







本文约3500字,建议阅读7分钟
本论文提出了一种新颖的超声心动图视频分割模型 MemSAM,将 SAM 应用于医学视频。
深圳大学计算机与软件学院和香港理工大学智能健康研究中心联合提出了一种新颖的超声心动图视频分割模型 MemSAM,与现有模型相比展示了最先进的性能。
根据世界卫生组织 (WHO) 的统计数据,心血管疾病是全球死亡的主要原因,每年夺走约 1,790 万人的生命,占全球死亡人数的 32%。超声心动图是用于心血管疾病的超声诊断技术,由于其便携性、低成本和实时性,被广泛应用于临床实践。然而,超声心动图需要有经验的医生进行人工评估,且评估质量很大程度上依赖于医生的专业知识与临床经验,这导致评估结果常常会出现较大的观察者间和观察者内差异 (inter- and intra-observer differences)。因此,临床实践迫切需要自动化的评估方法。
近年来,许多深度学习方法被提出用于超声心动图视频分割。然而,由于超声视频质量低且注释有限,这些方法仍无法取得令人满意的结果。近期,一个大型视觉模型——Segment Anything Model (SAM) 受到了高度关注,在许多自然图像分割任务中取得了显著成功,但如何将 SAM 应用于医学视频分割仍是一项颇具挑战性的任务。
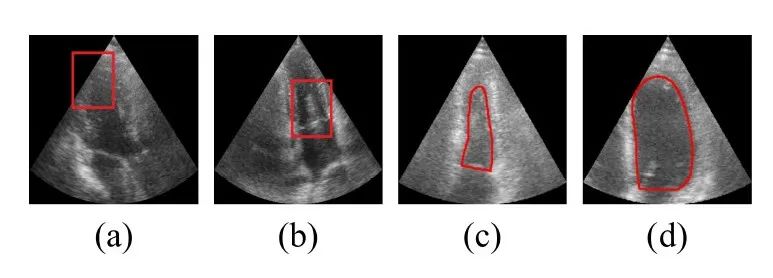
超声心动图视频评估的挑战
(a) 轮廓模糊,(b) 斑点噪声,(c-d) 跨帧尺度变化
基于此,由深圳大学计算机与软件学院和香港理工大学智能健康研究中心联合组成的团队,在计算机视觉顶级会议 CVPR 2024 上发布了题为「MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation」的论文。在论文中,研究人员提出了一种新颖的超声心动图视频分割模型 MemSAM,将 SAM 应用于医学视频。

论文成功入围 CVPR2024 最佳论文的候选名单
该模型使用包含时空信息的记忆作为提示当前帧的分割,并使用记忆强化机制在存储记忆之前提高记忆质量。在公开数据集的实验表明,该模型以少量点提示实现了最先进的性能,并以有限的注释实现了与完全监督方法相当的性能,大大降低了视频分割任务所需的提示和注释要求。
研究亮点:
本研究使用包含时空信息的记忆作为提示当前帧的分割,以提高表示的一致性和分割精度;
研究人员进一步提出了记忆增强模块,以在存储记忆之前增强记忆,从而减轻记忆提示过程中斑点噪声和运动伪影的不利影响;
