







1.平台概述
大模型应用平台是一款专为高校在大模型应用场景下的教学和科研需求设计的知识库问答系统。平台具备便捷性,支持上传常见格式的数据文件,如txt、doc、pdf、md等,并提供简洁明了的操作配置界面,使用户能够轻松搭建和训练AI应用,迅速调用以支持各领域的交互式对话场景。此外,平台还支持可视化的工作流编排,能够满足复杂问答场景的搭建需求。应用场景涵盖多个领域包括:教材知识点和考试试卷生成 、代码智能评阅与辅助代码开发、图像数据标注、信息提取与智能打标、出版社自动校稿机器人 等,通过这些功能,大模型应用平台帮助用户应用先进的大模型技术,极大地提升了教学和科研活动的质量和效率。
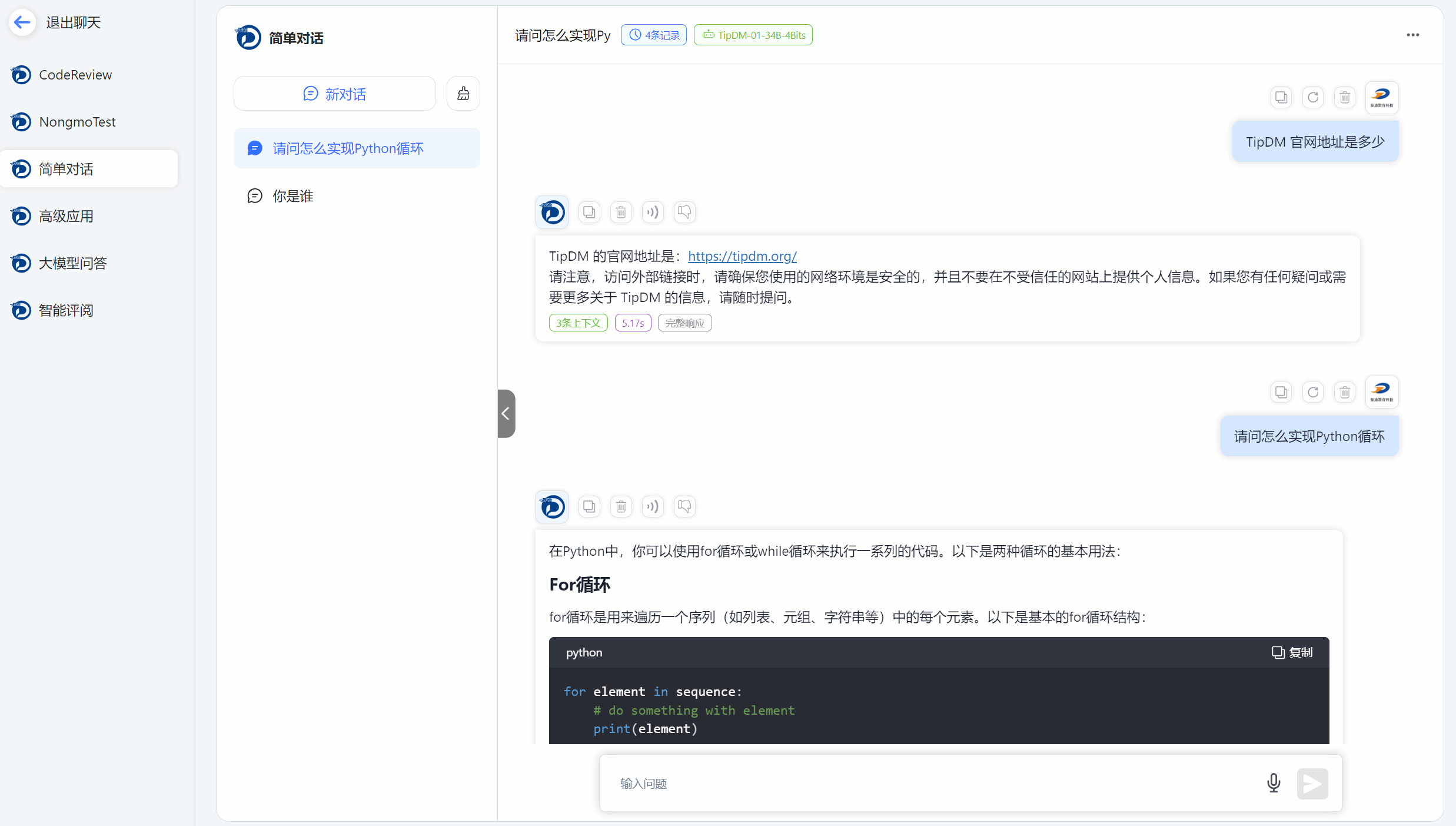
图1 大模型应用平台
2.功能简介

3.产品特色
1.提供应用列表,能够快速调用构建的AI应用,展开对话交互。