






第0章、前言与相关知识
C语言与底层机器开发关联很大,是一种面向过程编程语言,什么是面向过程?简单点来说就是把一个事情拆分成几个步骤,逐一从上到下编译执行。
这个网址是有关C语言的简述,大家自行查阅
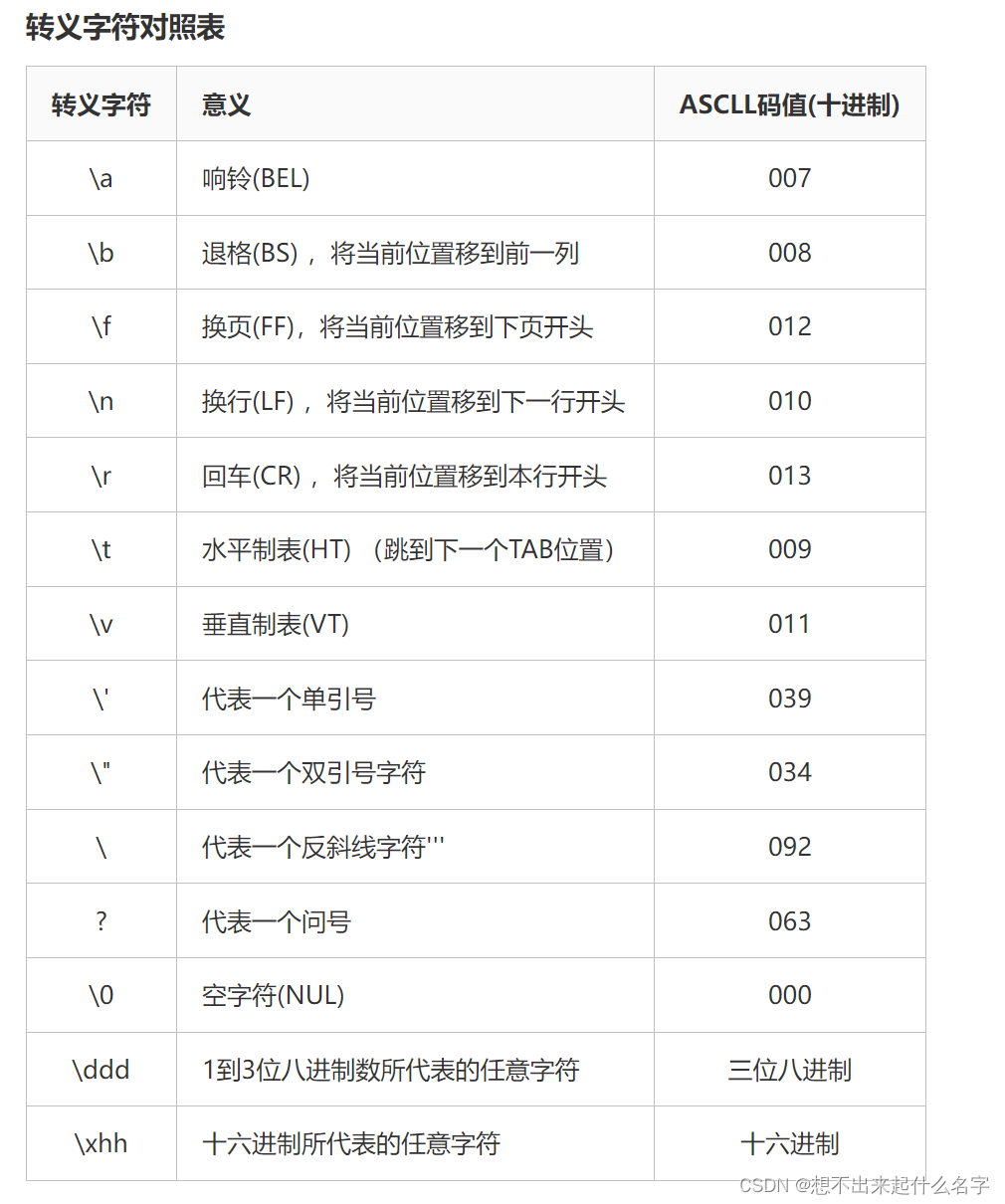
ASCII码
大家可以理解成计算机二进制储存与字符的映射

这是一张ASCII表,不需要特殊记忆,需要用的时候查表即可。
这里推荐大家记忆几组关键的就好
***A~Z对应着65~90
***a~z对应着97~122
***对应的大小写字符(a和A)的ASCII码值的差值是32
***数字字符0~9的ASCII码值从48~57
***在这些字符中ASCII码值从0~31 这32个字符是不可打印字符,无法打印在屏幕上观察
***换行符 \n 对应ASCII码为10
看段代码,打印出可打印的字符
int main()
{
int character = 0;
for (size_t i = 32; i <= 127; i++)
{
printf("%c ", i);
if (i % 16 == 15)
printf("\n");
}
return 0;
}
转义字符——转变原来的意思的字符
相关知识这些就足够了,接下来我们进入正题
第1章、内置数据类型与变量
什么是数据类型?数据的表达形式,比如说整数、小数(浮点型),计算机会接收不同的类型来进行操作,何为内置?就是C语言自带的类型
类型分类
整型大类:
短整型 short [int] [signed] short [int] unsigned short [int] 整型 int [signed] int unsigned int 长整型 long [int] [signed] long [int] unsigned long [int] 更长的整型 C99中引入 long long [int] [signed] long long [int] unsigned long long [int]
//其实这些书写起来有点麻烦,C语言给我们提供了一个stdint的头文件,不需要写这么麻烦,后续会演示
字符大类:[signed] char //有符号的 unsigned char //无符号的
浮点型大类:float double long double
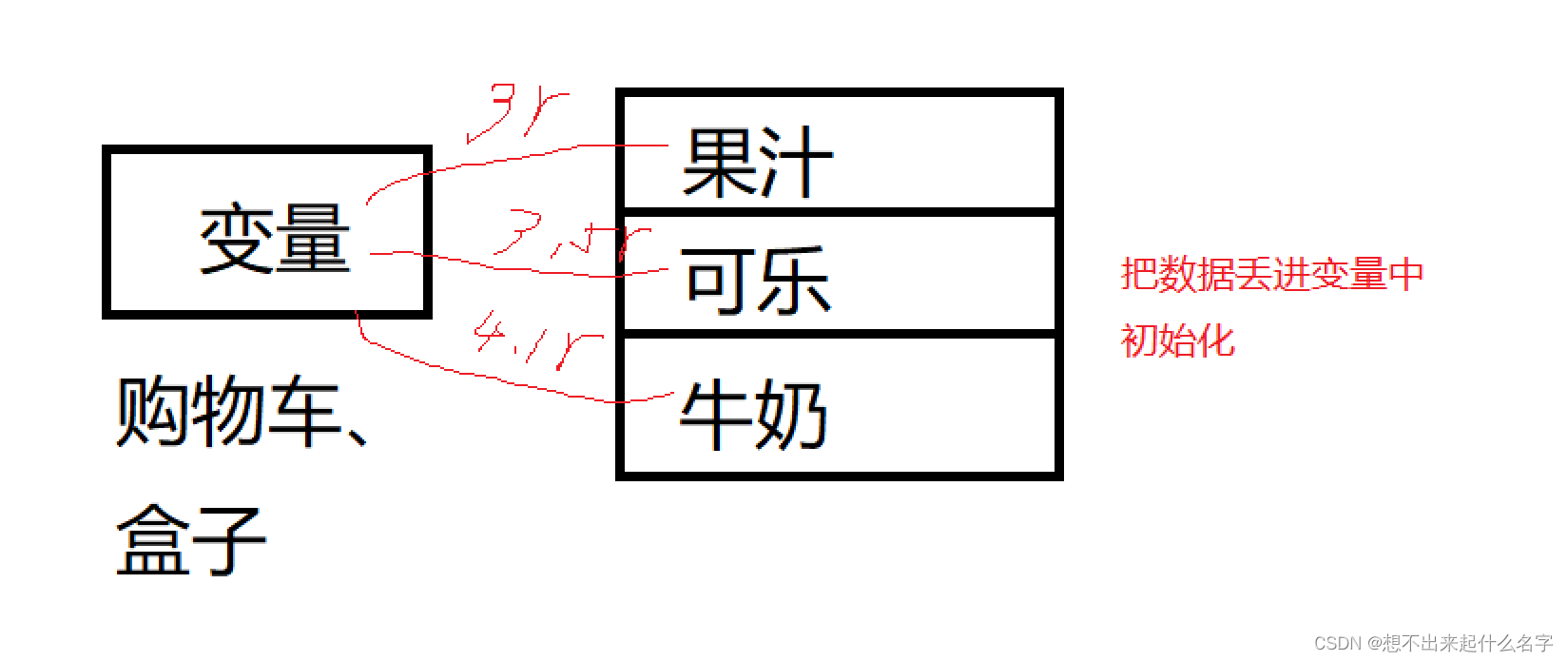
变量
我们可以把变量理解为一个盒子,用来装数据的
创建一个类型——把数据放进这个盒子
画张图理解一下
变量分为全局变量和局部变量
全局变量是定义在大括号外面的变量,作用域广、生命周期长,可以全局操作
局部变量是定义在大括号内部的变量,作用域窄、生命周期短,只能在所在大括号内操作
当局部变量和全局变量重名时,局部变量优先使用!

整型——integer
int input; //变量的声明
int input = 0; //变量的初始化
intput = 12; //重新给变量赋值
int dogs, cats, pigs = 1; //这种写法可读性很差,需要避免这种情况
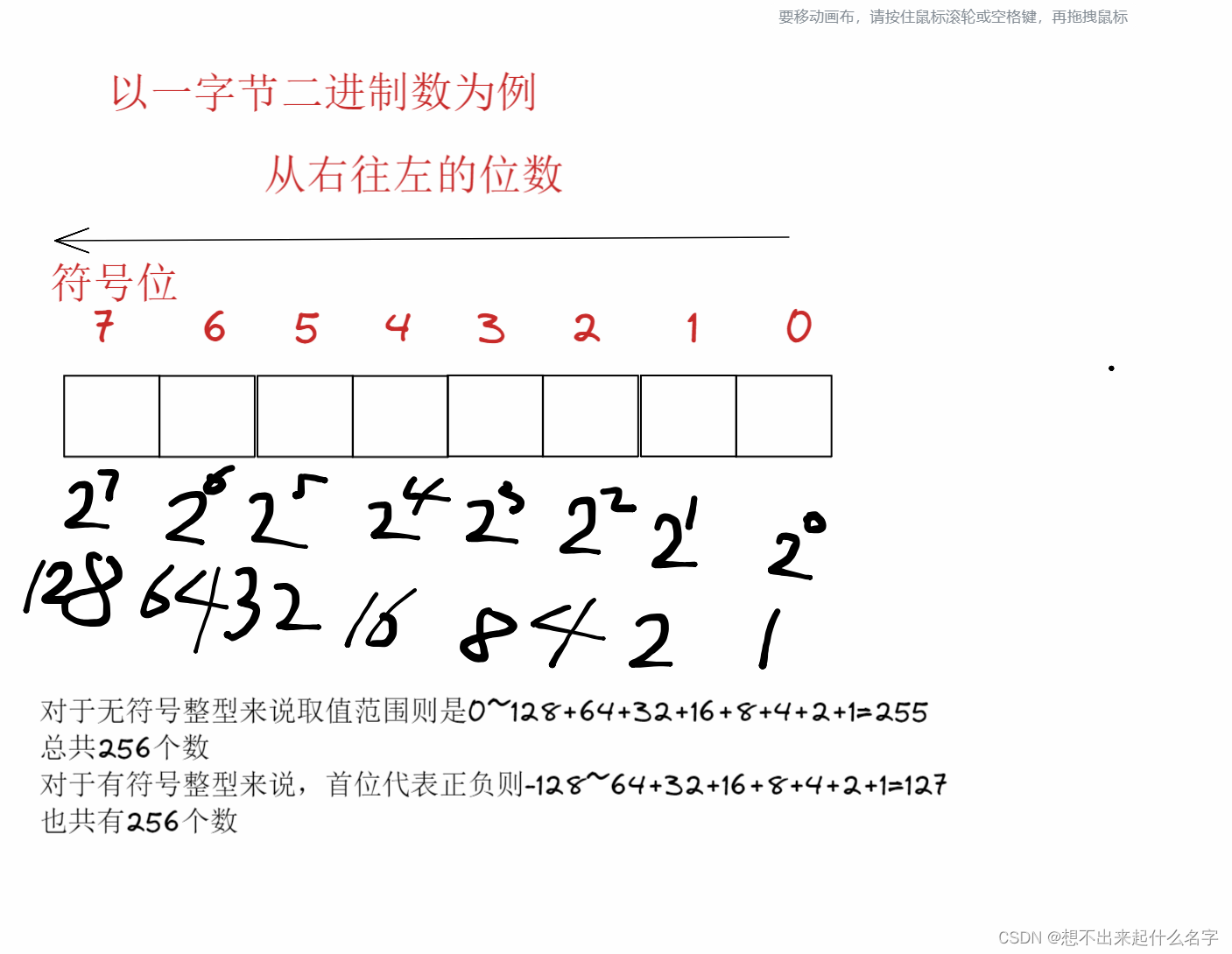
关于类型的取值范围问题
现在想象一下有两盏灯,亮表示1,灭表示0
不计算0,因为0没有正负之分
一共可以表示为01 10 11 这三个数
所以2bit可以表示的数有2^2 - 1
同理推广到32bit
第二种理解:
后续都可推广
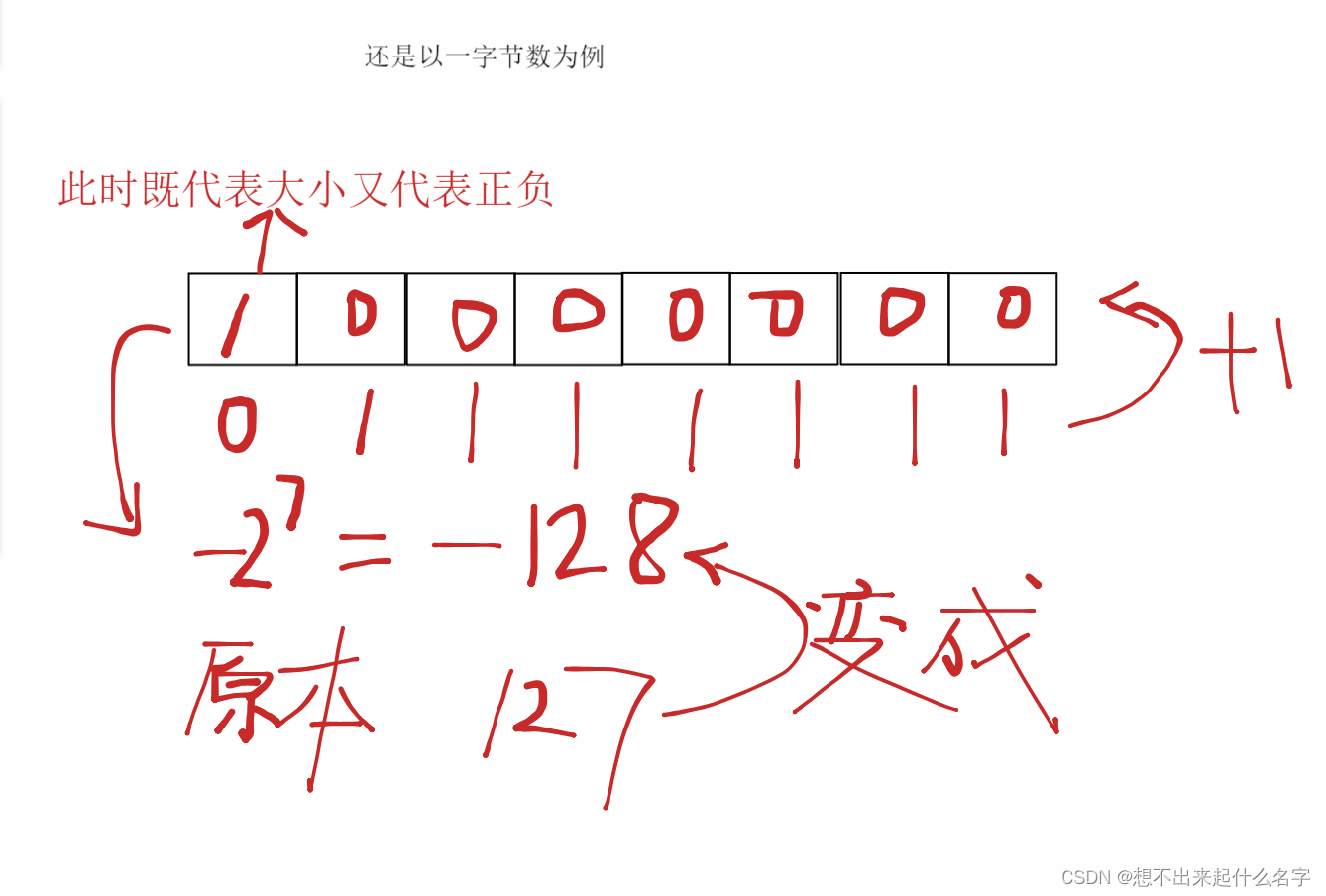
理解整型溢出
#include <stdio.h>
#include <stdint.h>
int main() {
uint8_t u8_max = UINT8_MAX + 1;
int8_t i8_max = INT8_MAX + 1;
printf("u8_max + 1 = %u\ni8_max + 1 = %d\n", u8_max, i8_max);
return 0;
}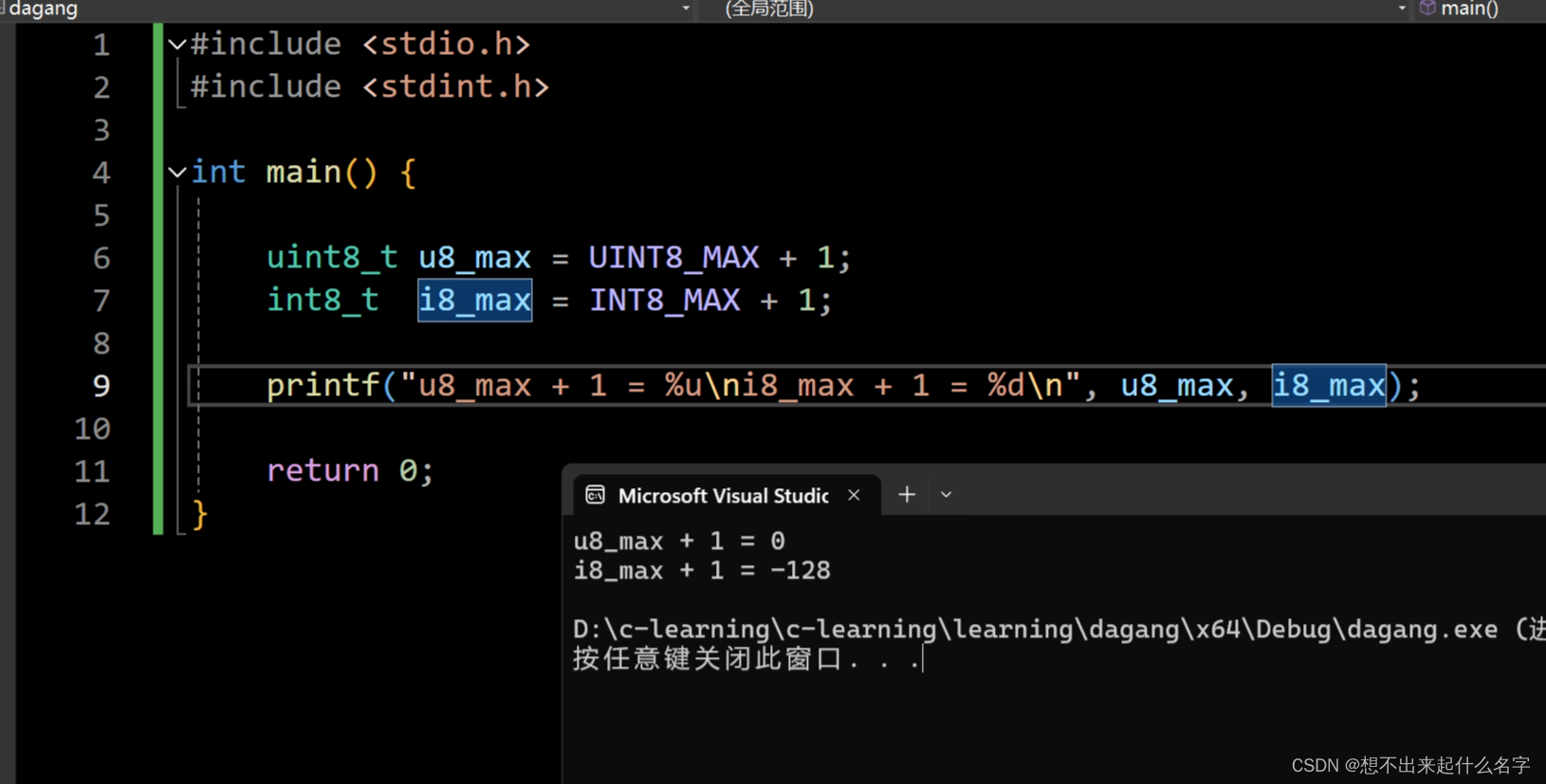
用段代码来理解,在无符号中如果溢出,则从最小值零开始,就像是汽车里程表,到达最大值,重新从零开始
在有符号中如果溢出,则从最小值开始-128开始逐渐增加
UINT8_MAX,INT8_MAX这两个常量是定义在这个头文件中
浮点型:整数部分和小数部分分开储存
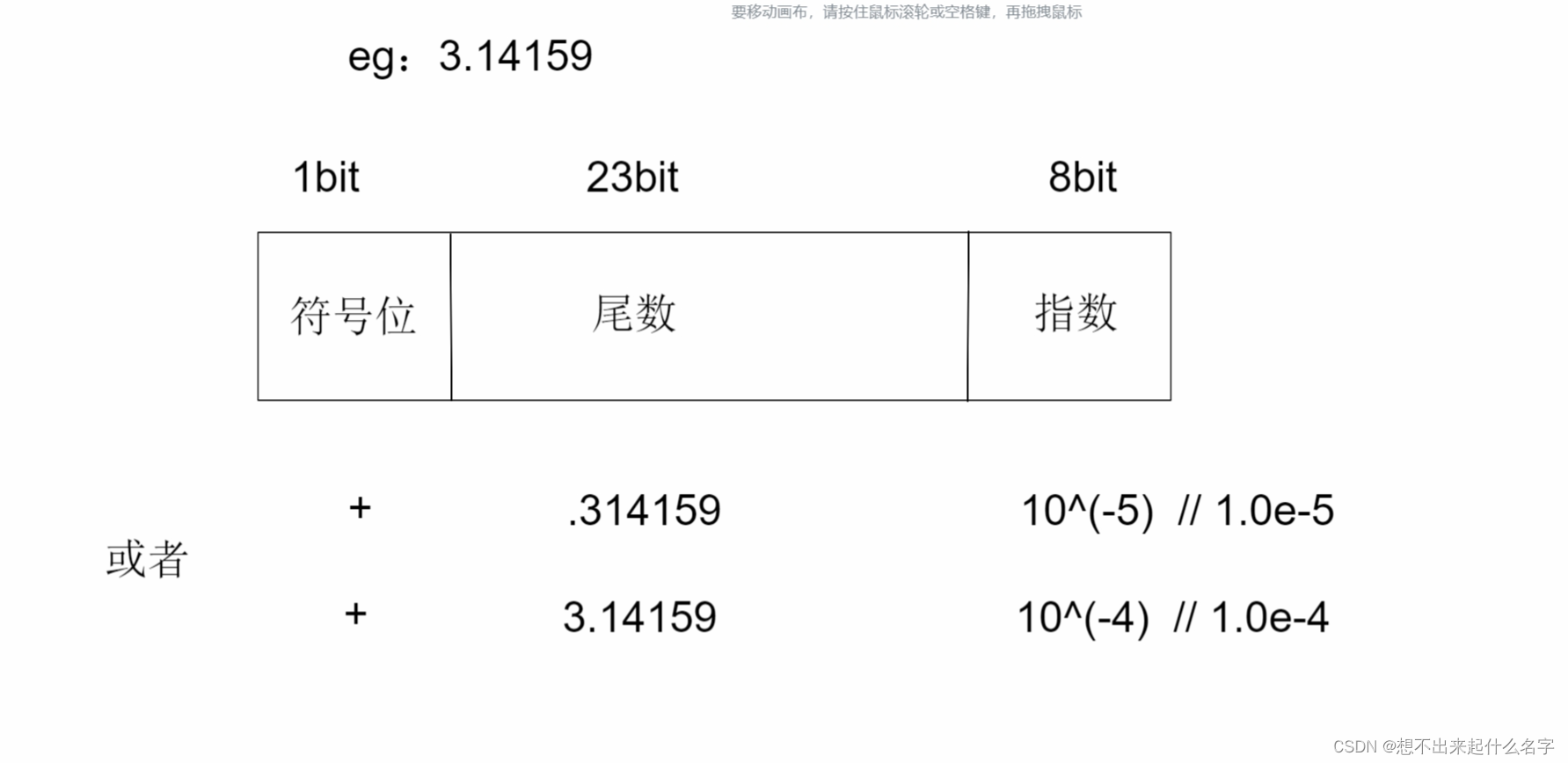
按照IEEE754标准储存,具体内容请学习计算机组成原理
感兴趣的朋友可以看看这篇博客
最近偶数舍入/银行家舍入
int main() {
float num1 = 3.24;
float num2 = 3.25;
float num3 = 3.26;
float num4 = 3.14;
float num5 = 3.15;
float num6 = 3.16;