新模型与现有模型相比展示了最先进的性能,特别是其在有限注释的情况下实现了与完全监督方法相当的性能。

论文地址:
https://github.com/dengxl0520/MemSAM
数据集:2 个公开可用的超声心动图数据集
研究人员在 2 个广泛使用的公开可用的超声心动图数据集 CAMUS 和 EchoNet-Dynamic 上评估了其方法:
CAMUS 数据集包含 500 个病例,包括 2D 心尖二腔和心尖四腔视图视频,同时还提供了所有帧的标注。
EchoNet-Dynamic 数据集包含 10,030 个 2D 心尖二腔视图视频。每个视频以积分的形式提供左心室的面积,仅标注了舒张末期 (ED) 和收缩末期 (ES) 的相位。
为了全面评估新方法在半监督视频分割中的有效性,研究人员将 CAMUS 数据集改编为两个变体:CAMUS-Full 和 CAMUS-Semi。CAMUS-Full 在训练期间使用所有帧的标注,而 CAMUS-Semi 仅使用舒张末期 (ED) 和收缩末期 (ES) 帧的标注。在测试期间,这两个数据集都使用完整的标注进行评估。
研究人员从数据集中均匀采样视频,并将它们裁剪到每个 10 帧。裁剪确保 ED 帧是第一帧,ES 帧是最后一帧,分辨率调整为 256×256。并将 CAMUS 数据集按照 7:1:2 的比例,划分为训练集、验证集和测试集。
模型架构:SAM 组件和记忆组件构筑 MemSAM 总体框架
MemSAM 模型的总体框架如下图所示,由 SAM 组件和 Memory 组件两个部分组成。
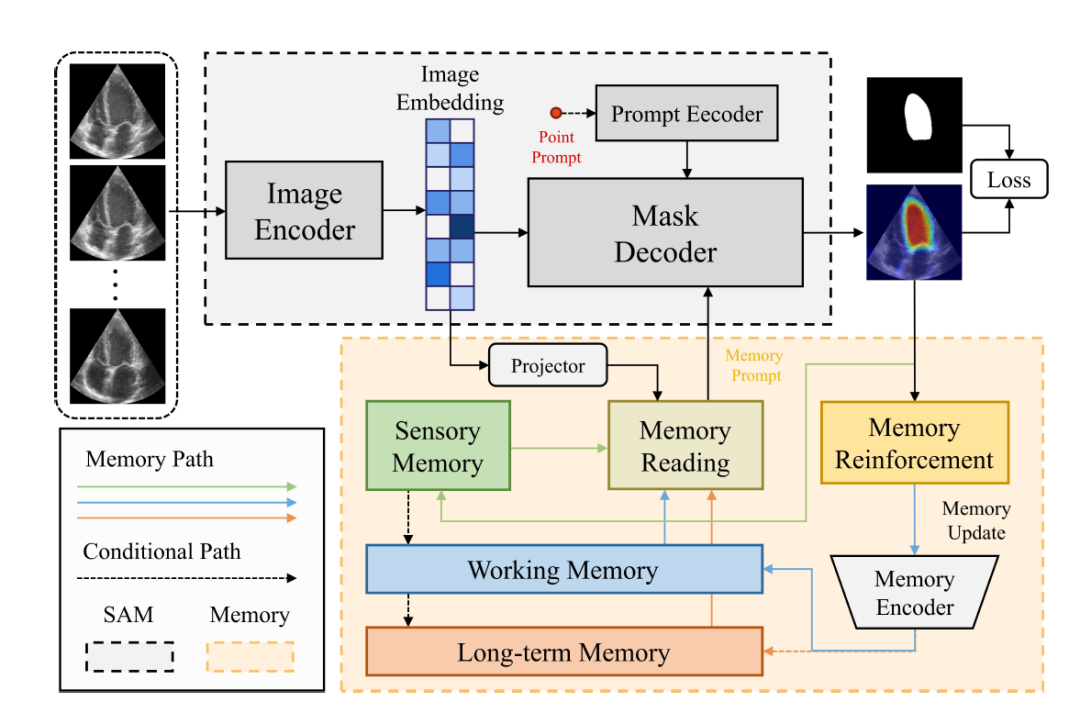
MemSAM 总体框架
图中灰色底部分为 SAM,橙色底部分为 Memory
SAM 组件采用与原始 SAM 相同的架构,由图像编码器 (Image Encoder)、提示编码器 (Prompt Encoder) 和掩码解码器 (Mask Decoder) 组成。
图像编码器采用 Vision Transformer (ViT) 作为 backbone,将输入图像编码为图像向量 (Image Embedding)。
提示编码器接收外部提示,如点提示 (Point Prompt),并将它们编码为一个 c 维度向量 (a c-dimensional embedding)。随后,掩码解码器结合图像和提示向量来预测分割掩码。
