






 本文介绍了Oracle中的TO_CHAR函数,特别是“FM”前缀的作用,它用于抑制零和空格。同时,讨论了如何正确排序一周的天数,并提到了其他字符串操作函数,如LENGTH系列函数,用于获取字符串不同单位的长度。
本文介绍了Oracle中的TO_CHAR函数,特别是“FM”前缀的作用,它用于抑制零和空格。同时,讨论了如何正确排序一周的天数,并提到了其他字符串操作函数,如LENGTH系列函数,用于获取字符串不同单位的长度。
//首字母大写
INITCAP('tech on the net');
result:'Tech On The Net'//删除左边匹配的内容,第二个参数为空的话则为匹配删除空格
LTRIM('123123Tech', '123')
Result: 'Tech'
LTRIM( '637Tech', '0123456789')
Result: 'Tech'//删除右边匹配的内容,第二个参数为空的话则为匹配删除空格
RTRIM('tech ')
Result: 'tech'
RTRIM('Tech123123', '123')
Result: 'Tech'//trim
TRIM(' tech ')
Result: 'tech'
TRIM(' ' FROM ' tech ')
Result: 'tech'
TRIM(LEADING '0' FROM '000123')
Result: '123'
TRIM(TRAILING '1' FROM 'Tech1')
Result: 'Tech'
TRIM(BOTH '1' FROM '123Tech111')
Result: '23Tech'//replace
REPLACE('123123tech', '123');
Result: 'tech'
REPLACE('123tech123', '123');
Result:'tech'
REPLACE('222tech', '2', '3');
Result: '333tech'
REPLACE('0000123', '0');
Result: '123'
REPLACE('0000123', '0', ' ');
Result: ' 123'//SUBSTR (start 为负数时,就是倒数第几个)
SUBSTR('This is a test', 6, 2)
Result: 'is'
SUBSTR('This is a test', 6)
Result: 'is a test'
SUBSTR('TechOnTheNet', 1, 4)
Result: 'Tech'
SUBSTR('TechOnTheNet', -3, 3)
Result: 'Net'
SUBSTR('TechOnTheNet', -6, 3)
Result: 'The'
SUBSTR('TechOnTheNet', -8, 2)
Result: 'On'//function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
//__srcstr :需要进行正则处理的字符串
//__pattern :进行匹配的正则表达式
//__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
//__occurrence :标识第几个匹配组,默认为1
//__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)(\s)')
FROM dual;Result: 'TechOnTheNet '
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)')
FROM dual;
Result: 'TechOnTheNet'
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)(\s)', 1, 2)
FROM dual;
Result: 'is '
SELECT REGEXP_SUBSTR ('2, 5, and 10 are numbers in this example', '\d')
FROM dual;
Result: 2
SELECT REGEXP_SUBSTR ('2, 5, and 10 are numbers in this example', '(\d)(\d)')
FROM dual;
Result: 10
SELECT REGEXP_SUBSTR ('Anderson', 'a|e|i|o|u', 1, 1, 'i')
FROM dual;
Result: 'A'
SELECT REGEXP_SUBSTR ('TechOnTheNet is a great resource', '(\S*)(\s)', 1, 3)
FROM dual
SELECT REGEXP_SUBSTR ('TechOnTheNet', 'a|e|i|o|u', 1, 3, 'i')
FROM dual;//INSTR( string, substring [, start_position [, nth_appearance ] ] )
INSTR('Tech on the net', 'e')
Result: 2 (the first occurrence of 'e')
INSTR('Tech on the net', 'e', 1, 1)
Result: 2 (the first occurrence of 'e')
INSTR('Tech on the net', 'e', 1, 2)
Result: 11 (the second occurrence of 'e')
INSTR('Tech on the net', 'e', 1, 3)
Result: 14 (the third occurrence of 'e')//REGEXP_COUNT( string, pattern [, start_position [, match_parameter ] ] )
SELECT REGEXP_COUNT ('The example shows how to use the REGEXP_COUNT function', 'the', 1, 'i')
FROM dual;
Result: 2//case statement
SELECT table_name,
CASE owner
WHEN 'SYS' THEN 'The owner is SYS'
WHEN 'SYSTEM' THEN 'The owner is SYSTEM'