printf("%.1f \n%.1f \n%.1f\n", num1, num2, num3);
printf("\n");
printf("%.1f \n%.1f \n%.1f\n", num4, num5, num6);
return 0;
}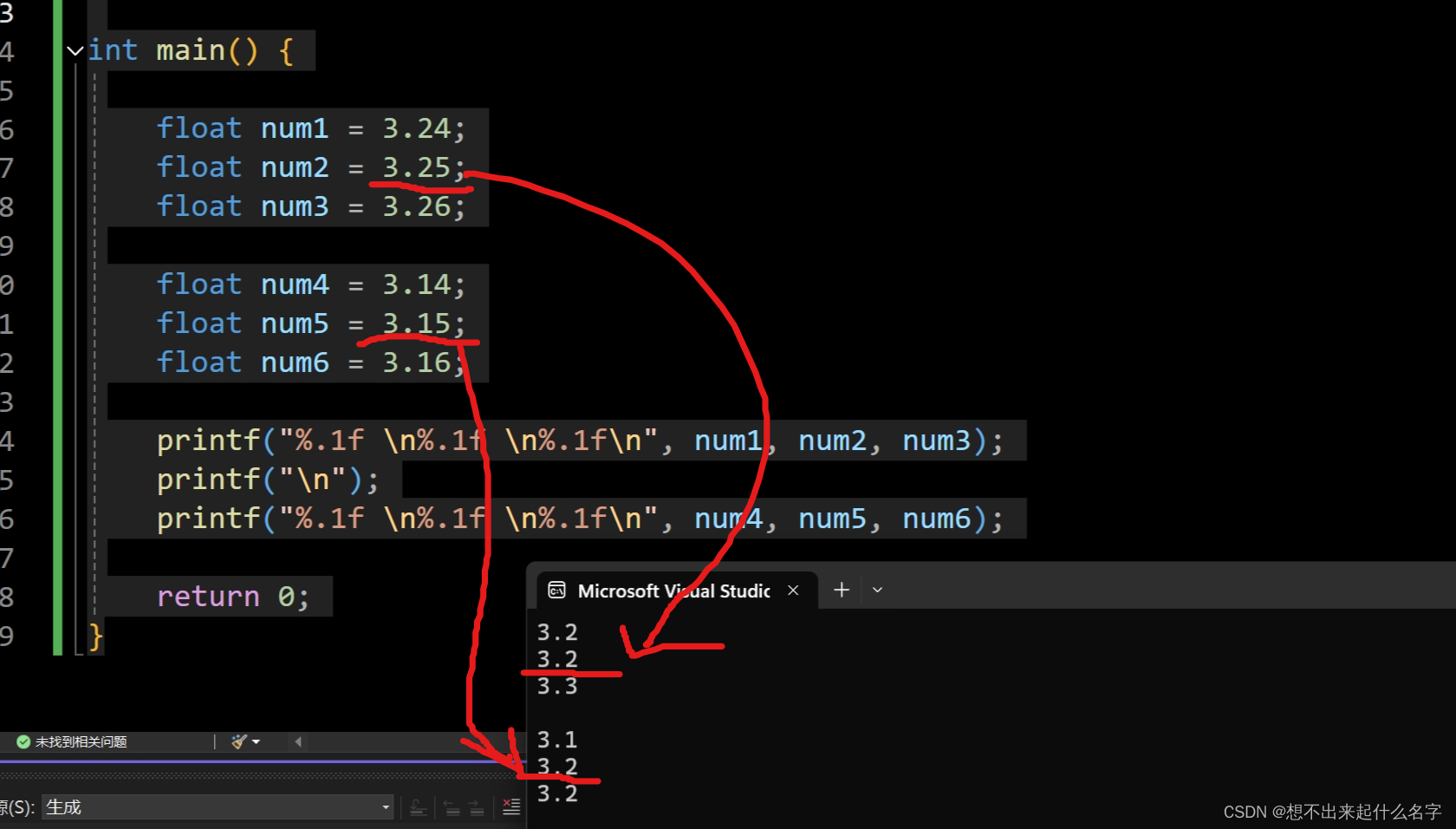
得出结论:
尾数的整数部分是奇数,向上舍入,使其变为偶数
尾数的整数部分是偶数,保持不变,它已经是偶数
输出方式
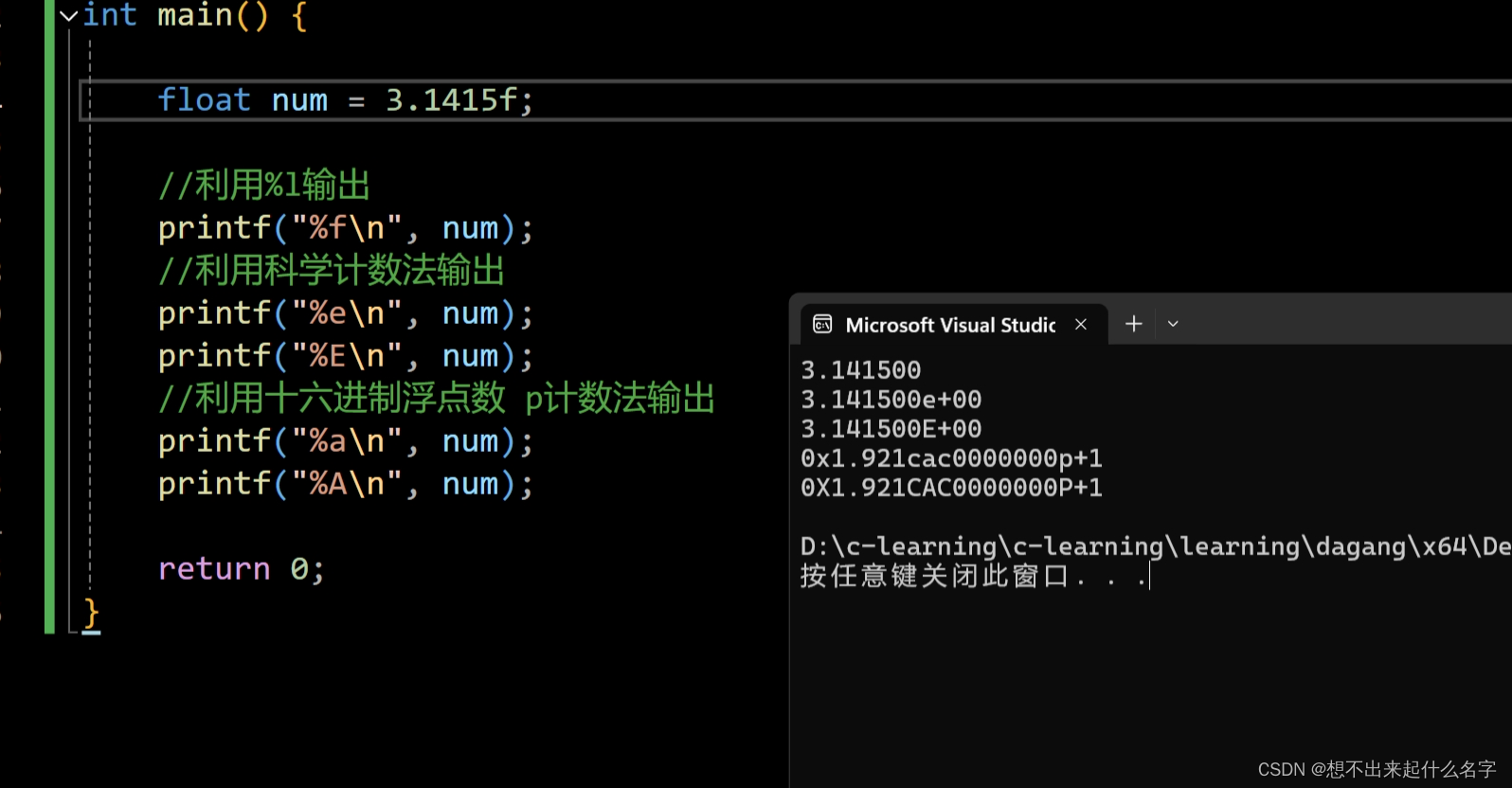
int main() {
float num = 3.1415f;
//利用%l输出
printf("%f\n", num);
//利用科学计数法输出
printf("%e\n", num);
printf("%E\n", num);
//利用十六进制浮点数 p计数法输出
printf("%a\n", num);
printf("%A\n", num);
return 0;
}
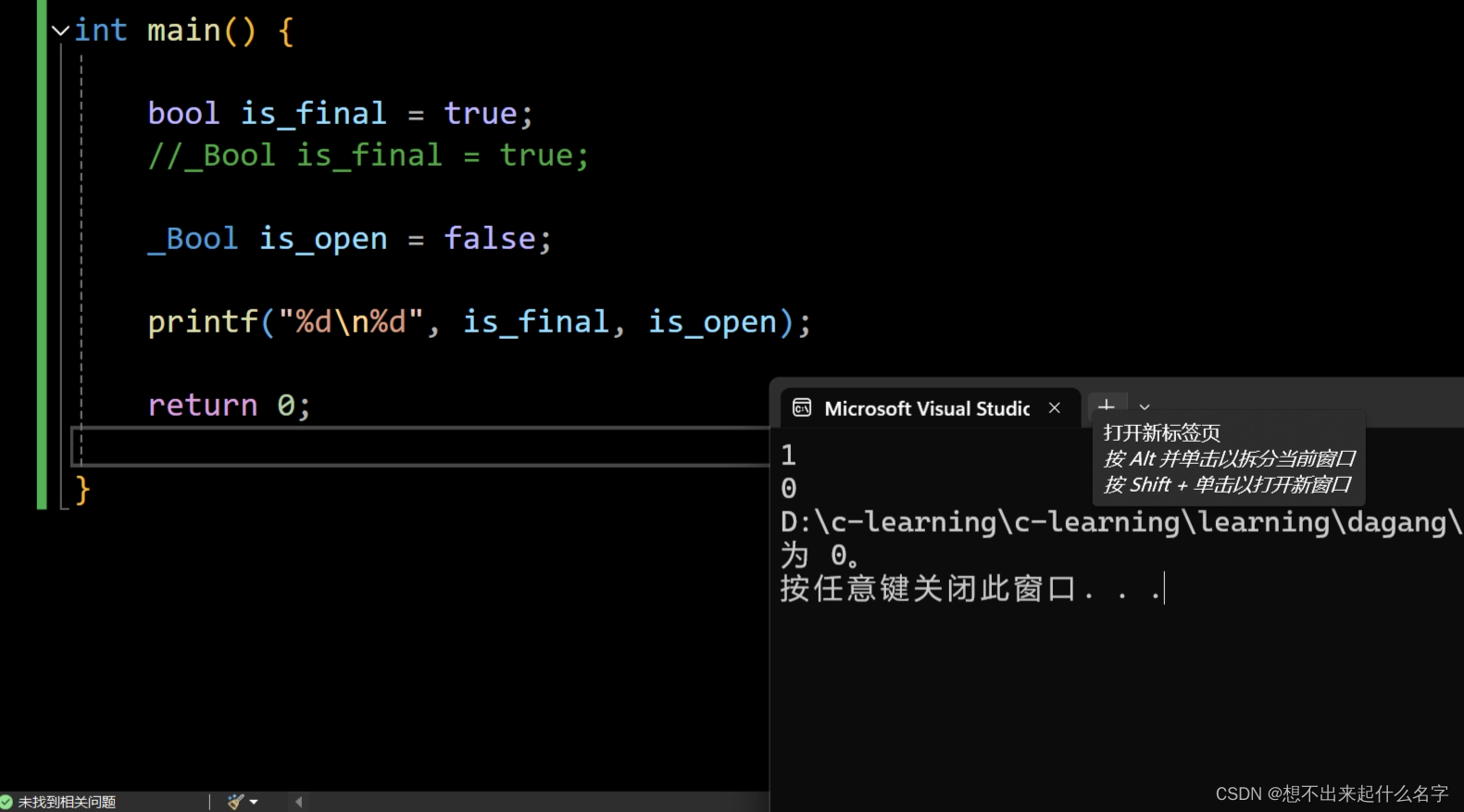
bool类型:判断真假
需要引入stdbool头文件
int main() {
bool is_final = true;
//_Bool is_final = true;
_Bool is_open = false;
printf("%d\n%d", is_final, is_open);
return 0;
}
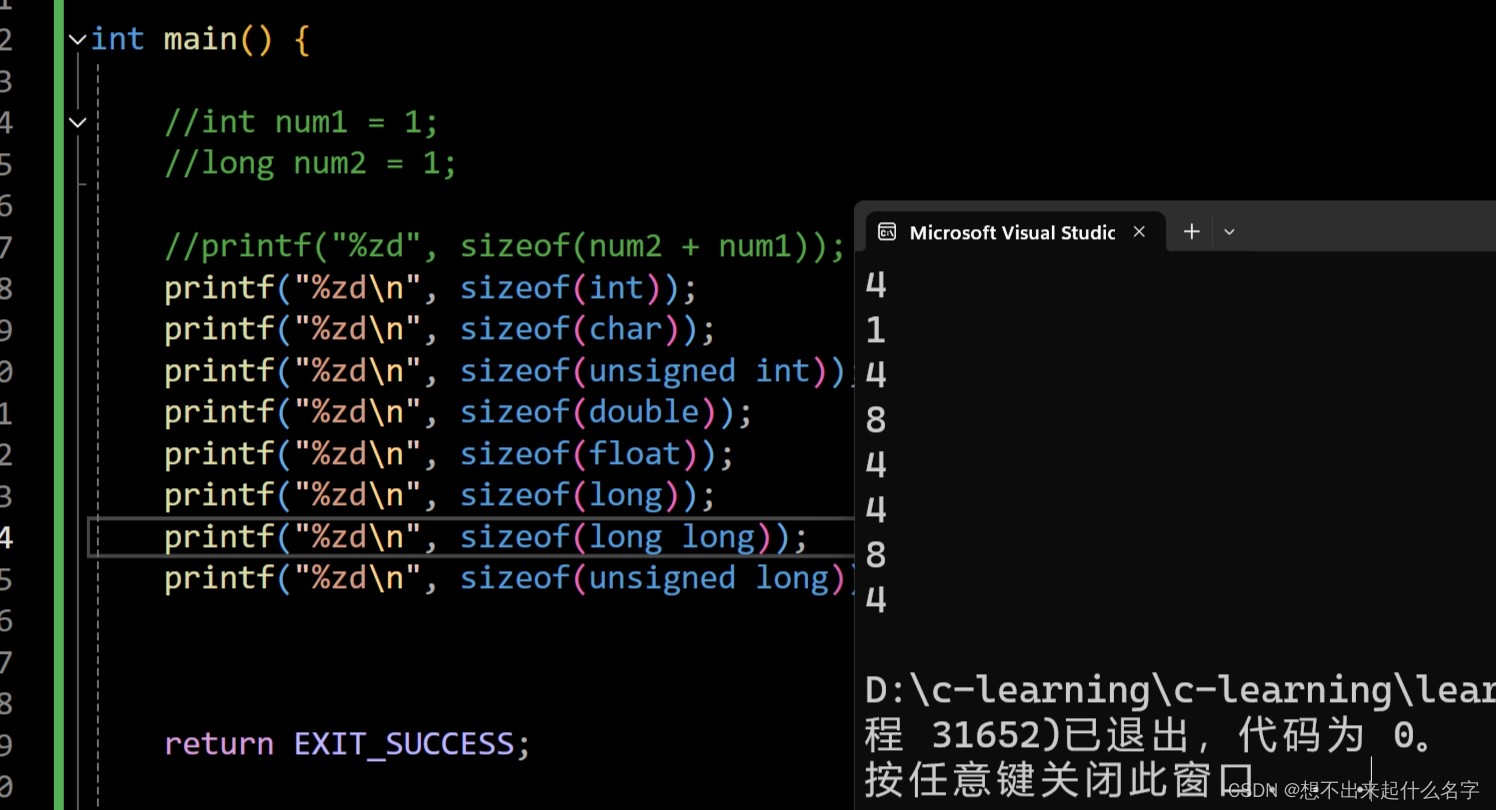
类型的大小
引入sizeof()操作符
sizeof()专门用来计算sizeof操作符数的类型长度即所占空间大小,单位是字节,其操作数可以是类型,也可以是变量或者表达式
表达式不计算
int main() {
//int num1 = 1;
//long num2 = 1;
//printf("%zd", sizeof(num2 + num1));
printf("%zd\n", sizeof(int));
printf("%zd\n", sizeof(char));
printf("%zd\n", sizeof(unsigned int));
printf("%zd\n", sizeof(double));
printf("%zd\n", sizeof(float));
printf("%zd\n", sizeof(long));
printf("%zd\n", sizeof(long long));
printf("%zd\n", sizeof(unsigned long));
return EXIT_SUCCESS;
}
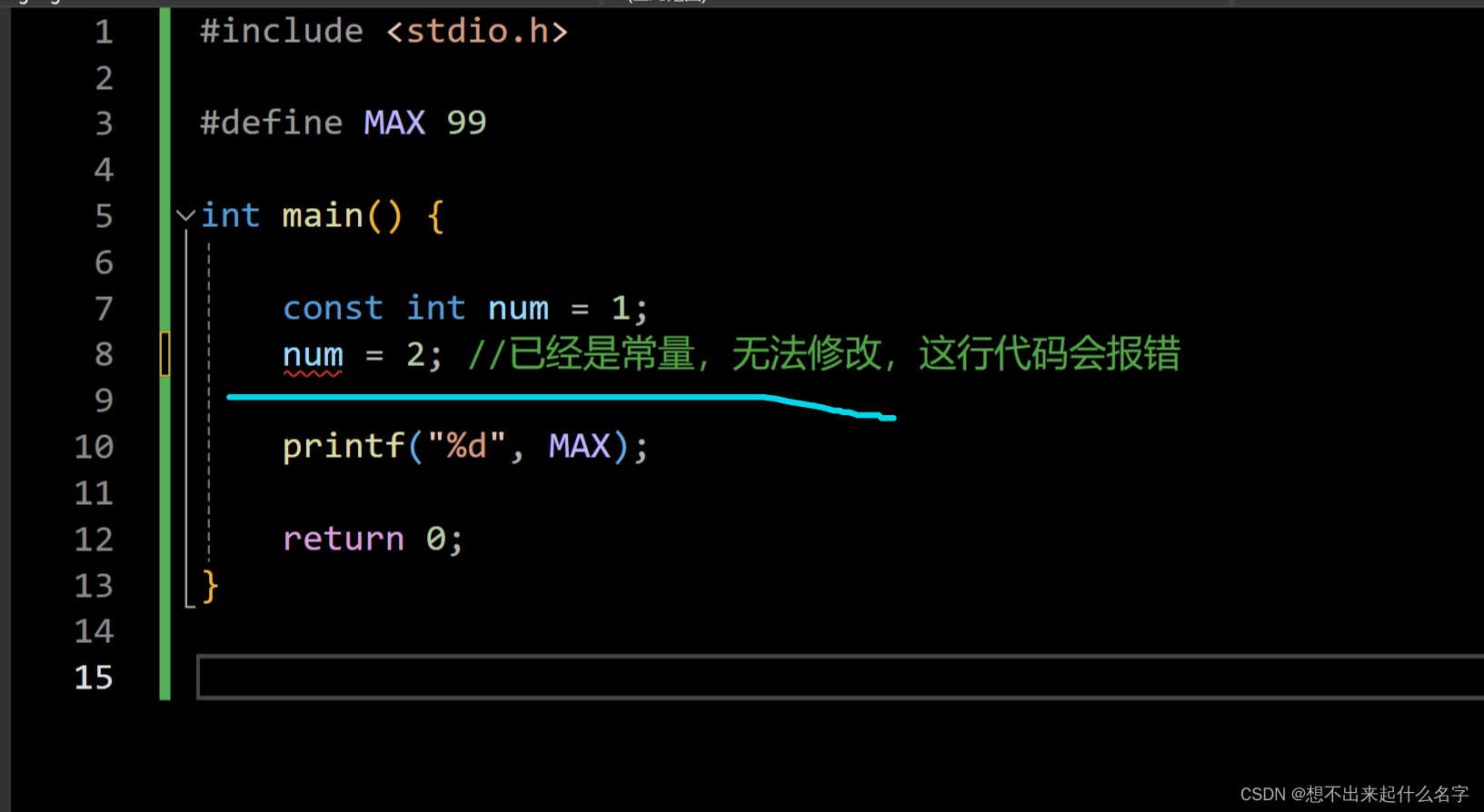
宏定义#define与常量const
#include <stdio.h>
#define MAX 99
int main(){
const int num = 1;
//num = 2; //已经是常量,无法修改,这行代码会报错
printf("%d",MAX);
return 0;
}
初识输入与输出
printf:将内容格式化输出到屏幕上
int printf(
const char *format [,
argument]... );
例如:打印十六进制和八进制数
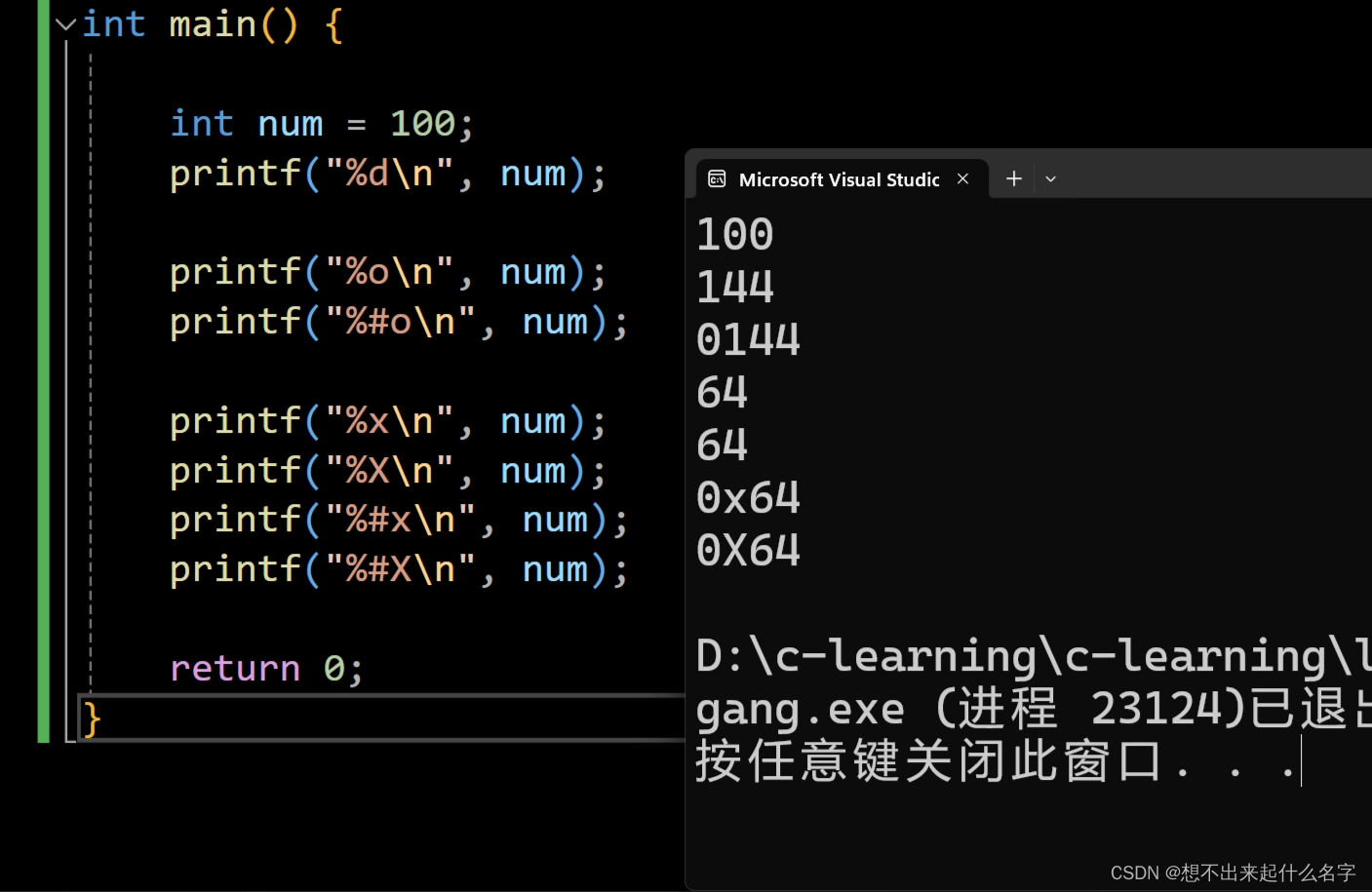
scanf:格式化输入数据在屏幕上
int scanf(
const char *format [,
argument]... );

vs认为scanf()不安全,需要检测返回值,它提供了一种更安全的scanf_s()来操作字符串
或者可以在文件开头宏定义一个他要求的#define _CRT_SECURE_NO_WARNINGS
来避免报错,相当于带了头盔,更安全了
具体的用法需要自己去摸索,讲不出来什么
运算符:操作控制数据
算数运算符: + - * / %
+ - * 比较简单,直接略过
看下除法
除号两端都是整数,执行的是整数除法,得到的结果是整数
如果想得到小数,两个运算数中至少有一个是浮点数
看下取模%,即两个整数相除的余数。只能用于整数,不能用于浮点数
负数求模的规则是:结果的正负号只有第一个运算数的正负号决定
补充:数的进制
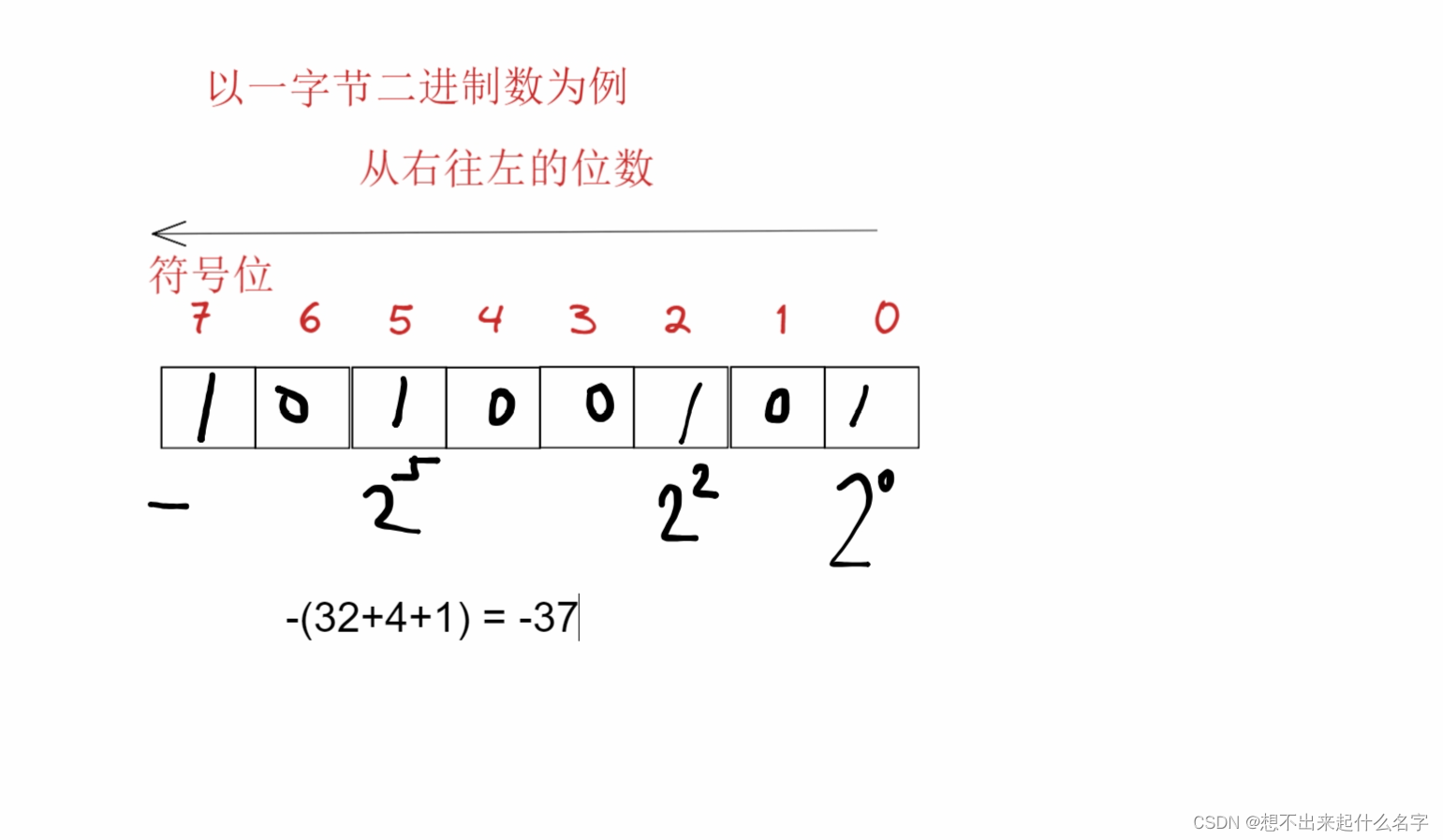
把每一个数位理解成权重
二进制->八进制,从二进制序列右边低位开始向左每三个二进制位组成一个八进制位数字,例如:
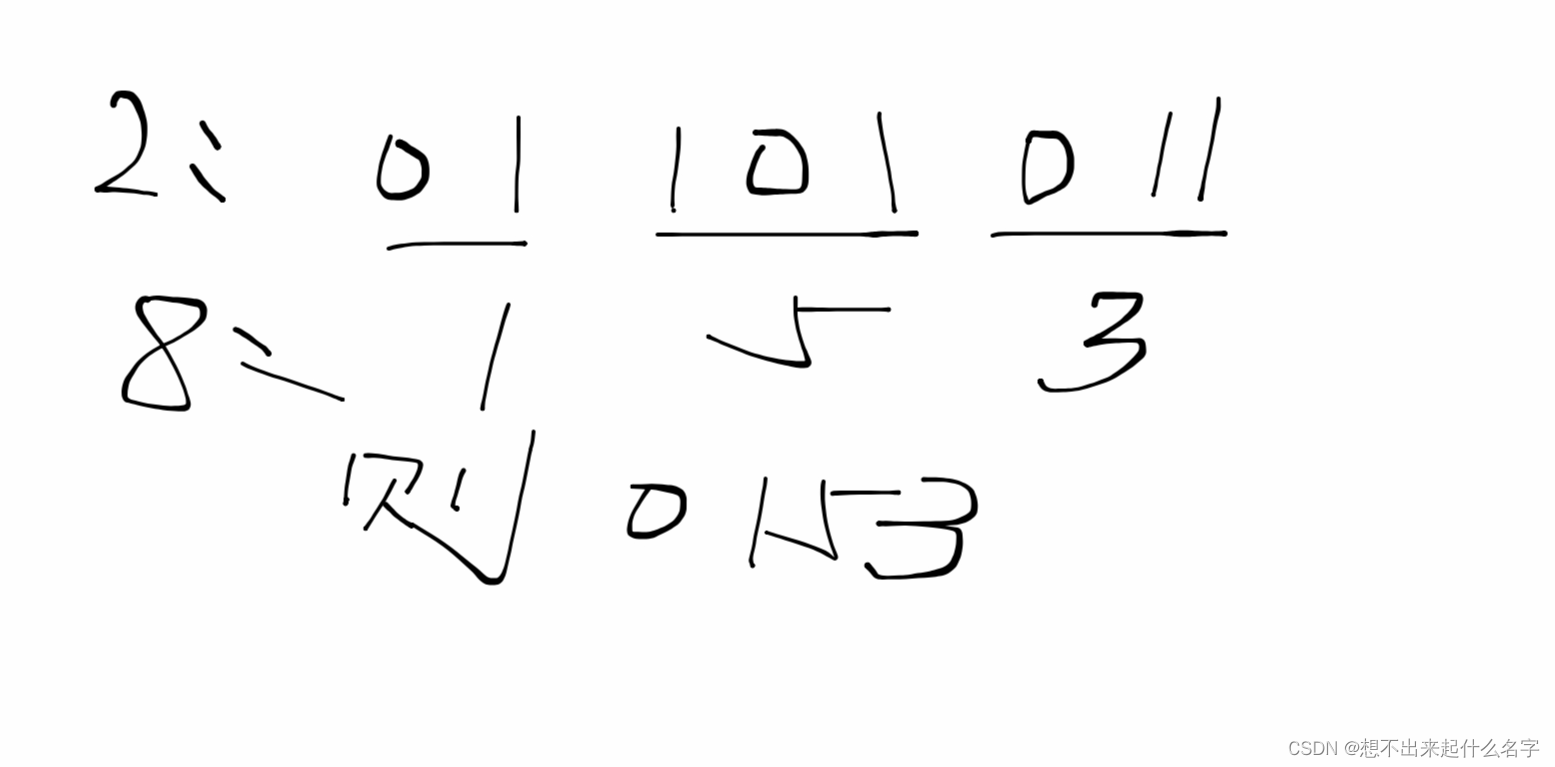
同理,二进制->十六进制,从二进制序列右边低位开始向左每三个二进制位组成一个八进制位数字,例如:
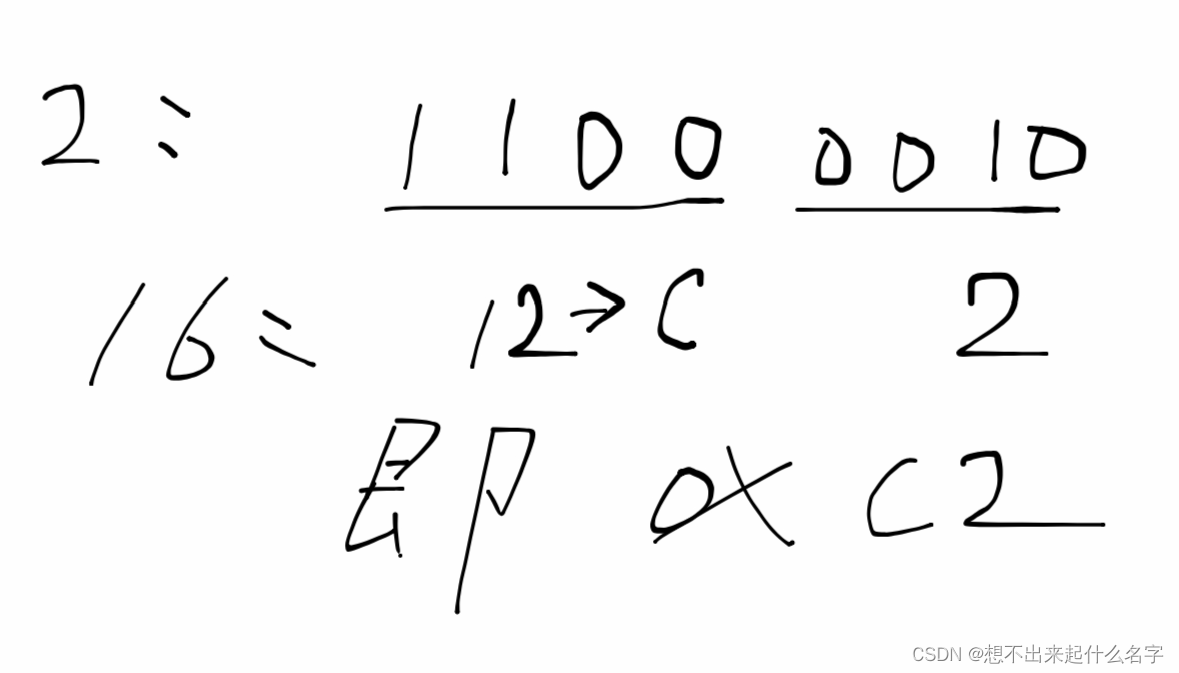
原码:按+-形式转化成的二进制数
