






用Tensorflow Lite的兄弟们都知道,谷歌推出的这个Tensorflow Lite更多的是为移动设备服务,提供了一个可实现在移动端设备上高速推理的一个产品,在移动端设备上的性能可远超在windows端上,而且部署方便简单,也几乎兼容所有的移动端平台
Tensorflow Lite之所以能有这种优秀的性能,得益于他的委托代理机制,可以把计算通过Delegate在GPU或者NPU上全部或者部分运行,而这种委托机制有点像插件,用户可以自己写一个Delegate,或者使用官方提供的Delegate,目前官方提供了4个Delegate,分别为:
GPU (支持OpenGL或OpenCL加速)
NPU (支持安卓原生的神经网络加速API和硬件端的自定义神经网络加速)
CoreML (针对iOS平台的优化,其本质也是使用GPU进行加速)
XnnPack (谷歌提供的一套高度优化的神经网络推理运算符库,可在全平台实现加速)
由于我不怎么用苹果系统,所以以前一直在用GPU和NPU在安卓端的加速,但最近在看谷歌的文档时发现了这个XnnPack,最让我有兴趣的是这个Delegate可以实现在windows端的加速,于是仔细翻阅了它的API接口,谷歌原文如下:
# XNNPACK backend for TensorFlow Lite
XNNPACK is a highly optimized library of neural network inference operators for
ARM, x86, and WebAssembly architectures in Android, iOS, Windows, Linux, macOS,
and Emscripten environments. This document describes how to use the XNNPACK
library as an inference engine for TensorFlow Lite.
## Using XNNPACK engine with TensorFlow Lite interpreter
XNNPACK integrates with TensorFlow Lite interpreter through the delegation
mechanism. TensorFlow Lite supports several methods to enable XNNPACK
for floating-point inference.
### Enable XNNPACK via Java API on Android (recommended on Android)
Pre-built [nightly TensorFlow Lite binaries for Android](https://www.tensorflow.org/lite/guide/android#use_the_tensorflow_lite_aar_from_mavencentral)
include XNNPACK, albeit it is disabled by default. Use the `setUseXNNPACK`
method in `Interpreter.Options` class to enable it:
```java
Interpreter.Options interpreterOptions = new Interpreter.Options();
interpreterOptions.setUseXNNPACK(true);
Interpreter interpreter = new Interpreter(model, interpreterOptions);
```
### Enable XNNPACK via Swift/Objective-C API on iOS (recommended on iOS)
Pre-built [nightly TensorFlow Lite CocoaPods](https://www.tensorflow.org/lite/guide/ios#specifying_versions)
include XNNPACK, but do not enable it by default. Swift developers can use
`InterpreterOptions` object to enable XNNPACK:
```swift
var options = InterpreterOptions()
options.isXNNPackEnabled = true
var interpreter = try Interpreter(modelPath: "model/path", options: options)
```
Objective-C developers can enable XNNPACK via a new property in the
`TFLInterpreterOptions` class:
```objc
TFLInterpreterOptions *options = [[TFLInterpreterOptions alloc] init];
options.useXNNPACK = YES;
NSError *error;
TFLInterpreter *interpreter =
[[TFLInterpreter alloc] initWithModelPath:@"model/path"
options:options
error:&error];
```
### Enable XNNPACK via Bazel build flags (recommended on desktop)
When building TensorFlow Lite with Bazel, add
`--define tflite_with_xnnpack=true`, and the TensorFlow Lite interpreter will
use XNNPACK engine by default.
The exact command depends on the target platform, e.g. for Android AAR you'd use
```
bazel build -c opt --fat_apk_cpu=x86,x86_64,arm64-v8a,armeabi-v7a \
--host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
--define android_dexmerger_tool=d8_dexmerger \
--define android_incremental_dexing_tool=d8_dexbuilder \
--define tflite_with_xnnpack=true \
//tensorflow/lite/java:tensorflow-lite
```
Note that in this case `Interpreter::SetNumThreads` invocation does not take
effect on number of threads used by XNNPACK engine. In order to specify number
of threads available for XNNPACK engine you should manually pass the value when
constructing the interpreter. The snippet below illustrates this assuming you
are using `InterpreterBuilder` to construct the interpreter:
```c++
// Load model
tflite::Model* model;
...
// Construct the interprepter
tflite::ops::builtin::BuiltinOpResolver resolver;
std::unique_ptr<tflite::Interpreter> interpreter;
TfLiteStatus res = tflite::InterpreterBuilder(model, resolver, num_threads);
```
**XNNPACK engine used by TensorFlow Lite interpreter uses a single thread for
inference by default.**
### Enable XNNPACK via additional dependency
Another way to enable XNNPACK is to build and link the
`//tensorflow/lite:tflite_with_xnnpack` target into your application alongside
the TensorFlow Lite framework.
This method works on platforms which support POSIX-style weak symbols (Android,
iOS, Linux, Mac, but **NOT** Windows).
### Enable XNNPACK via low-level delegate API (not recommended)
While it is possible to use low-level delegate API to enable XNNPACK, this
method is **NOT RECOMMENDED** unless you need to use TensorFlow Lite both with
and without XNNPACK (e.g. for benchmarking).
