







本来想写整理ARIMA和LSTM一起的作对比的时间时序分析。但是整理完ARIMA之后,发现,东西很多,而且,用起来并不是很理想。不过既然整理了,也就一并贴出来了
数据平稳性与差分法
概念
平稳性就是要求经由样本时间序列所得到的的拟合曲线在未来的一段时间内仍能顺着现有的形态“惯性”延续下去。
平稳性要求序列的均值和方差不发生明显的变化
严平稳与弱平稳
严平稳:表示的分布不随时间的改变而改变;如白噪声(正态)无论怎么取,期望值为0,方差为1;
弱平稳:期望与相关系数(依赖性)不变;未来的某时刻的t的值Xt依赖于他的过去信息,所以需要依赖性
严平稳的条件只是理论上的存在,现实中用得比较多的是宽平稳的条件。
宽平稳也叫弱平稳或者二阶平稳(均值和方差平稳),它应满足:
1.常数均值
2.常数方差
3.常数自协方差
ARIMA 模型对时间序列的要求是平稳型。因此,当你得到一个非平稳的时间序列时,首先要做的即是做时间序列的差分,直到得到一个平稳时间序列。如果你对时间序列做d次差分才能得到一个平稳序列,那么可以使用ARIMA(p,d,q)模型,其中d是差分次数。
保持数据平稳的方法:
差分法:时间序列在t与t-1时刻的差值
AIRMA模型
自回归模型(AR)
描述当前值与历史值之间的关系,用自变量的历史事件数据对自身进行预测
自回归模型必须满足平稳性的要求
p阶自回归过程的公式定义

yt是当前值,μ是常数项,p是阶数,γi是自相关系数,ϵt是误差
自回归模型的限制:
自回归模型是用自身系数来进行预测
必须具有平稳性
必须具有自相关性,如果自相关系数(φi)小于0.5则不宜采用
自回归只适用于预测与自身前期相关的现象
移动平均模型(MA)
移动平均模型关注的是自回归模型中的误差项的累计
q阶自回归过程的公式定义:

自回归移动平均模型(ARMA)
自回归与移动平均的结合
公式定义:
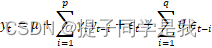
ARIMA(p,d,q)模型全程为差分自回归移动平均模型(Autoregressive Integrated Moving Average Model),AR是自回归,p为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数
原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对他的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
相关函数评估方法
自相关函数ACF(autocorrelation function)
有序的随机变量序列与其自身相比较,反映了统一序列在不同时序的取值之间的相关性
公式:

Pk的取值范围为[-1,1]
偏自相关函数(PACF)(partial autocorrelation function )
对于一个平稳AR(p)模型,求出滞后k自相关系数p(k)时,实际上得到的并不是x(t)与x(t-k)之间单纯的相关关系;
x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、…、x(t-k+1)的影响,而这k-1个随机变量又都和x(t-k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响
剔除了中间k-1个随机变量x(t-1)、x(t-2)、…、x(t-k+1)的干扰之后x(t-k)对x(t)影响的相关程度
ACF还包含了其他变量的影响,而偏自相关系数PACF是严格这两个变量之间的相关性
对比与选择
| 模型 | ACF | PACF |
| AR(p) | 衰减趋于零(几何型或振荡型) | p阶后截尾 |
| MA(q) | q阶后截尾 | 衰减趋于零(几何型或振荡型) |
| ARMA(p,q) | q阶后衰减趋于零(几何型或振荡型) | p阶后衰减趋于零(几何型或振荡型) |
截尾:落在置信区间(95%)内的点都符合改规则
ARIMA建模流程
①将序列平稳(差分法确定d)
②p和q阶数确定:使用ACF与PACF
③建立ARIMA(p,d,q)
模型选择AIC与BIC
为了选择更简单的模型
AIC:赤池信息准则(Akaike Information Criterion,AIC)
AIC=2k-2ln(L)
BIC:贝叶斯信息准则(Bayesian Information Criterion,BIC)
BIC=kln(n)-2ln(L)
k为模型参数个数,n为样本数量,L为似然函数;
在保证模型精度的情况下尽量使得k值越小越好。
pandas时间序列相关操作
时间序列的种类
时间戳(timestamp)
固定周期(period)
时间间隔(interval)
创建相关函数
创建时间date_range
指定开始时间与周期,默认D。H=小时,D=天,M=月