在这些组件中,图像向量通过投影层 (projection layer) 映射到记忆特征空间,然后研究人员进行记忆读取 (Memory Reading),从多重特征记忆(如感觉记忆 Sensory Memory、工作记忆 Working Memory 和长期记忆 Long-term Memory)中获得记忆提示 (Memory Prompt),并将其提供给掩码解码器。最后,通过记忆增强 (Memory Reinforcement) 和记忆编码器 (Memory Encoder) 后,记忆将被更新。
下图进一步展示了记忆读取、记忆增强和记忆更新 (Memory Update) 过程中的更多细节:
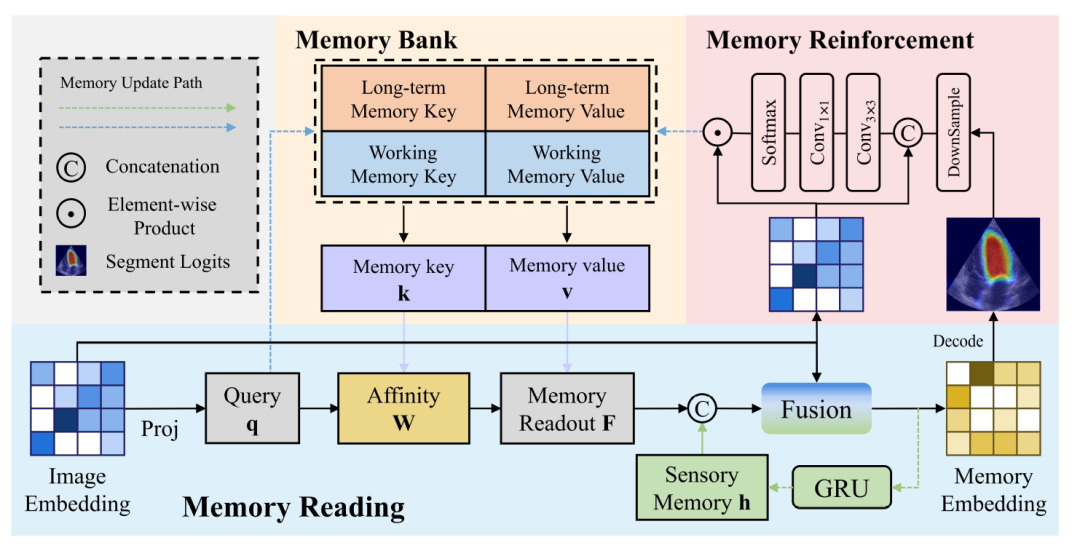
记忆读取、记忆增强和记忆更新的更多细节
* 记忆读取
记忆读取块展示了从图像向量生成记忆向量的过程。图像向量通过投影生成查询 (Query),随后针对记忆值亲和力 (Affinity) 查询得到记忆读出,最后记忆读出将与感觉记忆 (Sensory Memory) 和图像向量融合得到记忆向量。
* 记忆增强
与自然图像相比,超声图像包含更复杂的噪声,这意味着由图像编码器生成的图像向量不可避免地会携带噪声。如果在没有任何处理的情况下将这些噪声特征更新到记忆中,可能会导致错误的累积和传播。
为了减轻噪声对记忆更新的影响,需要采用记忆增强模块来增强记忆中特征表示的可辨识性。记忆增强块首先串联图像向量和预测概率图,随后通过 3×3 卷积限制每个像素的感受野 (receptive field) 从而生成局部权重特征 (local attention weight feature)。
* 记忆更新
最后通过 Softmax 函数和图像向量的点积得到将要被更新至记忆库的输出特征。
研究结果:MemSAM 在有限注释下实现了最佳性能
为了验证 MemSAM 的性能,研究人员广泛选择了不同类型的对比方法,包括传统图像分割模型和医学基础模型。三个传统的图像分割模型分别是基于 CNN 的 UNet、基于 Transformer 的 SwinUNet 和 CNN-Transformer 混合的 H2Former。适用于医学领域的 SAM 模型包括 MedSAM、MSA、SAMed、SonoSAM 和 SAMUS。其中,SonoSAM 和 SAMUS 专注于超声图像。
首先是定量比较结果,如下表所示:
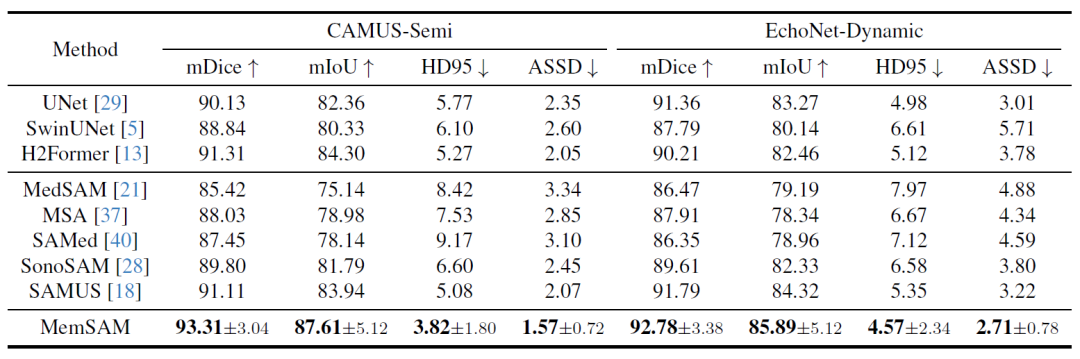
在 CAMUS-Semi 和 EchoNet-Dynamic 数据集上