反码:原码符号位不变,其他位按位取反
补码:反码+1
补码->原码:补码取反+1 理由:二进制数先-1后取反与先去反后+1结果一样
注:整数的三种码完全一样

赋值运算符=
这个不是等号,是将右值丢给左边已知变量
复合赋值符
对于自增自减的操作需要用到
+= -= *= /= %=
>>= <<= ^= |= ^=
相等运算符 ==
==才是C语言中的相等运算符,与“=”一定要区分开
!=不等运算符
>= 大于等于 <=小于等于
以上常用于循环中的条件判断
自增++自减--
分为前置和后置
前置:先加(减),后使用
后置:先使用,后加(减)
int a = 10;
int b = a++;
printf("a=%d b=%d\n",a,b);// 11 10位操作符
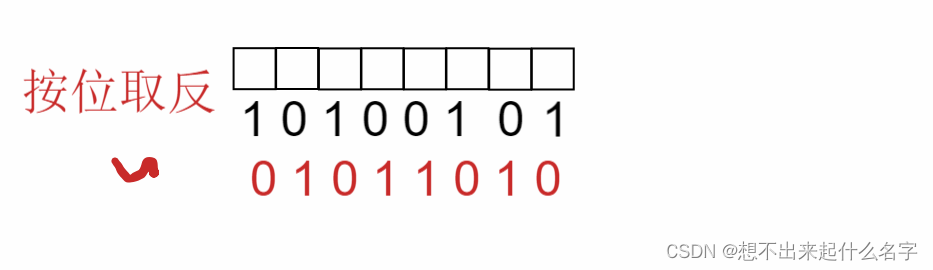
~按位取反:正常每一位按位取反,0变1,1变0
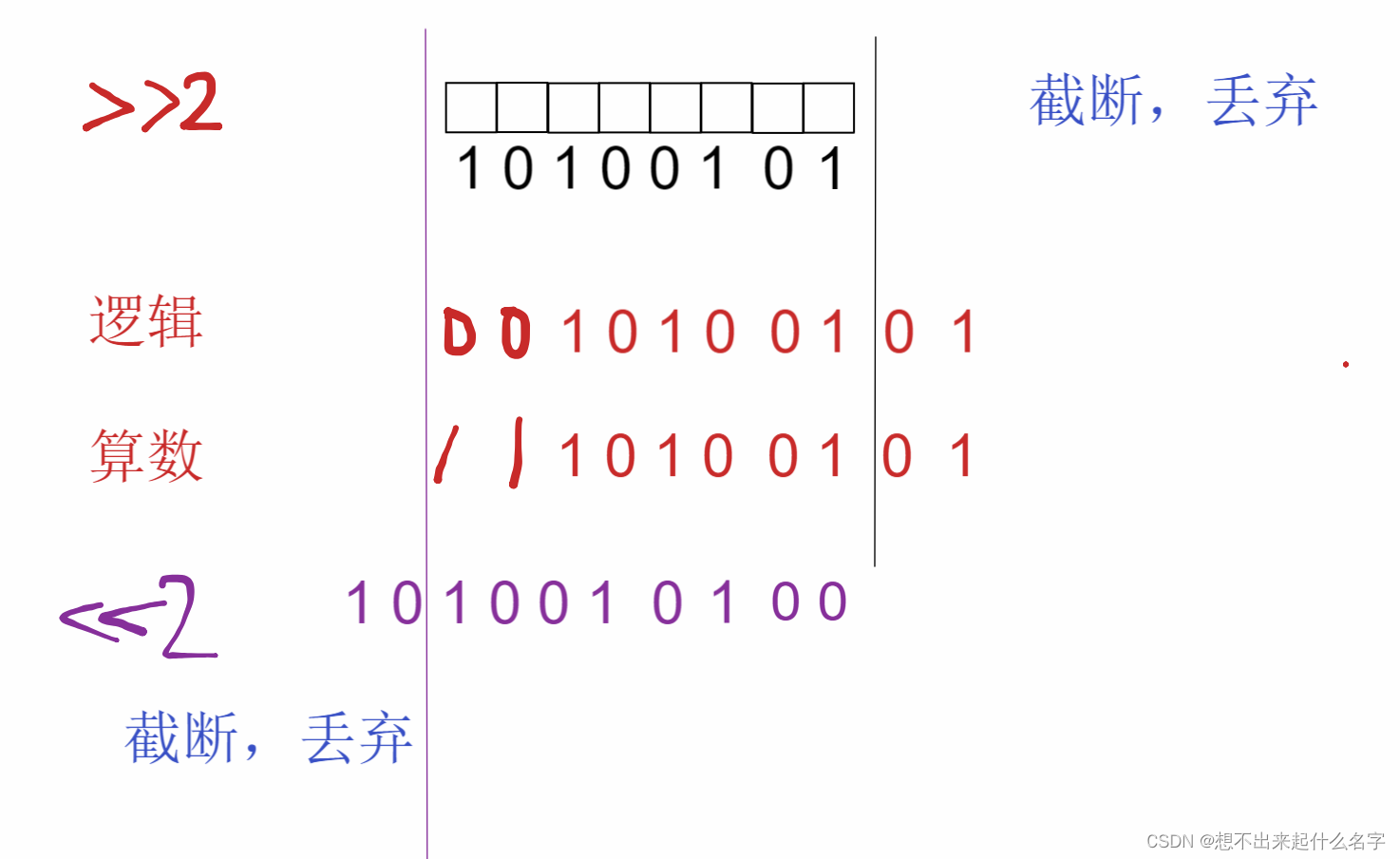
>>按位右移
逻辑右移:不考虑符号位
将运算对象的值每一位向右移动指定位数,左侧用0补齐
算术右移:考虑符号位
将运算对象的值每一位向右移动指定位数,左侧用符号位补齐
<<按位左移
将运算对象的值每一位向左移动指定位数,左侧用0补齐
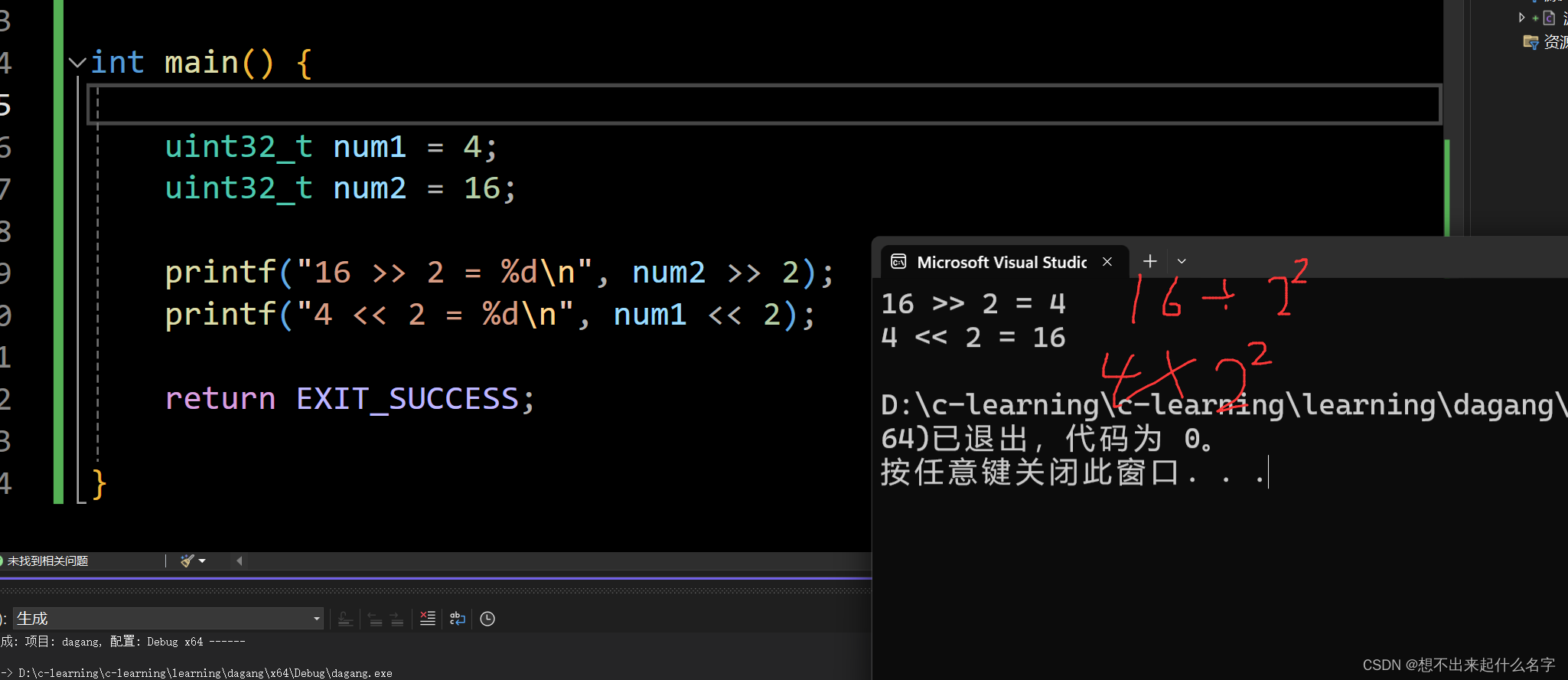
对于无符号整型
右移n位相当于除以2的n次幂
左移n位相当于乘以2的n次幂
&按位与:同时为1才为1,同时为true才为true
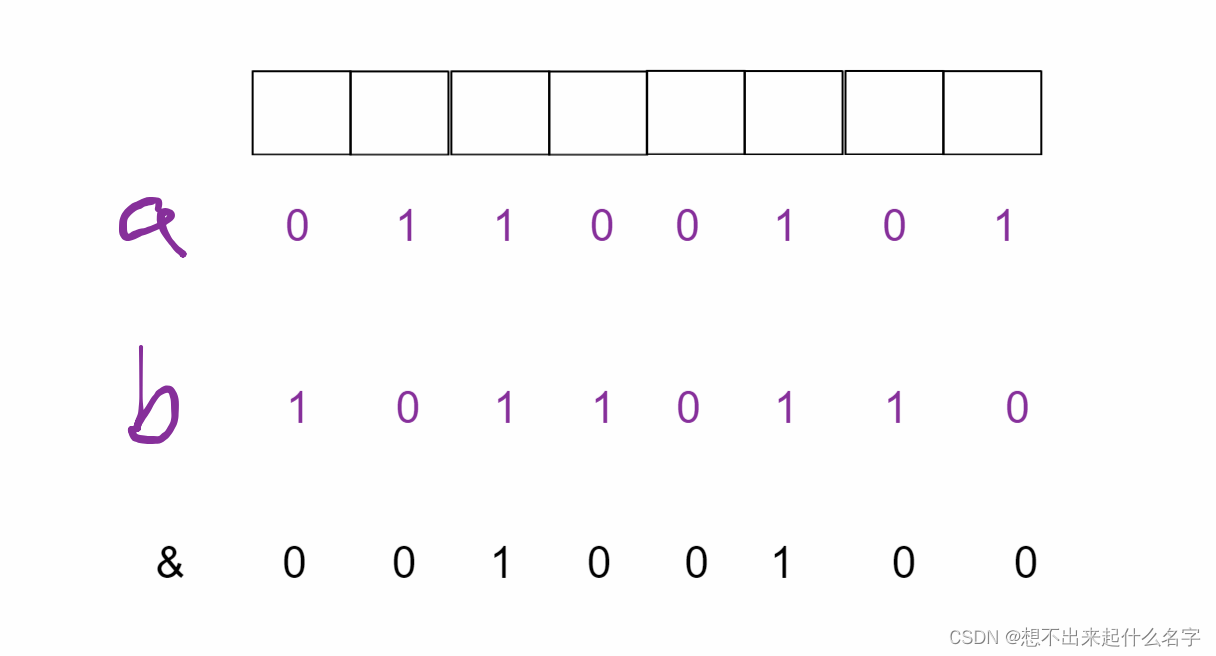
作用:
将某数特定位置数清零
检查某数特定位置是否为1
|按位或:有1就为1,二者有一个为true就为1
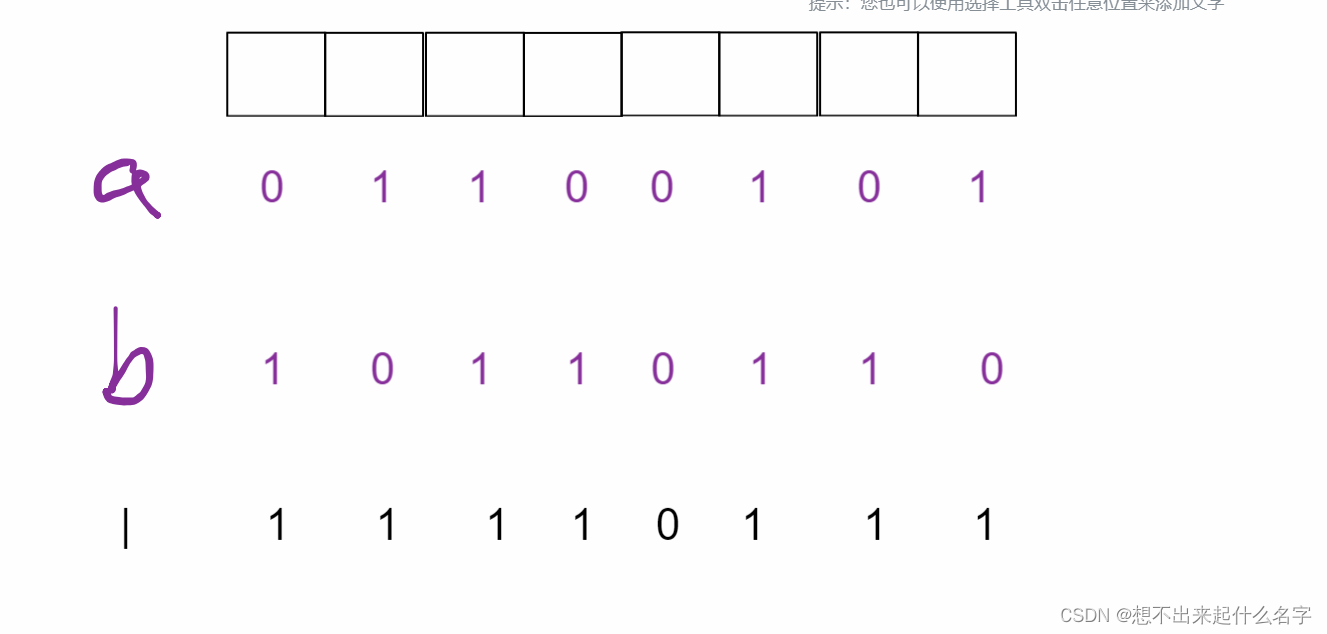
作用:
设置特定位 //让特定位置开关打开
^按位异或:0和1的组合才为1
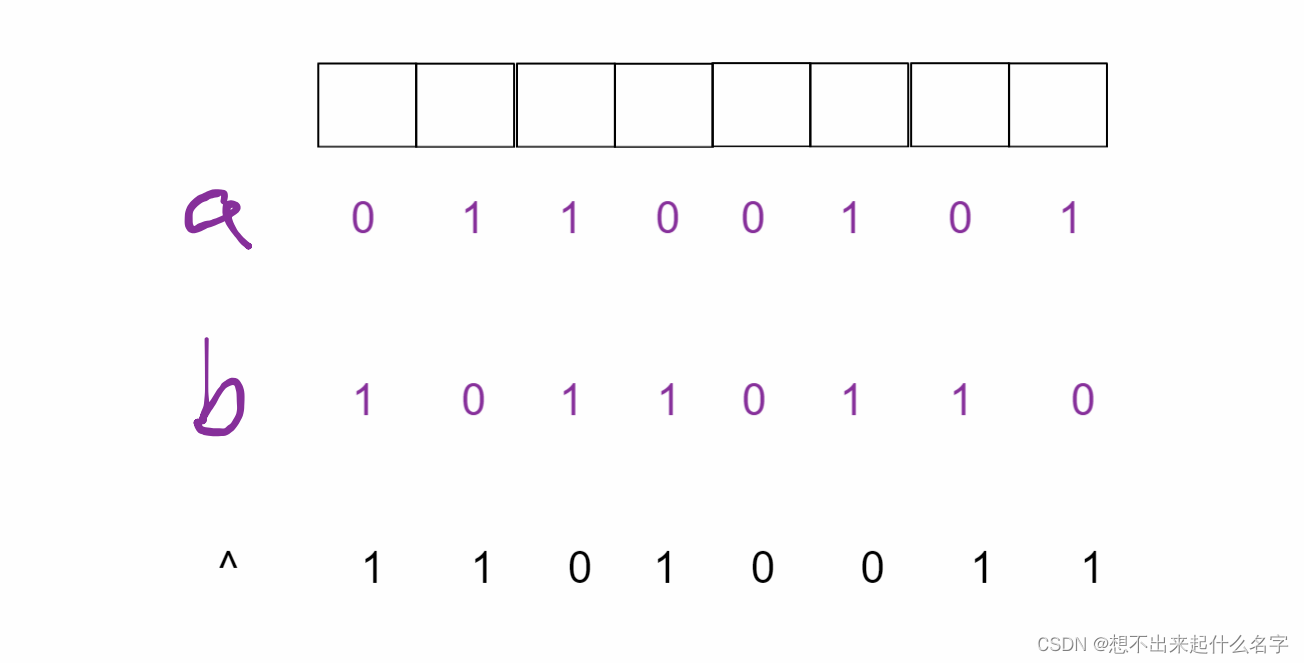
作用:
翻转特定位 //关闭开的位,打开关的位
案例总结:用掩码控制灯位、不创建新的变量交换两个变量的值
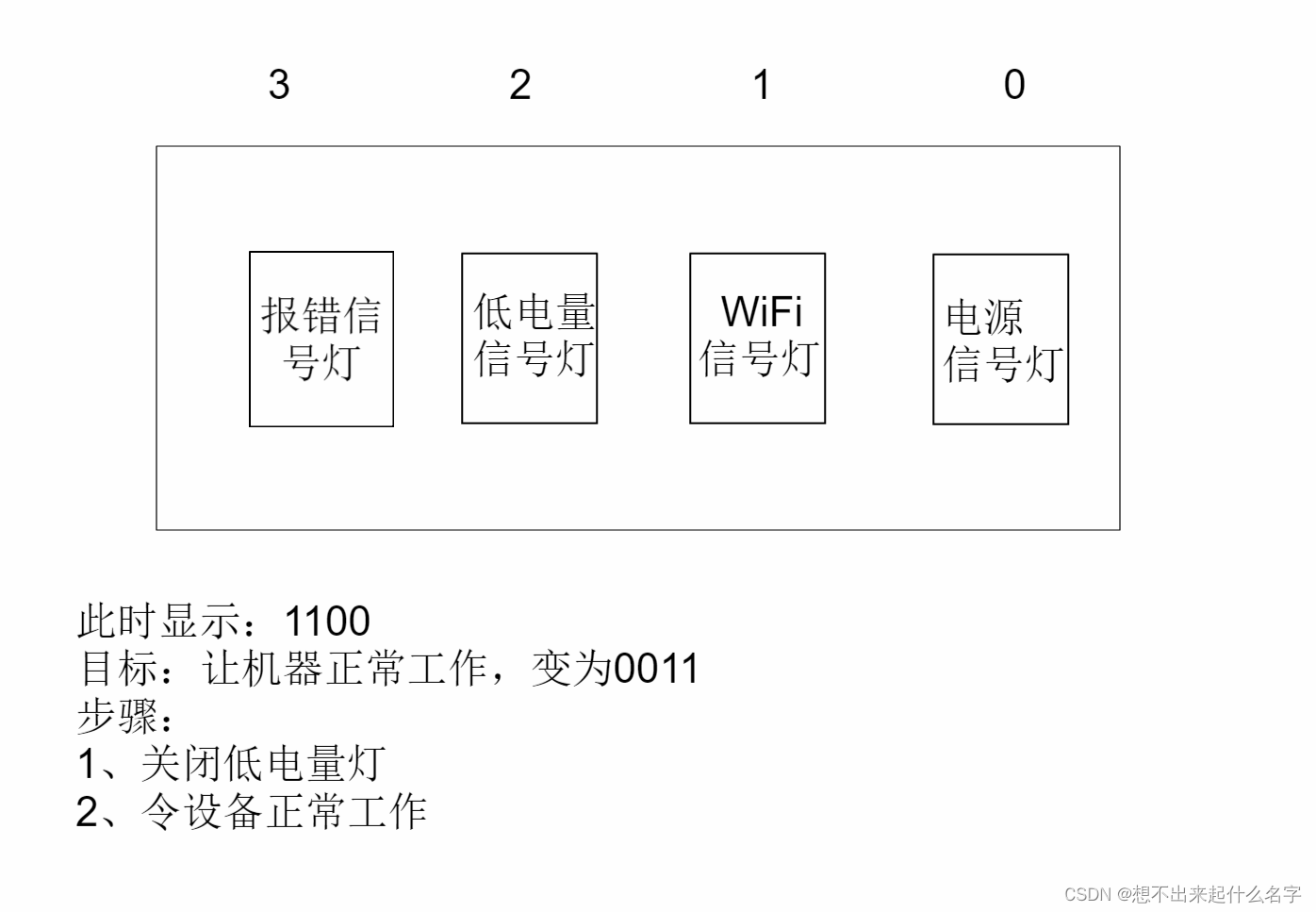
void print_bin(uint8_t num);
int main() {
uint8_t starting = 0b00001100;
printf("初始状态:0b");
print_bin(starting);
printf("\n");
printf("关闭低电量灯:0b");
uint8_t closing_low = starting & 0b11111000;
print_bin(closing_low);
printf("\n");
printf("正常工作:0b");
uint8_t final = closing_low ^ 0b00001011;
print_bin(final);
printf("\n");
return EXIT_SUCCESS;
}
void print_bin(uint8_t num) {
for(int i = 7; i >= 0 ; i--)
{
printf("%d", (num >> i) & 1);
}
}//不创建第三个变量交换两个变量值
int main() {
int a = 3;
int b = 6;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("a = %d\nb = %d", a, b);
return 0;
}条件表达式:(? :)
xxxx ? xxxx : xxxx
a b c
a为真,执行b
a为假,执行c
逻辑运算符
&& 且
||或
短路运算的原理:当有多个表达式时,左边的表达式值可以确定结果时,就不再继续运算右边的表达式的值
表达式1 && 表达式2 //若表达式1为假,则没有必要计算表达式2了,整个体系都为假
表达式1 || 表达式2 //若表达式1为真,则没有必要计算表达式2了,整个体系都为真
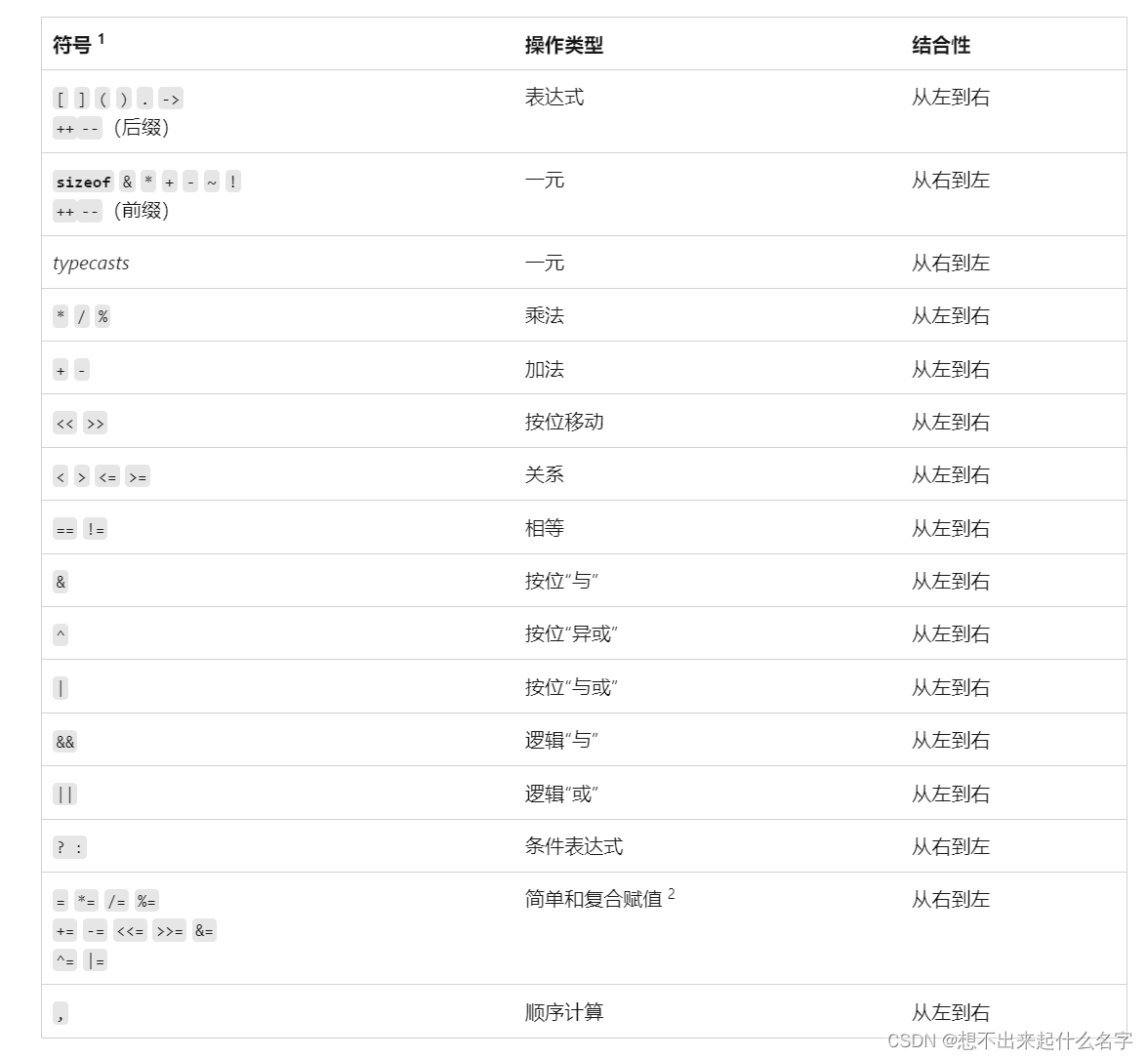
操作符优先级
第3章 分支与循环:决策与控制
C语言顺序结构、分支结构、循环结构这三种结构
朴素点理解:
顺序:每天早上起床后,会按照一定的顺序进行日常活动。起床洗漱,穿衣服,吃饭,赶早八,一条路径走到头。
选择:洗漱完,吃啥?面包?包子?这时候路径就会有多种选择了。
循环:吃完饭后,上早八,苦逼大学生日复一日地循环着。
分支
if-else语句
if(expression)
statement;
if(expression)
statement;
else
statement;
if(expression)
statement;
else if(expression)
statement;
else if
//....