With low-level delegate API users create an XNNPACK delegate with the
`TfLiteXNNPackDelegateCreate` function, and then call
`Interpreter::ModifyGraphWithDelegate` to delegate supported parts of
the model to the XNNPACK delegate. The users must destroy the delegate with
`TfLiteXNNPackDelegateDelete` **after** releasing the TensorFlow Lite
interpreter. The snippet below illustrates the typical usage:
```c++
// Build the interpreter
std::unique_ptr<tflite::Interpreter> interpreter;
...
// IMPORTANT: initialize options with TfLiteXNNPackDelegateOptionsDefault() for
// API-compatibility with future extensions of the TfLiteXNNPackDelegateOptions
// structure.
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.num_threads = num_threads;
TfLiteDelegate* xnnpack_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter->ModifyGraphWithDelegate(xnnpack_delegate) != kTfLiteOk) {
// Report error and fall back to another delegate, or the default backend
}
// IMPORTANT: AllocateTensors can be called only AFTER ModifyGraphWithDelegate
...
// Run inference using XNNPACK
interpreter->Invoke()
...
// IMPORTANT: release the interpreter before destroying the delegate
interpreter.reset();
TfLiteXNNPackDelegateDelete(xnnpack_delegate);
```
### Using the XNNPACK weights cache
XNNPACK internally packs static weights for operations (like convolutions) in
order to make accessing weights more memory friendly. XNNPACK needs to allocate
memory internally to hold these packed weights. If you are starting multiple
TFLite interpreter instances based on the same model, there can be multiple
copies of the same packed weights in each instance. This can cause high memory
usage. The weights cache can be used to share packed weights between multiple
TFLite instances.
```c++
// Create 2 interpreters which share the same model.
std::unique_ptr<tflite::Interpreter> interpreter1;
std::unique_ptr<tflite::Interpreter> interpreter2;
// Create a weights cache that you can pass to XNNPACK delegate.
TfLiteXNNPackDelegateWeightsCache* weights_cache =
TfLiteXNNPackDelegateWeightsCacheCreate();
// Like using the low-level API above, initialize options, and pass this cache
// to XNNPACK delegate via the options.
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weights_cache = weights_cache;
// Modify graph with delegate, as above...
TfLiteDelegate* delegate1 = TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter1->ModifyGraphWithDelegate(delegate1) != kTfLiteOk) {
// Static weights will be packed and written into weights_cache.
}
TfLiteDelegate* delegate2 = TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter1->ModifyGraphWithDelegate(delegate2) != kTfLiteOk) {
// XNNPACK will reuse packed weights if they can be found in the weights
// cache.
}
// Finalize the weights cache.
// Hard finalization has the lowest memory overhead, but requires that all
// TFLite interpreter instances must be created up front before any finalization
// and inference.
TfLiteXNNPackDelegateWeightsCacheFinalizeHard(weights_cache);
// Alternatively, soft-finalizate the weights cache. This is useful if more
// delegates using the same model will to be created after finalization.
// TfLiteXNNPackDelegateWeightsCacheFinalizeSoft(weights_cache);
// Later, after all the interpreters and XNNPACK delegates using the cache are
// destroyed, release the weights cache.
TfLiteXNNPackDelegateWeightsCacheDelete(weights_cache);
```
The weights cache is a contents-based cache. Every time XNNPACK has to pack
weights, it first packs into a temporary buffer, then tries to look up if the
packed weights can be found in the weights cache, based on the contents of the
packed weights. If it can be found, we access the packed weights in the
cache for subsequent operations, and the temporary buffer is freed. Otherwise,
the packed weights is added to the cache.
The weights cache has to be finalized before any inference, it will be an error
otherwise. Hard finalization and soft finalization depends on whether new
XNNPACK delegate instances will be created after finalization. Hard finalization
does not allow new instances to be created, and has lower memory overhead. Soft
finalization allows new instances to be created, and has higher memory overhead
(up to the size of the largest packed weights, rounded up to page alignment).
### Using XNNPACK for variable operations
XNNPACK can handle resource variables and associated operations: `VAR_HANDLE`,
`READ_VARIABLE`, and `ASSIGN_VARIABLE`, but needs to be opted in by the user
using delegate options:
```c++
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.flags |= TFLITE_XNNPACK_DELEGATE_FLAG_VARIABLE_OPERATORS;
```
When XNNPACK handles resource variables,
[tflite::Subgraph::resources](https://github.com/tensorflow/tensorflow/blob/5b4239ba9cf127fd26cd9f03c04dfc4c94c078d4/tensorflow/lite/core/subgraph.h#L197)
cannot be used to access resources, because the resources are now internal to
XNNPACK, and the changes are not reflected in tflite::Subgraph::resources. There
is currently no way to access resources if XNNPACK handles resource variables.
## Profiling
When TfLite profiling is enabled, XNNPACK will time each operator and report the
results to TfLite which will print them as part of the overall execution profile.
## Limitations and supported operators
XNNPACK delegate is a work-in-progress, and currently supports a limited set of
operators. Unsupported operators will fall back to the default implementations,
so models using a combination of supported and unsupported operators can still
benefit from XNNPACK delegate.