研究方法与最先进方法的分割性能对比
在这些最新的方法中,得益于 CNN-Transformer 架构和超声图像优化,H2Former 和 SAMUS 在两个数据集上表现相对较好。然而,在稀缺注释、不利用视频时间属性的情况下,上述模型均落后于本研究提出的方法。实验验证了 MemSAM 在有限注释的情况下实现了最佳的性能。
为了进一步评估 MemSAM,研究人员还在相同设置下对 CAMUS-Semi 和 CAMUS-Full 数据集进行了比较。结果如下图所示:
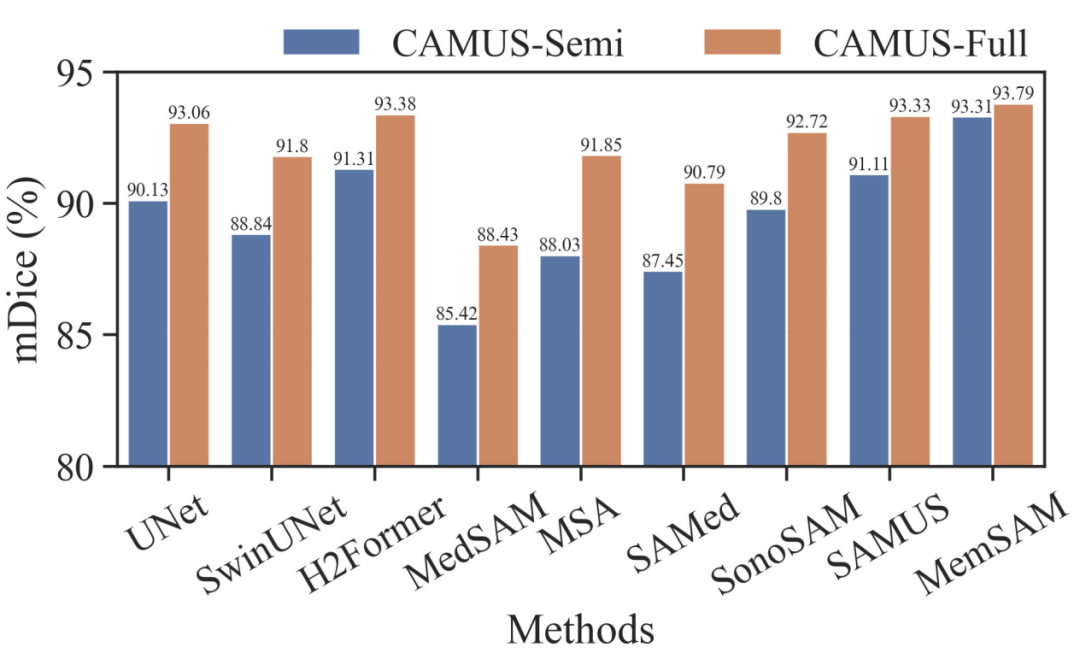
在 CAMUS-Semi 和 CAMUS-Full 数据集上
研究方法与最先进方法的分割性能对比
可以看出,像 UNet 和 H2Former 这样的传统方法,以及像 SonoSAM 和 SAMUS 这样的超声特化方法,在给出完整注释时可以恢复不错的分割结果。尽管本研究的方法从半监督到全监督设置的增益较小,但在这两种情况下仍然优于其他竞争对手。
值得注意的是,医学基础模型在全监督下需要每帧提示,而 MemSAM 只需要一个点提示。实验验证了本研究提出的方法在稀疏标签下以远少于外部提示的方式实现了与全注释相当的性能。
其次是定性比较结果,研究人员为一些具有挑战性的案例提供了可视化结果,如下图所示:

在 CAMUS-Semi 测试集上与最先进方法的直观对比
绿色、红色和黄色区域分别代表有效区域、预测和重叠区域
上图第 1-2 行的图像包含左心室周围的斑点噪声,误导了一些传统和医学基础模型错误地将其识别为心室边缘。第 3-4 行包含边界严重模糊的实例,几乎所有对比模型给出的结果都超出了真正的心室边界,而本研究提出的方法精确地勾勒出了边界。这些可视化结果表明本研究提出的方法在处理图像质量差的情况下具有鲁棒性。
AI 为心血管病防治带来新思路
心血管疾病是心脏和血管疾病的一个类别,包括冠心病、脑血管病、风湿性心脏病和其他疾病。现代社会,由于人们不健康的饮食、缺乏身体活动、吸烟酗酒,进一步增加了心血管疾病的发病风险。
近年来,随着人工智能、大数据等技术的发展,「AI+医疗」步入发展快车道,AI 在心血管疾病的诊断和预测领域已经取得广泛进展,如 AI 结合心电图和心血管影像数据可实现精准诊断,AI 联合心血管影像数据和其他临床数据可实现冠状动脉疾病、先天性心脏病、心力衰竭等心血管疾病的早期筛查和风险预测。
