







 文章讨论了在模型训练中遇到的验证集损失先下降后上升的问题,指出训练集损失最低的模型可能并不理想。文章强调了数据不平衡对序列标注任务的影响,并介绍了准确率、错误率、F1值等评估指标。此外,还探讨了学习率对模型收敛性的影响,提出了一些优化策略,包括调整学习率、使用RoChBERT预训练模型、Multi-SampleDropout等增强模型的鲁棒性。
文章讨论了在模型训练中遇到的验证集损失先下降后上升的问题,指出训练集损失最低的模型可能并不理想。文章强调了数据不平衡对序列标注任务的影响,并介绍了准确率、错误率、F1值等评估指标。此外,还探讨了学习率对模型收敛性的影响,提出了一些优化策略,包括调整学习率、使用RoChBERT预训练模型、Multi-SampleDropout等增强模型的鲁棒性。
模型選擇:驗證集(1480條)損失先下降后上升,訓練集損失一直下降,驗證集最低損失所在模型沒有驗證集損失最低所在模型好,即取訓練集損失最低處所在模型,只是對應的提升、下降只有0.5%左右,故任需測試
bert_config.josn 模型中参数的配置
{
“attention_probs_dropout_prob”: 0.1, #乘法attention时,softmax后dropout概率
“hidden_act”: “gelu”, #激活函数
“hidden_dropout_prob”: 0.1, #隐藏层dropout概率
“hidden_size”: 768, #隐藏单元数
“initializer_range”: 0.02, #初始化范围
“intermediate_size”: 3072, #升维维度
“max_position_embeddings”: 512,#一个大于seq_length的参数,用于生成position_embedding
“num_attention_heads”: 12, #每个隐藏层中的attention head数
“num_hidden_layers”: 12, #隐藏层数
“type_vocab_size”: 2, #segment_ids类别 [0,1]
“vocab_size”: 30522 #词典中词数
}1、数据不平衡是一个非常常见的问题,尤其见于序列标注任务中。比如,对词性标注任务来说,我们一般使用BIEOS,如果我们把O视为负例,其他视为正例,那么负例数和正例数之比是相当大的。
查看曲线图:tensorboard --logdir="E:\20220711171059\eval"
2、在程序运行过程中
3、基础概念
正例:BIE 负利:O
TP(True Positive, TP):真实为正例且被预测为正例的样本数为真正例;正样本 ==> 正类
TN(True Negative, TN):真实为负例且被预测为负例的样本数为真负例;负样本 ==> 负类
FP(False Positive, FP):真实为负例但被误预测为正例的样本数为假正例;负样本 ==> 正类
FN(False Negative, FN):真实为正例但被误预测为负例的样本数为假负例;正样本 ==> 负类
1)准确率(Accuracy)和错误率(Error Rate)
准确率Accuracy = (TP+TN)/(TP+TN+FP+FN) = 预测正确的样本数 / 总样本数
错误率Error Rate = 1-Accuracy
2)正确率(Precision)、召回率(Recall)、选择率(Selectivity)
Precision查准率 = TP/(TP+FP)
Recall查全率 = TPR = TP/(TP+FN) = 预测正确的正例数 / 实际正例数
Selectivity = TNR = TN/(TN+FP)
3)F1值
F1 = (2Precision x Recall)/(Precision + Recall)
4)困惑度越大,效果越差
5)Micro-F1 vs Macro-F1
Micro-F1(微观F1)和Macro-F1(宏观F1)都是F1值合并后的结果,主要用于多分类任务的评价。是分类任务的一个衡量指标,用于权衡Precision和Recall。换句话说,F1-Score是精确率
和召回率的调和平均数
micro F1:通过 计算所有分类的准确率P、召回率R,将它们代入F1方程中,再得出总的F1。更适用于数据分布不平衡的情况。但是在这种情况下,数量较多的类别对Micro-F1的影响会较大。
macro F1:通过计算所有分类的F1,再通过简单平均,得到总的F1。平等的看待每一类,高precision和高recall类的对结果影响较大
weighted-f1:考虑了不同类别的重要性,也就是把每个类别的样本数量作为权重,计算加权f1
详细:https://blog.csdn.net/qq_27668313/article/details/125570210
6)F1选择总结:
数据量越多,对weight-F1, micro-F1影响越大。此情况下,一般就用macroF1来评估多分类模型了。
macro-F1、micro-F1、weightF1都是在多分类下用来评估模型好坏的指标。具体选用哪个应该取决于你的任务数据情况:
1. 通常情况下,若数据集各类别数据量是不平衡的且所有类别都是同样重要,那用macroF1就好了,因为它是按类别计算,再取平均的F1作为最后值。大多数应该就是这种情况了,
micro在极度不平衡数据下会≈数据量大的那一类f1。
2.若是在一个非平衡的数据集上,你个人希望侧重于一些类,那当然是weighted F1 了。
3.若是平衡的数据集,且是忽略类别的情况那就用microF1好了【数据优化-调参】
1、crf-lr单独设置学习率,3e-5的100倍以上时,可解决无开始和结束标签
1)损失(F1)阶梯氏下降或上下波动太大,(原因:学习率太高,crf学习率超过其它学习率1倍以上),但是学习率在3e-5以下时“元”提成了金额、标签约束不好==>过拟合?
