






目录
homework for classification
原课程是不让用sklearn写的.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
x_train = pd.read_csv(r"C:\Users\dell\Desktop\机器学习\DL2020\data\hw2\data\X_train")
y_train = pd.read_csv(r"C:\Users\dell\Desktop\机器学习\DL2020\data\hw2\data\Y_train")
df_x = np.array(x_train.loc[:, :]) # 这样数据中就没有列标签了
df_y = np.array(y_train.loc[:, :])
df_x = df_x[:, 1:] # 这样数据中就没有行标签和没用的id了
df_y = df_y[:, 1:]
# print(x_train.head(10))
# print(y_train.head(10))
# print(x_train.shape)
# print(y_train.shape)
# print(df_x[0:10, :]) 查看删干净了没有
# print(df_y[0:10, :])
std = StandardScaler()
std.fit_transform(df_x)
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size=0.25)
lr = LogisticRegression()
lr.fit(x_train, y_train)
y_predict = lr.predict(x_test)
score = lr.score(x_test, y_test)
print(score)
print("召回率:", classification_report(y_test, y_predict))
下面是损失函数和梯度下降函数
def _cross_entropy_loss(y_pred, Y_label):
# This function computes the cross entropy.
#
# Arguements:
# y_pred: probabilistic predictions, float vector
# Y_label: ground truth labels, bool vector
# Output:
# cross entropy, scalar
cross_entropy = -np.dot(Y_label, np.log(y_pred)) - np.dot((1 - Y_label), np.log(1 - y_pred))
return cross_entropy
def _gradient(X, Y_label, w, b):
# This function computes the gradient of cross entropy loss with respect to weight w and bias b.
y_pred = _f(X, w, b)
pred_error = Y_label - y_pred
w_grad = -np.sum(pred_error * X.T, 1)
b_grad = -np.sum(pred_error)
return w_grad, b_grad
Backpropagation
purpose
我们一开始的目的是求损失函数对变量w的梯度。
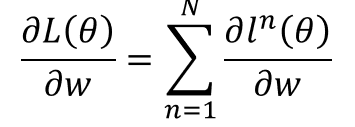
我们可以将这个偏微分看成计算下面两个式子
前面的是正向传播,后者是反向传播:
正向传播就是改路径的输入值。
而反向传播的计算需要一直往后推。

process
这是正向传播的求解过程

这是反向传播的求解过程

如果我们把反向传播看成倒着的正向传播话,也就是两个反向的输入值的乘积组成了损失函数对它w的微分。如下所示。

Tips for training DNN
Relu
一个代替Sigmoid的函数,可以解决gradient vanish的问题。也就是前面输入值的影响到面越来越小的问题。

Maxout
maxout 可以让神经网络自己学习核函数
Relu也可以用是maxout特殊形式的一种

Regularization
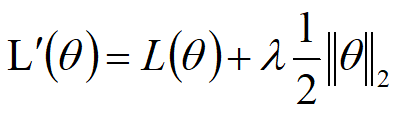
Drop out
drop out 是针对测试集结果差的情况,而不是训练集差就能用drop out 是集成算法的一种
















 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