举例来看:心音的精确分类是心血管疾病早期诊断和干预领域的关键。人工心音听诊的效果仍然依赖于医生的专业知识,但这种形势正悄然改变。2023 年 11 月,中国医学科学院阜外医院(阜外医院)潘湘斌团队在 Alexandria Engineering Journal 在线发表题为「Heart sound classification based on bispectrum features and Vision Transformer mode」的研究论文,该研究基于双谱启发的特征提取和视觉转换器模型,实现了对心音的二元分类。
模型在全人群(包括怀孕和非怀孕患者)中体现出极好的分类效果,诊断效能优于人类专家,体现出了极大的应用潜力。
2023 年 10 月,发表在「临床医学」杂志上的新研究数据表明,通过识别冠状动脉疾病的迹象,如钙化和堵塞,以及先前心脏病发作的证据,ECG-AI 可以比目前的风险计算器方程式早几年标记出一些风险。
就在近日,英国一家名为 Caristo Diagnostics 的公司在「柳叶刀」上发表了一项具有里程碑意义的临床研究结果,他们的 CaRi-Heart AI 技术可量化冠状动脉炎症的严重程度并准确预测心脏疾病。

图源:Caristo 公司官网
Caristo 公司由牛津大学心脏病专家创立于 2018 年,该公司 50 多年前就已有重磅研究发现——心脏病发作是由冠状动脉的炎症引起的,但临床医生一直无法通过常规心脏检查来观察和测量炎症的情况。而现在可以使用 CaRi-Heart 技术从患者心脏的 CTTA 扫描中提取这方面信息,这标志着一项科学突破,从根本上改变了心脏病预测、预防和管理的传统方法。据悉,CaRi-Heart 已经在英国、欧洲和澳大利亚投入临床使用。
展望未来,人工智能在临床诊疗尤其是心血管病防治方面,具有巨大的发展潜力,将助力医生更加高效、可靠的为患者提供精确的诊断和建议。
参考资料:
1.https://m.chinacdc.cn/jkzt/mxfcrjbhsh/jcysj/201909/t20190906_205347.html
2.https://mp.weixin.qq.com/s/daqoXwnxeZxw7xC6iw1h3A
3.https://www.drvoice.cn/v2/article/12166
4.https://36kr.com/p/2800805951747718
编辑:于腾凯
校对:邱婷婷
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









