









方法出自Google文章Detecting Near-Duplicates for Web Crawling(2007 WWW)。
Google要解决的问题是当crawler得到一个网页时,如何判断该网页是否是已经存在的或存在相似的。
解决这个问题分为两步,第一是对网页的内容进行hash,得到网页的“指纹”;第二是给定某个网页的指纹,如果快速的在数据库中找到相似的指纹。
解决第一个问题使用的hash方法是SimHash,SimHash与一般的hash方法最大的不同是对于相似的两个对象,使用SimHash得到的hash结果(二进制串)也是相似的,即海明距离比较小。
SimHash:
1. 提取网页的特征,并同时得到这些特征相应的权重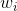
2. 对每个特征进行一般的hash,得到一个n bit的二进制串,假设n=64;
3. 设置网页的SimHash为向量V,V的初值0,向量V的维数与特征hash结果的维数相同,都是64位;
4. 对于每个特征i的hash值,如果第j位为0,则向量V的第j位减去
5. 处理所有特征的hash值后,将向量V中的负数置为0,正数置为1,此时的向量V就是该网页的SimHash值。
假设现在有一个由网页SimHash值(后面称作指纹)组成的数据库,数据库可能非常大,假设为
Detecting Near-Duplicates:
方案一:穷举搜索
最简单的办法是进行穷举搜索,比较输入指纹F与每一个库内指纹D,看他们的海明距离是否不大于3。该方法的时间复杂度是
方案二:穷举探测(probe)
另一个很暴力的方法是穷举probe。首先对数据库中的指纹进行排序(认为是预处理,不计入总的时间复杂度),对于输入指纹F,求出所有可能的与F海明距离不大于3的指纹F',使用F'在排序的数据库中进行二分查找(一次probe过程)。该方法的时间复杂度约为
方案三:预处理法
该方案是首先算出数据库中每个指纹D的海明距离不大于3的指纹D',并且D'是在数据库内的。也就是说一旦通过F查询到D,由于与D海明距离不大于3的指纹已经预处理得到,就可以得到F的所有相似指纹。该方法的时间复杂度为
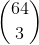
方案四:折中二三
该方案也是Google在这篇论文中提出的方法,是对方案二和方案三的一个折中,即使用可以接受的内存消耗,减少查询次数。
因为数据库中共有
现在选择p位的显著位,p小于d并且

其实说白了核心思想就是先用F的某些位进行查询,缩小校验指纹海明距离的范围。那么问题来了,如何确定d和p呢?其实不用也没有办法找出d位的显著位,Google用了一种很巧妙的办法解决这个问题,就是建立多个表!
具体检索流程:
1. 将指纹分成若干段,这里使用最简单的方法,假设就分成4段,每段为16位。
2. 假设第一段,也就是前16位为上面提到的p位,使用这p为到指纹数据库中进行查询(数据库是排序的),那么大概会得到
现在问题又来了,如果只是简单的取第一段,那么如果第一段中存在某一位不同,但是后面三段中的每一位都相同,这时海明距离还是不大于3的,但是却把这样的结果给滤掉了!解决这个问题的方法就是建立多个表。还是以将指纹分为4段为例,这时4段中至少有一段是应该与查询指纹相应段完全相同的。所以这时就要建立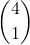

当然分段的方法有很多种,而分成多少段跟表的个数是有关的,比如分成5段就应该有
以分成4段4个表的方法为例,一次probe(查询)大约返回
可以看出当划分的段越多时,表就越多,内存消耗就越大,但是p就越接近于d,也就是每次probe返回的结果就越少,速度越快。所以划分段或者建立多少个表是内存与速度之间的权衡,而方案二和方案三是两个极端的情况。
在论文中还提到了表的压缩问题和批量查询的问题。















 3600
3600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









