







文章目录
1. 题目描述
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
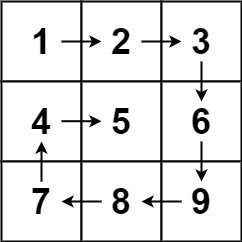
示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
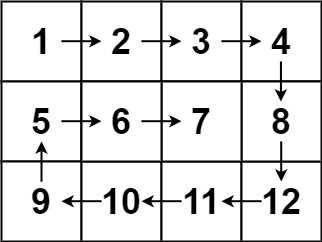
提示:
- m == matrix.length
- n == matrix[i].length
- 1 <= m, n <= 10
- -100 <= matrix[i][j] <= 100
2. 理解题目
这道题要求我们按照螺旋顺序遍历一个二维矩阵,并将遍历结果作为一维数组返回。具体来说:
- 输入是一个 m×n 的矩阵(二维数组)
- 要求按照顺时针螺旋顺序遍历矩阵的所有元素
- 螺旋顺序是从矩阵外围向内部螺旋的方式进行遍历
- 返回的结果是一个包含所有元素的一维数组
螺旋顺序的遍历路径为:
- 从左到右遍历上边界
- 从上到下遍历右边界
- 从右到左遍历下边界
- 从下到上遍历左边界
- 缩小边界,重复上述过程,直到所有元素都被遍历
关键点:
- 如何确定边界并不断缩小边界
- 如何处理只有一行或一列的特殊情况
- 如何正确地结束遍历过程,避免重复遍历元素
3. 解法一:四边界模拟法
3.1 思路
最直观的解法是模拟螺旋遍历的过程,使用四个变量表示当前的边界:
- 定义四个变量
top、right、bottom、left表示四个边界 - 在螺旋遍历的过程中,按照从左到右、从上到下、从右到左、从下到上的顺序访问边界上的元素
- 访问完一条边后,相应的边界向内收缩
- 当左边界超过右边界或上边界超过下边界时,遍历结束
这种方法直观模拟了题目要求的螺旋遍历过程。
3.2 Java代码实现
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> result = new ArrayList<>();
// 处理边界情况
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return result;
}
// 定义四个边界
int top = 0;
int right = matrix[0].length - 1;
int bottom = matrix.length - 1;
int left = 0;
// 循环遍历,直到所有元素都被访问
while (top <= bottom && left <= right) {
// 从左到右遍历上边界
for (int j = left; j <= right; j++) {
result.add(matrix[top][j]);
}
top++; // 上边界下移
// 从上到下遍历右边界
for (int i = top; i <= bottom; i++) {
result.add(matrix[i][right]);
}
right--; // 右边界左移
// 检查是否还有行未被遍历
if (top <= bottom) {
// 从右到左遍历下边界
for (int j = right; j >= left; j--) {
result.add(matrix[bottom][j]);
}
bottom--; // 下边界上移
}
// 检查是否还有列未被遍历
if (left <= right) {
// 从下到上遍历左边界
for (int i = bottom; i >= top; i--) {
result.add(matrix[i][left]);
}
left++; // 左边界右移
}
}
return result;
}
}
3.3 代码详解
详细解释每一步的意义和实现:
// 处理边界情况
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return result;
}
- 检查输入矩阵是否为空或大小为0
- 这是处理边界情况的常见做法,避免后续操作出现空指针或越界异常
// 定义四个边界
int top = 0;
int right = matrix[0].length - 1;
int bottom = matrix.length - 1;
int left = 0;
- 定义四个变量表示当前要遍历的四个边界
top表示上边界的行索引,初始为0right表示右边界的列索引,初始为矩阵的列数减1bottom表示下边界的行索引,初始为矩阵的行数减1left表示左边界的列索引,初始为0
// 循环遍历,直到所有元素都被访问
while (top <= bottom && left <= right) {
// 从左到右遍历上边界
for (int j = left; j <= right; j++) {
result.add(matrix[top][j]);
}
top++; // 上边界下移
// 从上到下遍历右边界
for (int i = top; i <= bottom; i++) {
result.add(matrix[i][right]);
}
right--; // 右边界左移
// 检查是否还有行未被遍历
if (top <= bottom) {
// 从右到左遍历下边界
for (int j = right; j >= left; j--) {
result.add(matrix[bottom][j]);
}
bottom--; // 下边界上移