并提供对话引用搜索功能,能够展示对话所引用的知识库内容,用户能够准确了解对话是否匹配,并对AI应用进行进一步优化
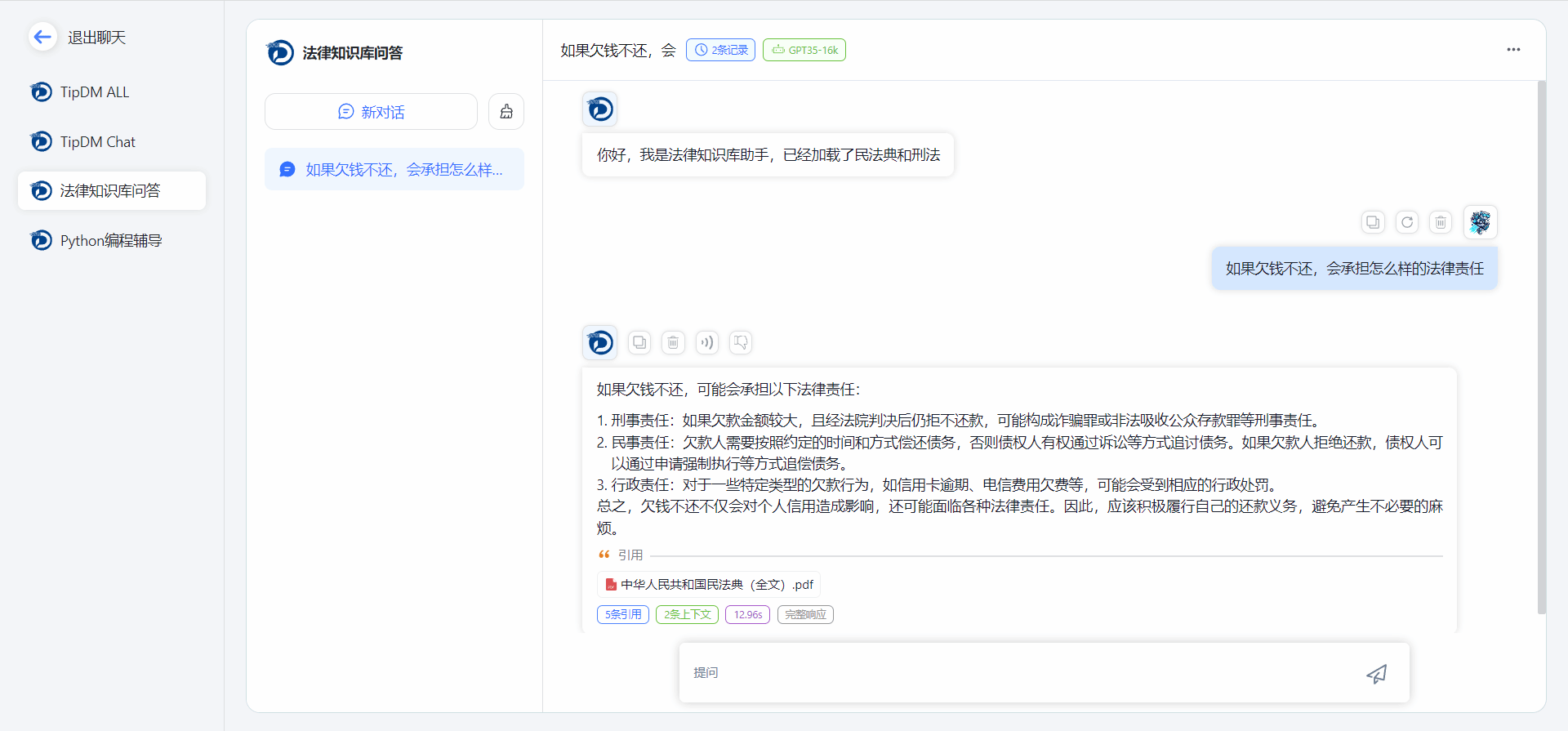
图2 聊天列表
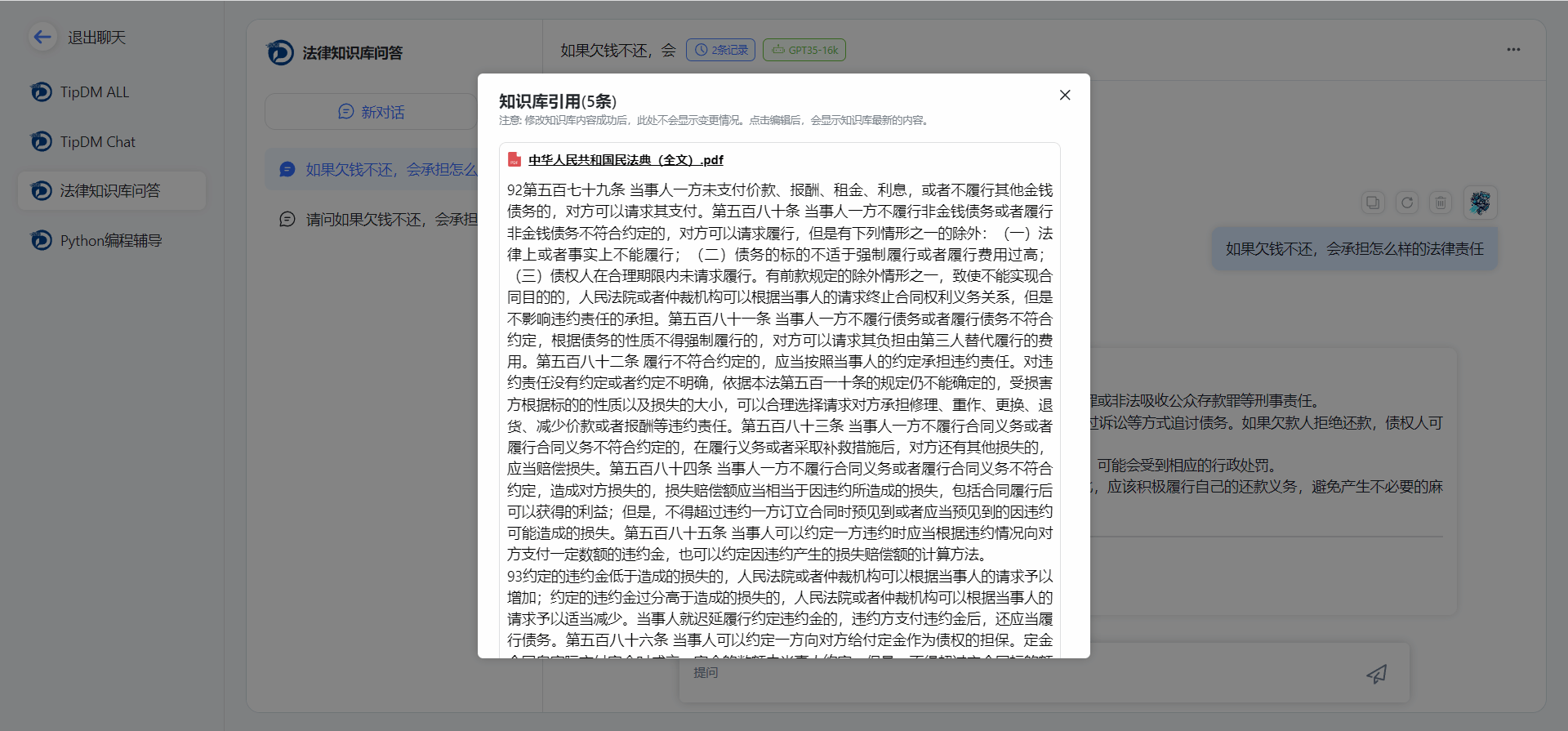