### Floating-Point (IEEE FP32) Operators
Below is the list of currently supported floating-point operators:
#### `ABS`
* Inputs and outputs must be in 32-bit floating-point format.
#### `ADD`
* Inputs and outputs must be in 32-bit floating-point format.
* Only addition with two inputs is supported.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `AVERAGE_POOL_2D`
* Inputs and outputs must be in 32-bit floating-point format.
* 1x1 pooling with non-unit stride is not supported.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `CEIL`
* Inputs and outputs must be in 32-bit floating-point format.
#### `CONCATENATION`
* Inputs and outputs must be in 32-bit floating-point format.
* Only concatenation with two, three, or four inputs is supported.
#### `CONV_2D`
* Inputs and outputs must be in 32-bit floating-point format.
* Bias is mandatory.
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type).
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `DEPTH_TO_SPACE`
* Inputs and outputs must be in 32-bit floating-point format.
* Block size must be greater than 1.
#### `DEPTHWISE_CONV_2D`
* Inputs and outputs must be in 32-bit floating-point format.
* Bias is mandatory.
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type).
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `DIV`
* Inputs and outputs must be in 32-bit floating-point format.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `ELU`
* Inputs and outputs must be in 32-bit floating-point format.
#### `FULLY_CONNECTED`
* Inputs and outputs must be in 32-bit floating-point format.
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type).
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `FLOOR`
* Inputs and outputs must be in 32-bit floating-point format.
#### `HARD_SWISH`
* Inputs and outputs must be in 32-bit floating-point format.
#### `LEAKY_RELU`
* Inputs and outputs must be in 32-bit floating-point format.
#### `LOGISTIC`
* Inputs and outputs must be in 32-bit floating-point format.
#### `MAX_POOL_2D`
* Inputs and outputs must be in 32-bit floating-point format.
* 1x1 pooling with non-unit stride is not supported.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `MAXIMUM`
* Inputs and outputs must be in 32-bit floating-point format.
#### `MEAN`
* The first input and the output must be 4D tensors in 32-bit
floating-point format.
* The second input (the input with the axes specification) must be static
(use `kTfLiteMmapRo` allocation type).
* Only [1, 2], [2, 1], and [2] axes specification (i.e. reduction across either
both spatial dimensions or across the width dimension) is supported.
#### `MINIMUM`
* Inputs and outputs must be in 32-bit floating-point format.
#### `MUL`
* Inputs and outputs must be in 32-bit floating-point format.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `NEG`
* Inputs and outputs must be in 32-bit floating-point format.
#### `PAD`
* The first input and the output must be in 32-bit floating-point format.
* The second input (the input with the padding specification) must be static
(use `kTfLiteMmapRo` allocation type).
* The numbers of padding elements must be non-negative.
#### `PRELU`
* Inputs and outputs must be in 32-bit floating-point format.
* Slope must be static (use `kTfLiteMmapRo` allocation type).
* Slope must be either a 1D tensor, or have all its non-channel dimensions equal
1.
#### `RELU`
* Inputs and outputs must be in 32-bit floating-point format.
#### `RELU6`
* Inputs and outputs must be in 32-bit floating-point format.
#### `RELU_N1_TO_1`
* Inputs and outputs must be in 32-bit floating-point format.
#### `RESHAPE`
* The first input and the output must be in 32-bit floating-point format.
* The second input (the input with the new shape specification) must be either
static (use `kTfLiteMmapRo` allocation type), or absent (with the new shape
specified via `ReshapeOptions` table).
#### `RESIZE_BILINEAR`
* The first input and the output must be 4D tensors in 32-bit floating-point
format.
* The second input (the input with the new shape specification) must be
static (use `kTfLiteMmapRo` allocation type).
#### `ROUND`
* Inputs and outputs must be in 32-bit floating-point format.
#### `SLICE`
* The first input and the output must be in 32-bit floating-point format.
* The second and third inputs (the inputs with the slices' begin and size
specification) must be static (use `kTfLiteMmapRo` allocation type).
#### `SOFTMAX`
* Inputs and outputs must be in 32-bit floating-point format.
* Only `beta = 1.0` is supported.
#### `SPACE_TO_DEPTH`
* Inputs and outputs must be in 32-bit floating-point format.
* Block size must be greater than 1.
#### `SPLIT`
* Inputs and outputs must be in 32-bit floating-point format.
* Only split into two, three, or four outputs is supported.
#### `SQRT`
* Inputs and outputs must be in 32-bit floating-point format.
#### `SQUARE`
* Inputs and outputs must be in 32-bit floating-point format.
#### `SQUARED_DIFFERENCE`
* Inputs and outputs must be in 32-bit floating-point format.
#### `STRIDED_SLICE`
* The first input and the output must be in 32-bit floating-point format.
* The second, third, and fourth inputs (the inputs with the slices' begin, end,
and stride specification) must be static (use `kTfLiteMmapRo` allocation
type).
* The fourth input (strides) must be all ones.
* The ellipsis mask, new axis mask, and shrink axis mask must be 0.