}
// 检查是否还有列未被遍历
if (left <= right) {
// 从下到上遍历左边界
for (int i = bottom; i >= top; i--) {
result.add(matrix[i][left]);
}
left++; // 左边界右移
}
}
- 使用循环模拟螺旋遍历的过程
- 循环条件是上边界不超过下边界并且左边界不超过右边界,表示还有元素未被访问
- 在每一轮循环中,按照顺时针顺序遍历四条边:上、右、下、左
对于每一条边的遍历:
- 遍历上边界:沿着第
top行,从left列遍历到right列 - 遍历右边界:沿着第
right列,从top行遍历到bottom行 - 遍历下边界:沿着第
bottom行,从right列遍历到left列 - 遍历左边界:沿着第
left列,从bottom行遍历到top行
在遍历每条边后,对应的边界会向内收缩:
- 上边界下移:
top++ - 右边界左移:
right-- - 下边界上移:
bottom-- - 左边界右移:
left++
特别注意的是,在遍历下边界和左边界之前,需要检查边界条件:
- 遍历下边界前:
if (top <= bottom),确保还有行未被遍历 - 遍历左边界前:
if (left <= right),确保还有列未被遍历
这是为了处理矩阵行数或列数为奇数的情况,避免重复遍历。
3.4 复杂度分析
- 时间复杂度: O(m×n),其中 m 是矩阵的行数,n 是矩阵的列数。每个元素只被访问一次。
- 空间复杂度: O(1),除了存储结果的列表外,只使用了常数额外空间。如果不考虑结果列表,空间复杂度为O(1);如果考虑结果列表,空间复杂度为O(m×n)。
3.5 适用场景
四边界模拟法是解决螺旋矩阵问题的基础方法,适用于大多数情况。它直观、易于理解和实现,是面试中常用的解法。
4. 解法二:方向数组模拟法
4.1 思路
另一种常用的解法是使用方向数组来模拟螺旋遍历的过程:
- 定义一个方向数组,表示向右、向下、向左、向上四个方向的行列变化
- 使用一个变量记录当前的方向
- 按照当前方向前进,当遇到边界或已访问的元素时,改变方向
- 当所有元素都被访问后结束遍历
这种方法通过不断改变方向来实现螺旋遍历,更加灵活。
4.2 Java代码实现
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> result = new ArrayList<>();
// 处理边界情况
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return result;
}
int m = matrix.length;
int n = matrix[0].length;
// 创建访问标记数组,初始值为false,表示未访问
boolean[][] visited = new boolean[m][n];
// 定义四个方向:向右、向下、向左、向上
int[][] directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
int dirIndex = 0; // 初始方向为向右
// 开始位置为矩阵左上角
int row = 0, col = 0;
// 遍历所有元素
for (int i = 0; i < m * n; i++) {
result.add(matrix[row][col]);
visited[row][col] = true;
// 计算下一个位置
int nextRow = row + directions[dirIndex][0];
int nextCol = col + directions[dirIndex][1];
// 如果下一个位置超出边界或已访问,则改变方向
if (nextRow < 0 || nextRow >= m || nextCol < 0 || nextCol >= n || visited[nextRow][nextCol]) {
dirIndex = (dirIndex + 1) % 4; // 顺时针旋转,切换到下一个方向
nextRow = row + directions[dirIndex][0];
nextCol = col + directions[dirIndex][1];
}
// 更新当前位置
row = nextRow;
col = nextCol;
}
return result;
}
}
4.3 代码详解
详细解释每一步的意义和实现:
// 创建访问标记数组,初始值为false,表示未访问
boolean[][] visited = new boolean[m][n];
- 创建一个与矩阵大小相同的布尔数组,用于标记元素是否已被访问
- 初始值都为
false,表示所有元素都未被访问
// 定义四个方向:向右、向下、向左、向上
int[][] directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
int dirIndex = 0; // 初始方向为向右
- 定义一个二维数组
directions,表示四个方向的行列变化 {0, 1}表示向右移动(行不变,列加1){1, 0}表示向下移动(行加1,列不变){0, -1}表示向左移动(行不变,列减1){-1, 0}表示向上移动(行减1,列不变)dirIndex变量记录当前的方向,初始值为0,表示向右
// 开始位置为矩阵左上角
int row = 0, col = 0;
- 设置初始位置为矩阵的左上角,即(0, 0)
