









05
数据预处理
本案例主要采用数据清洗、属性规约与数据变换的预处理方法。
1. 数据清洗
通过对数据观察发现原始数据中存在票价为空值,票价最小值为0、折扣率最小值为0、总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成。其他的数据可能是客户乘坐0折机票或者积分兑换造成。由于原始数据量大,这类数据所占比例较小,对于问题影响不大,因此对其进行丢弃处理。同时,数据探索时发现部分年龄大于100记录,也进行丢弃处理,具体处理方法如下。
(1) 丢弃票价为空的记录;
(2) 保留票价不为0的,或者平均折扣率不为0且总飞行公里数大于0的记录;
(3) 丢弃年龄大于100的记录;
使用pandas对满足清洗条件的数据进行丢弃,处理方法为满足清洗条件的一行数据全部丢弃,如代码清单1所示。
import numpy as npimport pandas as pddatafile = '../data/air_data.csv' # 原始数据路径cleanedfile = '../tmp/data_cleaned.csv' # 数据清洗后保存的文件路径# 读取数据airline_data = pd.read_csv(datafile,encoding = 'utf-8')print('原始数据的形状为:',airline_data.shape)# 去除票价为空的记录airline_notnull = airline_data.loc[airline_data['SUM_YR_1'].notnull() &airline_data['SUM_YR_2'].notnull(),:]print('删除缺失记录后数据的形状为:',airline_notnull.shape)# 只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。index1 = airline_notnull['SUM_YR_1'] != 0index2 = airline_notnull['SUM_YR_2'] != 0index3 = (airline_notnull['SEG_KM_SUM']> 0) & (airline_notnull['avg_discount'] != 0)index4 = airline_notnull['AGE'] > 100 # 去除年龄大于100的记录airline = airline_notnull[(index1 | index2) & index3 & ~index4]print('数据清洗后数据的形状为:',airline.shape)airline.to_csv(cleanedfile) # 保存清洗后的数据
代码清单1 清洗空值与异常值
2.属性规约
本案例的目标是客户价值分析,即通过航空公司客户数据识别不同价值的客户,识别客户价值应用最广泛的模型是RFM模型。
2.1 RFM模型
① R (Recency)
R (Recency)指的是最近一次消费时间与截止时间的间隔。通常情况下,最近一次消费时间与截止时间的间隔越短,对即时提供的商品或是服务也最有可能感兴趣。这也是为什么,消费时间间隔0至6个月的顾客收到的沟通信息多于1年以上的顾客。
最近一次消费时间与截止时间的间隔不仅能够为确定促销客户群体提供依据,还能够从中得出企业发展的趋势。如果分析报告显示最近一次消费时间很近的客户在增加,则表示该公司是个稳步上升的公司。反之,最近一次消费时间很近的客户越来越少,则说明该公司需要找到问题所在,及时调整营销策略。