#### `SUB`
* Inputs and outputs must be in 32-bit floating-point format.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `TANH`
* Inputs and outputs must be in 32-bit floating-point format.
#### `TRANSPOSE`
* The first input and the output must be in 32-bit floating-point format.
* The second input (the input with the permutation specification) must be
static (use `kTfLiteMmapRo` allocation type).
#### `TRANSPOSE_CONV`
* Input, filter, bias (if present) and output tensors must be in 32-bit
floating-point format.
* Output size, filter and bias (if present) must be static (use
`kTfLiteMmapRo` allocation type).
### Floating-Point (IEEE FP16) Operators
XNNPACK supports half-precision (using IEEE FP16 format) inference for all
floating-point operators. XNNPACK automatically enables half-precision
inference when the following conditions are met:
* XNNPACK runs on hardware that natively supports computations in IEEE FP16
format. Currently, this hardware is limited to ARM & ARM64 devices with
ARMv8.2 FP16 arithmetics extension, and includes Android phones starting with
Pixel 3, Galaxy S9 (Snapdragon SoC), Galaxy S10 (Exynos SoC), iOS devices with
A11 or newer SoCs, all Apple Silicon Macs, and Windows ARM64 laptops based with
Snapdragon 850 SoC or newer.
* The model's "reduced_precision_support" metadata indicates that the model
is compatible with FP16 inference. The metadata can be added during model
conversion using the `_experimental_supported_accumulation_type` attribute
of the [tf.lite.TargetSpec](https://www.tensorflow.org/api_docs/python/tf/lite/TargetSpec)
object:
```python
converter.optimizations = [tf.lite.Optimize.DEFAULT]
...
converter.target_spec.supported_types = [tf.float16]
converter.target_spec._experimental_supported_accumulation_type = tf.dtypes.float16
```
When the above conditions are met, XNNPACK replace FP32 operators with their
FP16 equivalents, and insert additional operators to convert model inputs
from FP32 to FP16 and convert model outputs back from FP16 to FP32. If the
above conditions are not met, XNNPACK will perform model inference with FP32
calculations.
Additionally, XNNPACK delegate provides an option to force FP16 inference
regardless of model metadata. This option is intended for development workflows,
and in particular for testing end-to-end accuracy of model when FP16 inference
is used. Forcing FP16 inference has several effects:
* Besides ARM64 devices with ARMv8.2 FP16 arithmetics extension, forced FP16
inference is supported on x86/x86-64 devices with AVX2 extension in emulation
mode: all elementary floating-point operations are computed in FP32, then
converted to FP16 and back to FP32. Note that such simulation is not bit-exact
equivalent to native FP16 inference, but simulates the effects of restricted
mantissa precision and exponent range in the native FP16 arithmetics.
* On devices that support neither the native FP16 arithmetics (ARM64 devices
with ARMv8.2 FP16 arithmetics extension), nor emulation (x86/x86-64 devices with
AVX2 extension), inference will fail rather than fall back to FP32.
* If any floating-point operator offloaded to XNNPACK is not supported for FP16
inference, inference will fail rather than fall back to FP32.
To force FP16 inference, either build the delegate with
`--define xnnpack_force_float_precision=fp16` option, or add
`TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16` flag to the
`TfLiteXNNPackDelegateOptions.flags` bitmask passed into
the `TfLiteXNNPackDelegateCreate` call:
```c
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
...
xnnpack_options.flags |= TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16;
TfLiteDelegate* xnnpack_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
```
XNNPACK has full feature parity between FP32 and FP16 operators: all operators
that are supported for FP32 inference are also supported for FP16 inference,
and vice versa. In particular, sparse inference operators are supported for FP16
inference on ARM processors.
### Quantized Operators
By default, quantized inference in XNNPACK delegate is disabled, and XNNPACK is
used only for floating-point models. Support for quantized inference in XNNPACK
must be enabled by adding extra Bazel flags when building TensorFlow Lite.
* `--define tflite_with_xnnpack_qs8=true` flag enables XNNPACK inference for
quantized operators using signed quantization schema. This schema is used by
models produced by [Model Optimization
Toolkit](https://www.tensorflow.org/model_optimization) through either
post-training integer quantization or quantization-aware training.
Post-training dynamic range quantization is not supported in XNNPACK.
* `--define tflite_with_xnnpack_qu8=true` flag enables XNNPACK inference for
quantized operators using unsigned quantization schema, produced via the
legacy TensorFlow 1.X quantization tooling. This option is experimental and
may perform suboptimally on mobile processors with NEON DOT product
instructions.
Below is the list of currently supported quantized operators:
#### `ADD`
* Inputs and outputs must be in 8-bit quantized format.
* Only addition with two inputs is supported.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `CONCATENATION`
* Inputs and outputs must be in 8-bit quantized format.
* Only concatenation with two, three, or four inputs is supported.
#### `CONV_2D`
* Inputs and outputs must be in 8-bit quantized format (bias must be in 32-bit
quantized format).
* Bias is mandatory.
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type),
and can use either per-tensor or per-channel quantization parameters.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `DEPTH_TO_SPACE`
* Inputs and outputs must be in 8-bit quantized format.
* Block size must be greater than 1.