2)宏观F1和微观F1差不多时,不用单独设置crf学习率???
3)打乱训练顺序不容易过拟合、波动小一些
4)批次降低,学习率也要降低
5)任意损失呈 下降-上升-下降,效果不好
2、crf-lr 增加,各损失上下波动更厉害(从3e-5的100倍提升到133倍,其他不变;结论来自宏观F1和微观F1差不多的模型训练)
3、损失走势
train loss 不断下降,test loss也不断下降:网络仍在学习,让他继续学;
train loss 不断下降,test loss趋于不变或上升:说明网络过拟合;
train loss 趋于不变,test loss不断下降:不用想数据集250%有问题;
train loss 趋于不变,test loss趋于不变:说明学习遇到瓶颈,需要减小学习率或批量数目;或者是数据集有问题(数据集标注错误数据比较多)
train loss 不断上升,test loss不断上升:说明网络结构设计不当、训练超参数设置不当、数据集经过清洗、学习率太高、batch size太小等问题。
4、学习率用于控制梯度下降中参数更新的幅度(速度)。学习率过小,能保证收敛性,但会大大降低模型的优化速度,需要更多轮的迭代才能达到比较理想的优化效果。如果幅度过大,可能导致参数的“摆动”特性。
5、说明Bert模型更多的是记住实体,而非关注到上下文信息。
6、其它调参:下兩者需在常規參數訓練后視情況再選擇調整
1)训练损失一直下降,验证损失先下降后上升。找到验证集损失最小值b,设置训练集loss=abs(loss-b)+b;https://cloud.tencent.com/developer/beta/article/1685956
2)训练损失先下降后上升。设置warmup_step=1000(整数)左右;https://www.jianshu.com/p/c8583867677e
7、模型不收斂,loss一會很高一會又很低:https://blog.csdn.net/kyle1314608/article/details/107099807?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170597669616800215091806%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170597669616800215091806&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-24-107099807-null-null.nonecase&utm_term=nlp&spm=1018.2226.3001.4450【优化思路】
1、说明模型更多的是记住实体,而非关注到上下文信息。
2、鲁棒性:RoChBERT预训练模型
2.1 相同的上下文 + 不同的实体;
2.2 对抗训练方式:使用对抗训练,其效率较低。因其需要迭代来产生对抗样本,能否不产生对抗样本,同时也能够达到对抗训练的能力?