else
statement;
括号内表达式如果为真,则执行statement,若为假,则按顺序往下执行
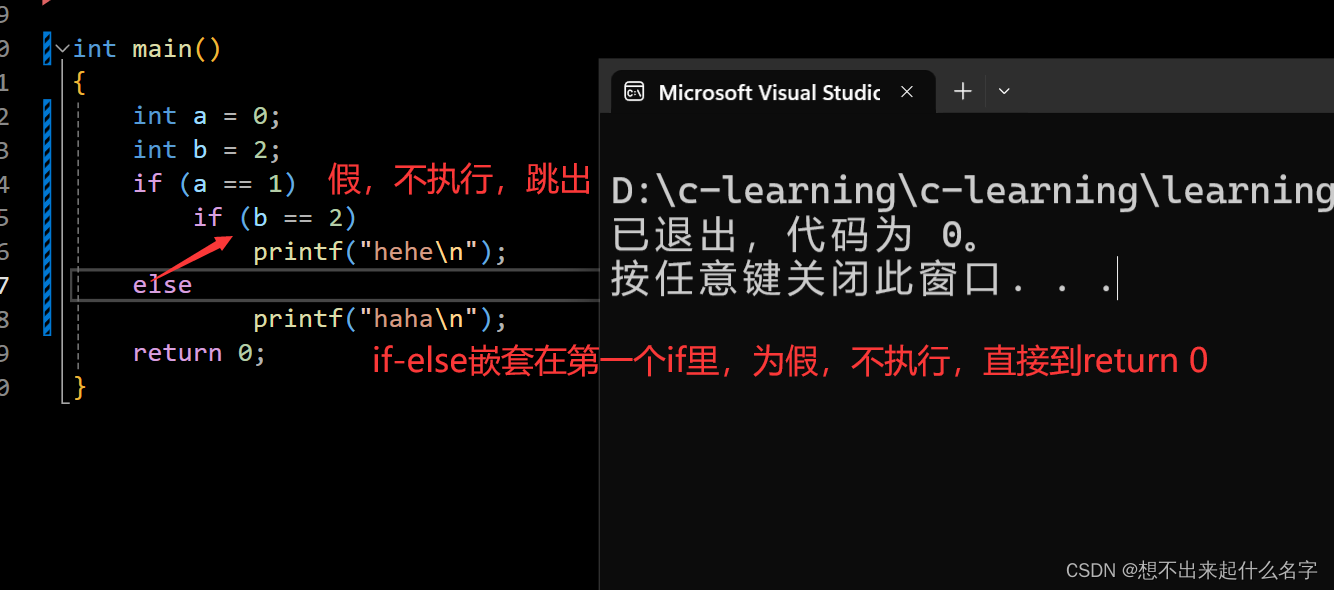
悬空else问题
如果有多个if和else,else总会和最近的if相匹配
int main()
{
int a = 0;
int b = 2;
if(a == 1)
if(b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0;
}
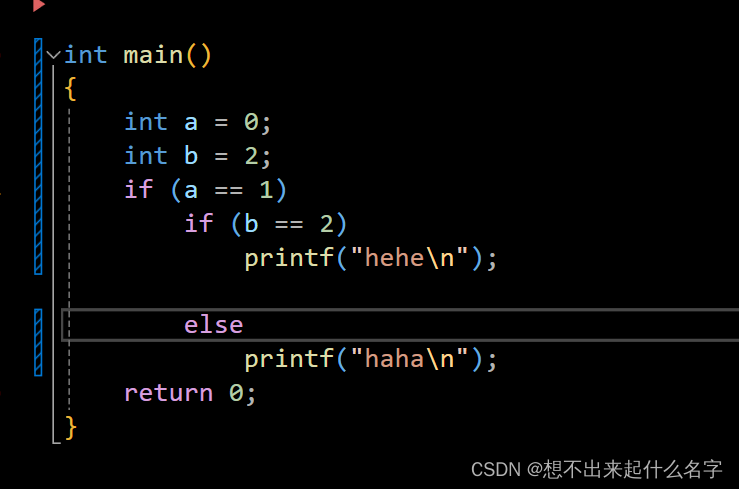
为什么啥都不输出?这个是排版问题,微软会自动匹配组合好,else和第二个if匹配,第一个if里嵌套了一个if-else语句,第一个if为假,直接跳到return 0
所以大括号{ }很重要!!!!!!
防御性编程——条件判断中与常量做比较,将常量放在左侧
//...
if(3 == x){
//......
}
//....为什么这样写?避免将“==”写成“=”引起难以调试出的bug,大家多写写就懂了
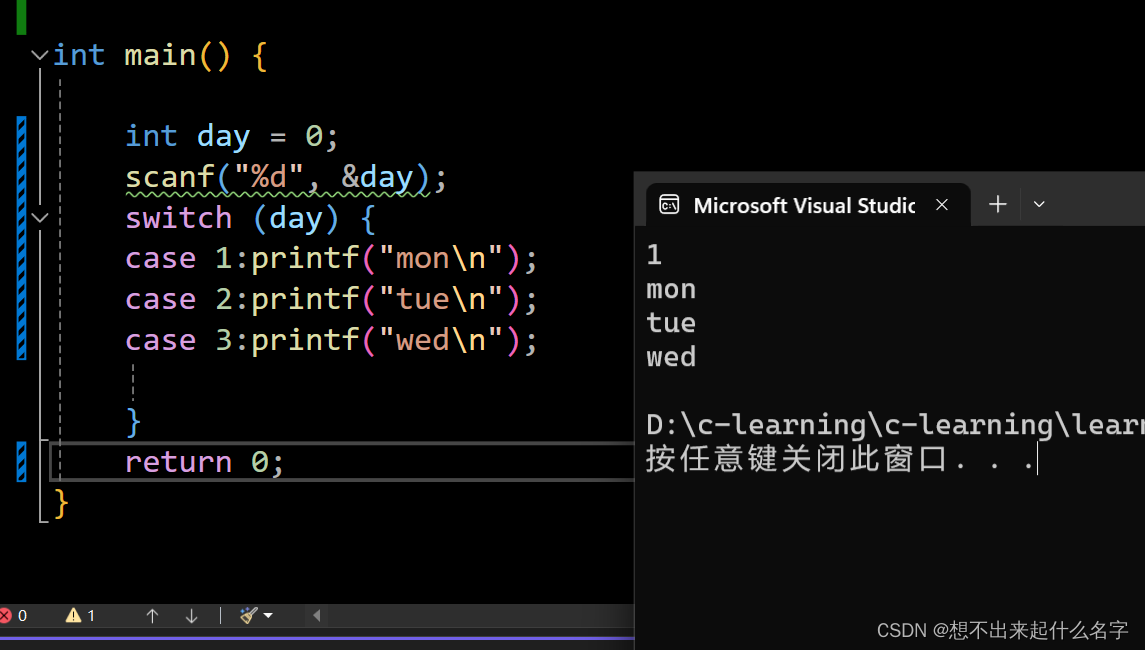
switch-case语句
switch ( expression )
{
// declarations
// . . .
case constant_expression:
// statements executed if the expression equals the
// value of this constant_expression
break;
default:
// statements executed if expression does not equal
// any case constant_expression
}这里的default可以在switch的“{}”内任意位置,只不过习惯放到最后
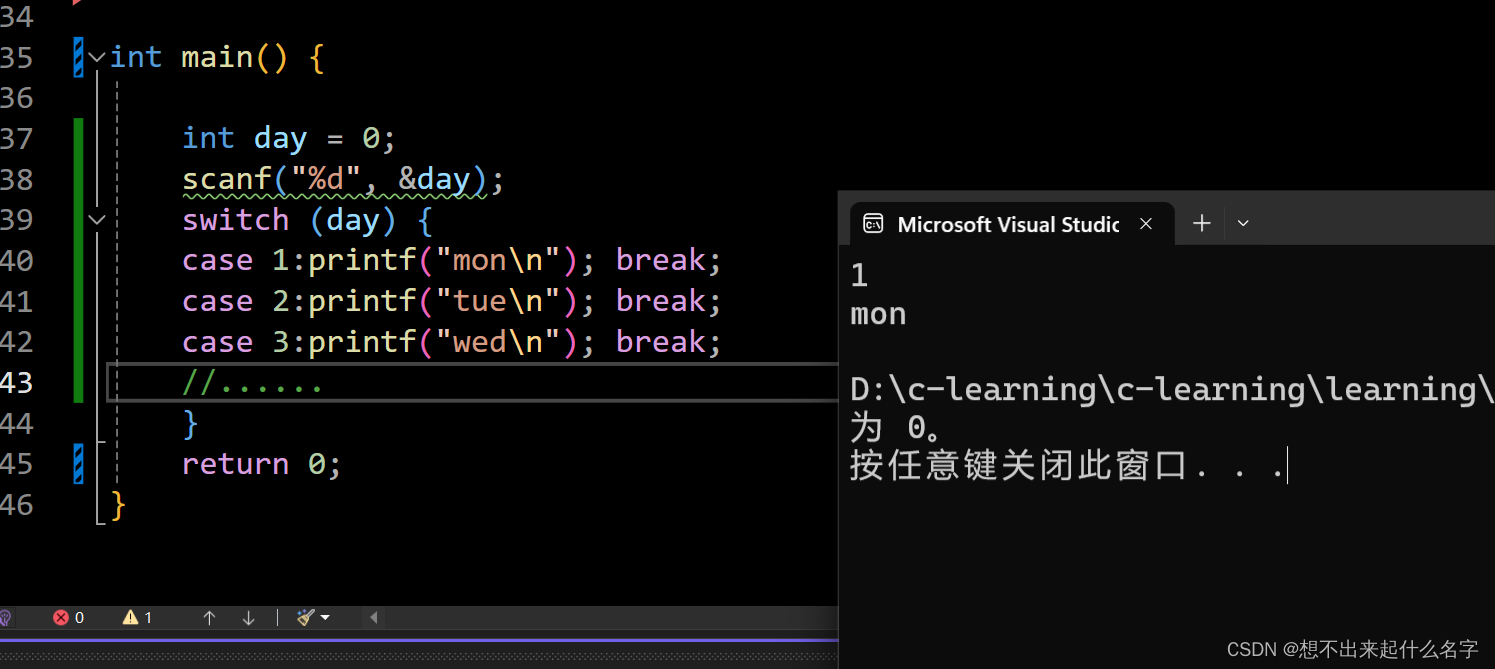
使用switch-case语句时一个case结束后不要忘了break!!!!!
如果没有break语句,将会逐一执行!!!!!!
修改后:
循环
while循环与do-while循环
while(expression)statement;如果expression为真则重复执行statement,否则不执行
比较简单没有什么需要注意的
do
{
statement;
}
while(expression);
先执行do里的语句,执行完之后判断expression是否为真,如果为真,则继续循环,否则停止跳出循环
值得注意的是,while()循环是先判断条件后执行,而do-while循环则是先执行后判断,至少会执行一次语句
for循环
for(初始的循环变量 ;循环变量满足的条件 ;调整循环变量 )
{
statement;
}
先明确初始的循环变量,之后判断条件,条件为真,执行statement,之后进行循环变量调整再判断条件,往复执行,指导不满足循环条件跳出
continue和break
continue即继续,跳过continue之后的语句,重新进行循环
break即打破,直接跳出整个循环
int i = 1;
while(i<=10)
{
if(i == 5)
break;//当i等于5后,就执⾏break,循环就终⽌了
printf("%d ", i);
i = i+1;
}
//1 2 3 4
int i = 1;
while(i<=10)
{
if(i == 5)
continue;//当i等于5后,跳过之后的语句,继续执行循环,此时跳过了i = i + 1,i一直等于5,陷入死循环
printf("%d ", i);
i = i+1;
}
int i = 1;
for(i=1; i<=10; i++)
{
if(i == 5)
continue;//这⾥continue跳过了后边的打印,来到了i++的调整部分
printf("%d ", i);
}
//1 2 3 4 6 7 8 9 10循环相关练习
//任意输入一个正整数N,统计1~N之间奇数的个数和偶数的个数,并输出。
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d",&n);
int o = 0;
int j = 0;//o为偶数,j为奇数
for(int i = 1; i <= n; i++)
{
if(i % 2 == 0) o++;
else j++;
}
printf("%d %d",j,o);
return 0;
}
//所有三位整数中,有多少个质数。
#include <stdio.h>
#include <math.h>
int main()
{
int i = 1;
int num = 0;
for(i = 101; i <= 999; i+=2)
{
int temp = 1;
for(int j = 2; j <= sqrt(i); j++)
{
if(i % j == 0)
{
temp = 0;
break;
}
}
if(temp == 1) num++;
}
printf("%d",num);
return 0;
}
//打印99乘法口诀表
#include <stdio.h>
int main() {
for(int i = 1; i <= 9; i++)
{
for(int j = 1; j <= i; j++)
{
printf("%d*%d=%2d ",j,i,i*j);
}
printf("\n");
}
return 0;
}
/*有一个数字魔法,给你一个正整数n,如果n为偶数,就将他变为n/2, 如果n为奇数,就将他变为乘3加1
不断重复这样的运算,经过有限步之后,一定可以得到1
牛牛为了验证这个魔法,决定用一个整数来计算几步能变成1*/
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d",&n);
int step = 0;
while(n != 1)
{
if(n % 2 ==0)
n /= 2;
else
n = 3*n + 1;
step++;
}
printf("%d",step);
return 0;
}
//一行,一个整数,表示1~2019中共有多少个数包含数字9。
#include <stdio.h>
int main()
{
int num = 0;
int tmp = 0;
for(int i = 1; i <= 2019; i++)
{
int m = i;
while(m)
{
if(m % 10 == 9)
{
num++;
break;
}
else
m /= 10;
}
}
printf("%d",num);
return 0;
}
/*输入数据有多组,每组占一行,包括两个整数m和n(100 ≤ m ≤ n ≤ 999)
对于每个测试实例,要求输出所有在给定范围内的水仙花数,就是说,输出的水仙花数必须大于等于m,并且小于等于n,如果有多个,则要求从小到大排列在一行内输出,之间用一个空格隔开; 如果给定的范围内不存在水仙花数,则输出no; 每个测试实例的输出占一行。
*/
#include <stdio.h>
#include <stdio.h>
int main()
{
int a,b;
int tmp = 0;
while((scanf("%d %d",&a,&b)) != EOF)
{
for(int i = a; i <= b; i++)
{
if((pow(i%10,3)+pow(i/10%10,3)+pow(i/100,3)) == i)
{
tmp = 1;
printf("%d ",i);
}
}
if(tmp == 0)
{
printf("no\n");
}
else
{
printf("\n");
}
}
return 0;
}
/*变种水仙花数 - Lily Number:把任意的数字,从中间拆分成两个数字,比如1461 可以拆分成(1和461),(14和61),(146和1),如果所有拆分后的乘积之和等于自身,则是一个Lily Number。
例如:
655 = 6 * 55 + 65 * 5
1461 = 1*461 + 14*61 + 146*1
求出 5位数中的所有 Lily Number。*/
#include <stdio.h>
int main()
{
for(int i = 10000; i <= 99999; i++)
{
if((i/10000)*(i%10000) + (i/1000)*(i%1000) + (i/100)*(i%100) +(i/10)*(i%10) == i)
{
printf("%d ",i);
}
}
return 0;
}
/*公务员面试现场打分。有7位考官,从键盘输入若干组成绩,每组7个分数(百分制),去掉一个最高分和一个最低分,输出每组的平均成绩。
(注:本题有多组输入)
输入描述:
每一行,输入7个整数(0~100),代表7个成绩,用空格分隔。
输出描述:
每一行,输出去掉最高分和最低分的平均成绩,小数点后保留2位,每行输出后换行。*/
//注意,这题有点坑,这题多组输入,很多朋友可能会用for循环遍历一个数组,这样只有一组数据
#include <stdio.h>
int main() {
int score = 0;
int max = 0;
int min = 100;
double sum = 0;
int cnt = 0; //用于判断是否输入了7个数
while ((scanf("%d ", &score)) != EOF) {
if (score > max) max = score;
if (score < min) min = score;
sum += score;
cnt++;
if (cnt == 7) {
printf("%.2lf\n", (sum - max - min) / 5.0);//别忘了换行符,一组一行
cnt = 0;
max = 0;
min = 100;
sum = 0;
//一组数据处理完成,数据初始化,等待多组数据的输入和处理
}
}
return 0;
}
//输出1到n之间的回文数
#include <stdio.h>
int main() {
int n;
scanf("%d",&n);
for (int i = 1; i < n; i++) {
int temp = i;
int sum = 0;
while(temp){
sum = sum * 10 + temp % 10;
temp /= 10;
}
if(sum == i) printf("%d\n",i);
}
return 0;
}函数
指针
初阶指针
地址与取地址
计算机中,地址是内存的编号,是内存中储存数据的唯一标识
我们为什么需要地址呢?为了方便快速地查找数据并操作数据
举个简单的例子,你去朋友的宿舍,如果没有房间号(地址编号),你是不是要一层楼一层楼挨个门去敲(逐一访问)直到找到你的朋友,这样很容易被揍的,如果给你个确切的房间号(地址编号)你就会很快到达。
在计算机中也是如此,为了快速找到目标文件或者目标数据,如果没有地址,想象一下会有多么困难。
取地址&这个操作符我们在scanf()函数中使用过
我们现在用段代码来理解
#include <stdio.h>
int main()
{
int place[5] = { 101, 102, 103, 104, 105 };
//我们现在要找到103房间,怎么操作?
int tagert_place = place[2]; //目标103房间
printf("寻找中 %d 中。。。。\n", tagert_place);
for (int i = 0; i < 5; i++)
{
printf("住户 %d 的地址为: %p\n", place[i], &place[i]);
if (place[i] == tagert_place)
{
printf("找到目标住户 %d 的地址为: %p\n", tagert_place, &place[i]);
break;
}
else
printf("未找到!\n");
}
return 0;
}%p 是地址的占位符,而取地址&操作符就是找到目标地址
我们看下运行结果
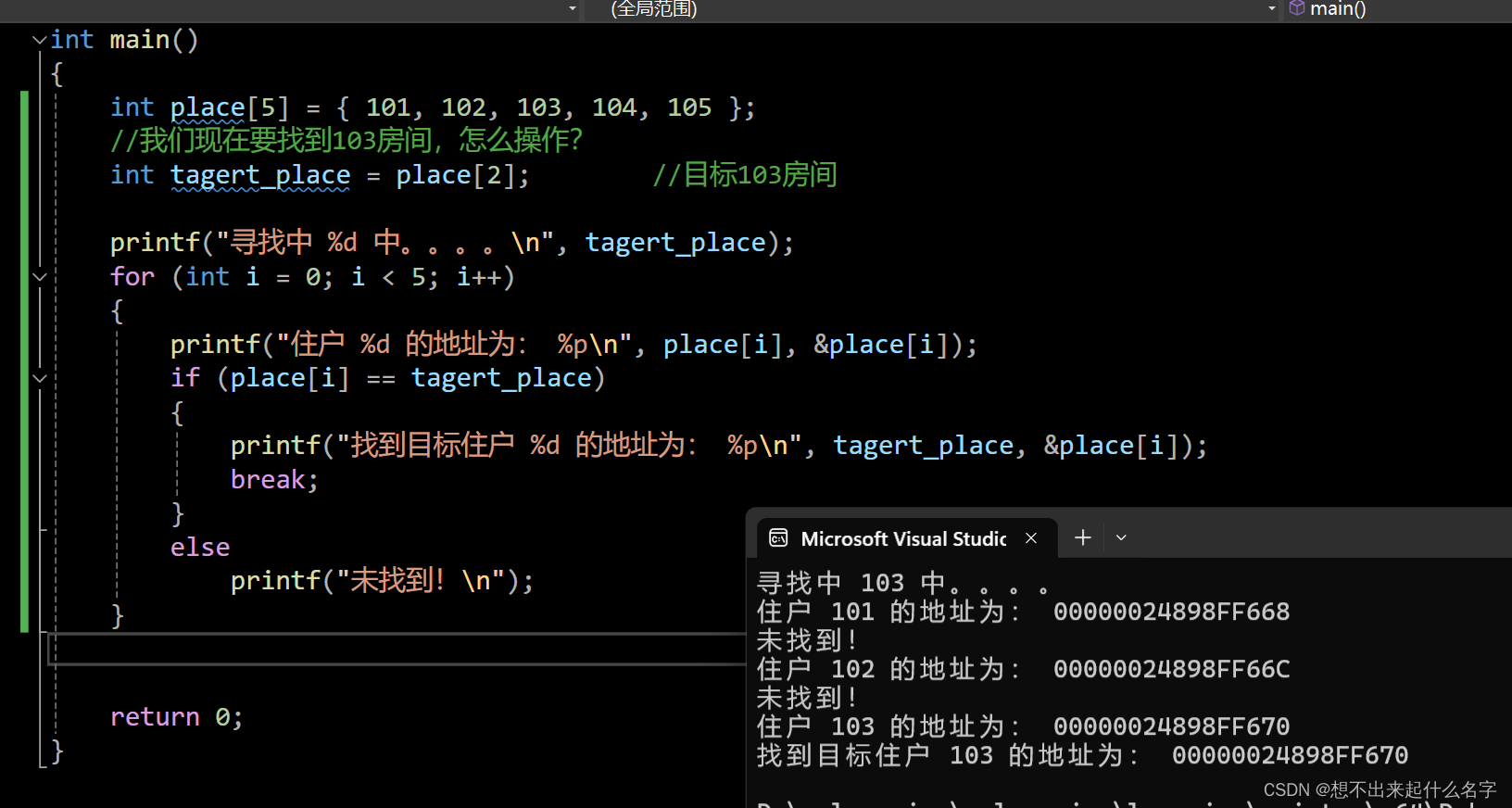
这里我们还是注意查找,为了避免被揍的风险,该如何操作?