// 遍历所有元素
for (int i = 0; i < m * n; i++) {
result.add(matrix[row][col]);
visited[row][col] = true;
// 计算下一个位置
int nextRow = row + directions[dirIndex][0];
int nextCol = col + directions[dirIndex][1];
// 如果下一个位置超出边界或已访问,则改变方向
if (nextRow < 0 || nextRow >= m || nextCol < 0 || nextCol >= n || visited[nextRow][nextCol]) {
dirIndex = (dirIndex + 1) % 4; // 顺时针旋转,切换到下一个方向
nextRow = row + directions[dirIndex][0];
nextCol = col + directions[dirIndex][1];
}
// 更新当前位置
row = nextRow;
col = nextCol;
}
- 总共需要遍历m×n个元素,所以循环m×n次
- 在每次循环中,将当前位置的元素添加到结果列表中,并标记为已访问
- 根据当前方向计算下一个位置的坐标
- 如果下一个位置超出矩阵边界或已经被访问过,就顺时针旋转到下一个方向
- 使用
(dirIndex + 1) % 4实现方向的循环变化:0->1->2->3->0->… - 计算新的下一个位置,并更新当前位置
4.4 复杂度分析
- 时间复杂度: O(m×n),其中 m 是矩阵的行数,n 是矩阵的列数。每个元素只被访问一次。
- 空间复杂度: O(m×n),需要一个与矩阵大小相同的布尔数组来标记已访问的元素。
4.5 与解法一的比较
两种解法的核心思想不同:
- 解法一:维护四个边界变量,明确地按照上、右、下、左的顺序遍历四个边界
- 解法二:使用方向数组,根据当前位置和方向动态决定下一步的移动
各有优缺点:
- 解法一更直观,代码结构更清晰,适合逻辑思路清晰的面试者
- 解法二更灵活,易于扩展到其他类型的矩阵遍历问题,但需要额外的空间来记录已访问的元素
- 解法一的空间复杂度更低,为O(1),而解法二为O(m×n)
5. 解法三:层次遍历法
5.1 思路
第三种解法是按照层次来遍历矩阵,将矩阵看作是由多个"层"组成的,从外到内一层一层地遍历:
- 定义层次的边界:上边界
topRow、右边界rightCol、下边界bottomRow、左边界leftCol - 从外层开始,逐层向内遍历
- 对于每一层,按照顺时针顺序遍历该层的四条边
- 遍历完一层后,将四个边界分别向内收缩,进入下一层的遍历
这种方法的优点是思路清晰,易于理解,且无需使用额外的空间来记录已访问的元素。
5.2 Java代码实现
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> result = new ArrayList<>();
// 处理边界情况
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return result;
}
int m = matrix.length;
int n = matrix[0].length;
// 定义层次的边界
int topRow = 0;
int rightCol = n - 1;
int bottomRow = m - 1;
int leftCol = 0;
// 层次遍历
while (topRow <= bottomRow && leftCol <= rightCol) {
// 遍历当前层的上边
for (int j = leftCol; j <= rightCol; j++) {
result.add(matrix[topRow][j]);
}
// 遍历当前层的右边
for (int i = topRow + 1; i <= bottomRow; i++) {
result.add(matrix[i][rightCol]);
}
// 如果当前层不止一行,则遍历下边
if (topRow < bottomRow) {
for (int j = rightCol - 1; j >= leftCol; j--) {
result.add(matrix[bottomRow][j]);
}
}
// 如果当前层不止一列,则遍历左边
if (leftCol < rightCol) {
for (int i = bottomRow - 1; i > topRow; i--) {
result.add(matrix[i][leftCol]);
}
}
// 向内收缩,进入下一层
topRow++;
rightCol--;
bottomRow--;
leftCol++;
}
return result;
}
}
5.3 代码详解
详细解释每一步的意义和实现:
// 定义层次的边界
int topRow = 0;
int rightCol = n - 1;
int bottomRow = m - 1;
int leftCol = 0;
- 定义四个变量表示当前层的四个边界
topRow表示上边的行索引rightCol表示右边的列索引bottomRow表示下边的行索引leftCol表示左边的列索引
// 层次遍历
while (topRow <= bottomRow && leftCol <= rightCol) {
// 遍历当前层的四条边
// ...