#### `DEPTHWISE_CONV_2D`
* Inputs and outputs must be in 8-bit quantized format (bias must be in
32-bit quantized format).
* Bias is mandatory.
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type),
and can use either per-tensor or per-channel quantization parameters.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `DEQUANTIZE`
* Input tensor must be in 8-bit quantized format without per-channel
quantization.
* Output tensor must be in 32-bit floating-point format.
#### `ELU`
* Inputs and outputs must be in 8-bit signed quantized format.
#### `FULLY_CONNECTED`
* Inputs and outputs must be in 8-bit quantized format (bias, if present, must
be in 32-bit quantized format).
* Both filter and bias must be static (use `kTfLiteMmapRo` allocation type).
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `LEAKY_RELU`
* Inputs and outputs must be in 8-bit quantized format.
* The ratio of input scale to output scale must be within [1/256, 128].
* The product of negative slope by the ratio of input scale to output scale
must be within either [-127.99609375, -1/256] range or [1/256, 128] range.
#### `LOGISTIC`
* Inputs and outputs must be in 8-bit quantized format.
#### `MAX_POOL_2D`
* Inputs and outputs must be in 8-bit quantized format.
* 1x1 pooling with non-unit stride is not supported.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `MEAN`
* The first input and the output must be 4D tensors in 8-bit quantized format.
* The second input (the input with the axes specification) must be static
(use `kTfLiteMmapRo` allocation type).
* Only [1, 2], [2, 1], and [2] axes specification (i.e. reduction across either
both spatial dimensions or across the width dimension) is supported.
#### `MUL`
* Inputs and outputs must be in 8-bit quantized format.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `PAD`
* The first input and the output must be in 8-bit quantized format.
* The second input (the input with the padding specification) must be static
(use `kTfLiteMmapRo` allocation type).
* The numbers of padding elements must be non-negative.
#### `QUANTIZE`
* Input tensor must be in 32-bit floating-point format or in 8-bit quantized
format.
* Output tensor must be in 8-bit quantized format without per-channel
quantization.
* If inputs are in 8-bit quantized format, they must have the same signedness
as the outputs, and the ratio of input scale to output scale must be in the
[2**-8, 2**7] range.
#### `RESHAPE`
* The first input and the output must be in 8-bit quantized format.
* The second input (the input with the new shape specification) must be either
static (use `kTfLiteMmapRo` allocation type), or absent (with the new shape
specified via `ReshapeOptions` table).
#### `RESIZE_BILINEAR`
* The first input and the output must be 4D tensors in 8-bit quantized format.
* The second input (the input with the new shape specification) must be
static (use `kTfLiteMmapRo` allocation type).
#### `SLICE`
* The first input and the output must be in 8-bit quantized format.
* The second and third inputs (the inputs with the slices' begin and size
specification) must be static (use `kTfLiteMmapRo` allocation type).
#### `SPACE_TO_DEPTH`
* Inputs and outputs must be in 8-bit quantized format.
* Block size must be greater than 1.
#### `SPLIT`
* Inputs and outputs must be in 8-bit quantized format.
* Only split into two, three, or four outputs is supported.
#### `SUB`
* Inputs and outputs must be in 8-bit quantized format.
* Fused `NONE`, `RELU`, `RELU_N1_TO_1`, and `RELU6` activations are supported,
but fused `TANH` and `SIGN_BIT` activations are not.
#### `TANH`
* Inputs and outputs must be in 8-bit quantized format.
#### `TRANSPOSE`
* The first input and the output must be in 8-bit quantized format.
* The second input (the input with the permutation specification) must be
static (use `kTfLiteMmapRo` allocation type).
#### `TRANSPOSE_CONV`
* Input, filter, and output tensors must be in 8-bit quantized format (bias, if
present, must be in 32-bit quantized format).
* Output size, filter and bias (if present) must be static (use
`kTfLiteMmapRo` allocation type).
### Sparse Inference
XNNPACK backend supports sparse inference for CNN models described in the
[Fast Sparse ConvNets](https://arxiv.org/abs/1911.09723) paper. Sparse
inference is restricted to subgraphs with the following floating-point
operators:
* Sparse subgraph must store its weights in sparse representation (using
`DENSIFY` operators in the TensorFlow Lite schema).
* Sparse subgraph must start with a 3x3 stride-2 `CONV_2D` operator with
padding 1 on each side, no dilation, and 3 input channels.
* Sparse subgraph must end with either a `MEAN` operator with reduction across
spatial axes, or a `DEPTH_TO_SPACE` operator.
* Sparse subgraph may contain the following operators:
* `CONV_2D` with 1x1 kernel and no padding. At least 2/3rd of filter weights
in the 1x1 `CONV_2D` operators across the sparse subgraph must be zeroes
to enable sparse inference.
* `DEPTHWISE_CONV_2D` with 3x3 kernel, stride 1, no dilation, and padding 1
on each side.
* `DEPTHWISE_CONV_2D` with 3x3 kernel, stride 2, no dilation, and padding 1
on each side.
* `DEPTHWISE_CONV_2D` with 5x5 kernel, stride 1, no dilation, and padding 2
on each side.
* `DEPTHWISE_CONV_2D` with 5x5 kernel, stride 2, no dilation, and padding 2
on each side.