我们就需要引入指针了
指针定义
在现实生活中我们的具体地址是不会随意泄露的,而计算机中的地址也是,这时就需要一个工具来查找具体地址了,这便是指针。
指针是一种特殊的变量,指针不存在具体的数值,指针用于储存另一个变量的地址
这就好比外卖小哥只知道你的门牌号(地址)和手机号(手机号也有隐私保密)而你的其他相关信息他是不知道的

这是指针变量的定义与初始化
注意看这两种写法的不同:*的位置不同
第一种写法是微软的风格,强调这个ptr_place_103变量是个int*(整型指针)
而第二种写法更强调ptr_place_102这个变量是个指针
二者含义相同,只是风格习惯不同
在定义多个指针变量时,我推荐大家一个变量写一行,这样可读性强

这两种写法不论哪一种,结果都是一个指针和一个变量,这种错误要刻意避免
下面看段代码
#include <stdio.h>
int main()
{
int place[5] = { 101, 102, 103, 104, 105 };
//我们现在要找到103房间,怎么操作?
int tagert_place = place[2]; //目标103房间
int* ptr_place_103 = &place[2]; //ptr_place_103 -> (指向) &place[2]
int *ptr_place_102 = &place[1]; //ptr_place_102 -> (指向) &place[1]
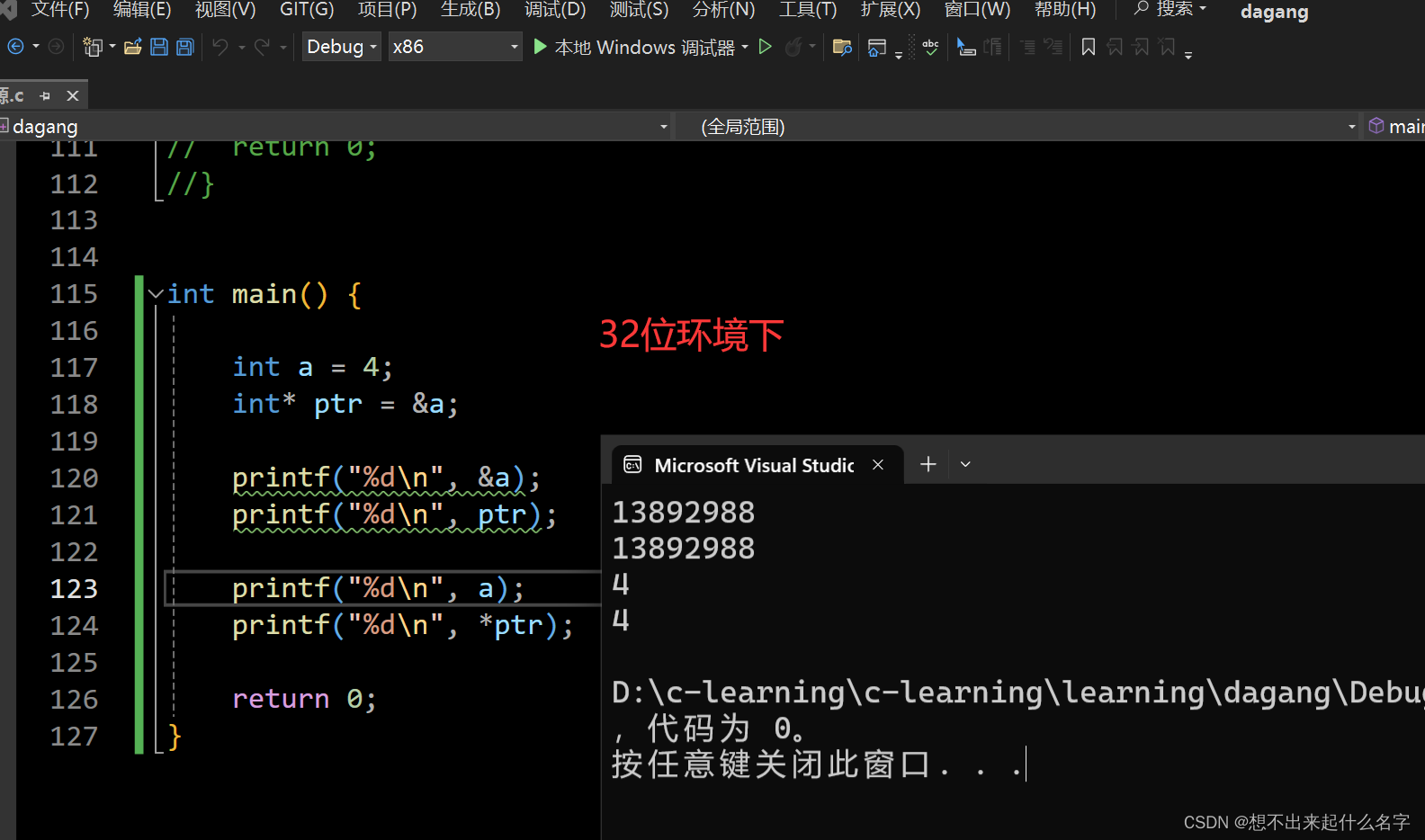
printf("&place[2]的地址是:%p\n", &place[2]);
printf("ptr_place_103指针变量保存的的地址是:%p\n", ptr_place_103);
printf("place[2] = %d\n", place[2]);
printf("外卖小哥通过*(相当于地图工具),他带着ptr_place_103这个指针变量(存储了住户的地址)去寻找。。。\n");
printf("他找到了住户门牌号%d\n", *ptr_place_103);
printf("他找到了住户门牌号%d\n", place[2]);
return 0;
}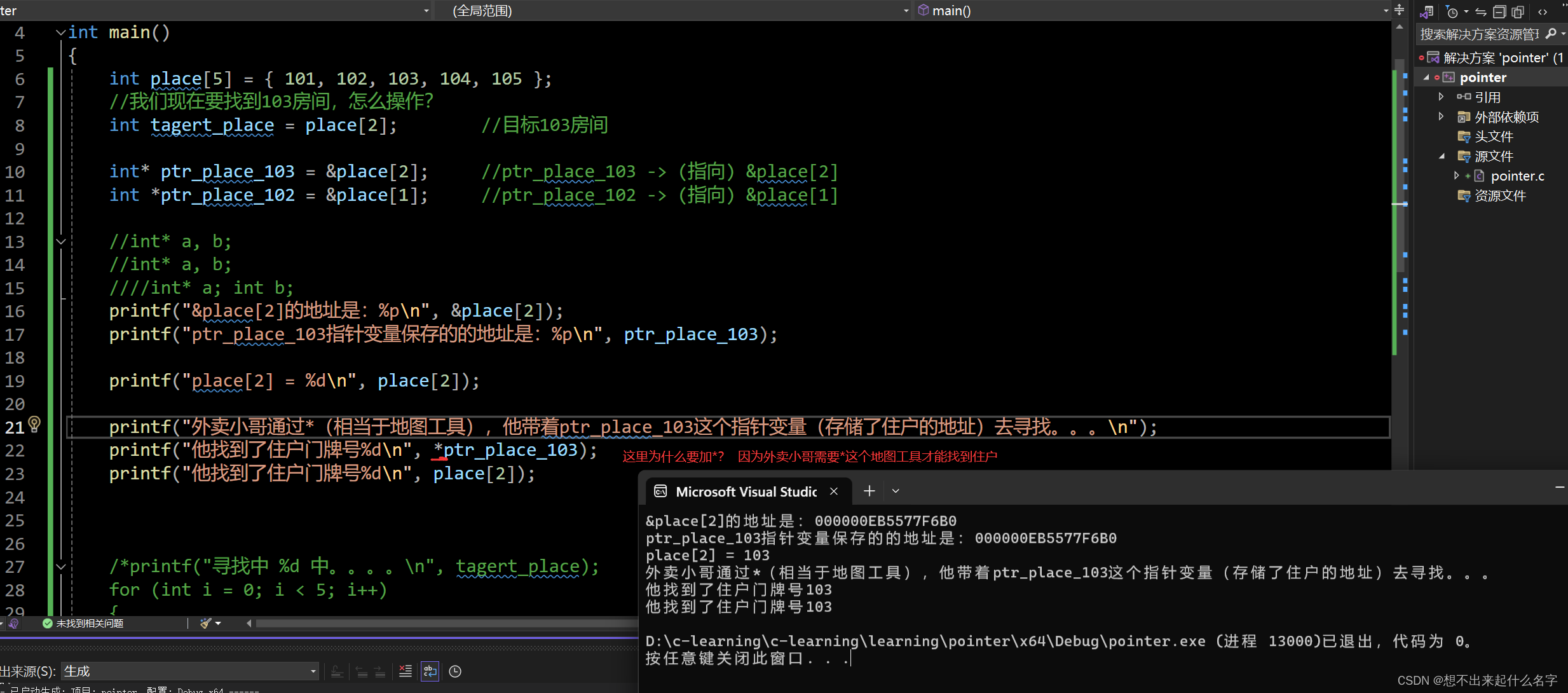
*解引用操作符就相当于地图工具,你带着他就可以准确找到目标的位置了
再来温习一下:
指针指向一个变量,储存这个变量的地址
*用于访问这个变量地址上的值,即变量的值
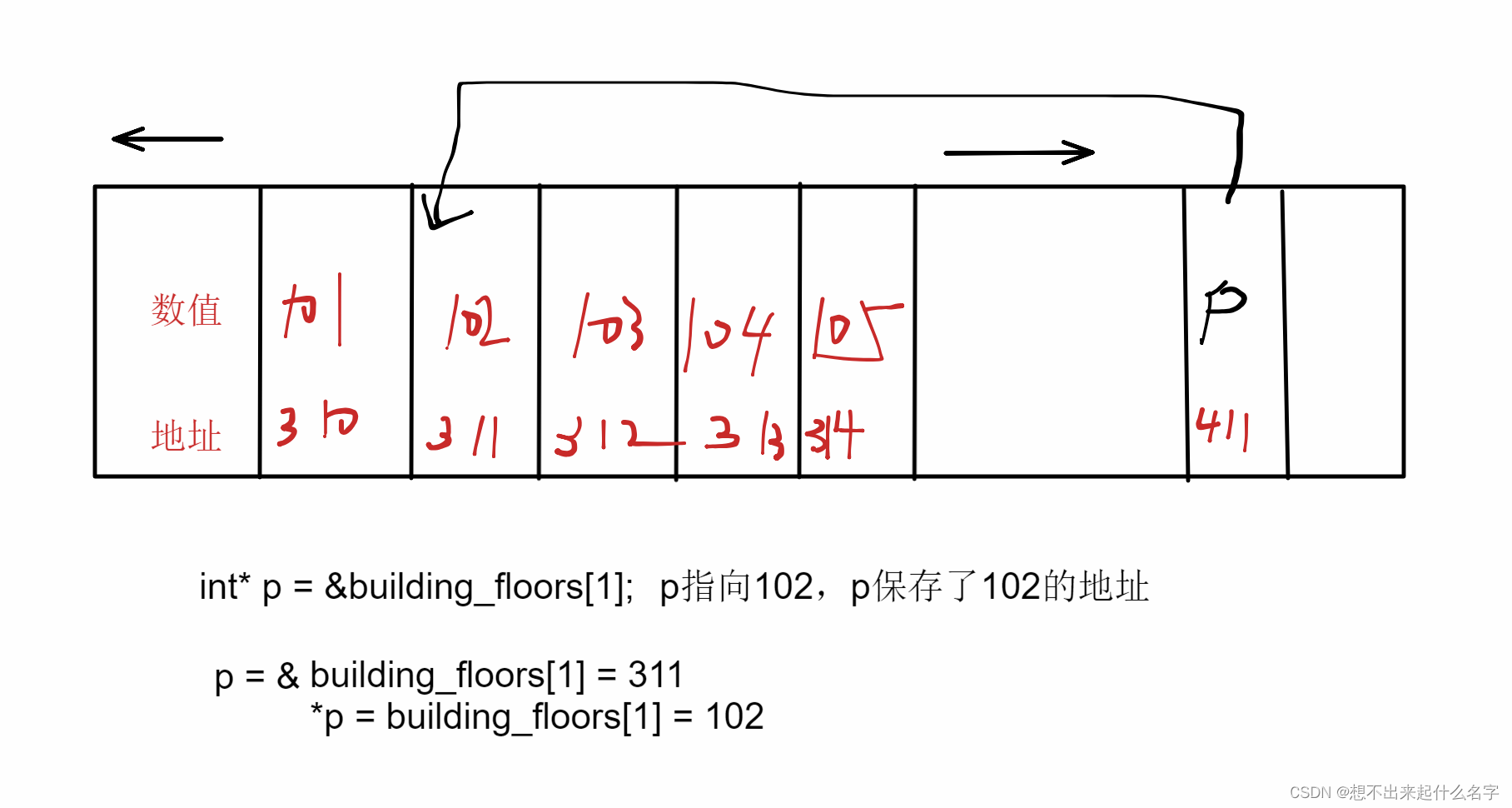
这是为什么?我们并没有明确定义(ptr + 1)这个指针变量,这时它访问的是一块未知的内存空间,相当于是野指针
讲了这么多,指针到底有什么现实意义呢?
有个专业术语叫外部服务操作,通俗点就是我们创造的快捷方式
我们电脑桌面图标基本都是快捷方式,双击快捷方式后台会自动访问文件或软件真正地址并打开文件或软件
这里我们继续介绍两个指针的概念:
野指针
野指针:指向了一个无效的内存地址或者是已经释放内存的地址
这种方式十分危险,因为野指针会访问一个不可描述的内存空间,会导致行为不可预测
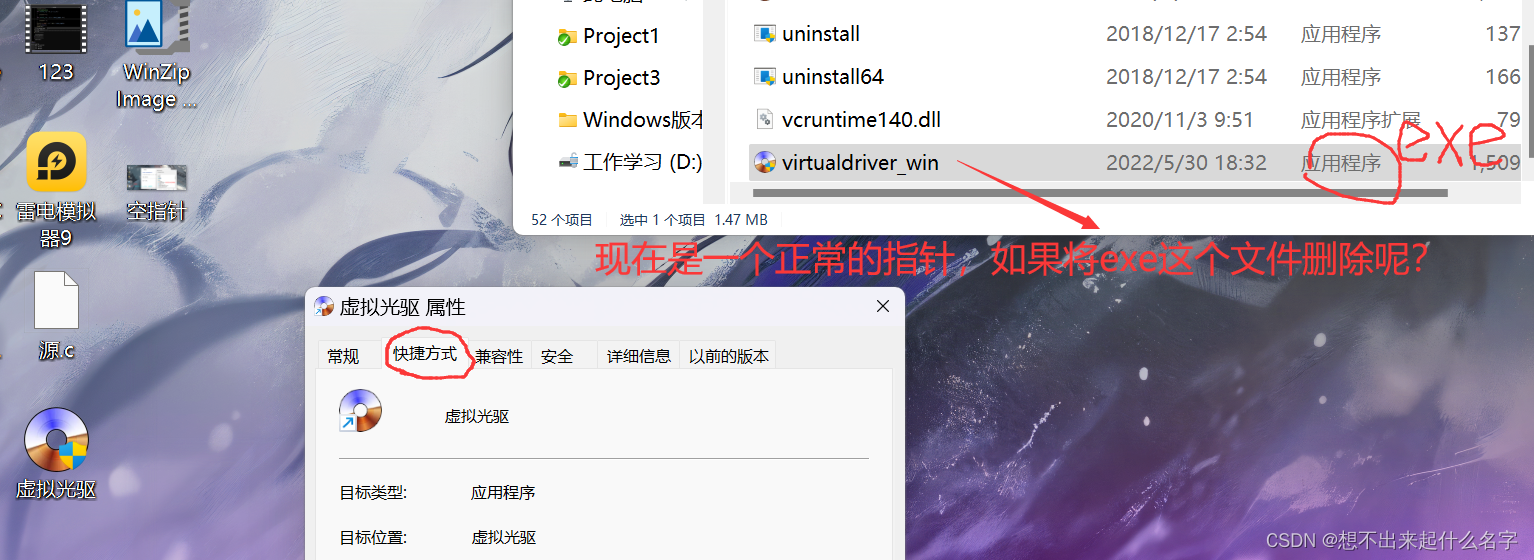
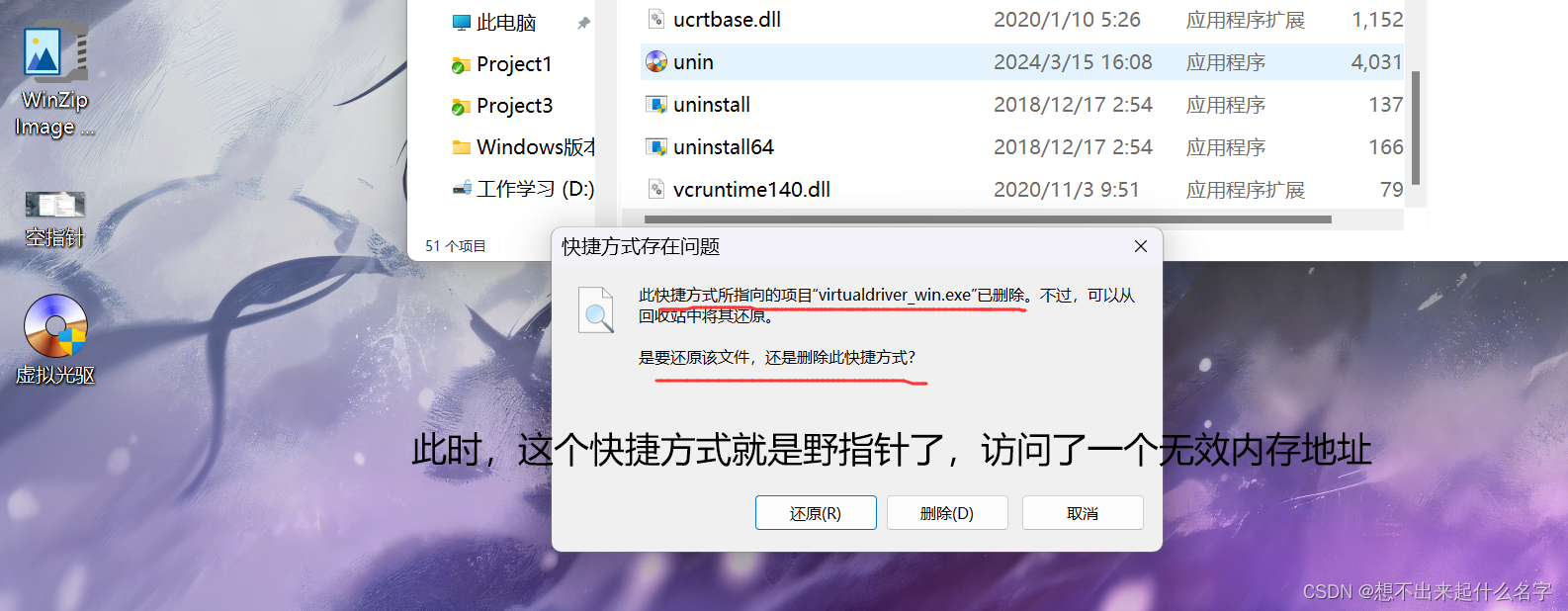
空指针
空指针:没有指向任何有效内存空间的地址
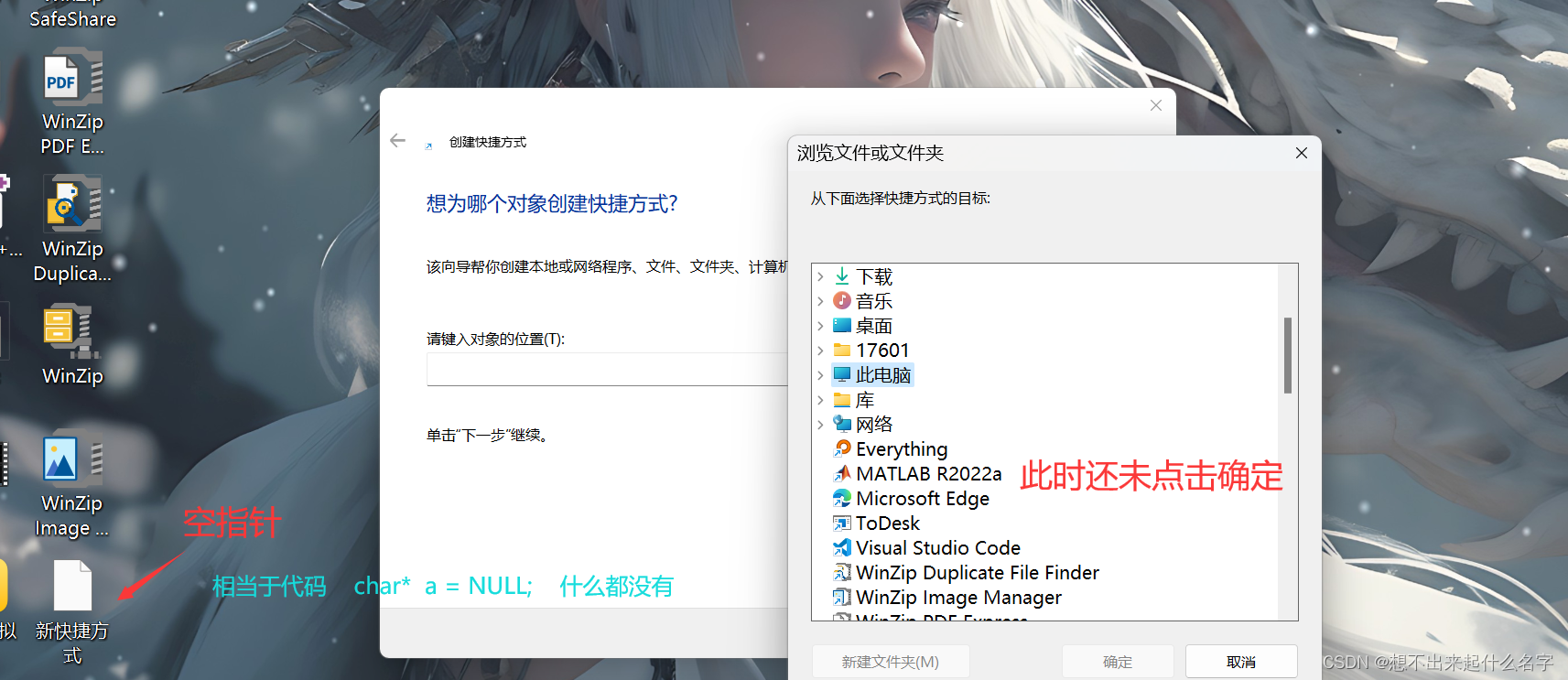
char* a = NULL;
这便是空指针的初始化
指针运算
使用指针加法和减法移动指针
int nums[] = { 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 };
int* ptr = &nums; //&nums[0] 将nums[]这个数组的第一个元素传给指针变量
//因为数组在内存中是连续的,所以只需一个首地址就可顺藤摸瓜找到剩下元素地址
//计算数组大小
size_t size = sizeof(nums) / sizeof(nums[0]);
printf("size = %d \n\n", size);
printf("原始数据:\nnums[] = {");
for (size_t i = 0; i < size; i++)
{
printf("%d ", nums[i]);
}
printf("}\n");
printf("\n");
//使用指针加法移动指针
puts("使用指针加法访问第6位元素:");
ptr += 5; //4 * 5 = 20字节
printf("nums[ptr += 5] = %d\n\n", *ptr);
//使用指针减法回退到第一个元素
puts("使用指针减法回退到第一个元素:");
ptr -= 5; //4 * 5 = 20字节
printf("回退到第一个元素:nums[ptr -= 5] = %d\n\n", *ptr);这里的代码我省略了头文件和主函数,我们看主体部分
我们定义的数组内存是连续的,每个元素之间相差4字节,这个加减法操作就相当于指针控制元素向前或者向后走几步
再看一段代码
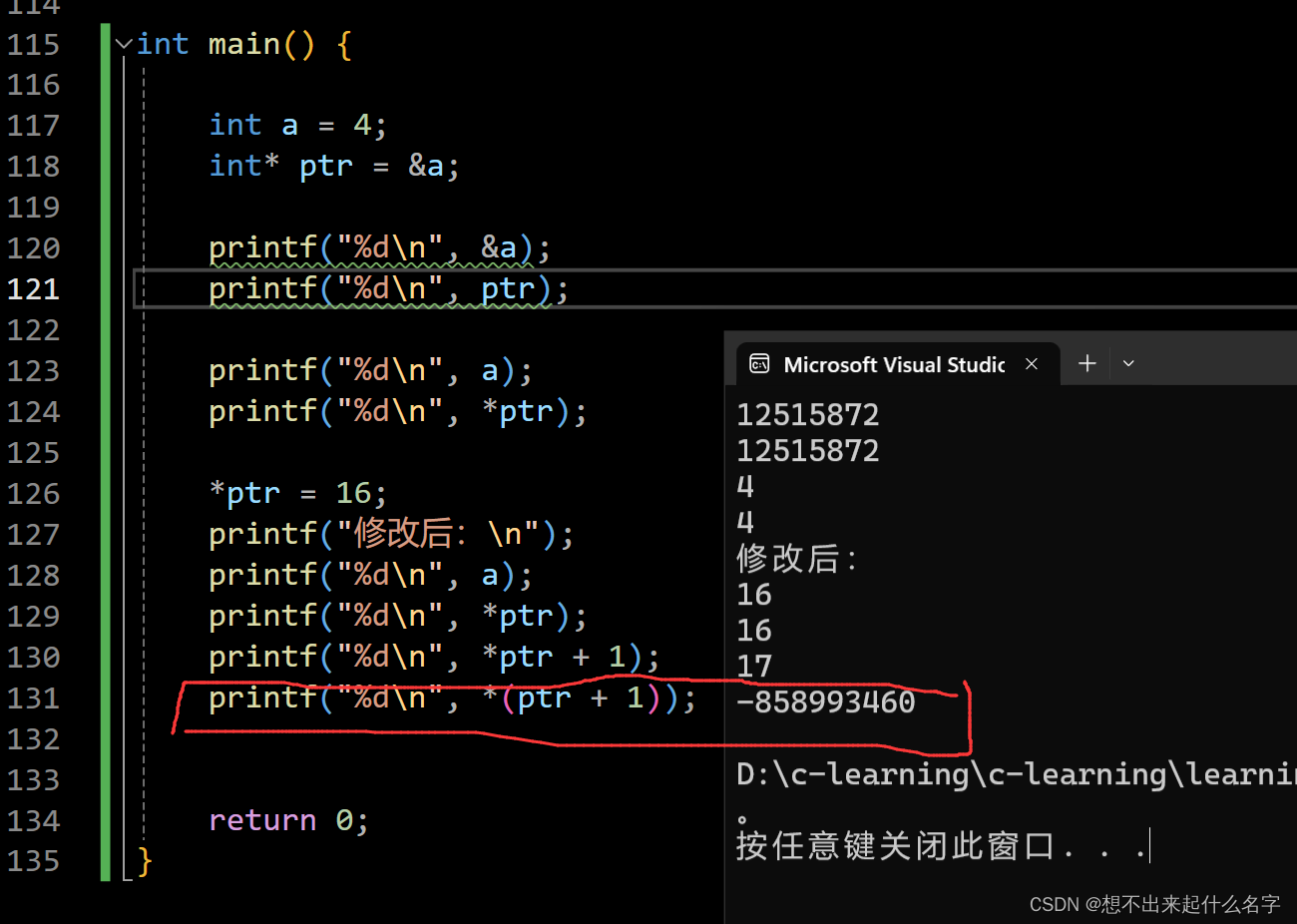
int temp = 3;
printf("*(start_ptr + temp) = %d\n", *(start_ptr + temp));
printf("*start_ptr + temp = %d\n\n\n", *start_ptr + temp);这个是和上面一样的数组类型

为什么会出现这种结果?

