







 本文介绍了多模态强化学习,特别是在VIMA项目中的应用,通过融合图像、文本等多种感知模态,使智能体在复杂任务决策中表现更优。VIMA展示了强大的模型可扩展性和泛化能力,为AI研究开辟新方向。
本文介绍了多模态强化学习,特别是在VIMA项目中的应用,通过融合图像、文本等多种感知模态,使智能体在复杂任务决策中表现更优。VIMA展示了强大的模型可扩展性和泛化能力,为AI研究开辟新方向。

作者:陈之炎
本文约3500字,建议阅读8分钟
本文介绍了多模态强化学习。多模态强化学习是将多个感知模态和强化学习相结合的方法,能够使智能系统从多个感知源中获取信息,并利用这些信息做出更好的决策。这种方法对于处理现实世界中的复杂任务具有潜在的价值,并为智能系统的发展提供了新的研究方向。
强化学习是一种机器学习方法,其通过智能体与环境的交互来学习最优的决策策略。早期的强化学习主要集中在单一模态数据上,如状态信息和奖励信号。经典的强化学习算法,如Q-learning和深度强化学习(DRL),在各种领域取得了重大突破。
多模态学习涉及多个感知模态的融合和处理,如图像、语音、文本等。该领域的研究主要关注如何从多模态数据中提取有用的特征,并利用这些特征进行模式识别、分类和生成等任务。多模态学习已经在计算机视觉、自然语言处理、语音识别等领域取得了显著的成果。
随着多模态学习和强化学习的发展,研究者开始将两者结合起来,形成了多模态强化学习的研究方向。多模态强化学习的目标是通过融合多种感知模态的数据,提供更全面的信息来进行决策和学习。这样的方法可以帮助智能体更好地理解环境和任务,并做出更准确的决策。
2023年5月28日,以李飞飞为代表的人工智能团队,发布了题为“’VIMA: General Robot Manipulation with Multimodal Prompts ”(多模态提示符下的通用机器人操作)一文,正式拉开了多模态智能体强化学习的序幕,接下来,让我们仔细研读一下李飞飞的研究,论文中的代码和演示视频,可在vimalabs.github.io.上获取。

通用机器人操纵任务可以通过多模态提示来表达,李飞飞团队开发了一个新的模拟基准,其中包括成千上万个程序生成的桌面任务,具有多模态提示, 60多万个用于模拟学习的专家轨迹,以及用于系统泛化的四级评估协议。它是一个基于Transformer的机器人智能体( VIMA ),它能自回归地处理输入提示命令并输出电机功率。VIMA具有实现强大模型可扩展性和数据效率,在给定相同的训练数据的前提下,零样本泛化设置最多可达2.9倍的任务成功率,即便在训练数据少了10倍的情况下, VIMA的性能仍然比最好的竞争变体好2.7倍。
VIMA的目标是构建一个能够执行多模态联运提示的机器人智能体。为了学习有效的多任务机器人策略,VIMA构建出一种具有多任务编码器-解码器架构和以物体为中心的机器人智能体。
具体来说,机器人需要学习策略π (  | P, H) ,其中H: =[
| P, H) ,其中H: =[ 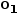 ,
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