* `RESIZE_BILINEAR` operator with output dimensions greater than 1.
* `MEAN` operator with reduction across spatial axes.
* `ADD` and `MUL` operators where both inputs are 4D tensors. If one of the
inputs to `ADD` or `MUL` is a constant tensor, it must be representable as
either a scalar, or a 1D vector.
* Unary elementwise operators `ABS`, `CEIL`, `ELU`, `FLOOR`, `HARD_SWISH`,
`LEAKY_RELU`, `LOGISTIC`, `NEG`, `RELU`, `RELU6`, `RELU_N1_TO_1`, `ROUND`,
`SIGMOID`, and `SQUARE`.
Pre-trained [Fast Sparse ConvNets models](https://github.com/google-research/google-research/tree/master/fastconvnets)
provide examples that satisfy these constraints.
### Transient Indirection Buffer
Some of XNNPACK operators, such as `CONV_2D`, use indirection buffers to supply
locations of input for the operators. Indirection buffers are created for each
operator instance, and are persistent by default. It causes XNNPACK to use
substantial amount of memory, especially when the input is in high resolution.
To reduce the memory footprint of indirection buffers, either build the delegate
with `--define tflite_with_xnnpack_transient_indirection_buffer=true` option, or
add `TFLITE_XNNPACK_DELEGATE_FLAG_TRANSIENT_INDIRECTION_BUFFER` flag to the
`TfLiteXNNPackDelegateOptions.flags` bitmask passed into the
`TfLiteXNNPackDelegateCreate` call:
```c
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
...
xnnpack_options.flags |= TFLITE_XNNPACK_DELEGATE_FLAG_TRANSIENT_INDIRECTION_BUFFER;
TfLiteDelegate* xnnpack_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
```
XNNPACK will now use the temporary memory in the workspace for indirection
buffers. However, instead of initializing the indirection buffers once during
the initialization of the operators, the indirection buffers will be initialized
