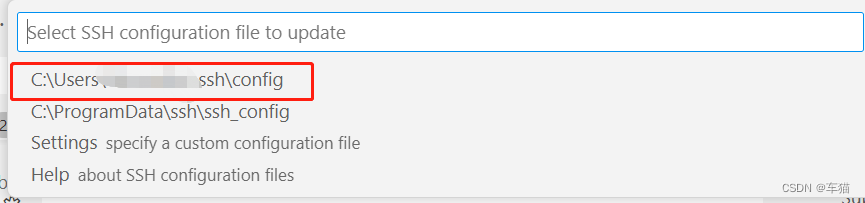
4. 开始配置
# 随便起
Host 2080Ti
# 主机IP
HostName 10.119.XXX.XXX
# DOCKER root用户
User root
# User ubuntu
# docker 端口
Port 9901

10.4 连接
ctrl_shift+P+连接到对应名字即可
10.5 open3d等远程可视化
10.5.1 容器安装
- 容器内部安装
apt-get update
apt-get install x11-xserver-utils
apt-get install x11-apps
- 首先不登录docker,在当前终端下运行
如果实验不成功,则重启容器,重启之后,重新设置当前指令
DISPLAY=:0.0
xhost +
- 登录容器后,再次运行
DISPLAY=:0.0
xhost +
测试是否成功
在容器内运行,会出现始终的小图标
xclock
- 查看环境变量
echo ${DISPLAY}
- 修改ubuntu server下的配置文件
参考一
本人经历过远程无法连接情况,表现为
- 客户端vscode 连接容器卡死
- 但是连接远程电脑,可以。
尝试下面的配置解决
- 打开文件
vim /etc/ssh/sshd_config
- 将
AllowTcpForwarding no
AllowAgentForwarding no
替换为
AllowTcpForwarding yes
AllowAgentForwarding yes
- 保存后重启sshd服务
systemctl restart sshd
10.5.2 本机安装
- 在本地安装vcxsrv
vcxsrv免费下载链接
- 一般自定义自定义下载路径,一个是权限问题,一个是路径查找方便问题
- 一路next直至下载完成。
-
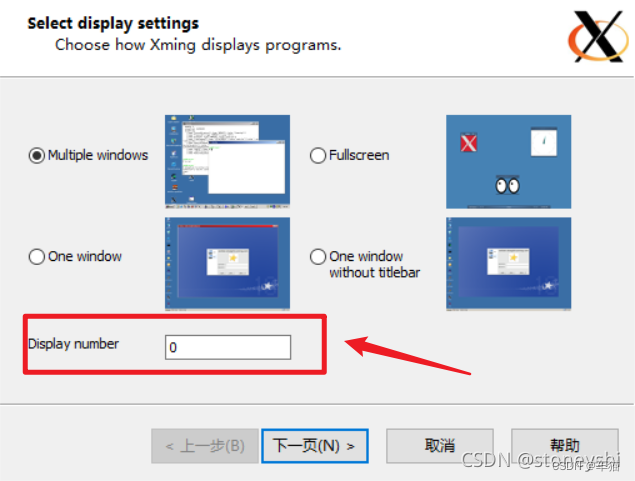
开启服务
打开XLaunch,记住这个Display number 0,其他的一路默认【下一步】就可以了直至完成。

-
修改vcxsrv配置。找到安装目录下的文件
- 0代表上面提到的
DISPLAY:0
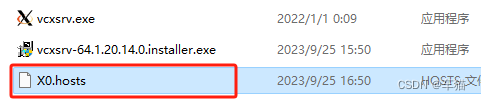
- 加入远程服务器的IP,保存