2.3 Flooding方法:借助CV领域的flooding方法。在正常情况下,随着训练的迭代,其损失会越来越小,而flooding方法,会让loss先像往常一样梯度下降到“flooding level”(一个超参,是训练损失的底线,下图中的b)附近, 但当训练损失低于这个值时,就进行梯度上升。这个方法实现简单,且在NLP领域也已经被证明有效。初始的b值一般设为 验证集loss开始上扬的值的一半。https://zhuanlan.zhihu.com/p/438196460
2.4 Multi-sample Dropout:dropout目前是NLP任务中很流行的数据扩充手段。Multi-Sample Dropout是对Dropout方法的一种改进,是2019年的一篇工作。Multi-Sample Dropout相比于dropout加快了模型训练过程的收敛速度和提高了泛化能力。dropout_rate设置0.2不能设置太大,否则0.4的比例在bert上会出现F1为零的情况。https://gitee.com/jtay/text_similarity/tree/submit/code
2.5 伪标签:
2.6 投票+rank/概率平均:几个模型预测结果投票
2.7 损失选择:面对不均衡 dice loss & focal loss & cross entropy loss。最后说一下实践下来的经验,由于不同数据集的数据分布特点各有不同,dice loss 以及 GHM loss 会出现些抖动、不稳定的情况。当不想挨个实践的时候,首推 focal loss,dice loss。 
2、大量分类数据模型优化 + 一般模型优化:看下方第一个链接
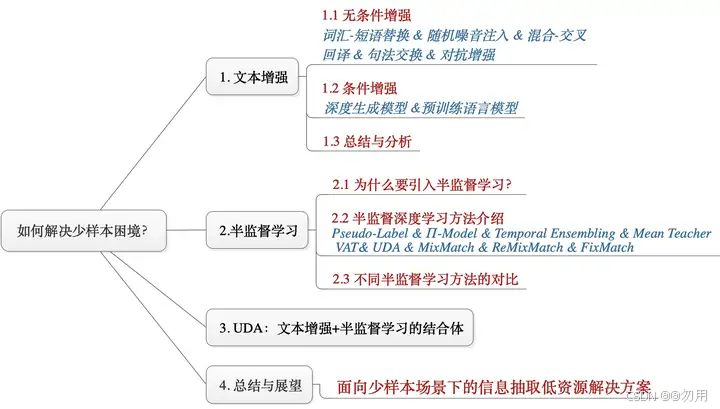
1)解决NLP分类任务的11个关键问题(开始于数据准备):UDA的方案不错https://zhuanlan.zhihu.com/p/183852900
PS:
1)《解决NLP分类任务的11个关键问题》发布于 2020-08-14 16:45,但是2024.10.10前没有最新的相关文档
2)UDA代码:GitHub - google-research/uda: Unsupervised Data Augmentation (UDA)
3)UDA实验:https://zhuanlan.zhihu.com/p/186211797
4)分类方案: TextCNN + 数据蒸馏(半监督学习) + 文本增强(有时间) https://zhuanlan.zhihu.com/p/183852900; 或者直接蒸馏为一个浅层BERT;或采用Google的UDA
2)上述作者之标注样本少(每个分类100条):https://zhuanlan.zhihu.com/p/146777068
3)上述作者之标注数据包含错误:https://zhuanlan.zhihu.com/p/146557232
4)TextCNN微调(文心一言,解决上述链接中数据增强的步骤):在已有的模型基础上,学习新的标注数据
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
# 加载已经训练好的 TextCNN 模型(确保模型文件是在 TensorFlow 1.15 下保存的)
textcnn_model_1 = load_model('path_to_textcnn_model_1.h5', custom_objects={'...': ...}) # 如果模型中有自定义对象(如层或损失函数),需要在这里指定
# 假设你已经有了一个 tokenizer 和预处理函数来处理文本数据
# tokenizer = ... # 你需要根据你的实际情况来创建或加载这个 tokenizer
# def preprocess_text(text, tokenizer, max_length):
# # 你的文本预处理逻辑
# pass
# 加载和预处理数据 A
# data_A = {'texts': [...], 'labels': [...]} # 你的原始标注数据集
# 假设 max_length 和 vocab_size 已经定义好了
max_length = 100