② F (Frequency)
F (Frequency)指顾客在某段时间内所消费的次数。可以说消费频率越高的顾客,也是满意度越高的顾客,其忠诚度也就越高,顾客价值也就越大。增加顾客购买的次数意味着从竞争对手处偷取市场占有率,赚取营业额。商家需要做的,是通过各种营销方式,去不断的刺激顾客消费,提高他们的消费频率,提升店铺的复购率。
③ M (Monetary)
M(Monetary)指顾客在某段时间内所消费的金额。消费金额越大的顾客,他们的消费能力自然也就越大,这就是所谓“20%的顾客贡献了80%的销售额”的二八法则。而这批顾客也必然是商家在进行营销活动时需要特别照顾的群体,尤其是在商家前期资源不足的时候。不过需要注意一点,不论采用哪种营销方式,以不对顾客造成骚扰为大前提,否则营销只会产生负面效果。
在RFM模型理论中,最近一次消费时间与截止时间的间隔,消费频率,消费金额是测算客户价值最重要的特征,这三个特征对营销活动的具有十分重要的意义。其中,近一次消费时间与截止时间的间隔是最有力的特征。
2.2 RFM模型结果解读
RFM模型包括3个特征,无法用平面坐标系来展示,所以这里使用三维坐标系进行展示,如图1所示,x轴表示R特征(Recency),y轴表示F特征(Frequency),z轴表示M指标(Monetary)。每个轴一般会用5级表示程度,1为最小,5为最大。需要特别说明的是R特征。在x轴上,R值越大,代表该类客户最近一次消费与截止时间的消费间隔越短,客户R维度上的质量越好。在每个轴上划分5等级,等同于将客户划分成5´5´5=125种类型。这里划分为5级并不是严格的要求,一般是根据实际研究需求和顾客的总量进行划分的,对于是否等分的问题取决于该维度上客户的分布规律。
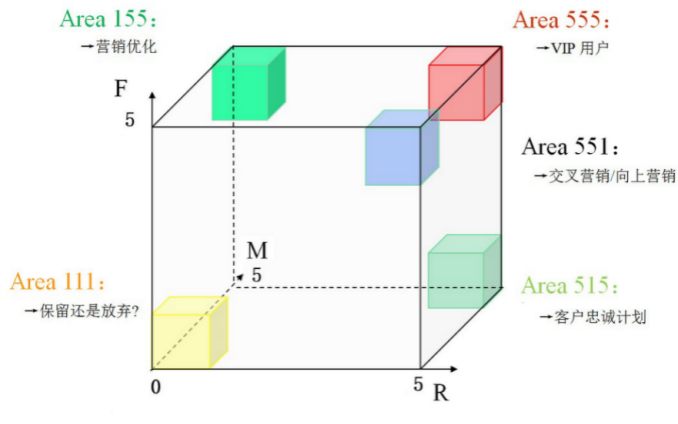
图1 RFM客户价值模型
图 1中,左上角方框的客户RFM特征取值为155。R值是比较小的,说明该类客户最近都没有来店消费,原因可能是最近比较忙,或者对现有的产品或服务不满意,或者是找到了更好的商家。R特征数值变小需要企业管理人员引起重视,说明该类客户可能流失,对企业造成损失。消费频率F很高,说明客户很活跃,经常到商家店里消费。消费金额M值很高,说明该类客户具备一定的消费能力,为店里贡献了很多的营业额。这类客户总体分析比较优质,但是R特征时间近度值较小,其往往是需要营销优化的客户群体。
同理,若客户RFM特征取值为555。则可以判定该客户为最优质客户,即该类客户最近到商家消费过,消费频率很高,消费金额很大。该类客户往往是企业利益的主要贡献者,需要重点关注与维护。
2.3 航空客户价值分析的LRFMC模型
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和。由于航空票价受到运输距离,舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的,比如一位购买长航线,低等级舱位票的旅客与一位购买短航线,高等级舱位票的旅客相比,后者对于航空公司而言价值可能更高。因此这个特征并不适合用于航空公司的客户价值分析⑮。本案例选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C两个特征代替消费金额。此外,航空公司会员入会时间的长短在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一特征。