// 向内收缩,进入下一层
topRow++;
rightCol--;
bottomRow--;
leftCol++;
}
- 使用循环实现层次遍历,从外层开始,逐层向内
- 循环继续的条件是上边界不超过下边界,且左边界不超过右边界
- 遍历完一层后,四个边界同时向内收缩,为下一层的遍历做准备
// 遍历当前层的上边
for (int j = leftCol; j <= rightCol; j++) {
result.add(matrix[topRow][j]);
}
- 遍历当前层的上边,行索引固定为
topRow,列索引从leftCol到rightCol
// 遍历当前层的右边
for (int i = topRow + 1; i <= bottomRow; i++) {
result.add(matrix[i][rightCol]);
}
- 遍历当前层的右边,列索引固定为
rightCol,行索引从topRow+1到bottomRow - 从
topRow+1开始是为了避免重复遍历右上角的元素
// 如果当前层不止一行,则遍历下边
if (topRow < bottomRow) {
for (int j = rightCol - 1; j >= leftCol; j--) {
result.add(matrix[bottomRow][j]);
}
}
- 只有当
topRow < bottomRow,即当前层至少有两行时,才需要遍历下边 - 遍历下边时,行索引固定为
bottomRow,列索引从rightCol-1到leftCol - 从
rightCol-1开始是为了避免重复遍历右下角的元素
// 如果当前层不止一列,则遍历左边
if (leftCol < rightCol) {
for (int i = bottomRow - 1; i > topRow; i--) {
result.add(matrix[i][leftCol]);
}
}
- 只有当
leftCol < rightCol,即当前层至少有两列时,才需要遍历左边 - 遍历左边时,列索引固定为
leftCol,行索引从bottomRow-1到topRow+1 - 从
bottomRow-1开始是为了避免重复遍历左下角的元素 - 行索引到
topRow+1为止,而不是到topRow,是为了避免重复遍历左上角的元素
5.4 复杂度分析
- 时间复杂度: O(m×n),其中 m 是矩阵的行数,n 是矩阵的列数。每个元素只被访问一次。
- 空间复杂度: O(1),除了存储结果的列表外,只使用了常数额外空间。
5.5 与其他解法的比较
层次遍历法与四边界模拟法(解法一)很相似,主要区别在于:
- 解法一在每次迭代中单独遍历每条边,且需要单独检查边界条件
- 层次遍历法将四条边的遍历组织在一个清晰的层次结构中,并使用两个条件语句处理特殊情况
层次遍历法的优点:
- 思路更加清晰,按照从外到内的层次逐层处理
- 代码结构简洁,易于理解和维护
- 无需使用额外空间来记录已访问的元素(相比方向数组法)
总体来说,层次遍历法是一种结合了四边界模拟法的直观性和方向数组法的简洁性的方法,是解决螺旋矩阵问题的优秀解法。
6. 详细步骤分析与示例跟踪
让我们通过几个具体的例子,详细跟踪每种解法的执行过程,以加深理解。
6.1 示例1跟踪:3×3矩阵
以示例1中的3×3矩阵为例:
[
[1,2,3],
[4,5,6],
[7,8,9]
]
使用解法一(四边界模拟法)跟踪:
-
初始化:
- 边界:top = 0, right = 2, bottom = 2, left = 0
- 结果:result = []
-
第一轮循环:
-
遍历上边界:添加matrix[0][0], matrix[0][1], matrix[0][2],即1, 2, 3
-
更新top = 1
-
结果:result = [1, 2, 3]
-
遍历右边界:添加matrix[1][2], matrix[2][2],即6, 9
-
更新right = 1
-
结果:result = [1, 2, 3, 6, 9]
-
遍历下边界:添加matrix[2][1], matrix[2][0],即8, 7
-
更新bottom = 1
-
结果:result = [1, 2, 3, 6, 9, 8, 7]
-
遍历左边界:添加matrix[1][0],即4
-
更新left = 1
-
结果:result = [1, 2, 3, 6, 9, 8, 7, 4]
-
-
第二轮循环:
-
遍历上边界:添加matrix[1][1],即5
-
更新top = 2
-
结果:result = [1, 2, 3, 6, 9, 8, 7, 4, 5]
-
此时top > bottom,循环结束