vocab_size = 5000
# 预处理数据 A(转换为模型可以接受的格式)
X_A = []
for text in data_A['texts']:
# 使用 tokenizer 将文本转换为整数序列,并填充或截断到固定长度
sequence = tokenizer.texts_to_sequences([text])[0]
padded_sequence = pad_sequences([sequence], maxlen=max_length, padding='post')
X_A.append(padded_sequence)
X_A = tf.convert_to_tensor(X_A, dtype=tf.int32) # 转换为 TensorFlow 张量
# 将标签转换为 one-hot 编码(如果它们还不是的话)
y_A = to_categorical(data_A['labels'])
# 编译模型(如果需要的话,你可以更改优化器或损失函数,但通常微调时只需改变学习率)
optimizer = Adam(lr=0.0001) # 设置微调时的学习率
textcnn_model_1.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 微调模型
# 这里我们假设你只想训练几个 epoch 来进行微调
textcnn_model_1.fit(X_A, y_A, epochs=5, batch_size=32, validation_split=0.2)
# 保存微调后的模型
textcnn_model_2 = textcnn_model_1 # 或者你可以创建一个新的模型实例(但通常不需要,因为微调是在原模型上进行的)
textcnn_model_2.save('path_to_textcnn_model_2.h5')PS:
1)微调时,通常需要调整学习率。较小的学习率(如0.0001)可以帮助模型在保留之前学习到的知识的同时进行微调。其他训练参数(如批处理大小、训练轮数等)也需要根据实际情况调整。
2)半监督学习:是一种利用大量未标记数据和少量标记数据共同训练模型的方法,半监督学习中一致性正则,一致性正则是啥?参考https://zhuanlan.zhihu.com/p/146777068
3)置信度:如分类模型下预测结果的分数
4)哈工大词林(部分):大词林目录浏览
5)Bert做分类任务:
真源码:https://zhuanlan.zhihu.com/p/498713086
简洁源码:基于BERT的文本分类——附-简单的示例代码_bert文本分类-CSDN博客
Roberta做中文分类:[PDF] RoBERTa-wwm-ext Fine-Tuning for Chinese Text Classification | Semantic Scholar
5)翻译工具:https://baijiahao.baidu.com/s?id=1805248171704288083&wfr=spider&for=pc

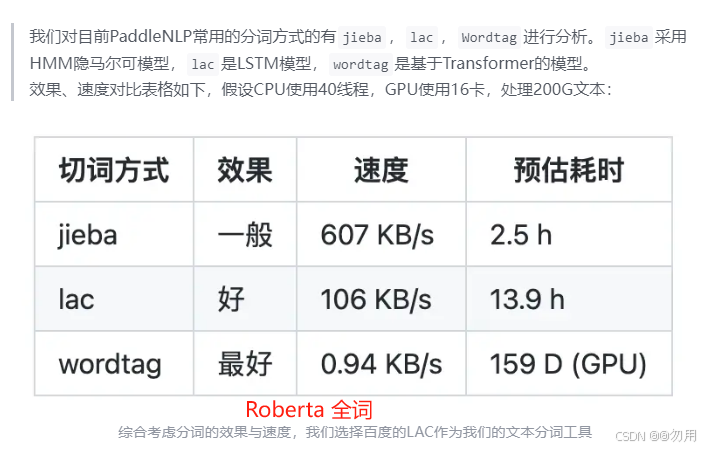
3、模型训练优化
1)迁移学习:利用已有的模型作为基础,通过迁移学习来适应新的分类。迁移学习可以帮助模型利用在旧分类上学习到的知识,加速新分类的学习过程。如利用在大型数据集上预训练的模型(如BERT、RoBERTa等),然后在其基础上进
行微调以适应特定的分类任务。
2)模型微调:在新数据上微调模型参数。这通常涉及到使用新分类的数据来更新模型的权重。
3)模型融合:如果资源允许,可以训练多个模型,然后使用集成学习方法如投票分类器来融合它们的预测,以提高整体性能
4)数据增强:通过数据增强技术如同义词替换、句子重组等方法扩充新分类的训练数据,这有助于提高模型的泛化能力
5)特征工程:考虑是否需要添加新的特征来更好地表示新分类的数据。
6)模型剪枝:如减少权重以提高性能、模型量化
7)特征选择:
文本表示:选择适当的文本表示方法,如词袋模型、TF-IDF、词嵌入(Word2Vec、GloVe)或更高级的上下文嵌入(BERT、GPT等)。