ELSE 'The owner is another value'
END
FROM all_tables;
SELECT table_name,
CASE
WHEN owner='SYS' THEN 'The owner is SYS'
WHEN owner='SYSTEM' THEN 'The owner is SYSTEM'
ELSE 'The owner is another value'
END
FROM all_tables;
IF owner = 'SYS' THEN
result := 'The owner is SYS';
ELSIF owner = 'SYSTEM' THEN
result := 'The owner is SYSTEM'';
ELSE
result := 'The owner is another value';
END IF;
//省略了else,not true 的时候自动返回true
SELECT table_name,
CASE owner
WHEN 'SYS' THEN 'The owner is SYS'
WHEN 'SYSTEM' THEN 'The owner is SYSTEM'
END
FROM all_tables;//LPAD( string1, padded_length [, pad_string] )
LPAD('tech', 7);
Result: ' tech'
LPAD('tech', 2);
Result: 'te'
LPAD('tech', 8, '0');
Result: '0000tech'
LPAD('tech on the net', 15, 'z');
Result: 'tech on the net'
LPAD('tech on the net', 16, 'z');
Result: 'ztech on the net'//RPAD( string1, padded_length [, pad_string] )
RPAD('tech', 7)
Result: 'tech '
RPAD('tech', 2)
Result: 'te'
RPAD('tech', 8, '0')
Result: 'tech0000'
RPAD('tech on the net', 15, 'z')
Result: 'tech on the net'
RPAD('tech on the net', 16, 'z')
Result: 'tech on the netz'//COALESCE( expr1, expr2, ... expr_n )
SELECT COALESCE( address1, address2, address3 ) result
FROM suppliers;
--The above COALESCE function is equivalent to the following IF-THEN-ELSE statement:
IF address1 is not null THEN
result := address1;
ELSIF address2 is not null THEN
result := address2;
ELSIF address3 is not null THEN
result := address3;
ELSE
result := null;
END IF;//ASCII( single_character )
ASCII('t')
Result: 116
ASCII('T')
Result: 84
ASCII('T2')
Result: 84//ASCIISTR( string )
ASCIISTR('A B C Ä Ê')
Result: 'A B C \00C4 \00CA'
ASCIISTR('A B C Õ Ø')
Result: 'A B C \00D5 \00D8'
ASCIISTR('A B C Ä Ê Í Õ Ø')
Result: 'A B C \00C4 \00CA \00CD \00D5 \00D8'//CHR( number_code )
CHR(116)
Result: 't'
CHR(84)
Result: 'T'//CONVERT( string1, char_set_to [, char_set_from] )
CONVERT('A B C D E Ä Ê Í Õ Ø', 'US7ASCII', 'WE8ISO8859P1')
Result: 'A B C D E A E I ? ?'//TRANSLATE( string1, string_to_replace, replacement_string )
TRANSLATE('1tech23', '123', '456')
Result: '4tech56'
TRANSLATE('222tech', '2ec', '3it')
Result: '333tith'//CEIL( number )
CEIL(32.65)
Result: 33
CEIL(32.1)
Result: 33//FLOOR( number )
FLOOR(5.9)
Result: 5
FLOOR(34.29)
Result: 34//ROUND( number [, decimal_places] )
ROUND(125.315)
Result: 125
ROUND(125.315, 0)
Result: 125
ROUND(125.315, 1)
Result: 125.3//TRUNC( number [, decimal_places] )
TRUNC(-125.815, 2)
Result: -125.81
TRUNC(125.815, -1)
Result: 120
TRUNC(125.815, -2)
Result: 100
TRUNC(125.815, -3)
Result: 0//GREATEST( expr1 [, expr2, ... expr_n] )
GREATEST(2, 5, 12, 3)
Result: 12
GREATEST('2', '5', '12', '3')---这个是string
Result: '5'
GREATEST('apples', 'oranges', 'bananas')
Result: 'oranges'
GREATEST('apples', 'applis', 'applas')
Result: 'applis'//SIGN( number )
If number < 0, then sign returns -1.