本案例将客户关系长度L,消费时间间隔R,消费频率F,飞行里程M和折扣系数的平均值C五个特征作为航空公司识别客户价值特征(如表1所示),记为LRFMC模型。

表1 特征含义
原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与LRFMC指标相关的六个属性:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、AVG_DISCOUNT、SEG_KM_SUM、LAST_TO_END。删除与其不相关、弱相关或冗余的属性,例如:会员卡号、性别、工作地城市、工作地所在省份、工作地所在国家、年龄等属性。属性选择的代码如代码清单2所示。
import pandas as pdimport numpy as np# 读取数据清洗后的数据cleanedfile = '../tmp/data_cleaned.csv' # 数据清洗后保存的文件路径airline = pd.read_csv(cleanedfile, encoding='utf-8')# 选取需求属性airline_selection = airline[['FFP_DATE','LOAD_TIME','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]print('筛选的属性前5行为:\n',airline_selection.head())
代码清单2 属性选择
通过代码清单2得到的数据集,如表2所示。
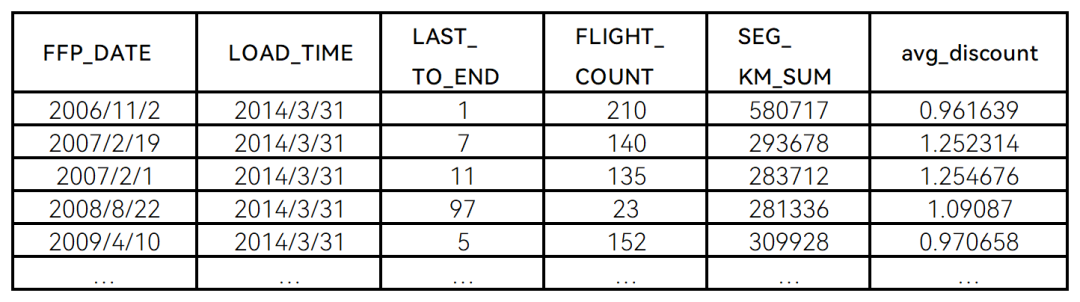
表2 属性选择后的数据集
3. 数据变换
数据变换是将数据转换成“适当的”格式,以适应挖掘任务及算法的需要。本案例中主要采用的数据变换方式有属性构造和数据标准化。
由于原始数据中并没有直接给出LRFMC五个指标,需要通过原始数据提取这五个指标。
1)会员入会时间距观测窗口结束的月数L=会员入会时长,如式(1)所示。

2)客户最近一次乘坐公司飞机距观测窗口结束的月数R=最后一次乘机时间至观察窗口末端时长(单位:月),如式(2)所示。
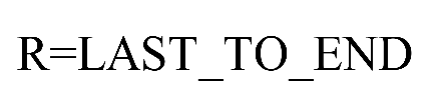
3)客户在观测窗口内乘坐公司飞机的次数F=观测窗口的飞行次数(单位:次),如式(3)所示。

4)客户在观测时间内在公司累计的飞行里程M=观测窗口总飞行公里数(单位:公里),如(4)所示。
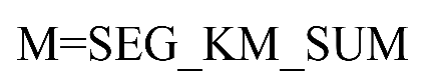
5)客户在观测时间内乘坐舱位所对应的折扣系数的平均值C=平均折扣率(单位:无),如式(5)所示。
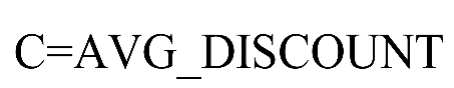
在完成五个指标的数据提取后,对每个指标数据分布情况进行分析,其数据的取值范围如表3所示。从表中数据可以发现,五个指标的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理。

表3 LRFMC指标取值范围
属性构造与数据标准化的代码如代码清单3所示。