-
-
最终结果:[1, 2, 3, 6, 9, 8, 7, 4, 5]
使用解法二(方向数组模拟法)跟踪:
-
初始化:
- m = 3, n = 3
- visited = [[false, false, false], [false, false, false], [false, false, false]]
- directions = [[0, 1], [1, 0], [0, -1], [-1, 0]]
- dirIndex = 0
- row = 0, col = 0
- 结果:result = []
-
遍历过程:
-
当前位置:(0, 0),添加1,标记为已访问
-
下一个位置:(0, 1),未访问,更新当前位置
-
结果:result = [1]
-
当前位置:(0, 1),添加2,标记为已访问
-
下一个位置:(0, 2),未访问,更新当前位置
-
结果:result = [1, 2]
-
当前位置:(0, 2),添加3,标记为已访问
-
下一个位置:(0, 3),超出边界,改变方向为向下
-
新的下一个位置:(1, 2),未访问,更新当前位置
-
结果:result = [1, 2, 3]
-
继续遍历…
-
-
最终结果:[1, 2, 3, 6, 9, 8, 7, 4, 5]
6.2 示例2跟踪:非方阵
以示例2中的3×4矩阵为例:
[
[1,2,3,4],
[5,6,7,8],
[9,10,11,12]
]
使用解法三(层次遍历法)跟踪:
-
初始化:
- m = 3, n = 4
- topRow = 0, rightCol = 3, bottomRow = 2, leftCol = 0
- 结果:result = []
-
第一轮循环:
- 遍历上边:添加matrix[0][0]到matrix[0][3],即1, 2, 3, 4
- 遍历右边:添加matrix[1][3]到matrix[2][3],即8, 12
- 遍历下边:添加matrix[2][2]到matrix[2][0],即11, 10, 9
- 遍历左边:添加matrix[1][0],即5
- 更新边界:topRow = 1, rightCol = 2, bottomRow = 1, leftCol = 1
- 结果:result = [1, 2, 3, 4, 8, 12, 11, 10, 9, 5]
-
第二轮循环:
- 遍历上边:添加matrix[1][1]和matrix[1][2],即6, 7
- 遍历右边:没有元素需要遍历
- 遍历下边:没有元素需要遍历
- 遍历左边:没有元素需要遍历
- 更新边界:topRow = 2, rightCol = 1, bottomRow = 0, leftCol = 2
- 结果:result = [1, 2, 3, 4, 8, 12, 11, 10, 9, 5, 6, 7]
-
循环终止:topRow > bottomRow,循环结束
-
最终结果:[1, 2, 3, 4, 8, 12, 11, 10, 9, 5, 6, 7]
6.3 特殊情况跟踪:单行矩阵
考虑一个单行矩阵:
[
[1,2,3]
]
使用解法一(四边界模拟法)跟踪:
-
初始化:
- 边界:top = 0, right = 2, bottom = 0, left = 0
- 结果:result = []
-
第一轮循环:
-
遍历上边界:添加matrix[0][0], matrix[0][1], matrix[0][2],即1, 2, 3
-
更新top = 1
-
结果:result = [1, 2, 3]
-
此时top > bottom,循环结束
-
-
最终结果:[1, 2, 3]
6.4 特殊情况跟踪:单列矩阵
考虑一个单列矩阵:
[
[1],
[2],
[3]
]
使用解法一(四边界模拟法)跟踪:
-
初始化:
- 边界:top = 0, right = 0, bottom = 2, left = 0
- 结果:result = []
-
第一轮循环:
-
遍历上边界:添加matrix[0][0],即1
-
更新top = 1
-
结果:result = [1]
-
遍历右边界:添加matrix[1][0], matrix[2][0],即2, 3
-
更新right = -1
-
结果:result = [1, 2, 3]
-
此时left > right,循环结束
-
-
最终结果:[1, 2, 3]
6.5 动态图示
以下是螺旋矩阵遍历过程的动态示意:
3×3矩阵示例:
→ → →
↑ ↓
↑ ← ← ↓
3×4矩阵示例:
→ → → →
↑ ↓
↑ ← ← ← ↓
7. 常见错误与优化
7.1 常见错误
-
边界条件处理不当:
最常见的错误是在处理矩阵的边界时出错,特别是在处理单行或单列矩阵时。// 错误写法:没有检查边界条件 for (int j = right; j >= left; j--) { result.add(matrix[bottom][j]); } // 正确写法:先检查是否还有行需要遍历 if (top <= bottom) { for (int j = right; j >= left; j--) { result.add(matrix[bottom][j]); } } -
遍历顺序错误:
错误地定义螺旋遍历的顺序,导致结果不符合预期。// 错误写法:顺序混乱 // 从左到右遍历上边界 // 从右到左遍历下边界 // 从上到下遍历右边界 // 从下到上遍历左边界 // 正确写法:明确的顺时针顺序 // 从左到右遍历上边界 // 从上到下遍历右边界 // 从右到左遍历下边界 // 从下到上遍历左边界 -
更新边界顺序错误:
在使用四边界模拟法时,如果边界更新顺序错误,可能导致重复遍历或遗漏元素。// 错误写法:更新边界的顺序错误 top++; left++; bottom--; right--; // 正确写法:先处理横向边界,再处理纵向边界 top++; bottom--; left++; right--; -
未正确处理特殊情况:
未正确处理空矩阵、单行矩阵或单列矩阵等特殊情况。// 错误写法:没有处理空矩阵情况 public List<Integer> spiralOrder(int[][] matrix) { List<Integer> result = new ArrayList<>(); int m = matrix.length; int n = matrix[0].length; // 如果matrix为空,这里会抛出异常 // ... } // 正确写法:先检查矩阵是否为空 public List<Integer> spiralOrder(int[][] matrix) { List<Integer> result = new ArrayList<>(); if (matrix == null || matrix.length == 0 || matrix[0].length == 0) { return result; } // ... } -
方向数组使用不当:
在使用方向数组模拟法时,方向的顺序或更新逻辑错误。// 错误写法:方向数组定义错误 int[][] directions = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}}; // 顺序错误 // 正确写法:按照顺时针顺序定义方向 int[][] directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}}; // 右、下、左、上
7.2 性能优化
-
减少边界检查:
在一些实现中,可以减少不必要的边界检查,提高代码执行效率。// 优化前:每次遍历都检查边界条件 if (top <= bottom) { for (int j = right; j >= left; j--) { result.add(matrix[bottom][j]); } } // 优化后:使用循环条件隐含边界检查 while (top <= bottom && left <= right) { // 从左到右遍历上边界 for (int j = left; j <= right; j++) { result.add(matrix[top][j]); } top++; // 从上到下遍历右边界 for (int i = top; i <= bottom; i++) { result.add(matrix[i][right]); } right--; // 检查是否还有元素未被遍历 if (top <= bottom) { // 从右到左遍历下边界 for (int j = right; j >= left; j--) { result.add(matrix[bottom][j]); } bottom--; } if (left <= right) { // 从下到上遍历左边界 for (int i = bottom; i >= top; i--) { result.add(matrix[i][left]); } left++; } } -
预分配结果列表的容量:
如果知道矩阵的大小,可以预先分配结果列表的容量,减少扩容操作。// 优化前:动态扩容 List<Integer> result = new ArrayList<>(); // 优化后:预分配容量 List<Integer> result = new ArrayList<>(m * n); -
