







工作学习中,没有比图表更好的东西了(虽然很多人在嘲笑PPT),尤其是描述精准的图表。当你想画图说明一个结构或一个流程时,必须对其已经充分理解。而在讲解一张图时,也必须对其有基本的理解。这真的不简单,反正对我来说是这样。关于Linux Storage架构,就有一张描述很精准的图,“Linux Storage Stack Diagram”。这张图总结的实在是太好了,Storage涉及的模块都有描述,让学习者能清晰的了解复杂的系统。本文试图对该图的各部分做个简介,但不会涉及具体的实现。
https://www.thomas-krenn.com/...
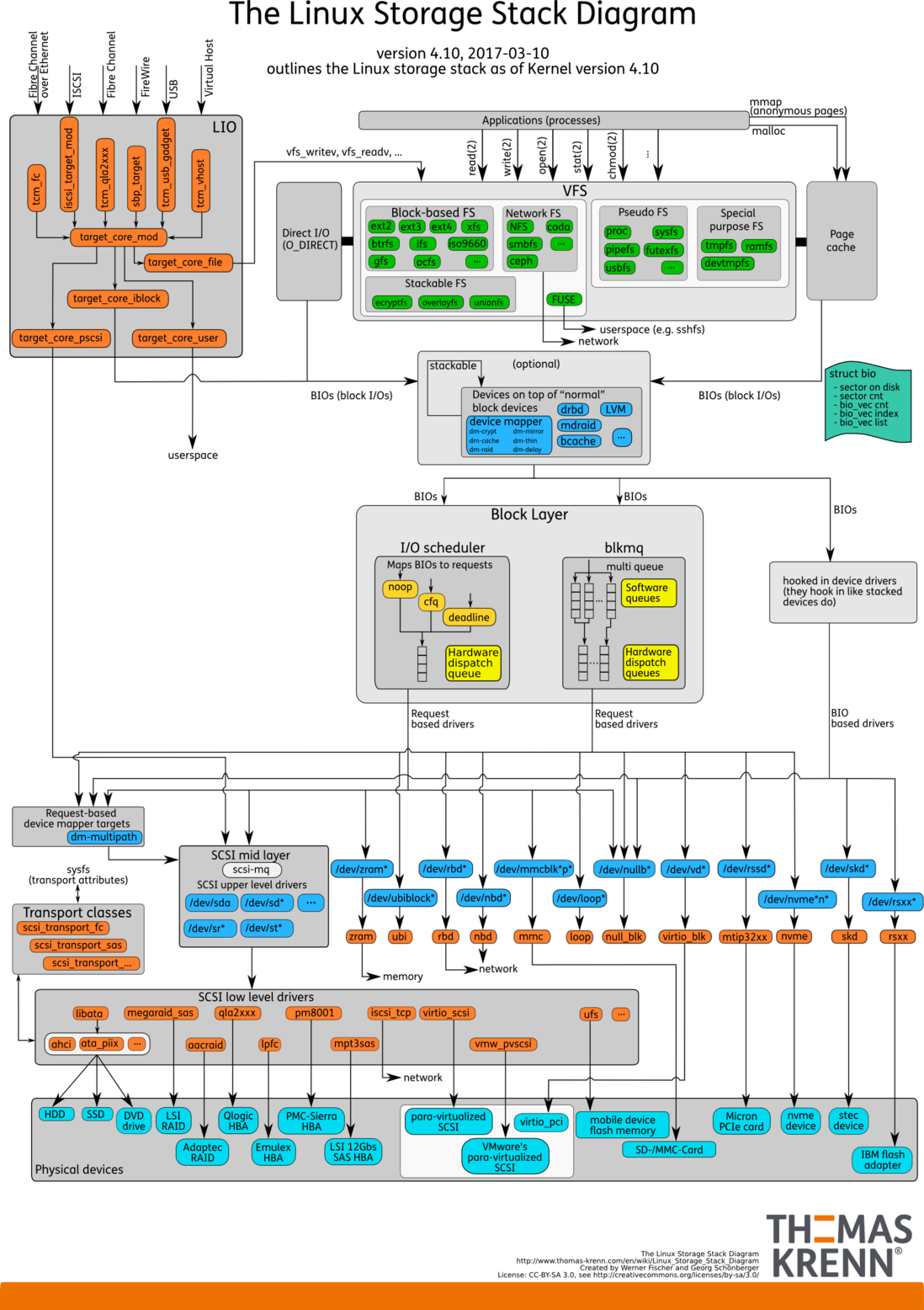
图中使用颜色来区分不同的组成部分。
- 天蓝色:硬件存储设备。
- 橙色:传输协议。
- 蓝色:Linux系统中的设备文件。
- 黄色:I/O调度策略。
- 绿色:Linux系统的文件系统。
- 蓝绿色:Linux Storage操作的基本数据结构BIO。
文件系统
VFS
VFS是Linux内核提供的一个虚拟文件系统层。VFS提供给用户层一些标准的系统调用来操作文件系统,如open()、read()、write()等,让用户态应用无需关心底层的文件系统和存储介质。同时VFS还要对底层文件系统进行约束,提供统一的抽象接口和操作方式。
底层文件系统
Linux支持的文件系统众多,大致可以分为以下几类。
- 磁盘文件系统:基于物理存储设备的文件系统,用来管理设备的存储空间,如ext2、ext4、xfs等。
- 网络文件系统:用于访问网络中其他设备上的文件,如NFS、smbfs等。网络文件系统的目标是网络设备,所以它不会调用系统的Block层。
- 堆栈式文件系统:叠加在其他文件系统之上的一种文件系统,本身不存储数据,而是对下层文件的扩展,如eCryptfs,Wrapfs等。
- 伪文件系统:因为并不管理真正的存储空间,所以被称为伪文件系统。它组织了一些虚拟的目录和文件,通过这些文件可以访问系统或硬件的数据。它不是用来存储数据的,而是把数据包装层文件用来访问,所以不能把伪文件系统当做存储空间来操作。如proc、sysfs等。
- 特殊文件系统:特殊文件系统也是一种伪文件系统,它使用起来更像是一个磁盘文件系统,但读写是内存而不是磁盘设备。如tmpfs、ramfs等。
- 用户文件系统:也叫做FUSE。它提供一种方式可以让开发者在用户空间实现文件系统,而不需要修改内核。这种方式更加灵活,但效率会更低。FUSE直接面向的是用户文件系统,也不会调用Block层。
Block Layer
Block Layer是Linux Storage系统中的中间层,连接着文件系统和块设备。它将上层文件系统的读写请求抽象为BIOs,通过调度策略将BIOs传输给设备。Block Layer包含图中的蓝绿色、黄色和中间BIOs传输过程。
Page cache