敲重点!!!!!
指针变量大小与类型无关!!!!!!!!!
指针变量大小与环境配置有关!!!!!!!!!!
64位环境所有指针变量为8字节!!!!!!!!!
32位环境所有指针变量为4字节!!!!!!!!!
指针解引用操作符*的操作权限不同(一次可以操作几个字节)!!!!!!!!
char* 的指针解引用就只能访问一个字节, int* 的指针的解引用就能访问四个字节
指针之间的减法,计算距离
//指针之间的减法,计算距离
int* start_ptr = &nums[0];
int* end_ptr = &nums[size - 1];
printf("数组间的距离为: %td\n\n", end_ptr - start_ptr);
指针之间的比较与位置确定
//指针之间的比较
puts("比较指针之间的元素:");
if (start_ptr < end_ptr)
{
puts("start_ptr指向的元素在end_ptr指向的元素之前\n\n");
}//确定两个指针指向位置
int* middle_ptr = &nums[size / 2];
puts("确定两个指针指向位置在中间的左边还是右边");
if (start_ptr < middle_ptr)
{
puts("在 middle_ptr 之前!");
}
if (end_ptr > middle_ptr)
{
puts("在 middle_ptr 之后!");
}使用指针遍历数组
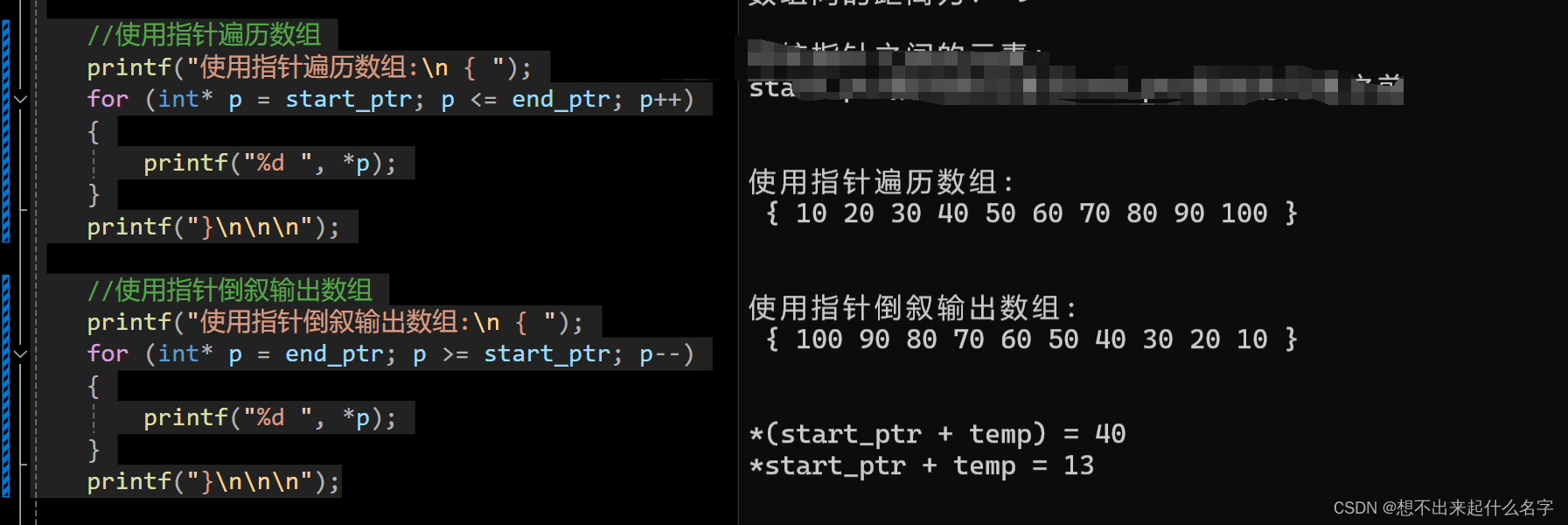
顺序
//使用指针遍历数组
printf("使用指针遍历数组:\n { ");
for (int* p = start_ptr; p <= end_ptr; p++)
{
printf("%d ", *p);
}
printf("}\n\n\n");
我们将第一个元素位置和最后一个元素位置确定,使用指针来循环遍历数组
倒序
修改一下循环体的限制条件,即可实现倒序
//使用指针倒序输出数组
printf("使用指针倒叙输出数组:\n { ");
for (int* p = end_ptr; p >= start_ptr; p--)
{
printf("%d ", *p);
}
printf("}\n\n\n");
看下两个运行结果
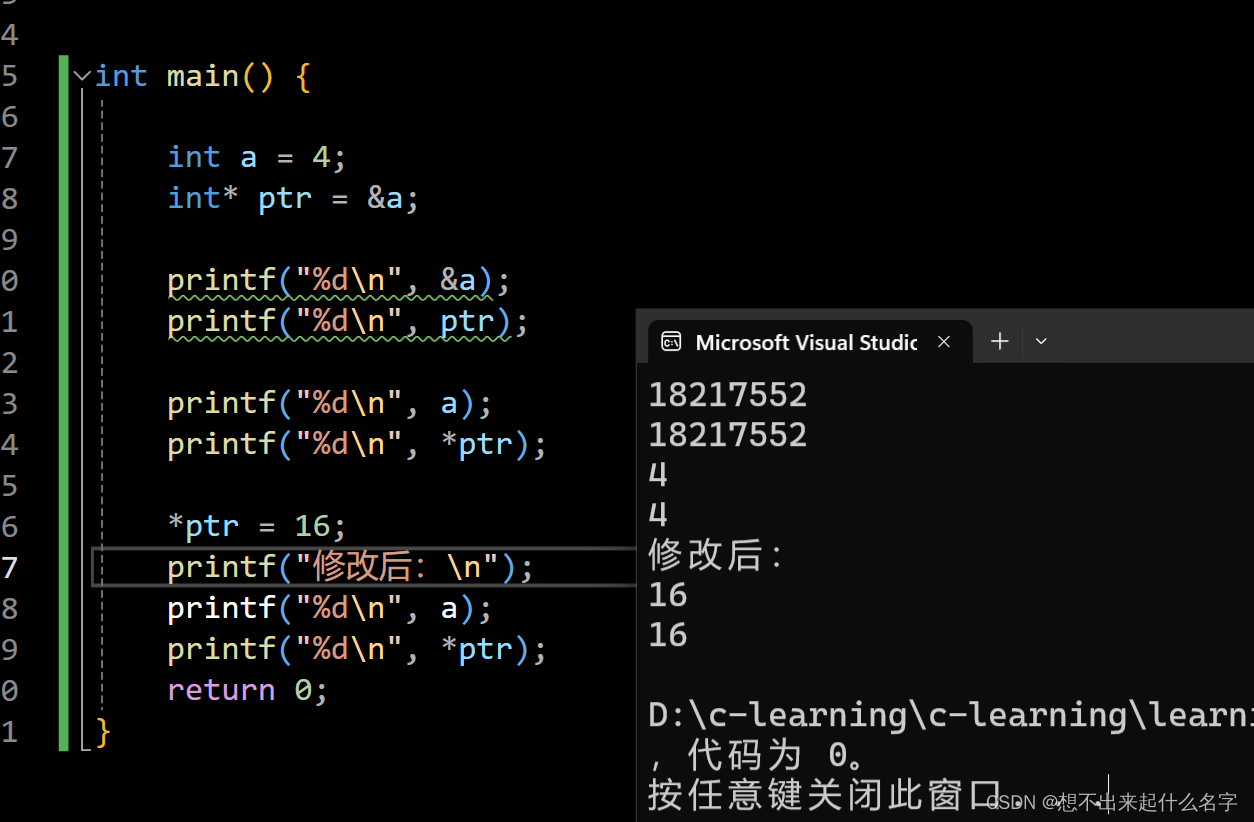
指针修改数组的值
int main() {
int arr[] = { 1,2,3,4,5,6,7,8,9 };
int* ptr_arr = arr;
//int* ptr_arr = &arr[0] 把数组名给指针,相当于把数组的首地址(index = 0)给指针
puts("输出原始数组:");
for (size_t i = 0; i < (sizeof(arr) / sizeof(arr[0])); i++)
{
printf("%d ", arr[i]);
}
puts("\n指针修改数组元素:");
for (size_t i = 0; i < (sizeof(arr) / sizeof(arr[0])); i++)
{
*(ptr_arr + i) += 6;//每次往后跃进一位的值加等于6
printf("%d ", *(ptr_arr + i));
//为什么能用?不怕野指针吗?
//因为数组内存空间是连续排布的,只要知道首地址,我们就可以顺藤摸瓜遍历到整个数组的元素了!
}
for (size_t i = 0; i < (sizeof(arr) / sizeof(arr[0])); i++)
{
printf("%d ", *(ptr_arr + i));
}
return 0;
}指针查找特定元素索引并返回/找下标
int main() {
int values[] = { 10,20,30,40,50 };
int* start_ptr = values;
size_t size = sizeof(values) / sizeof(values[0]);
printf("数组元素个数:%zd\n", size);
int tagert_value = 20;
int* tagert_ptr = NULL;
bool found = false;//假设初始未找到
size_t index = 0;
for (size_t i = 0; i < size; i++)
{ //从首地址开始遍历
if (*(start_ptr + i) == tagert_value) {
tagert_ptr = start_ptr + i; //保存目标元素的地址
index = i; //目标元素的索引
found = true;
break;
}
}
if (found) {
printf("元素 %d 的索引index = %zd\n", tagert_value, index);
}
else {
printf("元素 %d 未找到\n", tagert_value);
}
return 0;
}指针访问多维数组
int main() {
int arr_two[3][4] = {
{1,2,3,4},
{1,1,1,1},
{4,5,6,7}
};
int(*ptr)[4] = arr_two;
//(*ptr[4]): ptr是一个指针,它指向一个包含四个int类型元素的一维数组的指针
//int* ptr[1,2,3]这是指针数组,有三个指针
for (size_t i = 0; i < 3; i++) //控制行
{
for (size_t j = 0; j < 4; j++) //控制列
{
printf("%d ", ptr[i][j]);
}
printf("\n");
}
return 0;
}指针数组
高阶指针
结构体、枚举与联合
结构体定义与访问
我们利用结构体就可以定义我们自己想定义的类型
比如说一个学生相关信息:id,年龄,性别……
结构体最好定义在main函数外部
struct Stduent{
int id;
int age;
char gender[10];
float height;
//.....
} Student;
Student就是我们定义的结构体类型。其中包含id,年龄,性别,身高这几个成员
struct {
int id;
int age;
char gender[10];
float height;
//.....
} Student;
注意看上下区别,下面的student并未写入,下面的结构体称为匿名结构体
****结构体初始化****
struct Studuent{
int id;
int age;
char gender[16];
float height;
//.....
} Student;
Student kunkun = {101, 18, "man", 1.8};
这便是结构体的初始化,
需要注意:1、用花括号括起来数据,与数组的方括号区分开来
2、需要按照自己定义的顺序来初始化
如果不想按照顺序,需要以下操作:
struct student kunkun = {.age = 18, .id = 101, .height = 1.8, .gender = "man"};
.是用来访问结构体成员的符号
这里引入一个关键字typedef
typedef struct Studuent{
int id;
int age;
char gender[16];
float height;
//.....
} Student;
//初始化
student kunkun = //...........
有了这个关键字就无需在初始化时加上struct
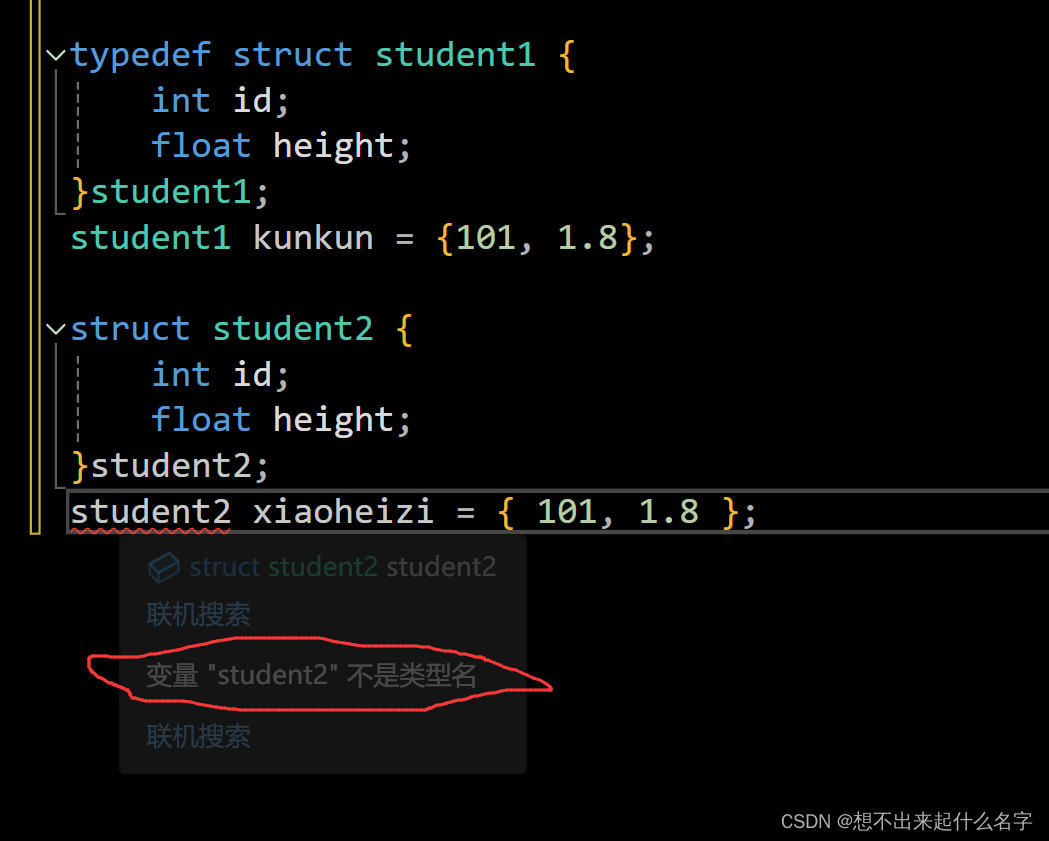
****结构体成员访问****
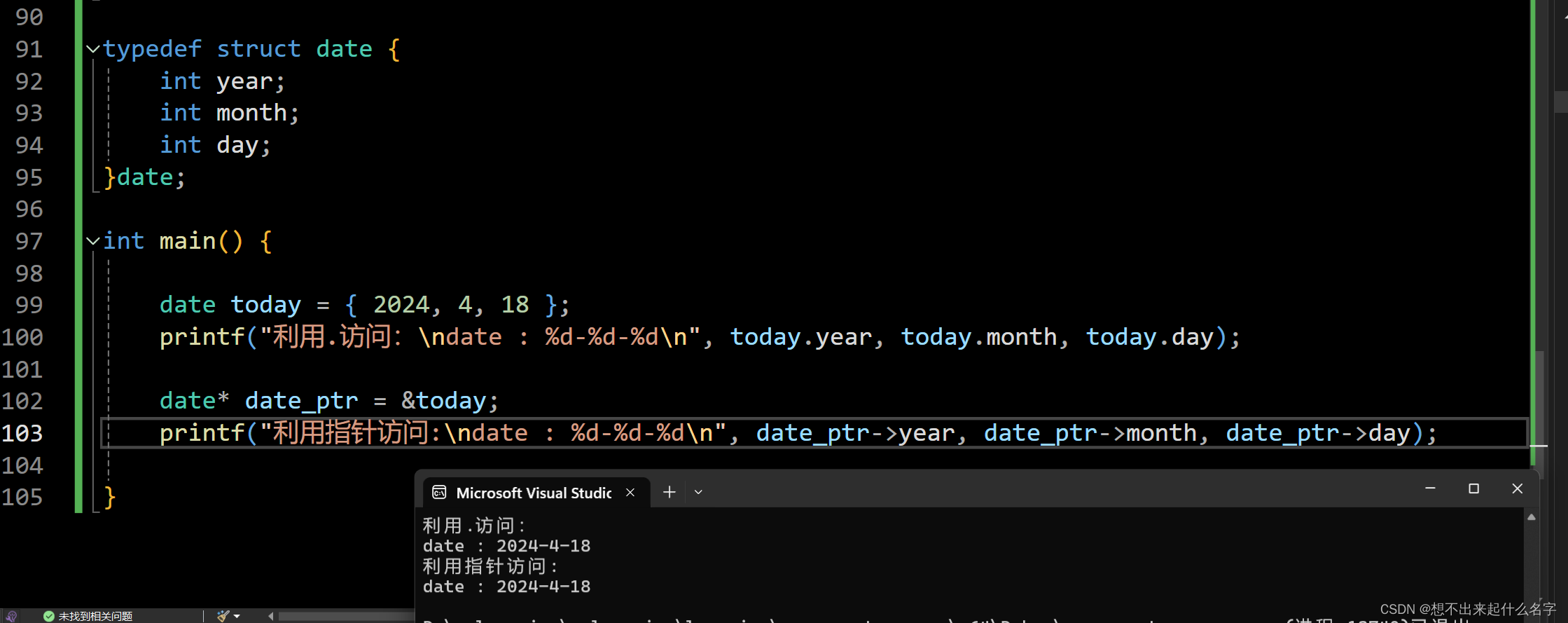
typedef struct Date {
int year;
int month;
int day;
}Date;
int main() {
Date today = { 2024, 4, 18 };
printf("利用.访问:\ndate : %d-%d-%d\n", today.year, today.month, today.day);
Date* date_ptr = &today;
printf("利用指针访问:\ndate : %d-%d-%d\n", date_ptr->year, date_ptr->month, date_ptr->day);
}
结构体作为函数参数
不废话,直接上案例
//录入一个学生信息,并修改其成绩
typedef struct Student {
int id;
char name[64];
float score;
}Student;
void print_student(Student stu);
float update_by_value(Student stu, float new_score);
void update_by_ptr(Student* stu, float new_score);
int main()
{
Student stu = { 01, "kunkun",2.5 };
puts("未修改之前的信息:");
print_student(stu);
puts("\n修改之后的信息,通过值传递:");
update_by_value(stu, 66);
print_student(stu);
puts("\n修改之后的信息,通过指针传递:");
update_by_ptr(&stu, 66);
print_student(stu);
}
void print_student(Student stu) {
printf("id:%d\n", stu.id);
printf("name:%s\n", stu.name);
printf("score:%.2f", stu.score);
}
float update_by_value(Student stu, float new_score) {
stu.score = new_score;
return new_score;
}
void update_by_ptr(Student* stu, float new_score) {
stu->score = new_score;
}结构体作为函数的返回值
typedef struct Position {
int x;
int y;
}Position;
position get_position(viod);
int main() {
Position my_position = get_position();
Position your_position = get_position();
printf("Position: (%d,%d)\n", my_position.x, my_position.y);
printf("Position: (%d,%d)\n", your_position.x, your_position.y);
return 0;
}
Position get_position(viod) {
Position p = { 10 , 9 };
return p; //返回一个结构体副本
}
这种写法有什么好处?安全性高!!!
结构体初始化没有在main函数中,放在了自己定义的一个函数中,只要这个函数执行完就立马销毁,位置难以寻找!!!!!
结构体数组
typedef struct Point {
int x;
int y;
int z;
}Point;
int main() {
Point p[3] = {
{1,2,0},
{3,4,9},
{11,12,66}
};
for (size_t i = 0; i < 3; i++)
{
printf("p[%zd] = (%d,%d,%d)\n", i, p[i].x, p[i].y, p[i].z);
}
return 0;
}嵌套结构体
typedef struct Address {
char country[64];
char city[32];
}Address;
typedef struct Person {
char name[16];
int age;
Address address;
}person;
int main() {
Person kunkun = {
"kunkun",
18,
{"China","BeiJing"}
};
puts("通过.访问");
printf("name:%s\nage:%d\ncountry:%s\ncity:%s\n", kunkun.name, kunkun.age, kunkun.address.country, kunkun.address.city);
puts("通过指针访问:");
Person* ptr = &kunkun;
printf("name:%s\nage:%d\ncountry:%s\ncity:%s\n", ptr->name,ptr->age,ptr->address.country,ptr->address.city);
return 0;
}
typedef struct Address {
char country[64];
char city[32];
}Address;typedef struct person {
char name[16];
int age;
Address address;
}person;
这两个部分顺序不能错!!!
C语言是从上到下依次执行,如果未先定义需要嵌套的结构体,后果很严重!!!!