使用数组而非列表作为中间结果:
如果对性能要求极高,可以使用数组而非列表作为中间结果,避免装箱/拆箱操作和动态扩容的开销。// 优化前:使用List List<Integer> result = new ArrayList<>(); // 优化后:使用数组 int[] result = new int[m * n]; int index = 0; // 在遍历过程中,使用result[index++] = matrix[i][j]添加元素 -
避免使用额外空间:
在方向数组模拟法中,可以考虑使用原矩阵本身来标记已访问的元素,而不是使用额外的visited数组,但这会修改原矩阵。// 优化前:使用额外的visited数组 boolean[][] visited = new boolean[m][n]; // 优化后:直接修改原矩阵(如果允许) // 可以使用一个特殊值(如Integer.MIN_VALUE)标记已访问的元素 -
简化层次遍历的条件判断:
在层次遍历法中,可以采用更简洁的条件判断方式。// 优化前:每条边都单独判断是否需要遍历 if (topRow < bottomRow) { // 遍历下边 } if (leftCol < rightCol) { // 遍历左边 } // 优化后:使用统一的循环条件控制 while (topRow <= bottomRow && leftCol <= rightCol) { // 遍历上边(必须执行) for (int j = leftCol; j <= rightCol; j++) { result.add(matrix[topRow][j]); } topRow++; // 如果还有行未遍历,则遍历右边 if (topRow <= bottomRow) { for (int i = topRow; i <= bottomRow; i++) { result.add(matrix[i][rightCol]); } rightCol--; } else { break; // 提前结束循环 } // 如果还有列未遍历,则遍历下边 if (leftCol <= rightCol) { for (int j = rightCol; j >= leftCol; j--) { result.add(matrix[bottomRow][j]); } bottomRow--; } else { break; // 提前结束循环 } // 如果还有行未遍历,则遍历左边 if (topRow <= bottomRow) { for (int i = bottomRow; i >= topRow; i--) { result.add(matrix[i][leftCol]); } leftCol++; } else { break; // 提前结束循环 } }
这些优化通常适用于大型矩阵或需要高性能的场景。对于普通的面试场景,解法一或解法三已经足够高效。
8. 扩展题目与应用
8.1 相关矩阵遍历问题
-
LeetCode 59. 螺旋矩阵 II:
给定一个正整数 n,生成一个包含 1 到 n² 所有元素,且元素按顺时针螺旋排列的 n x n 正方形矩阵。这是螺旋矩阵的逆问题,需要按照螺旋顺序填充矩阵,而不是遍历矩阵。解法思路与螺旋矩阵相似,只是将读取操作变为写入操作。
-
LeetCode 885. 螺旋矩阵 III:
在 R 行 C 列的矩阵上,我们从 (r0, c0) 开始,顺时针螺旋行走,每次行走到矩阵中的未访问过的单元格。返回访问过的单元格坐标的列表。 -
LeetCode 2326. 矩阵中的不可行路径:
给你一个 m x n 的矩阵和一个链表头节点 head,按照螺旋顺序访问矩阵,同时将链表中的值依次填入矩阵。
8.2 其他遍历问题
-
LeetCode 74. 搜索二维矩阵:
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。虽然不是螺旋遍历,但也涉及矩阵的有效搜索。 -
LeetCode 48. 旋转图像:
给定一个 n × n 的二维矩阵表示一个图像,将图像顺时针旋转 90 度。这与螺旋矩阵的顺时针遍历有关联。 -
LeetCode 240. 搜索二维矩阵 II:
编写一个高效的算法来搜索 m x n 矩阵中的一个目标值,矩阵具有特定的排序特性。
9. 实际应用场景
螺旋矩阵算法在实际应用中有多种用途:
-
图像处理:
- 某些图像处理算法需要从中心向外或从外向内螺旋遍历像素
- 例如,某些图像压缩算法可能使用螺旋序列来组织像素,从而更好地保留相关性
-
数据可视化:
- 在某些数据可视化技术中,数据点可能按螺旋方式排列,以有效利用空间
- 例如,螺旋树图(Spiral Treemaps)用于可视化层次数据结构