Linux系统在打开文件时可以通过O_DIRECT标识来却别是否使用Page cache。当带有O_DIRECT时,I/O读写会绕过cache,直接访问块设备。否则,读写需要通过Page cache进行,Page cache的主要行为如下。
- 读数据时,如果访问的页在Page cache中(命中),则直接返回页。
- 读数据时,如果访问的页不在Page cache中(缺失),则产生缺页异常。系统会创建一个缓存页,将访问的地址缓存到这个页中。上层会再次读取,发生cache命中。
- 写数据时,如果cache命中,则将数据写到缓存页中。
- 写数据时,如果cache缺失,则产生缺页异常,系统创建缓存页。上层再次写入,发生cache命中。
- 当Page cache中的一个缓存页被修改时,会标记为dirty。上层调用sync或pdflush进程会将脏页写回到磁盘中。
BIO
BIO代表对Block设备的读写请求,在内核中使用一个结构体来描述。
struct bvec_iter {
sector_t bi_sector; // 设备地址,以扇区(512字节)为单位
unsigned int bi_size; // 传输数据的大小,byte
unsigned int bi_idx; // 当前在bvl_vec中的索引
unsigned int bi_bvec_done; // 当前bvec中已经完成的数据大小,byte
};
struct bio {
struct bio *bi_next; // request队列
struct block_device *bi_bdev; // 指向block设备
int bi_error;
unsigned int bi_opf; // request标签
unsigned short bi_flags; // 状态,命令
unsigned short bi_ioprio;
struct bvec_iter bi_iter;
unsigned int bi_phys_segments; // 物理地址合并后,BIO中段的数量
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size; // 第一个可合并段的大小
unsigned int bi_seg_back_size; // 最后一个可合并段的大小
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io; // BIO结束时的回调函数,一般用于通知调用者该BIO的完成情况
......
unsigned short bi_vcnt; // bio_vec的计数
unsigned short bi_max_vecs; // bvl_vecs的最大数量
atomic_t __bi_cnt; // 使用计数
struct bio_vec *bi_io_vec; // vec list的指针
struct bio_set *bi_pool;
......