# 构造属性LL = pd.to_datetime(airline_selection['LOAD_TIME']) - \pd.to_datetime(airline_selection['FFP_DATE'])L = L.astype('str').str.split().str[0]L = L.astype('int')/30# 合并属性airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis=1)print('构建的LRFMC属性前5行为:\n',airline_features.head())# 数据标准化from sklearn.preprocessing import StandardScalerdata = StandardScaler().fit_transform(airline_features)np.savez('../tmp/airline_scale.npz',data)print('标准化后LRFMC五个属性为:\n',data[:5,:])
代码 3属性构造与数据标准化
标准差标准化处理后,形成ZL、ZR、ZF、ZM、ZC五个属性的数据,如表4所示。
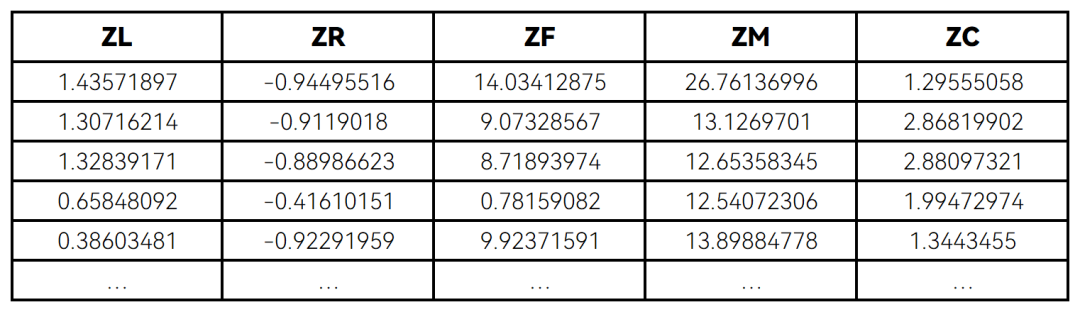
表4 标准化处理后的数据集
06
模型构建
客户价值分析模型构建主要由两个部分构成,第一个部分根据航空公司客户五个指标的数据,对客户作聚类分群。第二部分结合业务对每个客户群进行特征分析,分析其客户价值,并对每个客户群进行排名。
1. 客户聚类
采用K-Means聚类算法对客户数据进行客户分群,聚成五类(需要结合业务的理解与分析来确定客户的类别数量)。
使用scikit-learn库下的聚类子库(sklearn.cluster)可以实现K-Means聚类算法。使用标准化后的数据进行聚类,如代码清单1所示。
import pandas as pdimport numpy as npfrom sklearn.cluster import KMeans # 导入kmeans算法# 读取标准化后的数据airline_scale = np.load('../tmp/airline_scale.npz')['arr_0']k = 5 # 确定聚类中心数# 构建模型,随机种子设为123kmeans_model = KMeans(n_clusters=k,n_jobs=4,random_state=123)fit_kmeans = kmeans_model.fit(airline_scale) # 模型训练# 查看聚类结果kmeans_cc = kmeans_model.cluster_centers_ # 聚类中心print('各类聚类中心为:\n',kmeans_cc)kmeans_labels = kmeans_model.labels_ # 样本的类别标签print('各样本的类别标签为:\n',kmeans_labels)r1 = pd.Series(kmeans_model.labels_).value_counts() # 统计不同类别样本的数目print('最终每个类别的数目为:\n',r1)# 输出聚类分群的结果cluster_center = pd.DataFrame(kmeans_model.cluster_centers_,\columns=['ZL','ZR','ZF','ZM','ZC']) # 将聚类中心放在数据框中cluster_center.index = pd.DataFrame(kmeans_model.labels_ ).\drop_duplicates().iloc[:,0] # 将样本类别作为数据框索引print(cluster_center)