图3 知识库引用
2.支持引用模板,快速完成AI应用创建,满足不同的情形的聊天对话需求。
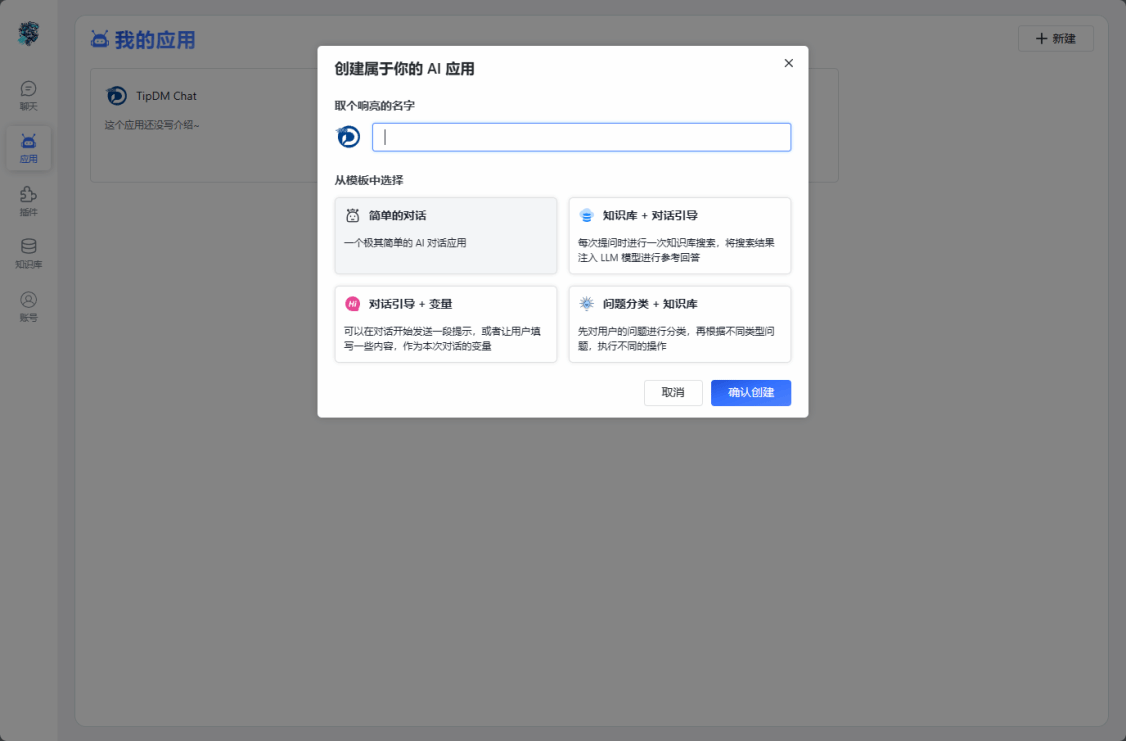
图4 创建AI应用
3.页面配置简单方便,快速调试不同应用的具体使用方式。