10.5.3 vscode 配置
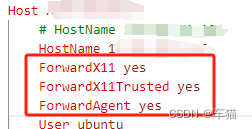
- 打开文件
C:\Users\用户名.ssh\config中添加如下3行:
ForwardX11 yes
ForwardX11Trusted yes
ForwardAgent yes
2. launch文件配置
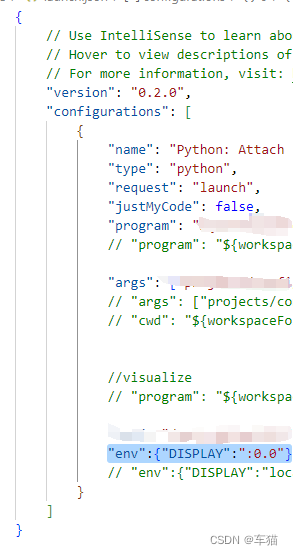
在.vscode/launch.json文件中
"env":{"DISPLAY":":0.0"}
10.5.4 问题
10.5.4.1 libGL.so.1
出现libGL.so.1: cannot open shared object file: No such file or directory问题。
- 第一步,安装包
pip install opencv-python-headless
- 安装库
apt-get update
apt-get install ffmpeg libsm6 libxext6 -y
10.5.4.2 failed to open swrast
参考
问题
libGL error: MESA-LOADER: failed to open swrast
方案:
cd /usr/lib/
sudo mkdir dri
sudo ls -s /lib/x86_64-linux-gnu/dri/swrast_dri.so swrast_dri.so
在自己的虚拟环境中:
conda install -c conda-forge gcc
10.7 conda 使用
10.7.x 问题
10.7.x.1 conda init问题
jie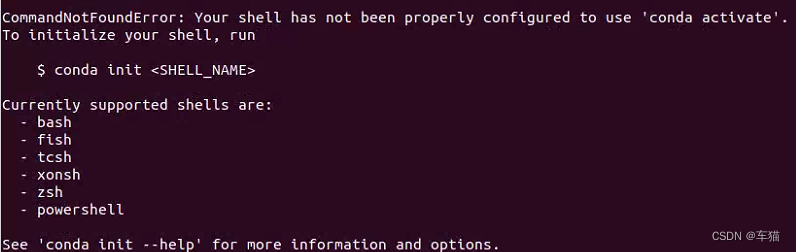
解决方案
source /opt/conda/bin/activate env_name
10.6 tensorboard 调用
- 打开
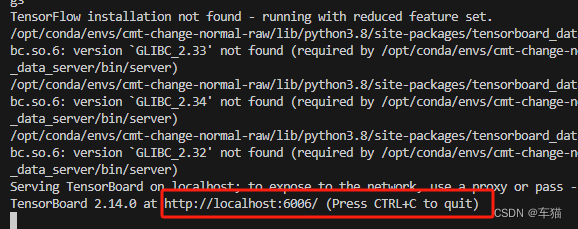
vscode终端 conda activate env_name- 进入tf_log目录,运行指令
tensorboard --logdir=work_dirs_name --port='6009' - 点击网址,进入浏览器查看
11 docker打包本地镜像,拷贝到其它宿主机上运行
参考
docker获取镜像的方式除了 pull 之外还有一种是将本地镜像打包拷贝给其它宿主机来运行。假设现实环境中本地仓库和远程仓库均连接异常, 那我们将事先打好包的镜像分发给其它docker节点用也是一种解决方法。
具体操作步骤如下:
- 执行如下命令找到被打包镜像的名字和版本号 (版本号=TAG)
docekr images
- docker打包镜像的两种方式 (选一种执行即可)
docker save 镜像名字:版本号 > /root/打包名字.tar
docker save -o /root/打包名字.tar 镜像名字:版本号
-
将打包镜像分发到其它宿主机的 /root/ 目录下
-
将打成 tar 包的镜像 load 出来
docker load < /root/打包名字.tar
- 查看 load 出来的镜像ID
docekr images
- 刚 load 出来的镜像其名字、版本号均为 none, 我们要通过 tag 命令赋予名字和版本号
docker tag 镜像ID 镜像名字:版本号















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