during every inference run.
Below is the list of currently supported operators:
* `CONV_2D`
* `DEPTHWISE_CONV_2D`
* `RESIZE_BILINEAR`
### Other limitations
* Dynamically allocated (with `kTfLiteDynamic` allocation type) inputs and
outputs are not supported.
* Resizing model inputs (via `Interpreter::ResizeInputTensor`) is supported, but
cause a complete reinitialization of the delegate instance, which has
considerable overhead.
大致介绍了什么是XnnPack,支持哪些ops操作和它的使用方法,由于在windows端只能使用它的低级调用方式,虽然谷歌不推荐此方法,但我找不到其它的方法,于是修改我之前在Delphi下封装的TFLite库,引入XnnPack相关API
XnnPackDelegateCreate := GetProcAddress(LibraryModule, 'TfLiteXNNPackDelegateCreate');
XnnPackDelegateDelete := GetProcAddress(LibraryModule, 'TfLiteXNNPackDelegateDelete');
XnnPackGetDefaultOptions := GetProcAddress(LibraryModule, 'TfLiteXNNPackDelegateOptionsDefault');
if (@XnnPackDelegateCreate = nil) or (@XnnPackDelegateDelete = nil) or
(@XnnPackGetDefaultOptions = nil) then
begin
raise ETensorFlowLiteFMXError.Create('xnnPack init error !');
Exit;
end;并在LoadModel的时候直接切换到XnnPack委托
//使用xnnPack代理
dtXNNPack:
begin
FXNNPackDelegateOptions:=XnnPackGetDefaultOptions();
FXNNPackDelegateOptions^.num_threads:=InterpreterThreadCount;
FXNNPackDelegateOptions^.experimental_adaptive_avx_optimization:=true;
FXNNPackDelegateOptions^.flags:=TFLITE_XNNPACK_DELEGATE_FLAG_ENABLE_SUBGRAPH_RESHAPING;
XNNPackDelegate:=XNNPackDelegateCreate(FXNNPackDelegateOptions);
if (XNNPackDelegate <> nil) then
begin
// XnnPackInterpreterModifyGraphWithDelegate(XNNPackDelegate);
InterpreterOptionsAddDelegate(InterpreterOptions, XNNPackDelegate);
end;
end;XnnPack的Delegate有一个Options的配置:
const
// 为有符号量化的8位推断启用XNNPACK加速。
// 这包括具有通道量化权重的运算符。
TFLITE_XNNPACK_DELEGATE_FLAG_QS8 = $00000001;
// 为无符号量化的8位推断启用XNNPACK加速。
TFLITE_XNNPACK_DELEGATE_FLAG_QU8 = $00000002;