同时支持AI应用一键分享,其他用户无需登录,通过链接即可快速访问和体验相应的AI应用。
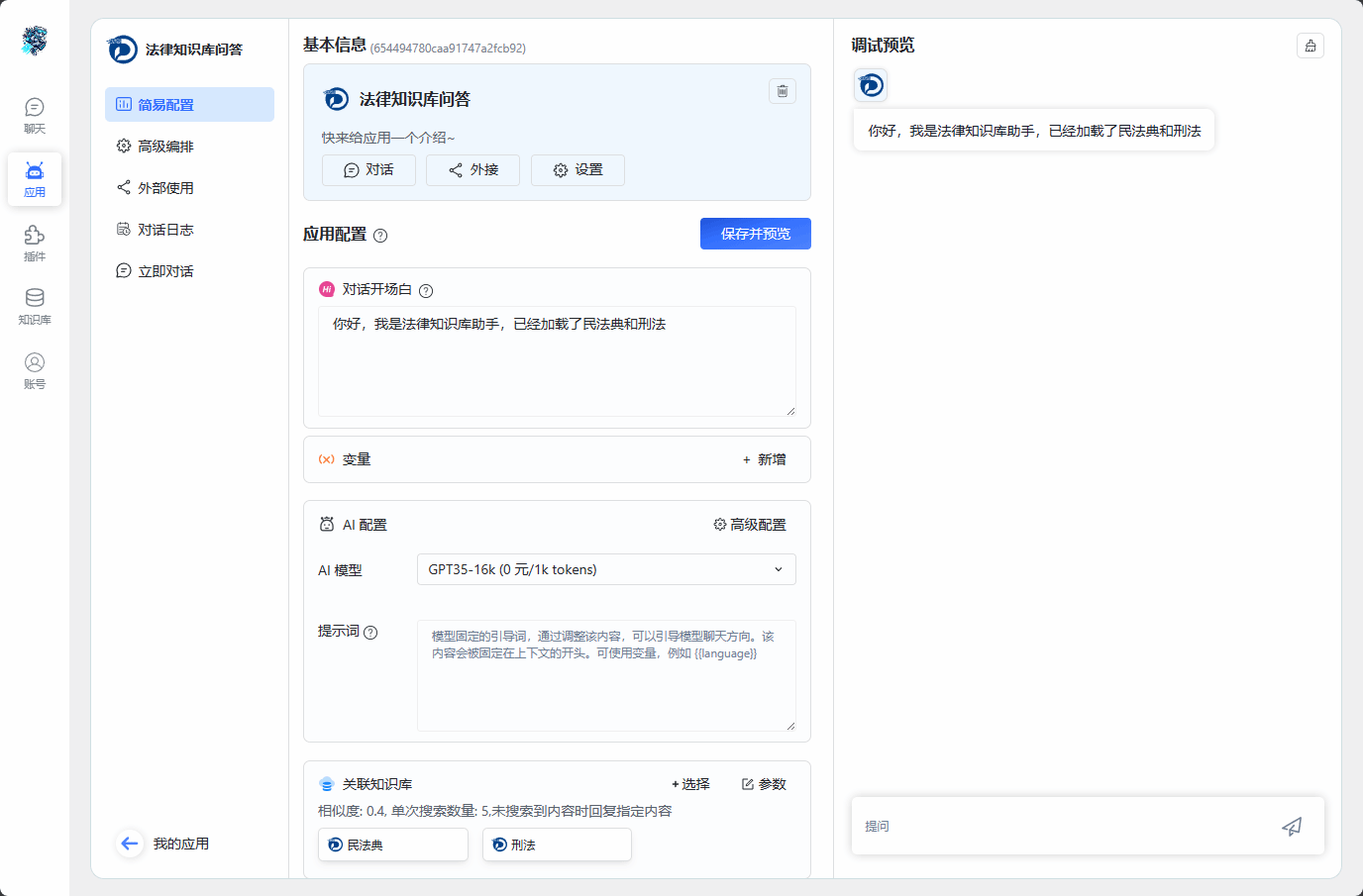
图5 简易配置
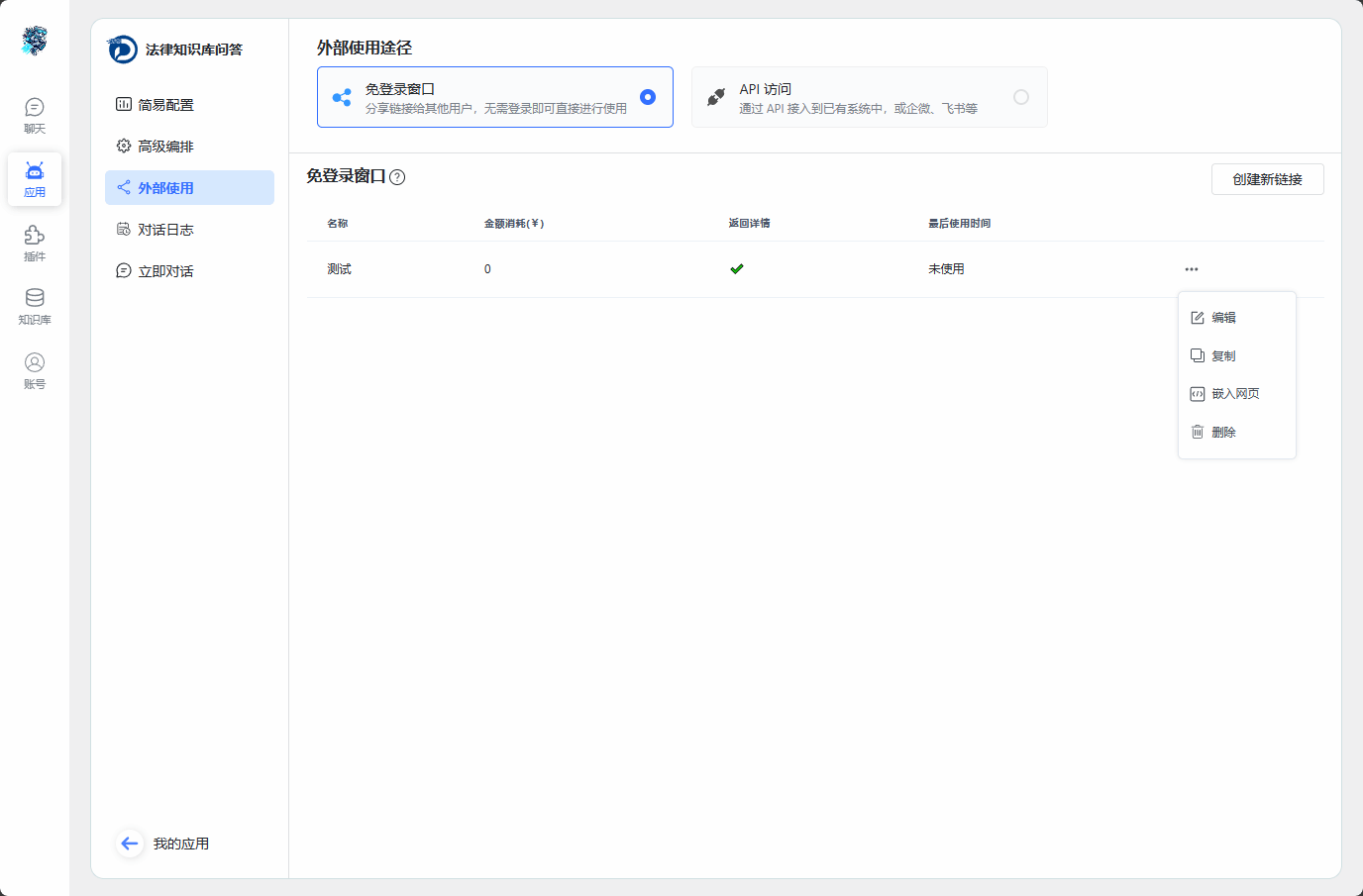
