









关键词
对比学习, 图像风格转换
问题简述
Motiviation
这是篇卖“问题”的文章。作者指出视频风格转换类方法目前还没有很好的解决"帧间不一致性"(Temporal Inconsistency或者Flicker Artifacts)问题,这导致转化后的视频总是特别“闪”,这里可以看一下作者提供的演示Demo,有个直观的感受。
为什么会这样呢?作者认为是之前的方法太重视“全局约束”(global constraint),虽然全局约束确保了图像整体风格转换的稳定性上,当前帧和后续帧在风格转换的效果上不会出现大面积的突变;但是现有的方法往往忽视了局部噪声的影响,导致迁移出来的效果虽然忠实于内容,但是却总感觉很“跳”(参考作者提供的演示demo的50秒的结果),或者纵有一层透明且蠕动的覆盖层(演示demo的35秒的结果);那很自然的想法就是直接在连续帧对应位置加上一些局部约束,这就不可避免的需要视频类数据来训练模型。这时候但本文最大的噱头就来了,本文提出的这个CCP损失,能在仅依赖单帧信息的前提下,实现帧间的一致性。
CCP损失
为什么不需要视频数据?
我们先看下图:
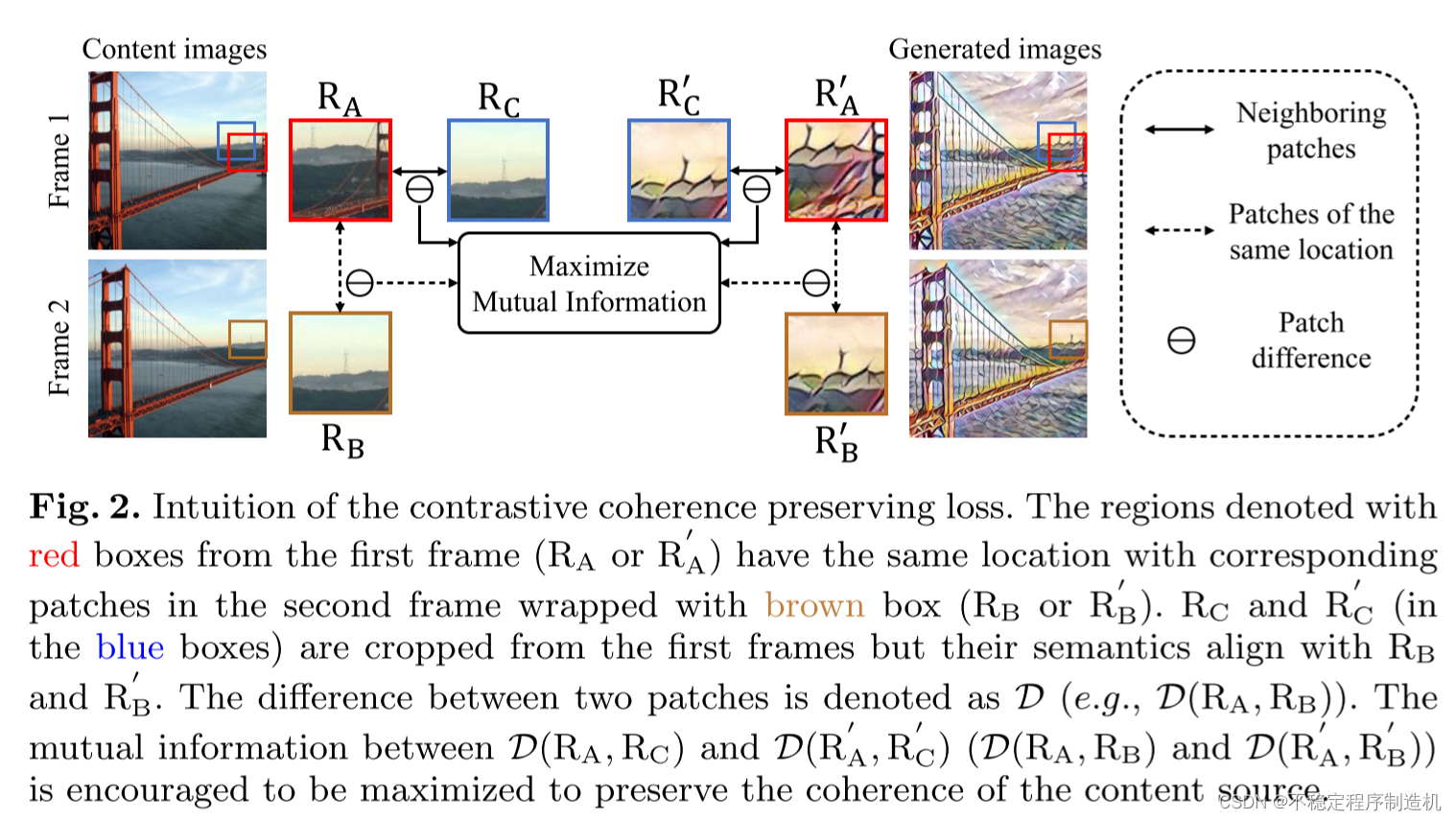
R A R_A RA与 R B R_B RB是连续两帧相同位置的两个Patch,如果这个区域没有运动的话,那么 R A R_A RA与 R B R_B RB在“内容”(不考虑噪声)上应该是完全一致的;而如果有运动的话,它们俩的内容会有一些差异。但是作者提出了一个假设:在两帧图像间隔的时间差 Δ t \Delta t Δt 足够小的前提下,在 R A R_A RA的附近相邻Patch中能找到一个 R C R_C RC,使其在内容上与 R B R_B RB完全一致。作者正是通过这种方式,将帧间的Patch对应关系“压缩”到了单帧图像内的Patch关系。
如何解决时序不一致问题?
作者觉得想要生成迁移结果具有较好的时序一致性,需要满足一个限制:
lim
Δ
t
→
0
D
(
C
t
+
Δ
t
,
C
)
≃
D
(
G
t
+
Δ
t
,
G
)
(1)
\lim_{\Delta t \rightarrow 0} D(C_{t+\Delta t}, C) \simeq D(G_{t+\Delta t}, G) \tag{1}
Δt→0limD(Ct+Δt,C)≃D(Gt+Δt,G)(1)
式中,
D
(
a
,
b
)
D(a,b)
D(a,b) 代表a与b之间的差异,
C
C
C 与
G
G
G 则分别代表这内容(Content)与迁移后结果(Generated); 作者特别注明了,这个限制对于全局来说可能太过于严格,但是从局部来看是能够满足的(因为局部上的运动通常体现为“平移”和“旋转”);也正是基于这个假设,作者提出了CCP损失(Contrastive Coherence Preserving):