rng= pd.date_range('2023/06/01',periods=10,freq='D')
rng= pd.date_range('2023/06/01', '2023/06/10',freq='D')
过滤时间truncate
指某一日期之前/之后的数据,都不要
time.truncate(before='2023/06/01')
time.truncate(after='2023/06/01')
指定时间的细节
pd.Timestamp('2016-07-10')#Timestamp('2016-07-10 00:00:00')
pd.Timestamp('2016-07-10 10')#Timestamp('2016-07-10 10:00:00')
pd.Timestamp('2016-07-10 10:15')#Timestamp('2016-07-10 10:15:00')
设置时间区间
pd.Period('2016-01')#Period('2016-01', 'M')
pd.Period('2016-01-01')#Period('2016-01-01', 'D')
时间偏移
pd.Timedelta('1 day')#Timedelta('1 days 00:00:00')
pd.Period('2016-01-01 10:10') + pd.Timedelta('1 day')#Period('2016-01-02 10:10', 'T')
pd.Timestamp('2016-01-01 10:10') + pd.Timedelta('1 day')#Timestamp('2016-01-02 10:10:00')
pd.Timestamp('2016-01-01 10:10') + pd.Timedelta('15 ns')#Timestamp('2016-01-01 10:10:00.000000015')
# 指定索引
rng = pd.date_range('2016-01-01', periods = 10, freq = 'D')
pd.Series(range(len(rng)), index = rng)
数据重采样
时间数据由一个频率转换到另一个频率
降采样:
ts.resample('M').sum()#数据降采样,降为月,指标是求和
ts.resample('3D').sum()#数据降采样,降为3天
ts.resample('M').mean()#数据降采样,降为月,指标是求平均
升采样:
采用插值方法
①ffill---空值取前面的值
ts.resample('D').ffill(1)#数字表示要对多少个空数进行填充
②bfill---空值取后面的值
ts.resample('D').bfill(1) #数字表示要对多少个空数进行填充
③interpolate---线性取值
ts.resample('D').interpolate('linear')#线性拟合填充
滑动窗口
获得窗口
r=ts.rolling(window = 10)
计算窗口
#r.mean()0
#r.max()
#r.median()
#r.std()
#r.skew()倾斜度
#r.sum()
#r.var()
大致上内容如上。下面插入一些我整理好的代码供参考
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.pylab import style
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import statsmodels.api as sm
style.use('ggplot')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
stockFile = 'DataFile/T1test.csv'
stock = pd.read_csv(stockFile, index_col=0, parse_dates=[0]) # 将索引index设置为时间,parse_dates对日期格式处理为标准格式。
# print(stock.head(10))
# 降采样
stock_week = stock['value'].resample('min').mean()
stock_train = stock_week['2023-05-05 07:30':'2023-05-05 19:00']
# print(stock_train)
# stock_train.plot(figsize=(12,8))
# plt.legend(bbox_to_anchor=(1.25, 0.5))
# plt.title("Stock Close")
# sns.despine()
# plt.show()
#拟合模型做季节性数据的分析
# model='additive'代表是加法模式,
#extrapolate_trend='freq'表示trend 、resid频率会从最近点开始,并且会对最近点的缺失值进行填充
# #更多参数设置请参考官方文档:https://www.statsmodels.org/stable/generated/statsmodels.tsa.seasonal.seasonal_decompose.html
# decomposition = sm.tsa.seasonal_decompose(stock_train, model='additive', extrapolate_trend='freq')
# plt.rc('figure',figsize=(12,8))
# fig = decomposition.plot()
# plt.show()
# 做一阶差分
# stock_diff = stock_train.diff()
# stock_diff = stock_diff.dropna()
# plt.figure()
# plt.plot(stock_diff)
# plt.title('一阶差分')
# plt.show()
# 平稳性检验---单位根
# from statsmodels.tsa.stattools import adfuller
# result = adfuller(stock_diff)
# # print(result)
# if result[1] > 0.05:
# print('概率p值为:%s,数据序列不平稳' % (result[1]))
# else:
# print('概率p值为:%s,数据序列平稳' % (result[1]))
#
# # 白噪声检验---LB检验
# from statsmodels.stats.diagnostic import acorr_ljungbox as lb_test
# p = lb_test(stock_diff, lags=1).iloc[0, 1]
# if p < 0.05:
# print('序列为非白噪声序列,p值为:%s' % p)
# else:
# print('序列为非白噪声序列,p值为:%s' % p)
#
# # 绘制ACF
# acf = plot_acf(stock_diff, lags=10)
# plt.title("ACF")
# plt.show()
#
# # 绘制PACF
# pacf = plot_pacf(stock_diff, lags=10, method='ywm')
# plt.title("PACF")
# plt.show()
# 训练模型
model = ARIMA(stock_train, order=(2, 1, 5), freq='min')
result = model.fit()
print(result.summary())#统计出ARIMA模型的指标
pred = result.predict('2023-05-05 19:00', '2023-05-05 23:59', dynamic=True, typ='levels') # 预测,指定起始与终止时间。预测值起始时间必须在原始数据中,终止时间不需要
print(pred)
#数据展示
plt.figure(figsize=(6, 6))
plt.xticks(rotation=45)
plt.plot(pred)
plt.plot(stock_train)
plt.show()代码中有大量屏蔽了的代码,是因为在运行过程中需要调试、看数据,所以用上了的~
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