图6 免登录分享
4. 提供多种系统模块及插件模块,用户通过托拉拽即可完成复杂抽象的AI应用场景搭建。
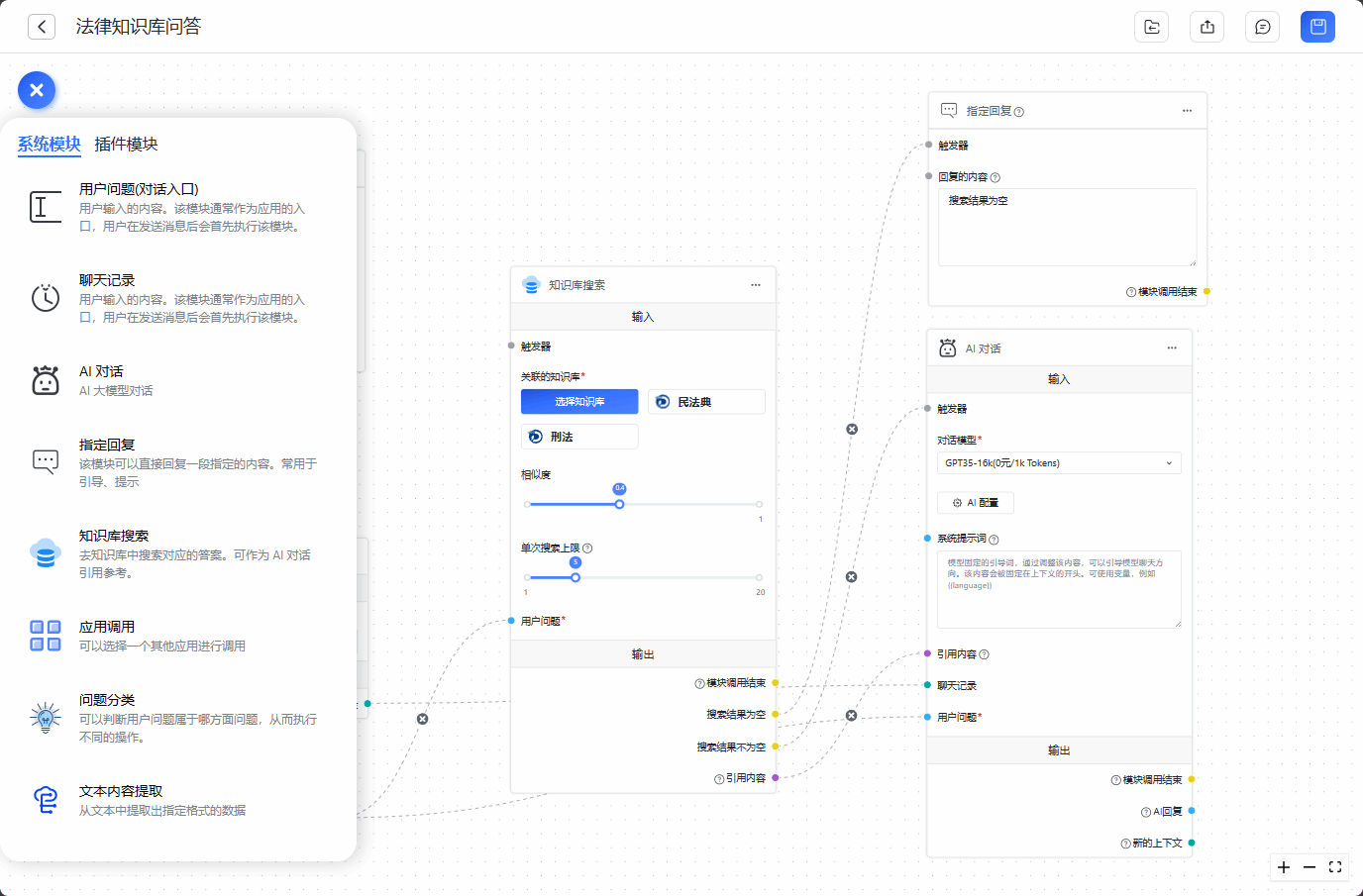
图7 可视化高级编排
5. 提供大模型的知识库搜索测试功能,检测AI应用的交互对话效果。