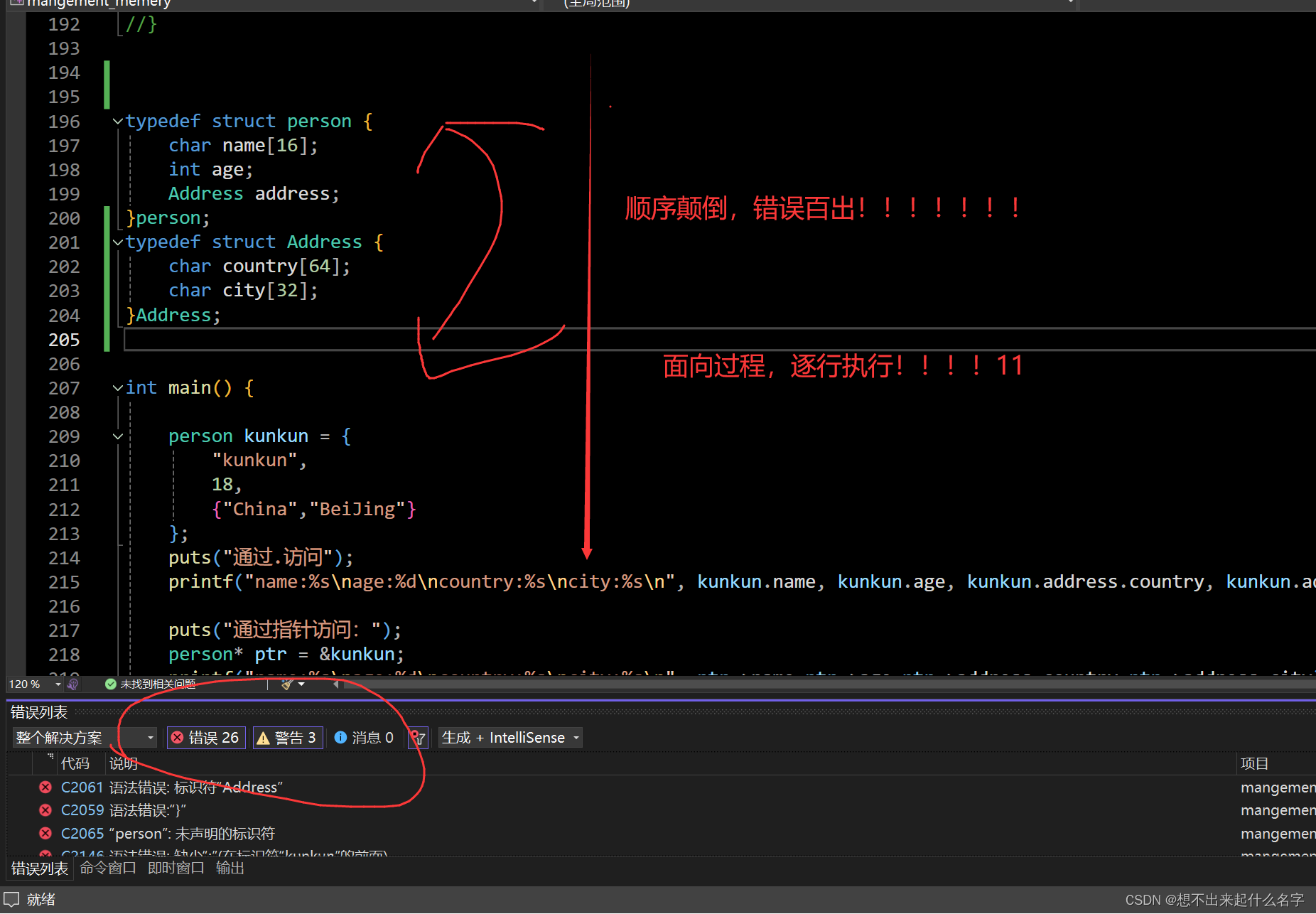
这里修改个小错误,命名结构体类型的时候首字母大写,有区分度,这里的图片我就不修改了
可能每个企业的要求会有所不同,现在大一的我做着白日梦哈哈哈哈哈哈哈
枚举
顾名思义,一一列举,语法也很简单
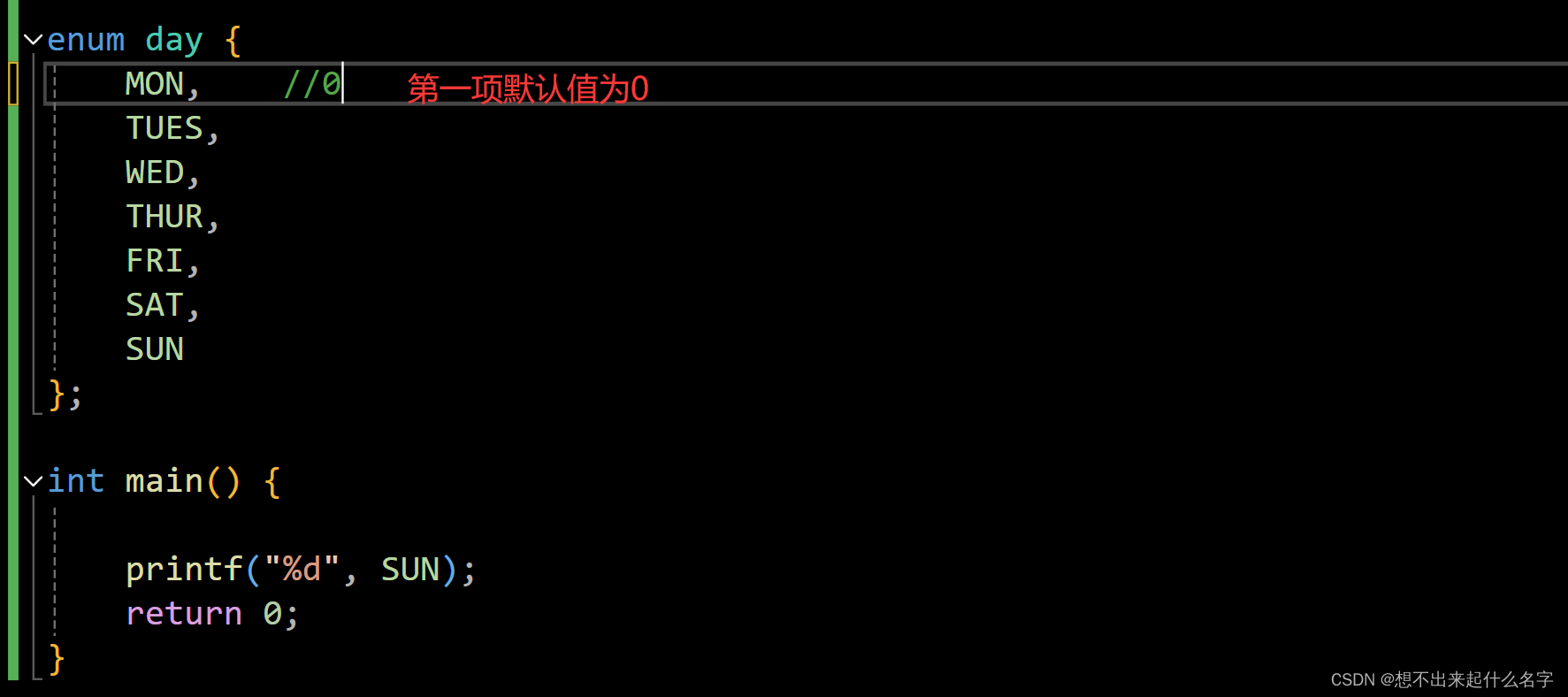
为什么需要枚举?
联合/共用体
它允许在相同内存位置储存不同的数据类型
联合体所有成员共享一块内存空间大小,大小一般情况下等于其最大成员的大小
这意味着在任意时刻,联合体只能存储一个成员的值,在给定的时刻,只使用成员里的唯一一个类型,即需要用到哪个成员就用哪个成员,这样可以节省内存
//定义一个联合体
//联合体里的成员公用一块内存,一般内存占用是内存最大的那个成员
typedef union {
int int_value;
float float_value;
char* strings_value;
}Data;
//定义一个枚举类型
typedef enum {
INT,
FLOAT,
STRINGS
}DataType;
//定义一个包含枚举和联合体的结构体,我们可以对结构体成员自由操作
typedef struct {
DataType type; //枚举
Data data; //联合
}TypeData;
void print_data(TypeData* ptr);
int main() {
TypeData data1 = {INT, { .int_value = 66 }};
TypeData data2 = { FLOAT, {.float_value = 66.666 } };
TypeData data3 = { STRINGS, {.strings_value = "hello! union!"}};
print_data(&data1);
print_data(&data2);
print_data(&data3);
}
void print_data(TypeData* ptr) {
switch (ptr -> type)
{
case INT:printf("intger: %d\n", ptr->data.int_value);
break;
case FLOAT:printf("float: %f\n", ptr->data.float_value);
break;
case STRINGS:printf("strings: %s\n", ptr->data.strings_value);
break;
}
}
字符串及其相关函数
文件操作
流与标准流
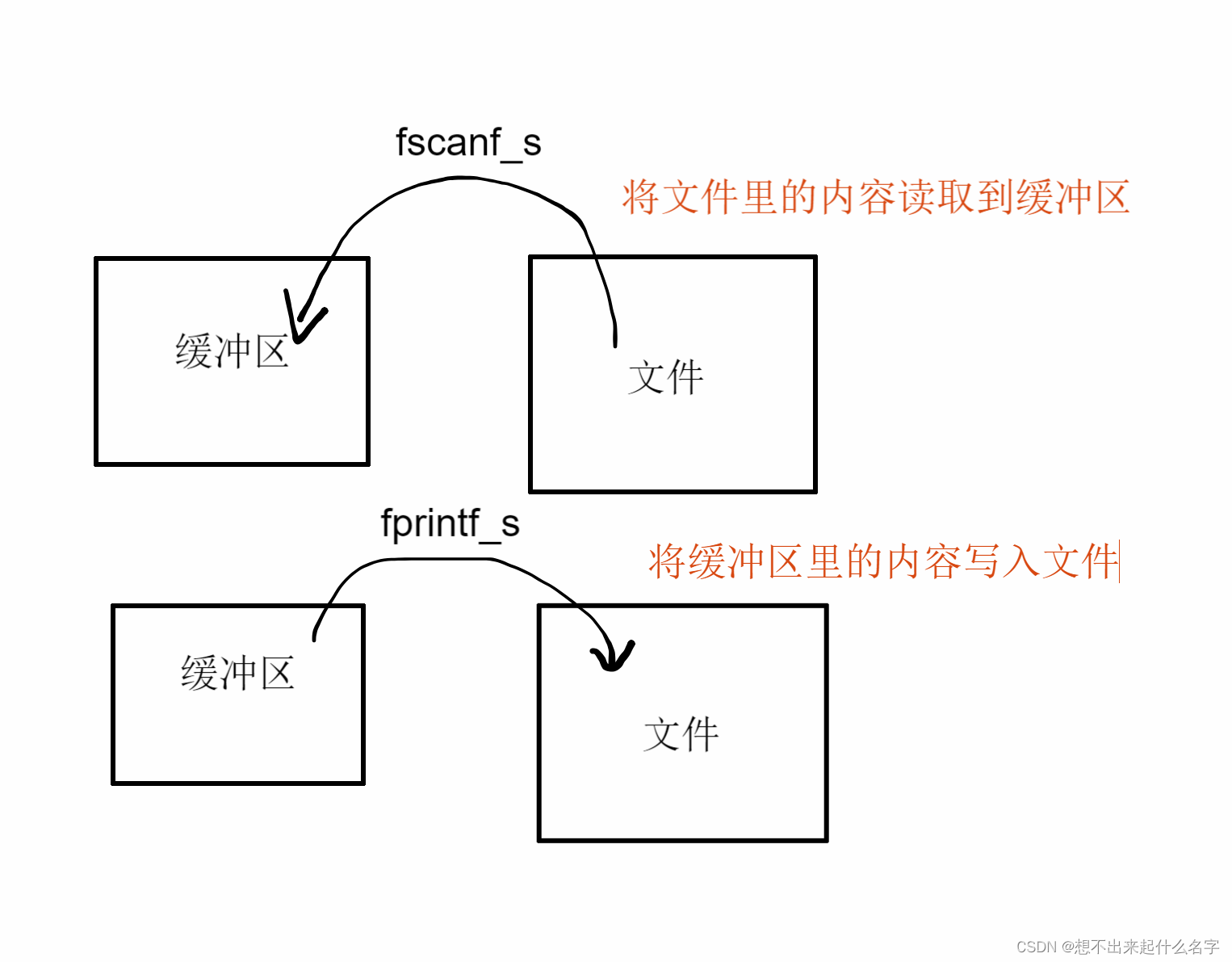
对于一个文件,我们可以对其读或写
输入流——input stream 输出流——output stream
输入流的数据被暂存到缓存区(buffer)
流的分类:
文件流:在磁盘上,用于读取与写入在磁盘上的文件
标准I/O流:
标准输入流stdin:默认连接到键盘,用于程序的输入
标准输出流stdout:默认连接到控制台或者屏幕上,用于程序的输出
标准错误流stderr:默认连接到控制台或者屏幕上,专门输出错误信息与警告
管道流:用于进程之间的通信,与许一个进程的输出成为另一个进程的输入
内存流:允许用户将流与内存缓冲区关联,使用户可以向内存中读写数据,就像操作文件一样
网络流:套接字
设备流:特殊文件或打印机
利用FILE* stream(变量名) 指针来进行对流的操作
打开文件 关闭文件
打开文件
fopen:
FILE *fopen( const char *filename, const char *mode );
文件名 访问类型
foepn_s
errno_t fopen_s( //errno_t为fopen_s的返回类型,需要<errno.h>
FILE** pFile, //二级指针,接收访问文件的指针
const char *filename, //文件名
const char *mode); //访问类型
这里的访问类型指的是你要对文件进行的操作
有如下访问类型:

关闭文件
关闭单个文件fclose:
int fclose( FILE *stream );
关闭所有文件_fcloseall
int _fcloseall( void );
文件读取与输出相关函数
读取:r模式
fgets: 从流中获取字符串
char *fgets(
char *str, //位置
int numChars, //最大字符数
FILE *stream ); //流名称
fgetc:从流中读取字符int fgetc( FILE *stream );
fscanf_s: 从流中读取格式化的数据
int fscanf_s( FILE *stream, const char *format [, argument ]... );
写入:w模式
fputs: 将字符串写入流
int fputs( const char *str, FILE *stream );
fputc: 将字符写入流
int fputc(
int c, //要写入的字符
FILE *stream );
fprintf_s: 将格式化的数据打印到流
int fprintf_s( FILE *stream, const char *format [, argument_list ] );
ftell: 获取文件指针的当前位置
long ftell( FILE *stream );
fseek: 将文件指针移动到指定位置
int fseek(
FILE *stream,
long offset, //来自源的字节数
int origin ); //初始位置
rewind: 将文件指针重新定位到文件开头的位置
void rewind( FILE *stream );
fgets、fgetc与r模式
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE* file_stream = NULL;
char buffer[256];
//打开文件
errno_t err = fopen_s(&file_stream, "C:\\Users\\17601\\Desktop\\myfile.txt", "r");
if (err != 0 || file_stream == NULL)
//为什么err不等于0?如果err等于0就相当于没有错误!
{
//打印错误信息
perror("error opening the file!");
return EXIT_FAILURE;
}
//按行打印所有字符串
while (fgets(buffer, sizeof(buffer), file_stream) != NULL)
{
printf("%s", buffer);
}
//读完之后就结束了,指针停在文件结尾,就不继续往下读了
//清理缓存区
memset(buffer, 0, sizeof(buffer));
printf("\n");
//将file_ stream指针引动到文件开头
rewind(file_stream);
int ch;
while ((ch = fgetc(file_stream)) != EOF)
{
putchar(ch);
}
if (fclose(file_stream) != 0)
{
perror("error closing the file!");
return EXIT_FAILURE;
}
return 0;
}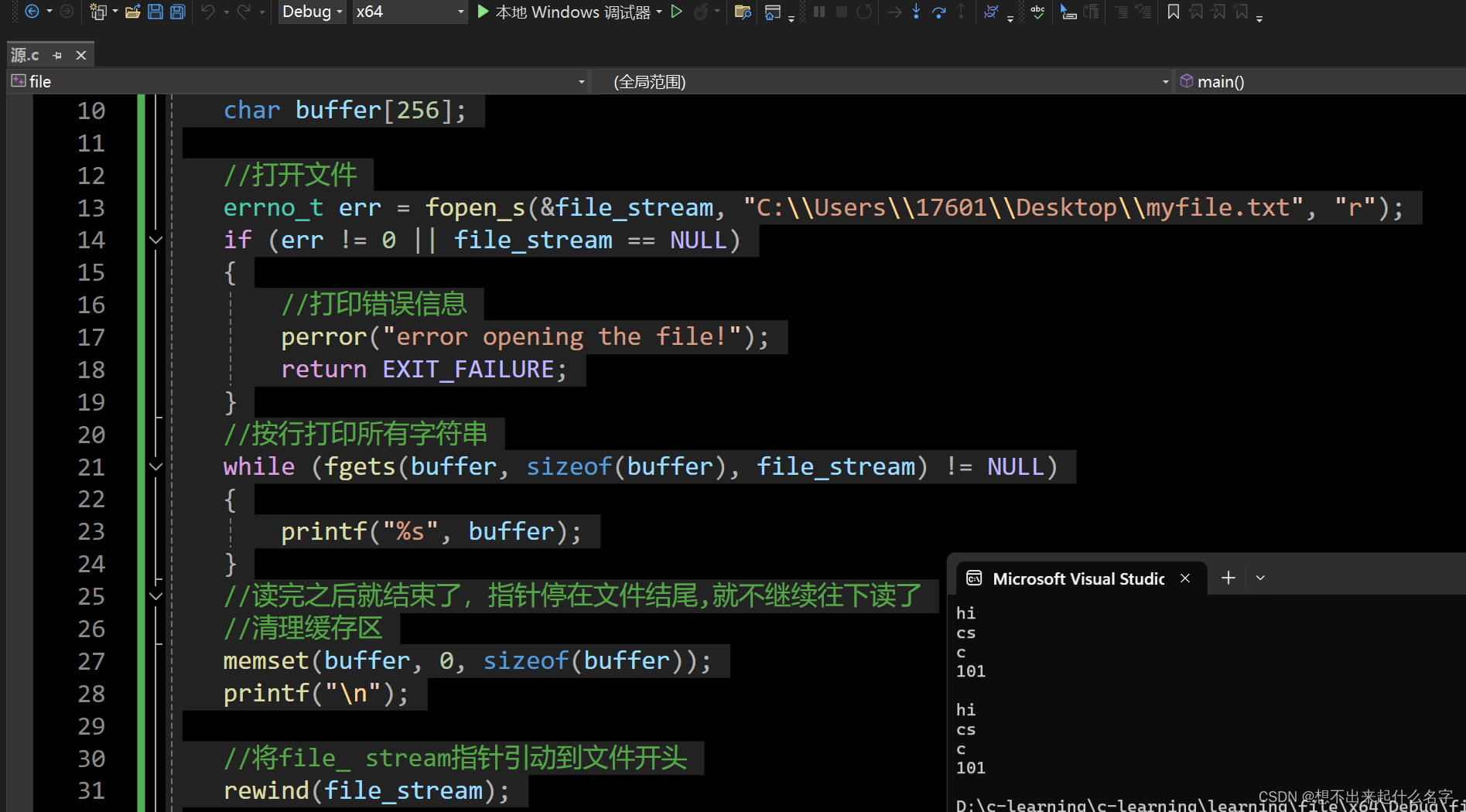
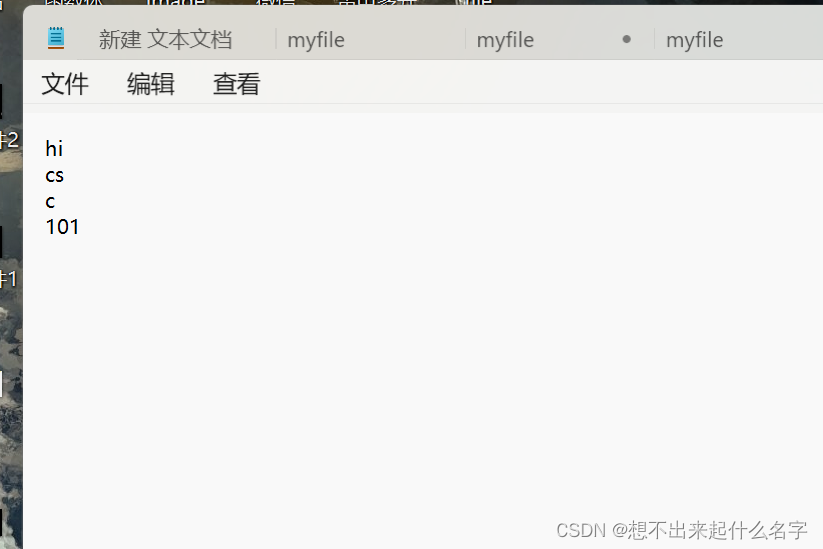
注意看运行结果,这个是我提前写入的一个记事本文件
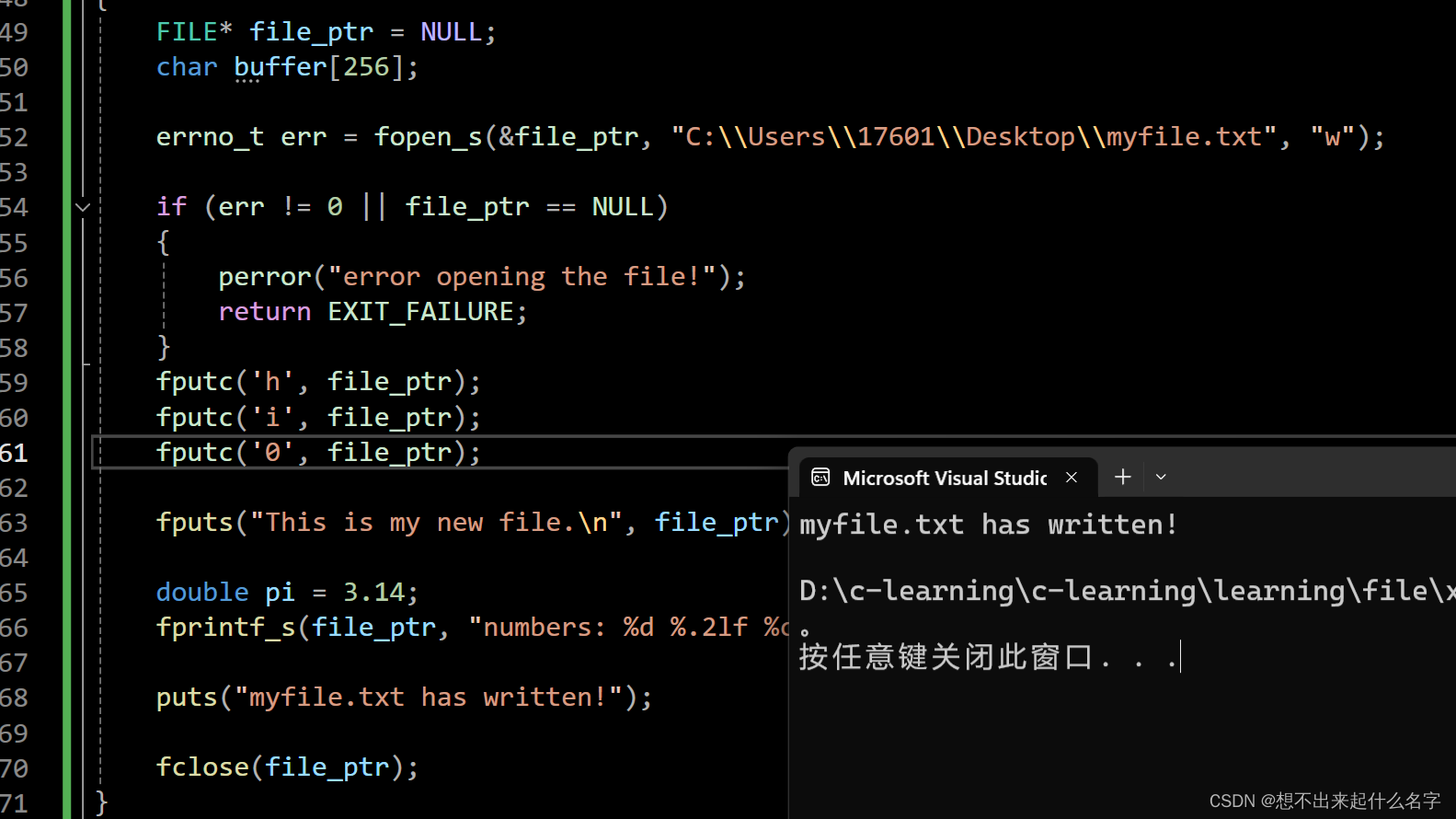
fputs、fputc与w模式
int main()
{
FILE* file_ptr = NULL;
char buffer[256];
errno_t err = fopen_s(&file_ptr, "C:\\Users\\17601\\Desktop\\myfile.txt", "w");
if (err != 0 || file_ptr == NULL)
{
perror("error opening the file!");
return EXIT_FAILURE;
}
fputc('h', file_ptr);
fputc('i', file_ptr);
fputc('0', file_ptr);
fputs("This is my new file.\n", file_ptr);
double pi = 3.14;
fprintf_s(file_ptr, "numbers: %d %.2lf %c", 10, pi, 'h');
puts("myfile.txt has written!");
fclose(file_ptr);
return 0;
}
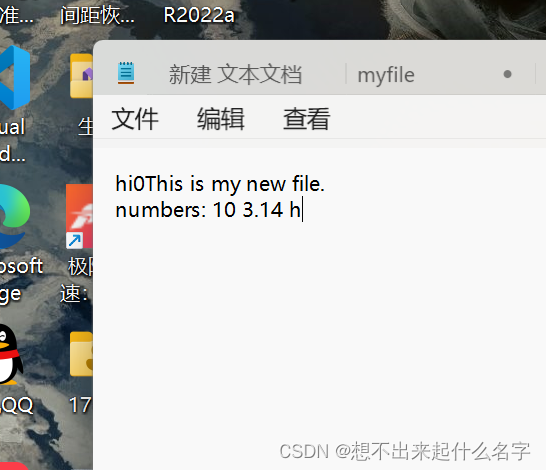
此时这个文件已经成功被修改,这里可以看出“w”模式,是把原来文件中的所有内容删除干净之后再写入
所以,w模式可以做一个操作:清空文档,但不写入的操作

ftell、fseek、rewind
int main()
{
FILE* file_stream;
char buffer[256];
errno_t err = fopen_s(&file_stream, "C:\\Users\\17601\\Desktop\\myfile.txt", "r");
if (err != 0 || file_stream == NULL)
{
perror("error opening the file!");
return EXIT_FAILURE;
}
//记录初始位置
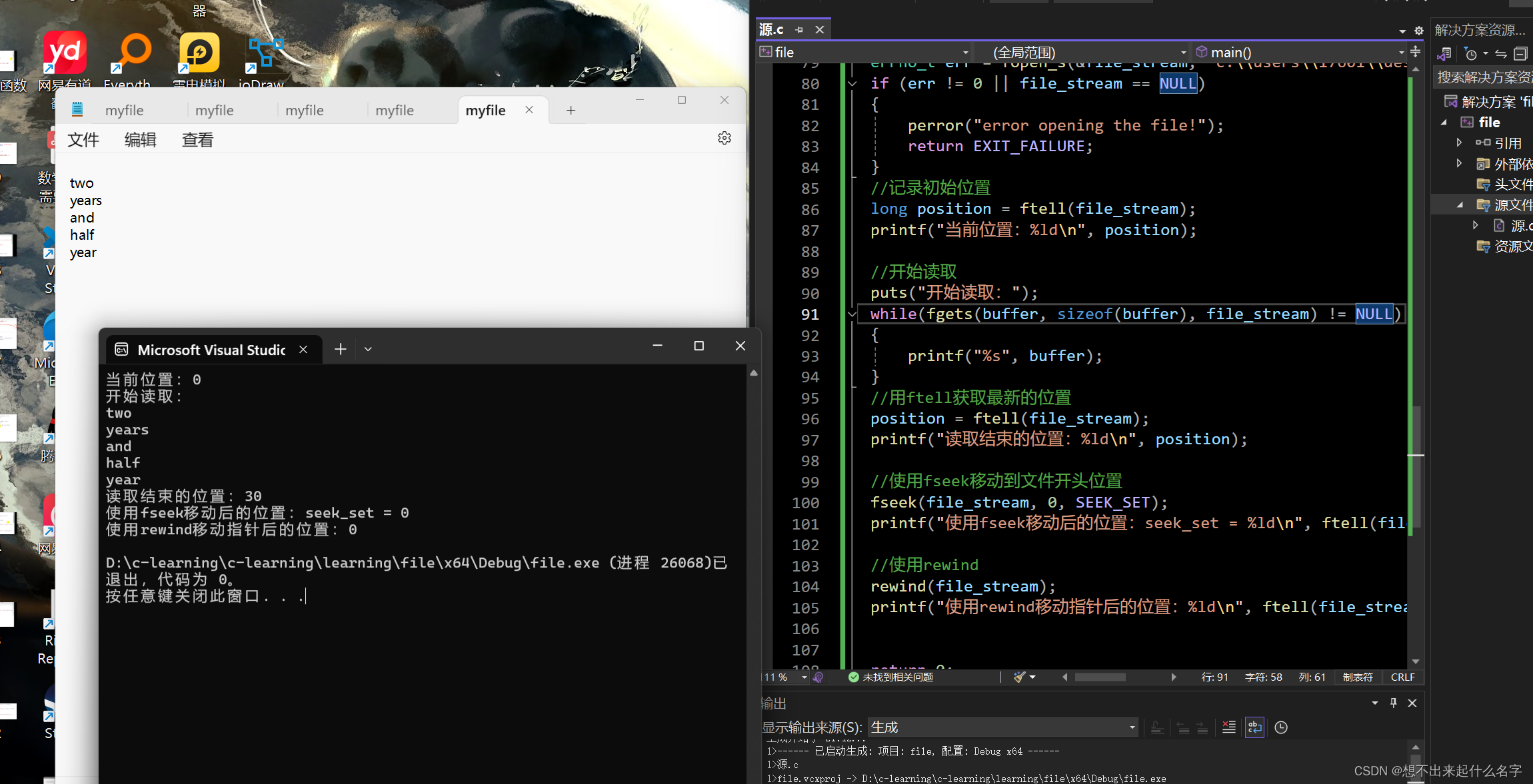
long position = ftell(file_stream);
printf("当前位置:%ld\n", position);
//开始读取
puts("开始读取:");
while(fgets(buffer, sizeof(buffer), file_stream) != NULL)
{
printf("%s", buffer);
}
//用ftell获取最新的位置
position = ftell(file_stream);
printf("读取结束的位置:%ld\n", position);
//使用fseek移动到文件开头位置
fseek(file_stream, 0, SEEK_SET);
printf("使用fseek移动后的位置:SEEK_SET = %ld\n", ftell(file_stream));
//使用rewind
rewind(file_stream);
printf("使用rewind移动指针后的位置:%ld\n", ftell(file_stream));
return 0;
}
ferror、feof、clearerr
clearerr:重置流的错误指示器,清除错误
void clearerr( FILE *stream );
feof:测试流上的文件末尾/是否到达文件末尾
int feof( FILE *stream );
ferror:测试流上的错误
int ferror( FILE *stream );
int main()
{
FILE* stream = NULL;
char buffer[64];
errno_t err = fopen_s(&stream, "C:\\Users\\17601\\Desktop\\myfile.txt", "r");
if (err != 0 || stream == NULL)
{
perror("error opening the file!");
return EXIT_FAILURE;
}
//这个错误检测是在打开文件的时候
while (fgets(buffer, sizeof(buffer), stream) != NULL)
{
printf("%s", buffer);
}
if (ferror(stream))
{
perror("error!");
clearerr(stream);
}
//这个错误检测是在文件已经打开,在读取的时候
if (feof(stream))
{
printf("\nSuccessfully reached the end of file!\n");
}
else
{
printf("\nfailuring reached the end of file!\n");
}
fclose(stream);
return 0;
}
if (err != 0 || stream == NULL)
{
perror("error opening the file!");
return EXIT_FAILURE;
}
这段代码是检测文件是否能成功打开if (ferror(stream))
{
perror("error!");
clearerr(stream);
}这段代码是在读取文件时,检测是否出错
fscanf_s与fprintf_s
fscanf_s: 从流中读取格式化的数据
int fscanf_s( FILE *stream, const char *format [, argument ]... );
fprintf_s: 将格式化的数据打印到流
int fprintf_s( FILE *stream, const char *format [, argument_list ] );
复制文件
fread: 从流中读取数据
size_t fread(
void *buffer,
size_t size, //项目大小,字节为单位
size_t count, //要读取的最大项目数
FILE *stream );
fwrite: 将数据写入流
size_t fwrite(
const void *buffer,
size_t size,
size_t count, //要写入的最大项目数
FILE *stream );
int main()
{
FILE* source_ptr = NULL;
FILE* tagert_ptr = NULL;
char buffer[1024];
size_t bytes_read;
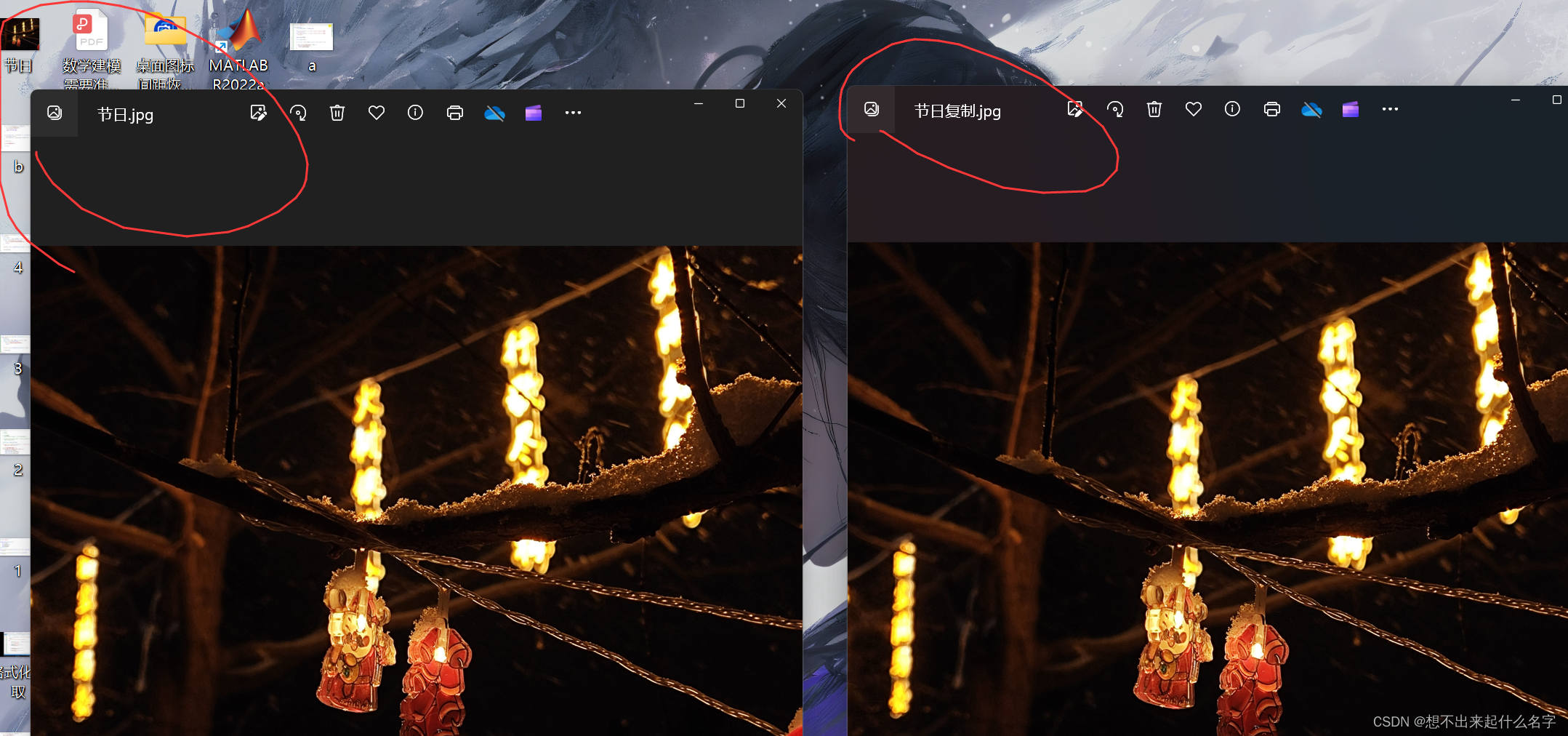