// 强制FP32运算符进行FP16推断。
TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16 = $00000004;
// 为具有动态权重的FULLY_CONNECTED运算符启用XNNPACK加速。
TFLITE_XNNPACK_DELEGATE_FLAG_DYNAMIC_FULLY_CONNECTED = $00000008;
// 为VAR_HANDLE、READ_VARIABLE和ASSIGN_VARIABLE运算符启用XNNPACK加速。
TFLITE_XNNPACK_DELEGATE_FLAG_VARIABLE_OPERATORS = $00000010;
// 启用瞬态间接缓冲区以减少选定运算符中的内存使用。
// 间接缓冲区初始化将在每次推断运行时进行,而不仅仅在运算符的初始化期间进行一次。
TFLITE_XNNPACK_DELEGATE_FLAG_TRANSIENT_INDIRECTION_BUFFER = $00000020;
// 在委托中启用最新的XNNPACK运算符和功能,这些功能尚未默认启用。
TFLITE_XNNPACK_DELEGATE_FLAG_ENABLE_LATEST_OPERATORS = $00000040;
// 启用XNNPack子图重塑。这意味着支持具有动态张量的模型,输入可以被高效地调整大小。
TFLITE_XNNPACK_DELEGATE_FLAG_ENABLE_SUBGRAPH_RESHAPING = $00000080;
type
TfLiteXNNPackDelegateWeightsCache = record
end;
PTfLiteXNNPackDelegateWeightsCache = ^TfLiteXNNPackDelegateWeightsCache;
TfLiteXNNPackDelegateOptions = record
num_threads: Integer;
flags: UInt32;
// 已弃用。请使用带有TFLITE_XNNPACK_DELEGATE_FLAG_VARIABLE_OPERATORS掩码的标志位字段。
handle_variable_ops: Boolean;
// 用于打包权重的缓存,可以在多个委托实例之间共享。
weights_cache: PTfLiteXNNPackDelegateWeightsCache;
// 为AVX CPU启用自适应优化。
experimental_adaptive_avx_optimization: Boolean;
end;
PTfLiteXNNPackDelegateOptions = ^TfLiteXNNPackDelegateOptions;其中的 num_threads 比较关键,是指定启动多少个线程来运行,这个需要看pc端的cpu配置,如果线程数量小,推理速度会下降,如果数量高,超过cpu内核处理极限,推理速度一下子会降低到比用纯CPU推理还慢,所以这里必须按实际CPU的性能来设置合适的线程数量
下面是我实际跑下来的对比
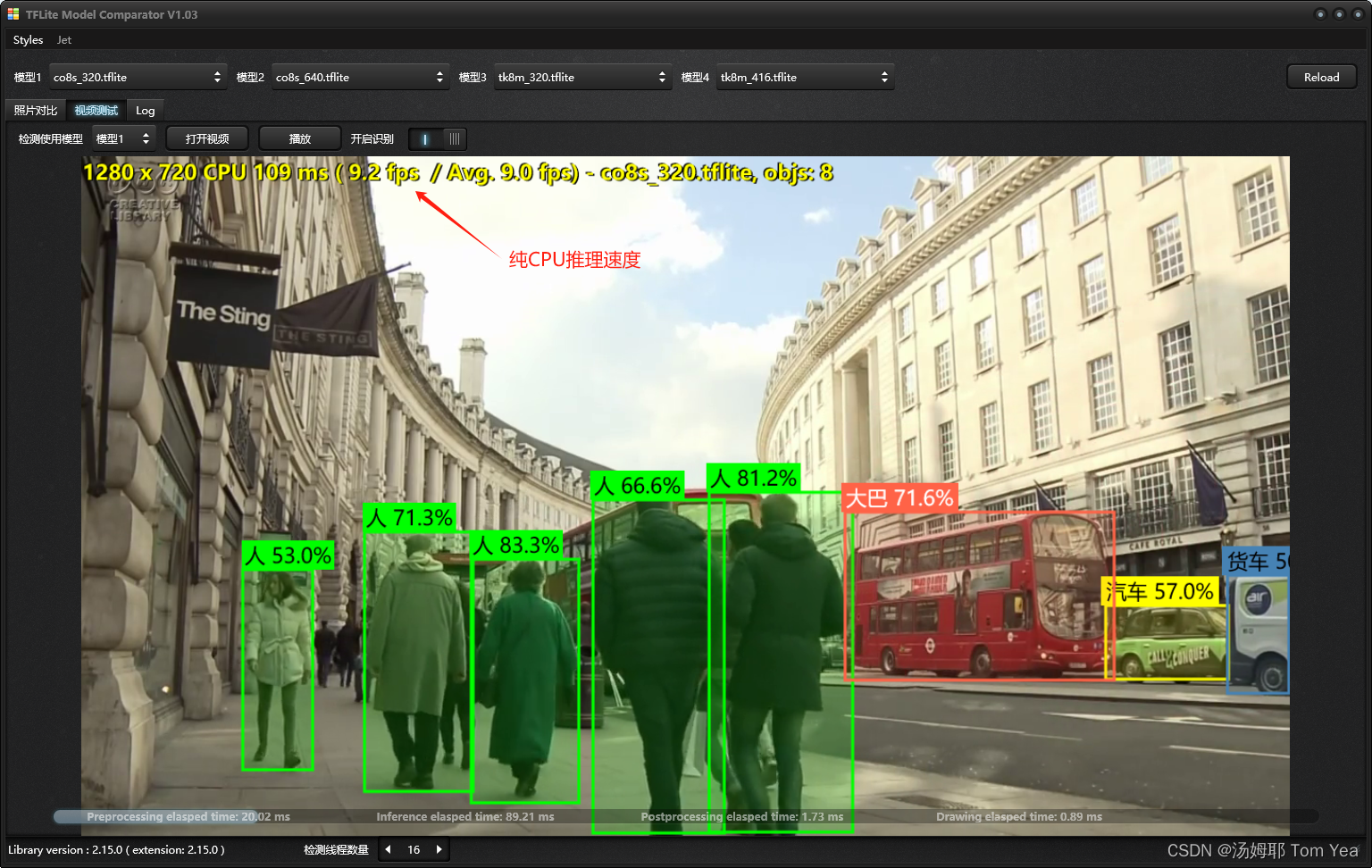
使用CPU运行推理的速度,大约9.2帧
使用XnnPack委托运行的速度,可以超过30帧
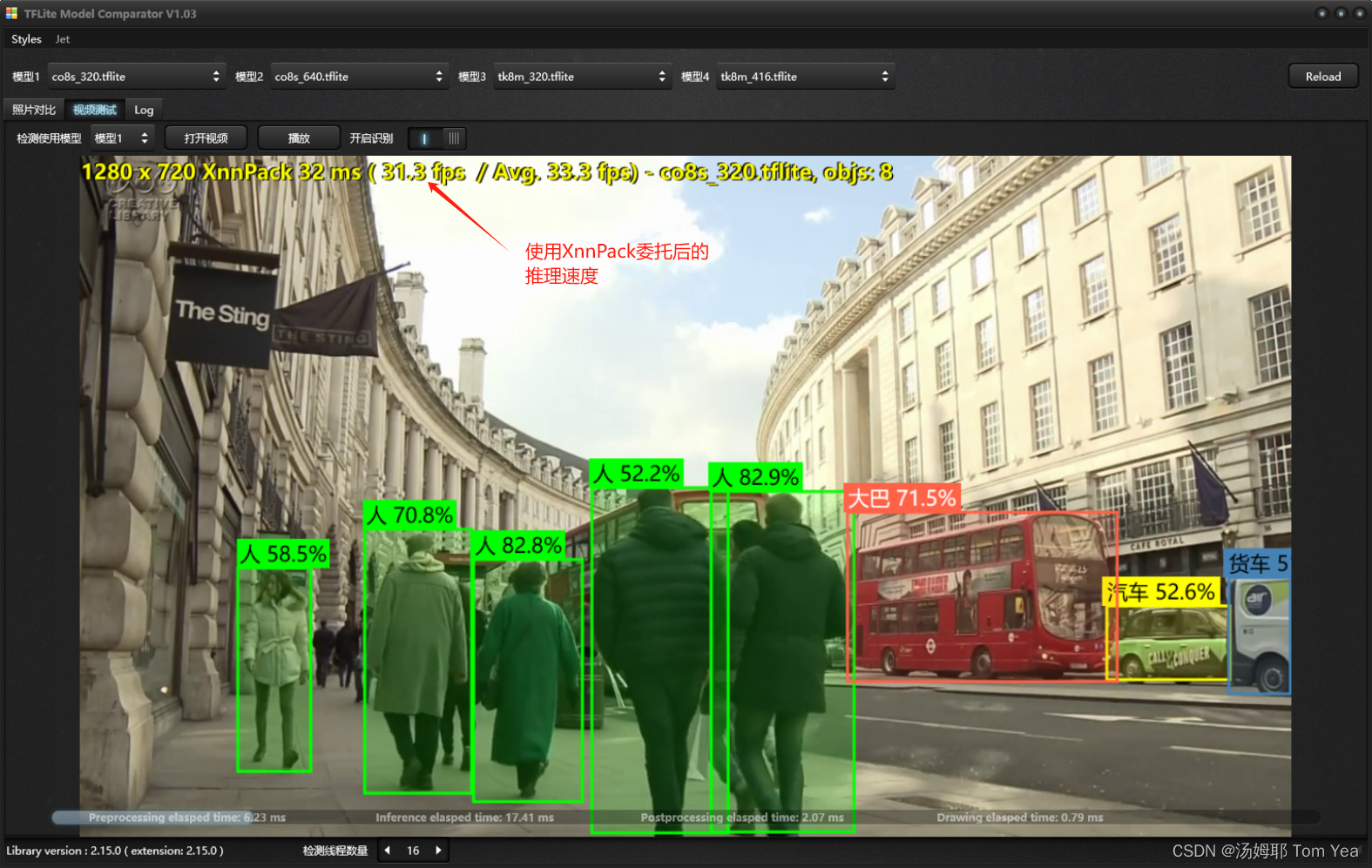
在运行的时候我观察了一下CPU和GPU的负载情况,CPU运行时 CPU几乎满负荷,但使用XnnPack时,CPU到80%左右,而GPU会到20%左右,明显XnnPack使用了GPU的资源,但它却又不像其它推理框架,必须部署cuda,虽然性能还比不上cuda的性能,但架不住它部署太简单了,windows端只要一个DLL文件就可以了
总结下来,谷歌的这套XnnPack委托代理非常适合一些AI小项目的开发,简单实用,性能也不算太弱,推荐各位Delphi的兄弟们使用















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