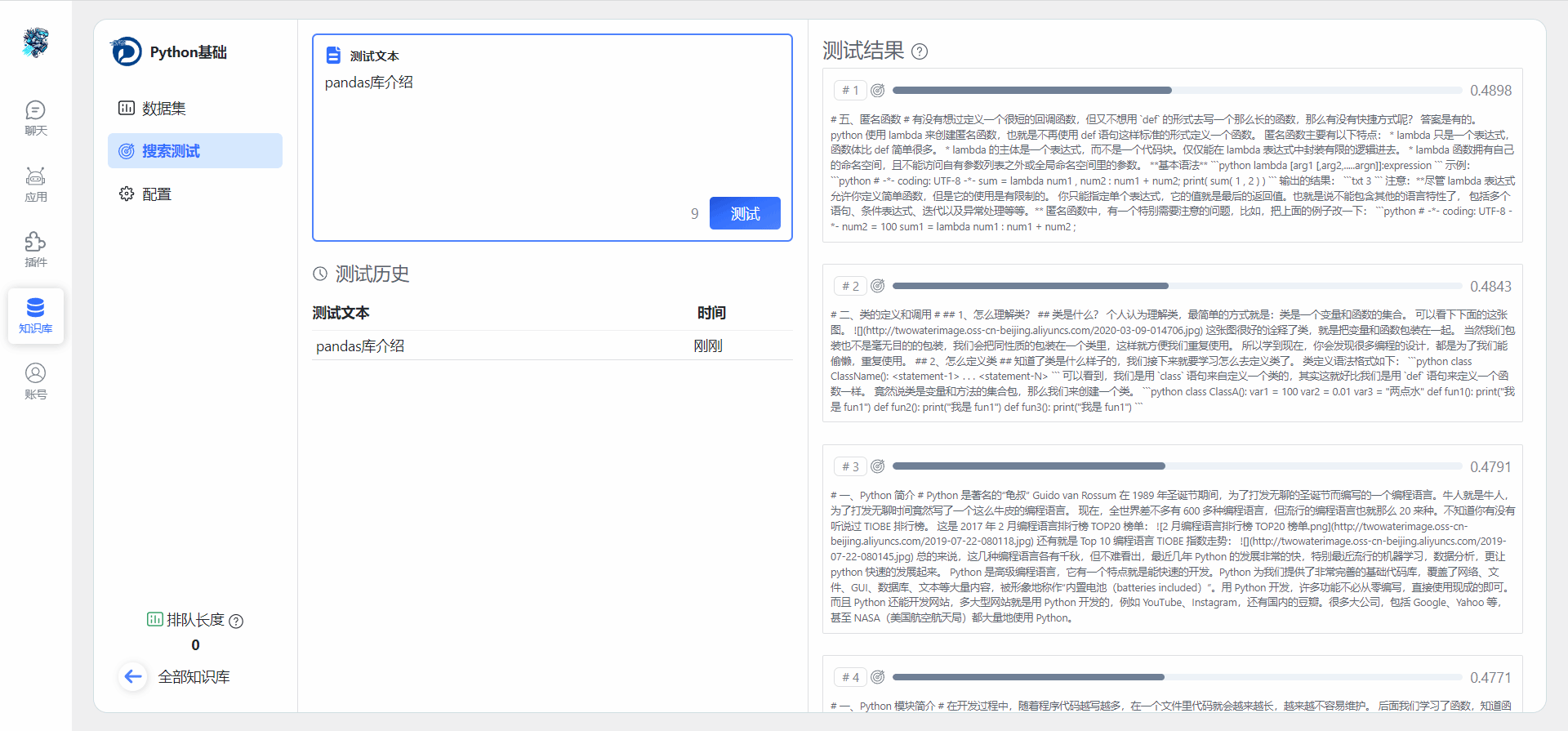
图8 规格管理

















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