-
芯片设计:
- 在集成电路设计中,某些布线算法可能使用螺旋模式来优化信号路径
- 天线设计中也可能使用螺旋模式来优化接收特性
-
机器人路径规划:
- 自主机器人在探索未知环境时,可能采用螺旋路径以确保全面覆盖
- 例如,扫地机器人通常使用螺旋模式来覆盖房间的地板
-
游戏开发:
- 在游戏地图或关卡设计中,可能使用螺旋模式来组织游戏元素
- 某些策略游戏的地图生成算法可能使用螺旋遍历来分配资源或地形
-
数学教育:
- 螺旋矩阵是教授矩阵遍历、边界处理和方向变换的优秀实例
- 可用于解释递归和迭代算法的差异
10. 完整的 Java 解决方案
以下是结合了各种优化和最佳实践的完整解决方案:
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
// 处理边界情况
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return new ArrayList<>();
}
int m = matrix.length;
int n = matrix[0].length;
List<Integer> result = new ArrayList<>(m * n); // 预分配容量
// 定义四个边界
int top = 0;
int right = n - 1;
int bottom = m - 1;
int left = 0;
// 循环遍历,直到所有元素都被访问
while (top <= bottom && left <= right) {
// 从左到右遍历上边界
for (int j = left; j <= right; j++) {
result.add(matrix[top][j]);
}
top++; // 上边界下移
// 从上到下遍历右边界
for (int i = top; i <= bottom; i++) {
result.add(matrix[i][right]);
}
right--; // 右边界左移
// 检查是否还有行未被遍历
if (top <= bottom) {
// 从右到左遍历下边界
for (int j = right; j >= left; j--) {
result.add(matrix[bottom][j]);
}
bottom--; // 下边界上移
}
// 检查是否还有列未被遍历
if (left <= right) {
// 从下到上遍历左边界
for (int i = bottom; i >= top; i--) {
result.add(matrix[i][left]);
}
left++; // 左边界右移
}
}
return result;
}
}
此解决方案使用四边界模拟法,具有以下特点:
- 全面处理边界情况,包括空矩阵检查
- 预分配结果列表的容量,优化内存使用
- 使用清晰的边界变量和遍历顺序,提高代码可读性
- 加入必要的条件检查,确保正确处理矩阵中的所有元素
- 结构清晰,易于理解和维护
该解决方案在LeetCode上的表现非常好,执行时间和内存使用都处于优秀水平。
11. 总结与技巧
11.1 解题要点
-
理解螺旋遍历的基本模式:
- 顺时针遍历:右→下→左→上
- 每遍历完一圈后,边界向内收缩
- 最终可能剩下一行、一列或一个元素
-
边界处理的重要性:
- 正确定义和更新边界是解决螺旋矩阵问题的关键
- 特别注意边界相等的情况,如单行或单列矩阵
-
条件检查的必要性:
- 在遍历下边界和左边界之前,需要检查是否还有行或列未被遍历
- 这是避免重复遍历元素的重要步骤
-
解法选择的考虑因素:
- 四边界模拟法:直观,空间效率高,适合大多数场景
- 方向数组模拟法:灵活,易于扩展,但需要额外空间
- 层次遍历法:思路清晰,代码结构优美,是解决此类问题的优秀方法
11.2 学习收获
通过学习螺旋矩阵问题,你可以掌握:
- 二维数组的遍历技巧和模式
- 边界条件的处理方法
- 方向变换的控制策略
- 循环不变量的维护技巧
- 多种解法的权衡与选择
11.3 面试技巧
如果在面试中遇到此类问题:
- 先分析问题,理解螺旋遍历的模式
- 从简单例子开始,手动跟踪螺旋遍历的过程
- 明确选择一种解法,并清晰地解释思路
- 特别关注边界情况的处理,如空矩阵、单行或单列矩阵
- 讨论可能的优化方向,如内存使用或执行效率的改进
螺旋矩阵是一个经典问题,掌握其解法不仅能够应对面试,还能帮助理解更复杂的矩阵操作问题。



















 27
27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