代码清单4 K-meas聚类标准化后的数据
对数据进行聚类分群的结果如表5所示
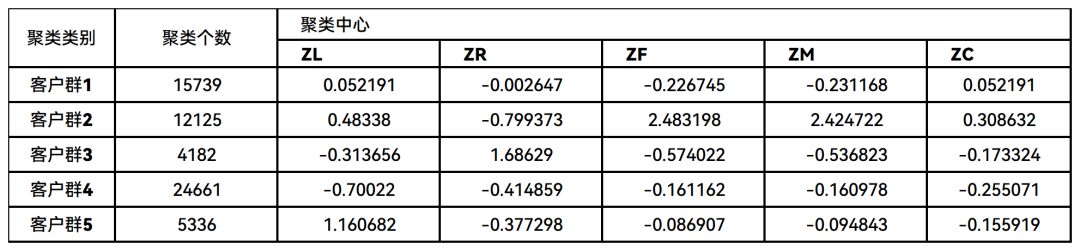
表 5 客户聚类结果
*由于K-Means聚类是随机选择类标号,因此重复此实验得到结果中的类标号可能与此不同;另外由于算法的精度问题,重复实验得到的聚类中心也可能略有不同。
2. 客户价值分析
针对聚类结果进行特征分析,绘制客户分群雷达图,如代码清单2所示。
%matplotlib inlineimport matplotlib.pyplot as plt# 客户分群雷达图labels = ['ZL','ZR','ZF','ZM','ZC']legen = ['客户群' + str(i + 1) for i in cluster_center.index] # 客户群命名,作为雷达图的图例lstype = ['-','--',(0, (3, 5, 1, 5, 1, 5)),':','-.']kinds = list(cluster_center.iloc[:, 0])# 由于雷达图要保证数据闭合,因此再添加L列,并转换为 np.ndarraycluster_center = pd.concat([cluster_center, cluster_center[['ZL']]], axis=1)centers = np.array(cluster_center.iloc[:, 0:])# 分割圆周长,并让其闭合n = len(labels)angle = np.linspace(0, 2 * np.pi, n, endpoint=False)angle = np.concatenate((angle, [angle[0]]))# 绘图fig = plt.figure(figsize=(8,6))ax = fig.add_subplot(111, polar=True) # 以极坐标的形式绘制图形plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 画线for i in range(len(kinds)):ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i])# 添加属性标签ax.set_thetagrids(angle * 180 / np.pi, labels)plt.title('客户特征分析雷达图')plt.legend(legen)plt.show()plt.close
代码清单5 绘制客户分群雷达图
通过代码清单2得到客户分群雷达图,如图2所示。
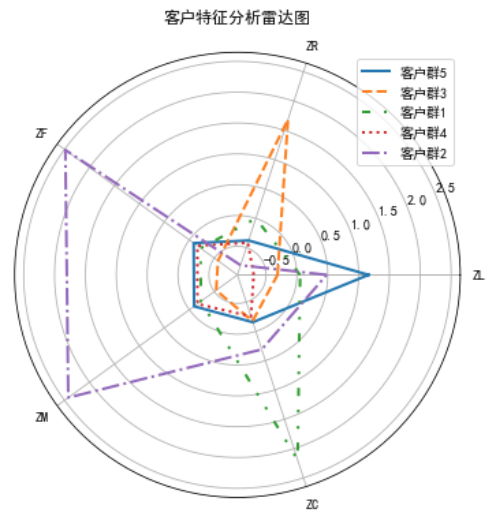
图 2 客户群特征雷达图
结合业务分析,通过比较各个特征在群间的大小对某一个群的特征进行评价分析。其中客户群1在特征C处的值最大,在特征F、M处的值较小,说明客户群1是偏好乘坐高级舱位的客户群;客户群2在特征F和M上的值最大,且在特征R上的值最小,说明客户群2的会员频繁乘机且近期都有乘机记录;客户群3在特征R处的值最大,在特征L、F、M和C处的值都较小,说明客户群3已经很久没有乘机,是入会时间较短的低价值的客户群;客户群4在所有特征上的值都很小,且在特征L处的值最小,说明客户群4属于新入会会员较多的客户群;客户群5在特征L处的值最大,在特征R处的值较小,其他特征值都比较适中,说明客户群5入会时间较长,飞行频率也较高,是有较高的价值的客户群。
