







本文约3200字,建议阅读10分钟
本文深入探讨了网友易受社交媒体信息影响的背后因素。 在这个信息爆炸的时代,社交媒体既是我们获取信息的重要途径,也是谣言扩散的温床。你是否曾想过,为什么有些谣言能在网络上瞬间蔓延,影响大批网友?为什么有些人更容易相信并传播谣言?这其中究竟隐藏了怎样的心理和社交机制?
在这个信息爆炸的时代,社交媒体既是我们获取信息的重要途径,也是谣言扩散的温床。你是否曾想过,为什么有些谣言能在网络上瞬间蔓延,影响大批网友?为什么有些人更容易相信并传播谣言?这其中究竟隐藏了怎样的心理和社交机制?
这项来自美国哈佛大学、斯坦福大学、加州大学洛杉矶分享(UCLA)、佐治亚理工4所名校的合作研究,深入探讨了网友易受社交媒体信息影响的背后因素。作者提出了一个计算模型,通过用户的活动推断他们的易受影响水平,利用可观察的分享行为对潜在受影响性倾向进行推断。仅通过社交媒体转发分享行为,就能揭示人们是如何被谣言所左右的。研究评估结果显示,本文模型的估计与人类对用户易受影响性水平的判断高度一致。这项研究还对社会因素与易受影响的关系进行了全面分析,发现政治倾向和心理因素与其存在不同程度的关联。
论文题目:From Scroll to Misbelief: Modeling the Unobservable Susceptibility to Misinformation on Social Media
论文链接:https://arxiv.org/abs/2311.09630
研究背景
社交媒体上的虚假言论不仅扰乱了个体对事实的判断,还加剧了社会内部的分歧和对立。虽然之前有研究工作关注了信息传播的可观察行为,但理解网友们相信虚假信息的心理过程仍具有挑战性。
易受影响性指的是个体对不可验证的言论(如虚假信息和谣言)的相信程度。在本研究中,易受影响性通常表示一个人在社交媒体等信息传播渠道中容易受到不准确或误导信息影响的程度。这一概念涉及个体的心理和认知过程,是一种难以直接观察的内在特征。
作者使用了一个计算模型,将用户的易受影响水平参数化,转化为一个可以观察到的模型输入。在训练过程中,进行多任务学习:
对用户是否会分享帖子进行分类;
在看到相同内容时,对相似用户和不相似用户的易受影响性分数进行排序。
本模型并不是直接预测个体的真实易受影响性水平,而是利用用户对虚假信息的转发作为一种更好解释其易受影响性水平的替代指标。
相信虚假信息是触发分享的重要驱动因素
虚假信息:虚构、不准确或者具有误导性的信息(不管是否有意生成的)。在社交媒体等平台上传播时,可能会误导公众的判断,对社会产生负面影响。
易受影响性:个体对虚假信息及相关概念的相信程度。这一程度涉及个体对真实和虚假言论之间的辨别能力,以及对虚假信息的相信程度如何影响其后续决策。较高的易受影响性可能导致个体更容易受到虚假信息的影响,在社交媒体上更容易分享这些虚假信息,同时也更易在面临虚假信息时被误导。
作者关注了信仰与信息传播之间的联系:
感知被视为相信的前提,然而,相信和分享并非相互包容,因为它们基于不同的心理、人口统计学或行为因素。
感知和分享是可观察的行为,而相信则是一种无法观察的事件。