If number = 0, then sign returns 0.
If number > 0, then sign returns 1.
SIGN(-23)
Result: -1
SIGN(-0.001)
Result: -1
SIGN(0)
Result: 0
SIGN(0.001)
Result: 1//POWER( m, n )
POWER(3, 2)
Result: 9
POWER(5, 3)
Result: 125//EXTRACT (
//{ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND }
//| { TIMEZONE_HOUR | TIMEZONE_MINUTE }
//| { TIMEZONE_REGION | TIMEZONE_ABBR }
//FROM { date_value | interval_value } )
EXTRACT(YEAR FROM DATE '2003-08-22')
Result: 2003
EXTRACT(MONTH FROM DATE '2003-08-22')
Result: 8
EXTRACT(DAY FROM DATE '2003-08-22')
Result: 22//TO_CHAR( value [, format_mask] [, nls_language] )
TO_CHAR(1210.73, '9999.9')
Result: ' 1210.7'
TO_CHAR(-1210.73, '9999.9')
Result: '-1210.7'
TO_CHAR(1210.73, '9,999.99')
Result: ' 1,210.73'
TO_CHAR(1210.73, '$9,999.00')
Result: ' $1,210.73'
TO_CHAR(21, '000099')
Result: ' 000021'
TO_CHAR(sysdate, 'yyyy/mm/dd')
Result: '2003/07/09'
TO_CHAR(sysdate, 'Month DD, YYYY')
Result: 'July 09, 2003'
TO_CHAR(sysdate, 'FMMonth DD, YYYY')
Result: 'July 9, 2003'
TO_CHAR(sysdate, 'MON DDth, YYYY')
Result: 'JUL 09TH, 2003'
TO_CHAR(sysdate, 'FMMON DDth, YYYY')
Result: 'JUL 9TH, 2003'
TO_CHAR(sysdate, 'FMMon ddth, YYYY')
Result: 'Jul 9th, 2003'You will notice that in some TO_CHAR function examples, the format_mask parameter begins with “FM”. This means that zeros and blanks are suppressed. This can be seen in the examples below.
TO_CHAR(sysdate, 'FMMonth DD, YYYY')
Result: 'July 9, 2003'
TO_CHAR(sysdate, 'FMMON DDth, YYYY')
Result: 'JUL 9TH, 2003'
TO_CHAR(sysdate, 'FMMon ddth, YYYY')
Result: 'Jul 9th, 2003'FREQUENTLY ASKED QUESTIONS
Question: Why doesn’t this sort the days of the week in order?
SELECT ename, hiredate, TO_CHAR((hiredate),'fmDay') "Day"
FROM emp
ORDER BY "Day";Answer: In the above SQL, the fmDay format mask used in the TO_CHAR function will return the name of the Day and not the numeric value of the day.