};
一个BIO构建完成后,就可以通过generic_make_request()来创建传输Request,将Request加入到请求队列中。请求队列在内核中有结构体request_queue来描述,它包含一个双向请求链表以及相关控制信息。请求链表中每一项都是一个Request,Request由BIOs组成,BIO中又可能包含不同的Segment。因为一个BIO只能连续的磁盘块,但一个Request可能不连续的磁盘块,所以一个Request可能包含一个或多个BIOs。尽管BIO中的磁盘块是连续的,但它们在内存中可能是不连续的,所以BIO中可能包含几个Segments。
Scheduler
读写数据组织成请求队列后,就是访问磁盘的过程,这个过程由IO调度完成。BIOs访问的指定的磁盘扇区,首先要进行寻址的操作。寻址就是定位磁盘磁头到特定块上的某个位置,这个过程相对来说很慢。为了优化寻址操作,内核既不会简单地按请求接收次序,也不会立即将其提交给磁盘,而是在提交前,先执行名为合并与排序的预操作,这种预操作可以极大地提高系统的整体性能。这就是IO调度需要完成的工作。
当前内核中,支持两种模式的IO调度器:single-queue和multi-queue。single-queue在图中标识为“I/O Scheduler”,multi-queue标识为blkmq。二者应该都是Scheduler,只是请求的组织方式不同。
single-queue通过合并和排序来减少磁盘寻址时间。合并指将多个连续请求合成一个更大的IO请求,以便充分发挥硬件性能。排序使用电梯调度,将整个请求队列将按扇区增长方向有序排列。排列的目的不仅是为了缩短单独一次请求的寻址时间,更重要的优化在于,通过保持磁盘头以直线方向移动,缩短了所有请求的磁盘寻址的时间。目前single-queue使用的调度策略包括:noop、deadline、cfq等。
- Noop:IO调度器最简单的算法,将IO请求放入队列中并顺序的执行这些IO请求,对于连续的IO请求也会做相应的合并。
- Deadline:保证IO请求在一定时间内能够被服务,避免某个请求饥饿。
- CFQ:即绝对公平算法,试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。
早先的内核只有single-queue,当时存储设备主要时HDD,HDD的随机寻址性能很差,single-queue就可以满足传输需求。当SSD发展起来后,它的随机寻址性能很好,传输的瓶颈就转移到请求队列上。结合多核CPU,multi-queue被设计出来。multi-queue为每个CPU core或socket配置一个Software queue,这也解决了single-queue中多核锁竞争的问题。如果存储设备支持并行多个Hardware dispatch queues,传输性能又会大幅度提升。目前multi-queue支持的调度策略包括:mq-deadline、bfq、kyber等。
Block设备
设备文件
设备文件是Linux系统访问硬件设备的接口,驱动程序将硬件设备抽象为设备文件,以便应用程序访问。设备驱动加载时在/dev/下创建设备文件描述符,如果是Block设备,同时会创建一个软链接到/dev/block/下,并根据设备号来命名。图中将Block设备分为以下几类。
- 逻辑设备:图中的“Devices on top of "normal" block devices",使用Device Mapper将物理块设备进行映射。通过这种映射机制,可以根据需要实现对存储资源的管理。包括LVM、DM、bcache等。
- SCSI设备:使用SCSI标准的设备文件,包括sda(硬盘)、sr(光驱)等。
- 其他块设备:每一种块设备都有自己的传输协议。一类代表真正的硬件设备,如mmc、nvme等。另一类表示虚拟的块设备,如loop、zram等。
传输协议
图中橙色部分表示了Block设备所依赖的技术实现,可能是硬件规范的软件实现,也可能是一种软件架构。图中把SCSI和LIO单独圈出来,因为这两部分相对比较复杂。SCSI包含的硬件规范很多,最常用的是通过libata来访问HDD和SSD。
LIO(Linux-IO)是基于SCSI engine,实现了SCSI体系模型(SAM)中描述的SCSI Target。LIO在linux 2.6.38后引入内核,其支持的SAN技术包括Fibre Channel、FCoE、iSCSI、iSER 、SRP、USB等,同时还能为本机生成模拟的SCSI设备,以及为虚拟机提供基于virtio的SCSI设备。LIO使用户能够使用相对廉价的Linux系统实现SCSI、SAN的各种功能,而不用购买昂贵的专业设备。可以看到LIO的前端是Fabric模块(Fibre Channel、FCoE、iSCSI等),用来访问模拟的SCSI设备。Fabric模块就是实现SCSI命令的传输协议,例如iSCSI技术就是把SCSI命令放在TCP/IP中传输,vhost技术就是把SCSI命令放在virtio队列中传输。LIO的后端实现了访问磁盘数据的方法。FILEIO通过Linux VFS来访问数据,IBLOCK访问Linux Block设备,PSCSI 直接访问SCSI设备,Memory Copy RAMDISK用来放访问模拟SCSI的ramdisk。
硬件设备
图中天蓝色部分,就是实际的硬件存储设备。其中virtio_pci、para-virtualized SCSI、VMware's para-virtualized scsi是虚拟化的硬件设备。
















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