- 先将内容图像(Content)和生成后的图像(Generated)分别喂给一个训练好(fixed)的Encoder提取特征,分别生成 C f C_f Cf, G f G_f Gf;
- 在 G f G_f Gf 中随机采样得到N个向量(上图中 G f G_f Gf 的红色点),记作 { G a x ∣ x ∈ { 1 , . . . , N } } \{{G_{a}^{x}| x \in \{1,...,N\}}\} {Gax∣x∈{1,...,N}} ;
- 对于每个 G a x G_{a}^{x} Gax ,取其8个相邻的 向量(上图中 G f G_f Gf 的蓝色点),记作 { G a x , y ∣ y ∈ { 1 , . . . , 8 } } \{{G_{a}^{x,y}| y \in \{1,...,8\}}\} {Gax,y∣y∈{1,...,8}} ;
- 在 C f C_f Cf 上按照步骤2和步骤3进行采样,得到 { C a x ∣ x ∈ { 1 , . . . , N } } \{{C_{a}^{x}| x \in \{1,...,N\}}\} {Cax∣x∈{1,...,N}} 和 { C a x , y ∣ y ∈ { 1 , . . . , 8 } } \{{C_{a}^{x,y}| y \in \{1,...,8\}}\} {Cax,y∣y∈{1,...,8}}
- d g x , y = G a x ⊖ G a x , y , d c x , y = C a x ⊖ C a x , y d_{g}^{x,y}=G_{a}^{x} \ominus G_{a}^{x,y},d_{c}^{x,y}=C_{a}^{x} \ominus C_{a}^{x,y} dgx,y=Gax⊖Gax,y,dcx,y=Cax⊖Cax,y, ⊖ \ominus ⊖代表向量减法;
为了满足式(1), 最暴力的做法就是让 d g x , y d_{g}^{x,y} dgx,y去直接拟合 d c x , y d_{c}^{x,y} dcx,y。但这会导致模型偷懒,逐渐让 G f G_f Gf越来越近似于 C f C_f Cf,就起不到风格迁移地作用了。因此,作者在这里引入了对比学习的思想,按照上图中“黄色线”地方式来构建正样本对,“藏青色线”来构建负样本对,通过InfoNCE损失来拉近 d g x , y d_{g}^{x,y} dgx,y与 d c x , y d_{c}^{x,y} dcx,y的距离;
总结
卖问题的,个人觉得有亮点,但拼凑的痕迹也很重;
- 最大的亮点就是基于作者本身大胆的想象力,尝试用单帧去解决时序不一致问题,感觉很有意思;
缺点: - “故事”的立意很新颖,但是讲的总觉得不是很清楚,某些部分只是轻轻一点,让人有点毛不着头脑;
- 引入对比学习的原因没讲清楚,有强行缝合的嫌疑;
参考文献
本文基本均为原创















 1572
1572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