To sort the days of the week in order, you need to return the numeric value of the day by using the fmD format mask as follows:
SELECT ename, hiredate, TO_CHAR((hiredate),'fmD') "Day"
FROM emp
ORDER BY "Day";//TO_DATE( string1 [, format_mask] [, nls_language] )
TO_DATE('2003/07/09', 'yyyy/mm/dd')
Result: date value of July 9, 2003
TO_DATE('070903', 'MMDDYY')
Result: date value of July 9, 2003
TO_DATE('20020315', 'yyyymmdd')
Result: date value of Mar 15, 2002
//TO_NUMBER( string1 [, format_mask] [, nls_language] )
TO_NUMBER('1210.73', '9999.99')
Result: 1210.73
TO_NUMBER('546', '999')
Result: 546
TO_NUMBER('23', '99')
Result: 23
TO_NUMBER('1210.73', '9999.99')
Result: 1210.73
TO_NUMBER('546', '999')
Result: 546
TO_NUMBER('23', '99')
Result: 23//TO_TIMESTAMP( string1 [, format_mask] ['nlsparam'] )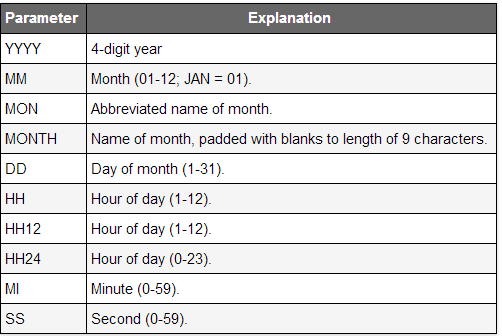
For example:
TO_TIMESTAMP('2003/12/13 10:13:18', 'YYYY/MM/DD HH:MI:SS')
would return '13-DEC-03 10.13.18.000000000 AM' as a timestamp value.
TO_TIMESTAMP('2003/DEC/13 10:13:18', 'YYYY/MON/DD HH:MI:SS')
would also return '13-DEC-03 10.13.18.000000000 AM' as a timestamp value.
//TO_TIMESTAMP_TZ( string1 [, format_mask] ['nlsparam'] )

For example:
TO_TIMESTAMP_TZ('2003/12/13 10:13:18 -8:00', 'YYYY/MM/DD HH:MI:SS TZH:TZM')
would return '13-DEC-03 10.13.18.000000000 AM -08:00' as a timestamp with time zone value.
TO_TIMESTAMP_TZ('2003/DEC/13 10:13:18 -8:00', 'YYYY/MON/DD HH:MI:SS TZH:TZM')
would also return '13-DEC-03 10.13.18.000000000 AM -08:00' as a timestamp with time zone value.TO_YMINTERVAL( character )
TO_YMINTERVAL('03-11')
Result: 3 years 11 months (as an INTERVAL YEAR TO MONTH type)
TO_YMINTERVAL('01-05')
Result: 1 year 5 months (as an INTERVAL YEAR TO MONTH type)
TO_YMINTERVAL('00-01')
Result: 0 years 1 month (as an INTERVAL YEAR TO MONTH type)CURRENT_DATE
select CURRENT_DATE
from dual;
9/10/2005 10:58:24 PMCURRENT_TIMESTAMP
select CURRENT_TIMESTAMP
from dual;
10-Sep-05 10.58.24.853421 PM -07:00LAST_DAY( date )
LAST_DAY(TO_DATE('2003/03/15', 'yyyy/mm/dd'))
Result: Mar 31, 2003NEXT_DAY( date, weekday )
SELECT NEXT_DAY('08-Sep-15','SUNDAY') from DUAL
13-SEP-15//NULLIF( expr1, expr2 )
NULLIF(12, 12)
Result: NULL
NULLIF(12, 13)
Result: 12
NULLIF('apples', 'apples')
Result: NULL
NULLIF('apples', 'oranges')
Result: 'apples'//LISTAGG (measure_column [, 'delimiter'])
WITHIN GROUP (order_by_clause) [OVER (query_partition_clause)]
SELECT LISTAGG(product_name, ', ') WITHIN GROUP (ORDER BY product_name) "Product_Listing"
FROM products;
//DBTIMEZONE
select DBTIMEZONE from dual;
+00:00//LAG ( expression [, offset [, default]] )over ( [ query_partition_clause ]order_by_clause )
select product_id, order_date,