总结出每个群的优势和弱势特征,具体结果如表6所示。

表 6 客户群特征描述表
注:正常字体表示最大值,加粗字体表示次大值,斜体字体表示最小值,带下划线的字体表示次小值。
根据以上特征分析的图表,说明不同用户类别的表现特征显著不同。基于该特征描述,本案例定义5个等级的客户类别:重要保持客户,重要发展客户,重要挽留客户,一般客户,低价值客户。每种客户类别的特征如图 3所示。

图 3 客户类别的特征分析
(1) 重要保持客户:
这类客户的平均折扣率(C)较高(一般所乘航班的舱位等级较高),最近乘坐过本公司航班(R)低,乘坐的次数(F)或里程(M)较高。他们是航空公司的高价值客户,是最为理想的客户类型,对航空公司的贡献最大,所占比例却较小。航空公司应该优先将资源投放到他们身上,对他们进行差异化管理和一对一营销,提高这类客户的忠诚度与满意度,尽可能延长这类客户的高水平消费。
(2) 重要发展客户
这类客户的平均折扣率(C)较高,最近乘坐过本公司航班(R)低,但乘坐次数(F)或乘坐里程(M)较低。这类客户入会时长(L)短,他们是航空公司的潜在价值客户。虽然这类客户的当前价值并不是很高,但却有很大的发展潜力。航空公司要努力促使这类客户增加在本公司的乘机消费和合作伙伴处的消费,也就是增加客户的钱包份额。通过客户价值的提升,加强这类客户的满意度,提高他们转向竞争对手的转移成本,使他们逐渐成为公司的忠诚客户。
(3) 重要挽留客
这类客户过去所乘航班的平均折扣率(C),乘坐次数(F)或者里程(M)较高,但是较长时间已经没有乘坐本公司的航班(R)高或是乘坐频率变小。他们客户价值变化的不确定性很高。由于这些客户衰退的原因各不相同,所以掌握客户的最新信息,维持与客户的互动就显得尤为重要。航空公司应该根据这些客户的最近消费时间,消费次数的变化情况,推测客户消费的异动状况,并列出客户名单,对其重点联系,采取一定的营销手段,延长客户的生命周期。
(4) 一般与低价值客户
这类客户所乘航班的平均折扣率(C)很低,较长时间没有乘坐过本公司航班(R)高,乘坐的次数(F)或里程(M)较低,入会时长(L)短。他们是航空公司的一般用户与低价值客户,可能是在航空公司机票打折促销时,才会乘坐本公司航班。
其中,重要发展客户,重要保持客户,重要挽留客户这三类重要客户分别可以归入客户生命周期管理的发展期,稳定期,衰退期三个阶段。
根据每种客户类型的特征,对各类客户群进行客户价值排名,其结果如表7所示。针对不同类型的客户群提供不同的产品和服务,提升重要发展客户的价值,稳定和延长重要保持客户的高水平消费,防范重要挽留客户的流失并积极进行关系恢复。
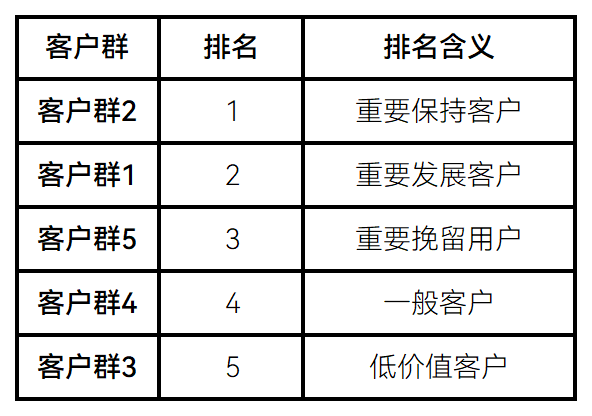
表 7 客户群价值排名
本模型采用历史数据进行建模,随着时间的变化,分析数据的观测窗口也在变换。因此,对于新增客户详细信息,考虑业务的实际情况,该模型建议每一个月运行一次,对其新增客户信息通过聚类中心进行判断,同时对本次新增客户的特征进行分析。如果增量数据的实际情况与判断结果差异大,需要业务部门重点关注,查看变化大的原因以及确认模型的稳定性。如果模型稳定性变化大,需要重新训练模型进行调整。目前模型进行重新训练的时间没有统一标准,大部分情况都是根据经验来决定。根据经验建议:每隔半年训练一次模型比较合适。















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