社交媒体用户相信一则虚假信息是引发分享行为的关键驱动因素。此外,分享行为还会受到新闻内容、吸引注意力程度和个体心理动机等多种因素的影响。
建模计算易受影响性
作者综合了分享内容和用户资料的特征,构建了一个计算模型,如图 1 所示。该模型使用浅层神经网络来预测易受影响性分数,并结合用户和帖子 Embedding 的点积来预测转发行为。在训练过程中,作者采用了二元分类熵和三元损失两个损失函数。为了训练这个模型,作者使用了近似对照的用户-帖子对作为训练数据。
通过分析用户的历史活动,作者推断了用户不可被观察到的易受影响性分数,并通过可观察的传播行为信号进行进一步的模型训练。
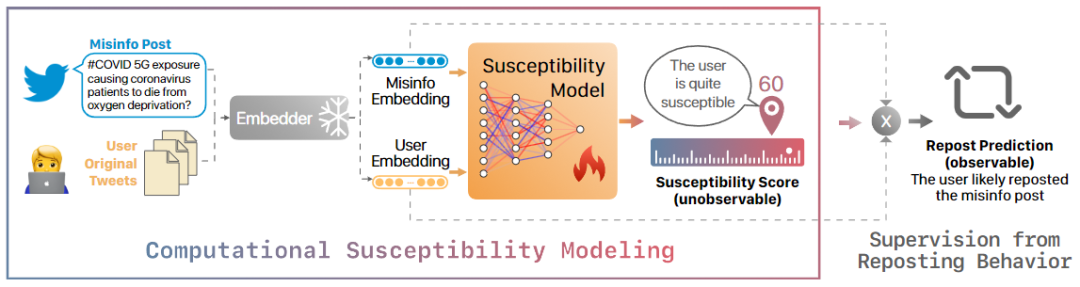
建模不可观察的易受影响性
内容敏感:作者关注用户在感知到特定虚假信息 时的易受影响性 ,这考虑到受主题和语言风格等因素的影响,个体在不同内容上的易受影响性可能存在差异。
作者用基于 RoBERTa-large 的 SBERT(Sentence-BERT)来生成表示帖子和用户资料中所包含语义信息的固定大小的向量。
虚假信息帖子被看作是一个句子,用 SBERT 生成了其相应的表示。
对于用户资料,计算了用户最近原创帖子句子表示的平均值。
具体而言,对于每个用户-帖子对 ,研究人员在虚假信息帖子 创建前的 10 天内收集了用户 发布的历史帖子,这能够学习用户在这个特定时间点的表示。
易受影响性的计算模型
在给定用户 的用户资料和虚假信息帖子 的输入时,通过浅层神经网络,模型将生成易受影响性分数 。这反映用户在感知到虚假信息 时所的易受影响性水平,即用户对该虚假信息的相信程度。
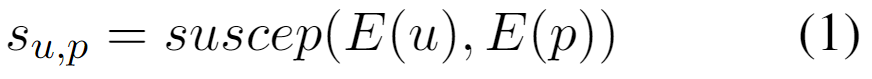
利用可观察行为监督训练
只有用户自己了解他们对帖子 的相信程度,因此易受影响性往往是一种难以直接观察的心理状态。为此,作者提出用可观察的分享行为作为监督信号。将易受影响性视为影响用户是否分享的重要因素,并用计算模型的输出来预测用户的转发行为。
为估计用户 分享虚假信息帖子 的概率,计算用户资料和帖子内容 Embedding 之间的点积,并将同一用户-帖子对上的分数作为权重因子,通过 Sigmoid 函数传递结果,从而更准确地预测分享行为:
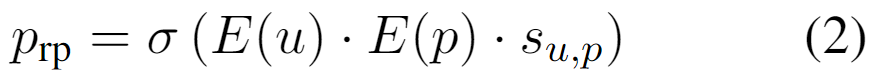
接下来,进行多任务学习以综合不同的监督信号。
二分类任务:使用交叉熵损失,来预测用户是否会转发虚假信息。
三元排名任务:区分当存在相同的虚假内容时,多个用户之间的易受影响性分数存在的细微差异。
数据集
作者了两个虚假信息的 Twitter 帖子数据集:ANTi-Vax 和 CoAID,共包含 14218 个实例,保留被有效用户转发的 1271 条虚假信息帖子,训练、验证和测试的比例为 80%-10%-10%。表 1 为数据集的详细统计信息:

▲表1 训练数据集的数据统计
正例:用户 查看并转发了虚假信息帖子;
负例:用户 查看但没有转发虚假信息帖子。
实验评估
与人类判断进行比较
作者为了验证先前推断的易受影响的有效性,使用人类评估进行了实验。将人类评估结构化为向评估者呈现用户-历史帖子对,要求他们确定哪个用户在总体上更易受 COVID-19 虚假信息影响。表 2 表明,该模型的预测结果与人类评估者提供的注释具有很好的一致性。