errno_t err_source = fopen_s(&source_ptr, "C:\\Users\\17601\\Desktop\\节日.jpg", "rb");
if (err_source != 0 || source_ptr == NULL)
{
printf("error opening!");
return EXIT_FAILURE;
}
errno_t err_tagert = fopen_s(&tagert_ptr, "C:\\Users\\17601\\Desktop\\节日复制.jpg", "wb");
if (err_tagert != 0 || tagert_ptr == NULL)
{
printf("error opening!");
return EXIT_FAILURE;
}
while ( ( bytes_read = fread(buffer, 1, sizeof(buffer), source_ptr) )> 0)
{
fwrite(buffer, 1, sizeof(buffer), tagert_ptr);
}
_fcloseall();
puts("文件复制完成!");
return 0;
}
动态内存管理
******计算机内存管理机制******
内存分为栈内存和堆内存
栈内存:
int input ; //固定死了4字节
int num[4]; //固定死了这个数组只有四个长度
我们在定义之后,整个变量的大小就固定死了
给用户的反馈就是,就这么大,我不管浪费还是不够,你爱用不用吧
a.自动管理的分配机制机制:在函数调用的时候,局部变量被分配在栈区,当函数返回时,局部变量全部销毁并释放
b.访问速度快:栈内存的分配与访问速度通常要比堆内存快,它是一种线性的数据结构(比如说数组的每个格子都是相邻紧挨着,下标连续)
c.大小有限制:栈的大小,在程序启动时就意味着已经确定了,就无法改动了,栈的内存被耗尽,就意味着崩溃,栈溢出。
d.栈区保存着函数的局部变量,函数参数,函数调用的返回地址
堆内存:
a.动态管理:malloc、calloc、realloc、free
b.速度相较于栈有些慢。它需要在内存中寻找足够大的连续空间块
c.大小十分灵活。堆的大小通常受到可用系统内存的限制,而并非栈本身的限制
malloc:分配内存空间
void *malloc(
size_t size );
//size是分配内存块的大小,单位字节
//
malloc会返回指向已分配空间的 void 指针,如果可用内存不足,则返回NULL。 若要返回指向类型而非void的指针,需要在返回值上使用类型转换
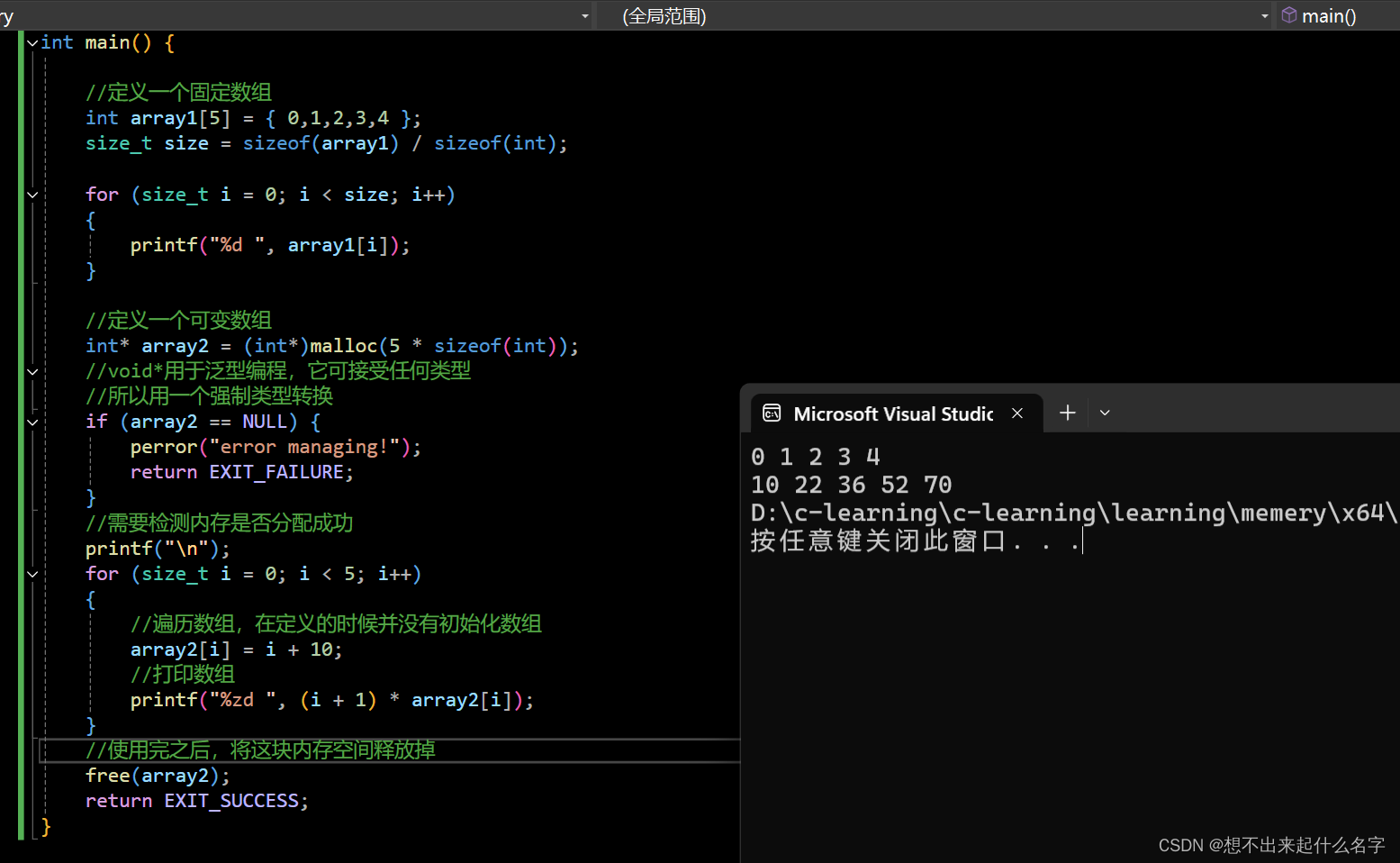
#include <stdio.h>
#include <stdlib.h>
int main() {
//定义一个固定数组
int array1[5] = { 0,1,2,3,4 };
size_t size = sizeof(array1) / sizeof(int);
for (size_t i = 0; i < size; i++)
{
printf("%d ", array1[i]);
}
//这个固定的数组分配到栈上
//在编译的时候,它的生命周期和作用域就已经确定,再无法更改
//定义一个可变数组,分配到堆上
int* array2 = (int*)malloc(5 * sizeof(int));
//void*用于泛型编程,它可接受任何类型
//所以用一个强制类型转换
if (array2 == NULL) {
perror("error managing!");
return EXIT_FAILURE;
}
//需要检测内存是否分配成功
printf("\n");
for (size_t i = 0; i < 5; i++)
{
//遍历数组,在定义的时候并没有初始化数组
array2[i] = i + 10;
//打印数组
printf("%zd ", (i + 1) * array2[i]);
}
//使用完之后,将这块内存空间释放掉,堆上的内存需要自己手动释放
free(array2);
return EXIT_SUCCESS;
}
realloc:重新分配内存空间
void *realloc(
void *memblock, //指向先前的已经分配了内存的指针
size_t size ); //新内存大小,单位字节
特别注意:
realloc函数更改已分配内存块的大小。memblock参数指向内存块的开头。 如果memblock为NULL,则realloc与malloc的行为相同,并分配一个size字节的新块。 如果memblock不为NULL,则它应是指向以前调用calloc、malloc或realloc所返回的指针。
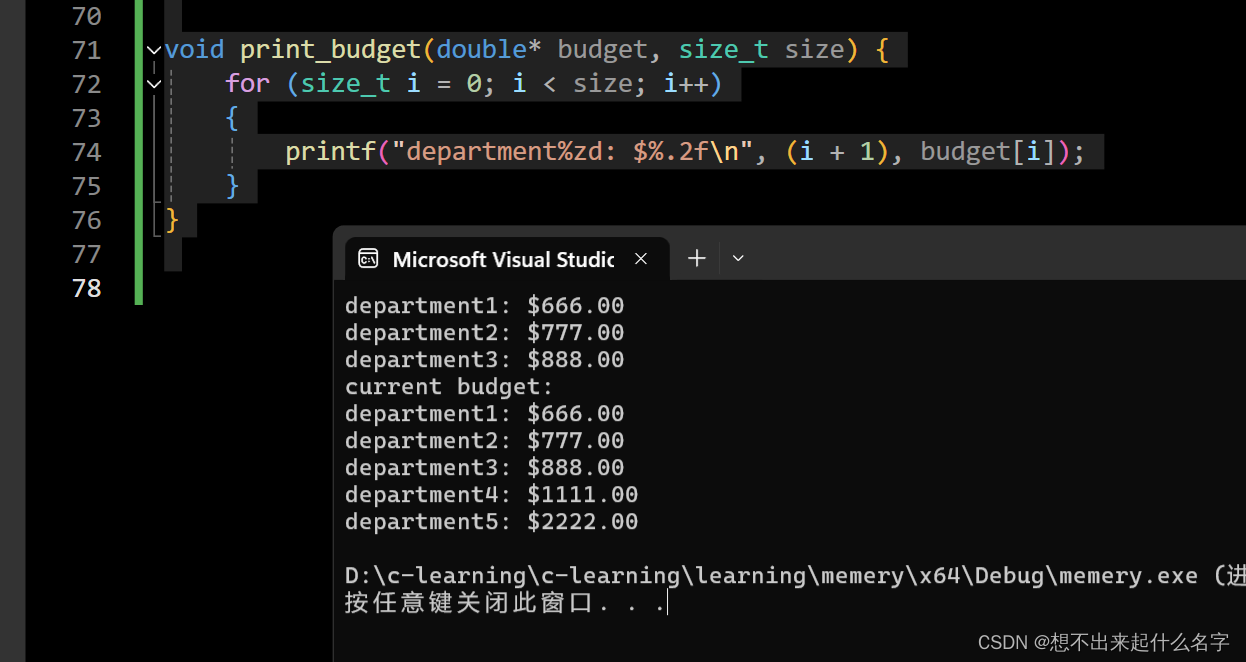
//三个部门预算增加至五个部门预算
void print_budget(double* budget, size_t size);
int main() {
size_t size = 3;
double* budget = (double*)malloc(size * sizeof(double));
if (budget == NULL) {
perror("error!");
return EXIT_FAILURE;
}
budget[0] = 666;
budget[1] = 777;
budget[2] = 888;
print_budget(budget, size);
size_t new_size = 5;
double* new_budget = (double*)realloc(budget, new_size * sizeof(double));
if (new_budget == NULL) {
perror("error!");
free(budget);//新的内存没有分配成功,释放旧的即可
return EXIT_FAILURE;
}
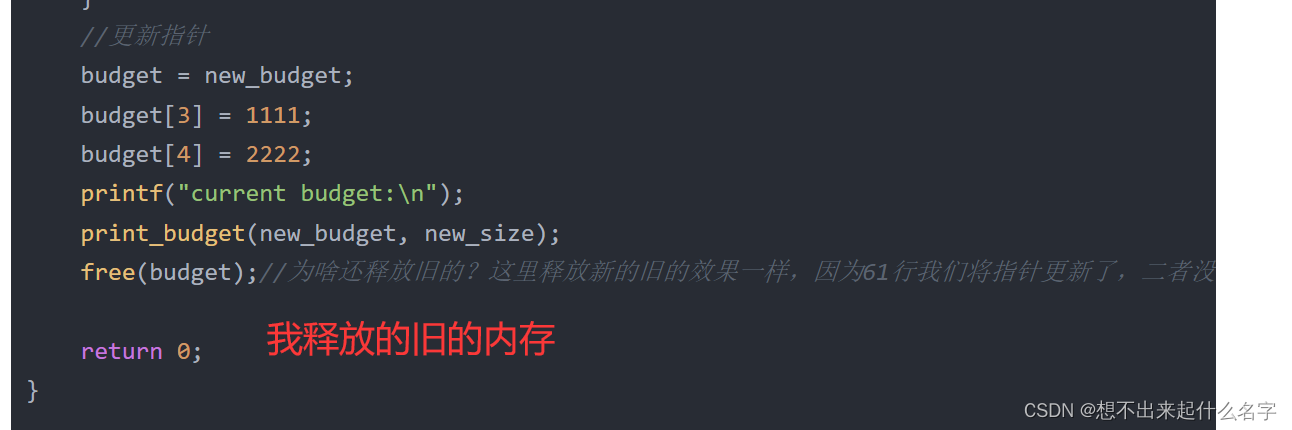
//更新指针
budget = new_budget;
budget[3] = 1111;
budget[4] = 2222;
printf("current budget:\n");
print_budget(new_budget, new_size);
free(budget);//为啥还释放旧的?这里释放新的旧的效果一样,因为61行我们将指针更新了,二者没有区别
return 0;
}
void print_budget(double* budget, size_t size) {
for (size_t i = 0; i < size; i++)
{
printf("department%zd: $%.2f\n", (i + 1), budget[i]);
}
}
//这个是我copy微软文档的案例
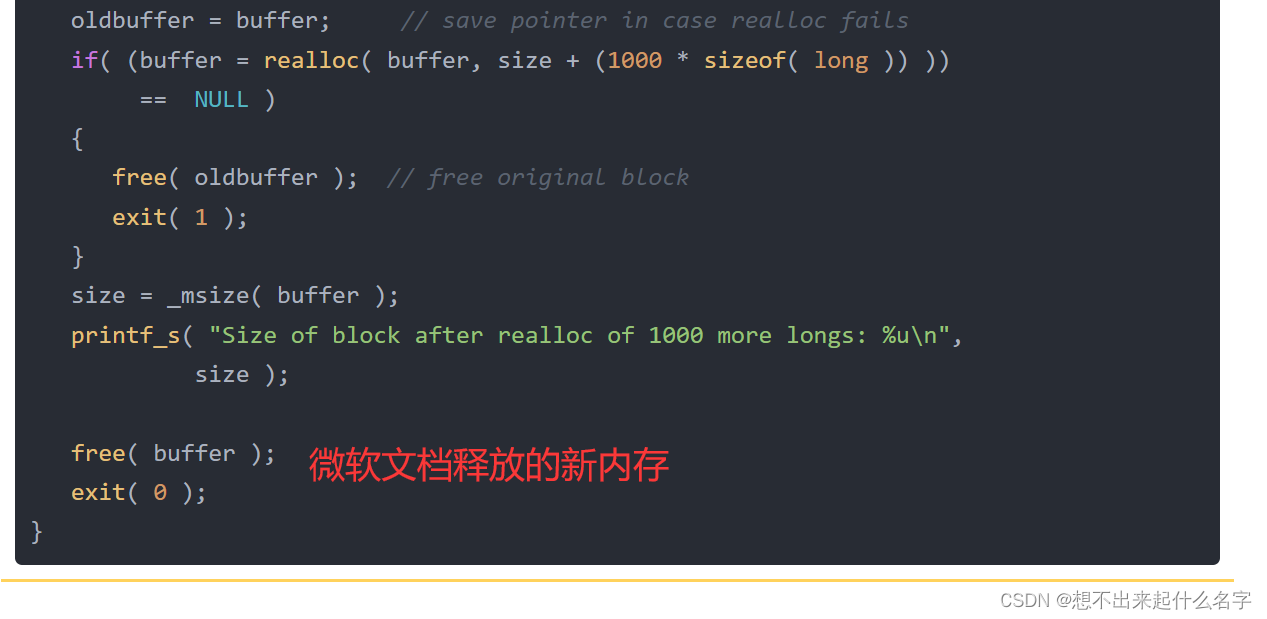
// crt_realloc.c
// This program allocates a block of memory for
// buffer and then uses _msize to display the size of that
// block. Next, it uses realloc to expand the amount of
// memory used by buffer and then calls _msize again to
// display the new amount of memory allocated to buffer.
#include <stdio.h>
#include <malloc.h>
#include <stdlib.h>
int main( void )
{
long *buffer, *oldbuffer;
size_t size;
if( (buffer = (long *)malloc( 1000 * sizeof( long ) )) == NULL )
exit( 1 );
size = _msize( buffer );
printf_s( "Size of block after malloc of 1000 longs: %u\n", size );
// Reallocate and show new size:
oldbuffer = buffer; // save pointer in case realloc fails
if( (buffer = realloc( buffer, size + (1000 * sizeof( long )) ))
== NULL )
{
free( oldbuffer ); // free original block
exit( 1 );
}
size = _msize( buffer );
printf_s( "Size of block after realloc of 1000 more longs: %u\n",
size );
free( buffer );
exit( 0 );
}
calloc :使用初始化为 0 的元素分配内存中的数组
void *calloc(
size_t number, //元素数量
size_t size );
//定制一个员工的姓名,任务列表,任务数量
typedef struct Employee {
char* name;
int* task_list;
int task_count;
}Employee;
Employee* create_employee(const char* name, int task_count);//任务数量决定着任务列表
void free_employee(Employee* Employee);
int main() {
Employee* developer = create_employee("kunkun", 5);
if (developer == NULL) {
perror("error!");
return EXIT_FAILURE;
}
developer->task_list[0] = 1235;
//任务列表就可以自己制定了
//输出一个看下实力,哈哈哈哈哈
printf("task: %s %d\n", developer->name, developer->task_list[0]);
free_employee(developer);
return 0;
}
Employee* create_employee(const char* name, int task_count) {
Employee* new_employee = (Employee*)malloc(sizeof(Employee));
if (new_employee == NULL) {
perror("error!");
return NULL;
}
new_employee->name = (char*)malloc(strlen(name) + 6);
if (new_employee->name == NULL) {
perror("error!");
free(new_employee);//名字都是空的,还创建什么员工?直接释放!防止内存泄露!
return NULL;
}
strcpy_s(new_employee->name, strlen(name) + 6, name);
new_employee->task_count = task_count;
//清空任务列表,任务数量决定着任务列表
new_employee->task_list = (int*)calloc(task_count, sizeof(int));
if (new_employee->task_list == NULL) {
perror("error!");
//注意释放内存的顺序,没任务?找员工名字,名字是空的?员工哪去了?
free(new_employee->name);
free(new_employee);
return NULL;
}
return new_employee;
}
void free_employee(Employee* employee) {
if (employee != NULL) {
free(employee->name);
free(employee->task_list);
free(employee);
}
}
Employee* create_employee(const char* name, int task_count) {
Employee* new_employee = (Employee*)malloc(sizeof(Employee));
if (new_employee == NULL) {
perror("error!");
return NULL;
}
new_employee->name = (char*)malloc(strlen(name) + 6);
if (new_employee->name == NULL) {
perror("error!");
free(new_employee);
return NULL;
}
strcpy_s(new_employee->name, strlen(name) + 6, name);
new_employee->task_count = task_count;
//清空任务列表,任务数量决定着任务列表
new_employee->task_list = (int*)calloc(task_count, sizeof(int));
if (new_employee->task_list == NULL) {
perror("error!");
//注意释放内存的顺序,我们先开辟的是员工,后开辟员工姓名的内存
free(new_employee->name);
free(new_employee);
return NULL;
}
return new_employee;
}
void free_employee(Employee* employee) {
if (employee != NULL) {
free(employee->name);
free(employee->task_list);
free(employee);
}
}














 2268
2268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









