







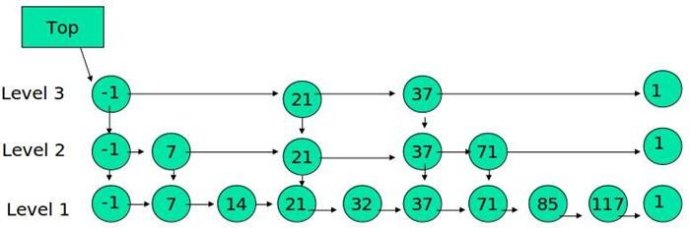
leveldb中的memtable只是一个封装类,它的底层实现是一个跳表。跳表是一种基于随机数的平衡数据结构,其他的平衡数据结构还有红黑树、AVL树,但跳表的原理比它们简单很多。跳表有点像链表,只不过每个节点是多层结构,通过在每个节点中增加向前的指针提高查找效率。如下图:
在/leveldb/db文件夹下有跳表的实现skiplist.h和跳表的测试程序skiplist_test.cc。
template<typename Key, class Comparator>
class SkipList {可以看出leveldb的skiplist是一个模板类,key是跳表每个节点存储的信息类,跳表是一个顺序结构,comparator是跳表key的比较器。
成员变量:
private:
//设定的跳表最大层数,新增节点的随机层数不能大于此值
enum { kMaxHeight = 12 };
// Immutable after construction
//key的比较器
Comparator const compare_;
//内存池
Arena* const arena_; // Arena used for allocations of nodes
//跳表的头结点
Node* const head_;
// Modified only by Insert(). Read racily by readers, but stale
// values are ok.
// 跳表的最大层数,不包括head节点,head节点的key为0,小于任何key,层数为kmaxheight=12
// AtomicPointer是leveldb定义的一个原子指针,它的读取和写入都设立了内存屏障,保证读取的值是即时的、最新的
// 这里直接将int型转化为指针保存,因为不会对其取地址,所以可行,值得借鉴
port::AtomicPointer max_height_; // Height of the entire list成员函数有:
// Insert key into the list.
void Insert(const Key& key);
// Returns true iff an entry that compares equal to key is in the list.
bool Contains(const Key& key) const;
Node* NewNode(const Key& key, int height);
int RandomHeight();
bool Equal(const Key& a, const Key& b) const { return (compare_(a, b) == 0); }
// Return true if key is greater than the data stored in "n"
bool KeyIsAfterNode(const Key& key, Node* n) const;
// Return the earliest node that comes at or after key.
// Return NULL if there is no such node.
//
// If prev is non-NULL, fills prev[level] with pointer to previous
// node at "level" for every level in [0..max_height_-1].
Node* FindGreaterOrEqual(const Key& key, Node** prev) const;
// Return the latest node with a key < key.
// Return head_ if there is no such node.
Node* FindLessThan(const Key& key) const;
// Return the last node in the list.
// Return head_ if list is empty.
Node* FindLast() const;相信你们可以看懂这些函数功能的注释。
节点和迭代器:
skiplist的节点Node和迭代器Iterator都是以嵌套类定义在类skiplist中的
class Iterator {
public:
// Initialize an iterator over the specified list.
// The returned iterator is not valid.
explicit Iterator(const SkipList* list);
// Returns true iff the iterator is positioned at a valid node.
bool Valid() const;
// Returns the key at the current position.
// REQUIRES: Valid()
const Key& key() const;
// Advances to the next position.
// REQUIRES: Valid()
void Next();
// Advances to the previous position.
// REQUIRES: Valid()
void Prev();
// Advance to the first entry with a key >= target
void Seek(const Key& target);
// Position at the first entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToFirst();
// Position at the last entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToLast();
private:
const SkipList* list_;
Node* node_;
// Intentionally copyable
};迭代器只有一个list指针(保存所指skiplist的指针)和node指针(所指的节点)。迭代器主要操作有前进,后退,定位头结点,尾节点,封装了list和node的操作。比如:
template<typename Key, class Comparator>
inline void SkipList<Key,Comparator>::Iterator::Next() {
assert(Valid());
node_ = node_->Next(0);
}
template<typename Key, class Comparator>
inline void SkipList<Key,Comparator>::Iterator::Prev() {
// Instead of using explicit "prev" links, we just search for the
// last node that falls before key.
assert(Valid());
node_ = list_->FindLessThan(node_->key);
if (node_ == list_->head_) {
node_ = NULL;
}
}注意next操作时沿节点最低层的指针前进的,实际上prev也是,这样保证可以遍历skiplist每个节点。实际上跳表的多层指针结构为了提高查询的效率。
下面来看看节点node的定义:
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
explicit Node(const Key& k) : key(k) { }
//所携带的数据,memtable中为我们指明了实例化版本是char* key
Key const key;
// Accessors/mutators for links. Wrapped in methods so we can
// add the appropriate barriers as necessary.