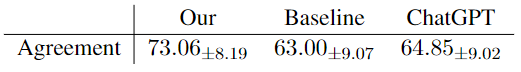
▲表2 与人类判断的比较
易受影响性分数分布
如图 2 所示,正例和负例之间的分布存在明显差异,验证了“相信程度是分享行为的重要驱动因素”假设。
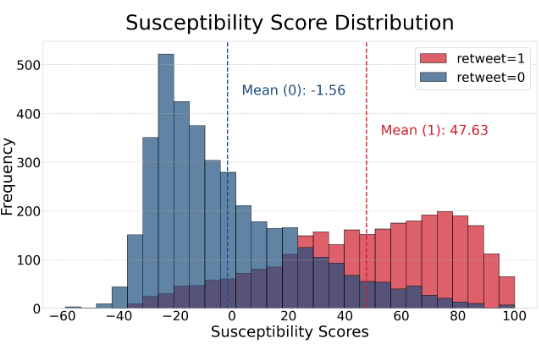 ▲图2 正例和负例用户-帖子样本中易受影响性分数分布
▲图2 正例和负例用户-帖子样本中易受影响性分数分布
与心理因素的相关性
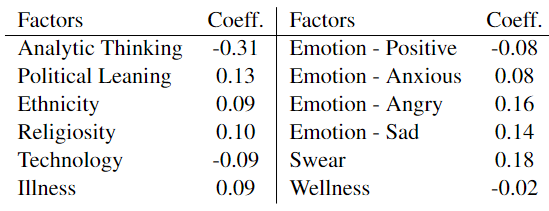
之前的研究主要使用问卷调查方法识别个体易受虚假信息影响的一些心理因素,在这里,作者又进行实验与先前的问卷研究结果进行比较。
使用 LIWC 分析基于用户历史帖子的方法,计算了多个心理因素的得分,又计算了这些因素与本文模型预测的易受影响性之间的皮尔逊相关系数,并绘制成表 3。结果显示,相关性与先前基于调查的社会科学研究结果一致。例如,分析性思维与低易受影响性强烈相关。
群体之间的差异
不同专业领域的用户:表 4 的结果表明,从事科学与技术、健康与医学以及教育领域的从业者社区对 COVID-19 虚假信息表现出较低的易受影响性。相反,在艺术与媒体领域的从业者中,易受影响性相对较高,可能因为他们更容易接触虚假信息。这一观察与之前的研究结果一致,即相关领域的专业知识和经验可能在抵御虚假信息方面起到保护作用。
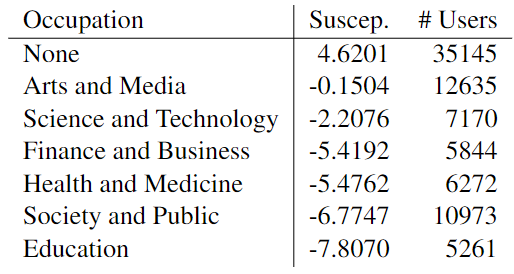 ▲表4 按专业领域划分的易受影响性分布
▲表4 按专业领域划分的易受影响性分布
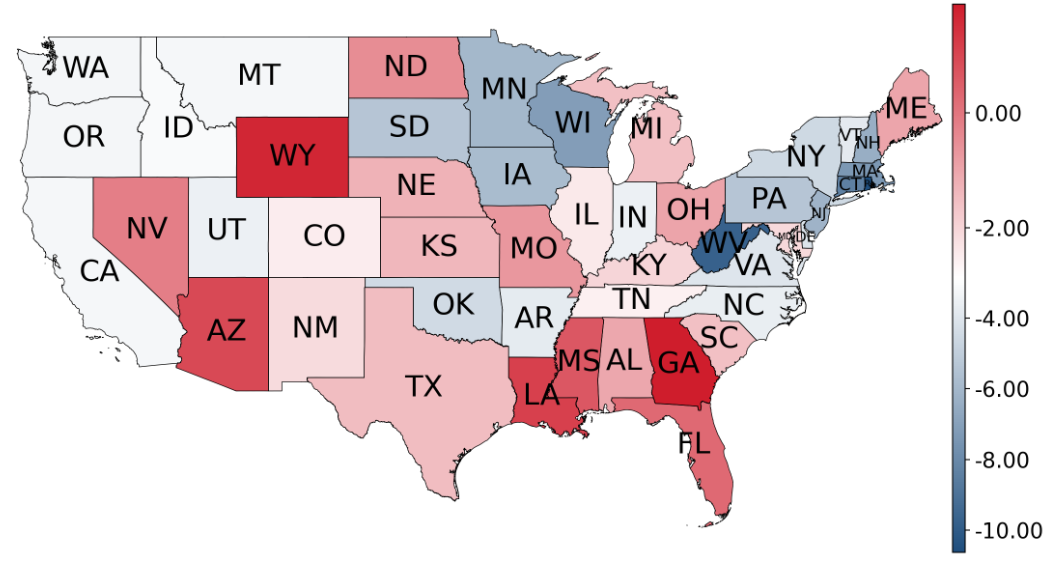
不同地理位置的用户:由于本研究的数据集收集于 Twitter,其用户多在美国。这里揭示了美国各州易受影响性分布存在不平衡,并与政治倾向有一定关联。总体而言,已知拥有相对保守人口的州通常显示出较高的易受影响性分数,而相对自由的州则分数较低。此外,研究发现各州的政治意识形态可能对个体对科学信息的感知产生影响。然而,研究也明确指出其局限性,因为仅反映了每个州抽样用户的易受影响性分布,未充分考虑其他潜在因素的影响。
总结
社交媒体如今是人们生活中不可或缺的一部分,正是在这片广阔无垠的信息海洋中,谣言悄然滋生。不同于传统媒体,社交媒体的信息传播更为迅速、广泛,而用户对信息的易受影响和敏感性也在这里得到了放大。因此,理性看待社交媒体中的信息至关重要。
目前来看,模型的研究结果与许多的调查或人类判定具有一致性,但还存在着数据集上的限制,在未来研究中需要更全面考虑多样性因素以提高模型的准确性和泛化性。
希望在这项研究的基础上,我们能更深刻地理解社交媒体与谣言之间的关系,提升个体的信息辨别能力。同时,也期盼更多的工作能专注于虚假信息领域,将研究成果付诸实践,共同构建一个清朗的网络空间。
编辑:黄继彦
校对:林亦霖

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