LAG (order_date,1) over (ORDER BY order_date) AS prev_order_date
from orders;
select product_id, order_date,
LAG (order_date,1) over (ORDER BY order_date) AS prev_order_date
from orders
where product_id = 2000;
//LEAD ( expression [, offset [, default]] )
over ( [ query_partition_clause ] order_by_clause )
select product_id, order_date,
LEAD (order_date,1) over (ORDER BY order_date) AS next_order_date
from orders;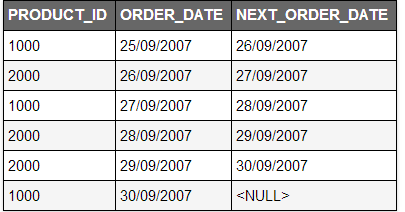
select product_id, order_date,
LEAD (order_date,1) over (ORDER BY order_date) AS next_order_date
from orders
where product_id = 2000;
//LNNVL( condition )
select * from products
where qty < reorder_level;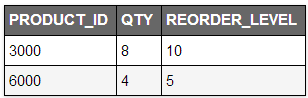
select * from products
where LNNVL(qty >= reorder_level);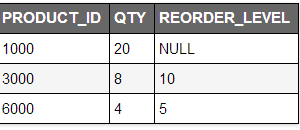
//NANVL( value, replace_with )Using table float_point_demo created for TO_BINARY_DOUBLE, insert a second entry into the table:
Insert INTO float_point_demo
VALUES (0,'NaN','NaN');
SELECT * FROM float_point_demo;
DEC_NUM BIN_DOUBLE BIN_FLOAT
---------- ---------- ----------
1234.56 1.235E+003 1.235E+003
0 Nan NanThe following example returns bin_float if it is a number. Otherwise, 0 is returned.
SELECT bin_float, NANVL(bin_float,0)
FROM float_point_demo;
BIN_FLOAT NANVL(BIN_FLOAT,0)
---------- ------------------
1.235E+003 1.235E+003
Nan 0//NVL( string1, replace_with)
功能:如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
//NVL2(string1, replace_with1, replace_with2)
的功能为:如果string1为NULL,则函数返回replace_with2,否则返回replace_with1。//RAWTOHEX( raw )功能: 将RAW类数值rawvalue转换为一个相应的十六进制表示的字符串. rawvalue中的每个字节都被转换为一个双字节的字符串. RAWTOHEX和HEXTORAW是两个相反的函数.
SQL> SELECT RAWTOHEX('11') FROM DUAL;
RAWT
----
3131//HEXTORAW功能: 将由string表示的二进制数值转换为一个RAW数值. String应该包含一个十六进制的数值. String中的每两个字符表示了结果RAW中的一个字节..HEXTORAW和RAWTOHEX为相反的两个函数.
SAMPLE:
SQL> select hextoraw('abcdef') from dual;
HEXTOR
------
ABCDEFINSTRB( string, substring [, start_position [, nth_appearance ] ] )start_position
代表string1 的哪个位置开始查找。此参数可选,如果省略默认为1. 字符串索引从1开始。如果此参数为正,从左到右开始检索,如果此参数为负,从右到左检索,返回要查找的字符串在源字符串中的开始索引。
INSTRB('TechOnTheNet.com', 'e', 1, 3)
Result: 11;
INSTRB('TechOnTheNet.com', 'e', -3, 2)
Result: 9 **LENGTH(string1) 返回以字符为单位的长度.
LENGTHB(string1) 返回以字节为单位的长度.
LENGTHC(string1) 返回以Unicode完全字符为单位的长度.
LENGTH2(string1) 返回以UCS2代码点为单位的长度.
LENGTH4(string1) 返回以UCS4代码点为单位的长度.**
//LENGTHB( string1 )
length求得是字符长度,
lengthb求得是字节长度。
LENGTHB(NULL)
Result: NULL
LENGTHB('')
Result: NULL
LENGTHB(' ')
Result: 1
LENGTHB('TechOnTheNet.com')
Result: 16
LENGTHB('TechOnTheNet.com ')
Result: 17
LENGTHB('新春快乐')
RESULT: 8














 9502
9502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