//返回本节点第n层的下一个节点指针
Node* Next(int n) {
assert(n >= 0);
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
//重设n层的next指针
void SetNext(int n, Node* x) {
assert(n >= 0);
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].Release_Store(x);
}
// No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].NoBarrier_Store(x);
}
private:
// Array of length equal to the node height. next_[0] is lowest level link.
// 本节点的n层后向的指针
port::AtomicPointer next_[1];
};在memtable的实现中,我们看到skiplist的实例化版本是SkipList
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::NewNode(const Key& key, int height) {
char* mem = arena_->AllocateAligned(
sizeof(Node) + sizeof(port::AtomicPointer) * (height - 1));
return new (mem) Node(key);
}很多人可能之前就奇怪为什么每个节点的n层后向指针却是next_[1],只有一个成员?因为节点的高度需要由一个随机算子产生,也就是说height对于每个节点是无法提前预知的,自然也就不能在node定义中确定next数组的大小,那么如何保证next数组足够用呢?newnode为我们展现了这样的一种奇技淫巧,实际上新节点在确定height后,向内存申请空间时,申请了一块sizeof(Node) + sizeof(port::AtomicPointer) * (height - 1)大小的空间,确保next指针的空间足够,并用placement new为新node指定空间。
结构已经铺垫好,接下来我们就看看skiplist成员函数的实现吧。
//寻找关键字大于等于key值的最近节点,指针数组prev保存此节点每一层上访问的前一个节点。
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node* SkipList<Key,Comparator>::FindGreaterOrEqual(const Key& key, Node** prev)
const {
Node* x = head_;
//首先获得跳表的最高层数,减一是数组next最大下标
int level = GetMaxHeight() - 1;
//查找操作开始
while (true) {
//跳表可以看成多层的链表,层数越高,链表的节点数越少,查找也就从高层数的链表开始
//如果key在本节点node之后,继续前进
//若果小于本节点node,把本节点的level层上的前节点指针记录进数组prev中,并跳向第一层的链表
//重复上述过程,直至来到最底层
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// Keep searching in this list
x = next;
} else {
if (prev != NULL) prev[level] = x;
if (level == 0) {
return next;
} else {
// Switch to next list
level--;
}
}
}
}跳表实际上是类似一种多层的有序链表,高层的链表比底层的链表节点更少,在更高层的链表上能更快的遍历完整个链表,跳到更底层的链表更利于精确的定位,以上便是skiplist利用空间换取时间的方法精髓。想首先从跳表头结点的最高层开始遍历,key值大于节点key值,则前往同一层的下一个节点,否则跳到节点的低一层并记录上一层的最后访问的节点,直到来到第一层(最底层)。以下其他操作的分析均源于此。贴一张跳表的示意图,帮助理解
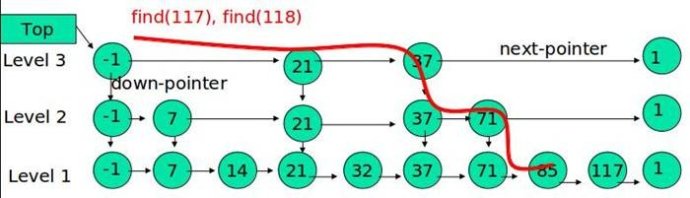
类似的函数还有FindLessThan,FindLast,大家自己理解理解。
其实FindGreaterOrEqual函数返回的前向节点指针数组是为了向跳表插入节点时用的,想想链表的插入操作,insert一个key时,首先新建一个node(key),把node->next指向prev-next,再把prev->next指向node。跳表也是,只不过需要操作多个链表。skiplist::insert函数如下:
template<typename Key, class Comparator>
void SkipList<Key,Comparator>::Insert(const Key& key) {
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev);
// Our data structure does not allow duplicate insertion
assert(x == NULL || !Equal(key, x->key));
int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}总结
好了,看了leveldb的skiplist和memtable,确实受益匪浅,不仅学习了skiplist的实现和memtable的封装,还认识了内存屏障以及如何在C++中插入汇编语句。但我觉得看leveldb最重要的还是学习人家的设计思路,说到底其实跳表的实现并不难,抛开性能上的差距,也许我也能实现,但如何真正做到面向对象,如何理解需求和设计出最简明的结构,如何让你的代码层次清楚,一目了然,这真的是一门大智慧。















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