降维:如果特征维度过高,可以考虑使用PCA、LDA等方法进行降维,以提高模型训练效率。
8)模型训练:
参数调优:通过交叉验证等方法调整模型参数,如学习率、迭代次数、正则化参数等。
早停法:在训练过程中监控验证集的性能,当性能不再提升时停止训练,以避免过拟合。
增量学习:随着新数据的加入,可以使用增量学习方法更新模型,而不是重新训练整个模型
9)模型评估:
评价指标:使用准确率、精确率、召回率、F1分数等指标评估模型性能。
混淆矩阵:分析混淆矩阵,了解模型在不同类别上的表现。
10)提升数据质量的预处理方法:
质量过滤:语言大模型训练中需要过滤低质量数据,主要分为两类方法:基于分类器的方法和基于启发式的方法。基于分类器的方法是训练一个文本质量判断模型,用以识别并过滤低质量数据。例如,GPT3、PaLM和
GLaM模型在训练数据构造时都使用了基于分类器的方法。而基于启发式的方法则是通过一组精心设计的规则来消除低质量文本,主要包括语言过滤、指标过滤、统计特征过滤和关键词过滤,如BLOOM和Gopher都采用了基于启发式的方法
冗余去除:语言大模型训练语料库中的重复数据会影响模型性能,降低语言大模型的多样性并可能导致训练过程不稳定。因此需要对数据进行冗余去除。文本冗余发现(Text DuplicateDetection)
也称为文本重复检测,是自然语言处理和信息检索中的基础任务之一。该方法用于数据处理可以发现不同粒度上的文本重复,包括句子、段落以及文档等不同级别,可以有效改善语言模型的训练效果。
隐私消除:预训练数据中可能包含涉及敏感或个人信息,增加隐私泄露的风险。对于此类问题,最直接的方法是采用基于规则的算法删除隐私数据。例如可以使用基于命名实体识别的算法,检测数据中姓名、地址和电话号码等个人
信息内容,并进行删除或者替换。这种方法使用了基于 Transformer 的模型,并结合机器翻译技术,可以处理超过 100 种语言的文本,消除其中的隐私信息。
11)数据准备:
数据收集:首先,你需要获取足够大规模的数据集,这些数据应当与你试图解决的任务相关联,比如文本数据、图像数据、音频数据、交易数据等。
数据清洗:清洗数据以去除异常值、缺失值和重复项,标准化或归一化数值数据,处理文本数据的停用词、标点符号和编码问题等。
特征工程:创建有助于模型学习的特征,可能涉及特征提取、衍生新特征、特征选择等。
数据划分:将数据集划分为训练集、验证集和测试集,确保模型训练、调参和最后评估的公正性。4、模型设置优化
1)无监督学习辅助:在某些情况下,可以先使用无监督学习方法(如聚类)对数据进行初步的分类,然后根据聚类结果选择代表性的样本进行标注
2)半监督(少量标注数据生成模型,识别评分高的未标注数据用来训练),主要针对未标注数据相关的正则化项进行设置
3)主动学习:
让模型选择最有信息量的样本进行标注,而不是随机选择。
这通常涉及模型对未标注数据的不确定性评估,然后选择不确定性最高的样本进行人工标注。
4)多层分类:(树结构化分类器)使用决策树、随机森林或者Gradient Boosted Trees等方法,它们可以处理多层分类,并且能够在每个节点上进行多分类。
5)同样的数据训练多个模型:MultiTrain是一个强大的工具,可以帮助我们在数据集上训练多个机器学习分类模型
6)多任务学习:
使用多任务学习(Multi-Task Learning, MTL)技术,将多个相关的分类任务合并到一个模型中。
通过共享模型的某些层(如特征提取层),可以同时学习多个分类任务,从而减少对独立模型的需求。
在这种情况下,可以设计一个模型,其输出层包含所有大分类和细分类的预测节点,但根据输入文章的大分类预测结果,只激活对应的细分类预测节点。
7)标签嵌入:
将分类标签(包括大分类和细分类)转换为嵌入向量,这些向量可以捕捉到标签之间的语义关系。
使用这些嵌入向量作为模型输入的一部分,可以帮助模型更好地理解文章与分类标签之间的关系。
通过这种方式,可以构建一个统一的模型来处理多个分类任务,而不需要为每个分类任务单独训练模型。
8、多分类标签模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









