






总:线性回归解决连续值预测;逻辑回归解决分类问题,工业界经常用来解决排序问题,因为它输出的是属于某一类的概率。
几个重要的概念:损失函数、梯度下降、过拟合和正则化
1.线性回归概念:
属于监督学习---------》学习样本为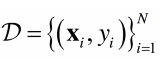
输出/预测的结果yi 为连续值变量
要学习映射关系:![]()
假定输入x和输出y之间有线性相关关系
测试/预测阶段:对于给定的x,预测其输出![]()
函数f为输入x的线性函数:f(x)=![]() ,一般写成向量形式,f(x)=
,一般写成向量形式,f(x)=![]()
2.损失函数(loss function)概念:
损失函数的作用,是权衡在特定参数下得到结果的准确性。其实,就是我们预测的结果和真实结果之间的差距。我们想要得到的目的就是让损失函数最小化,让误差达到最小。
损失函数的一般形式:
线性回归中常用的损失函数:

逻辑回归的中常用的损失函数:
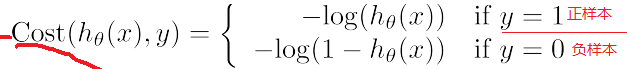
怎样让损失函数最小化:
a.梯度下降法(凸函数):自动找准方向(梯度),每次都找下降最快方向,即最陡的方向,每次迈出一步,直至逼近最小值。


注:学习率可以理解为,每次迈的步子的大小,太大有可能成功越过最低点,太小收敛较慢,效率降低,一般设为0.01;
当![]() 取上图左边的
取上图左边的![]() 值时,斜率为负(导数为负),按照上述公式,
值时,斜率为负(导数为负),按照上述公式,![]() 将会变大,所以会越来越接近损失函数的最小值,也就是图像的最低点;
将会变大,所以会越来越接近损失函数的最小值,也就是图像的最低点;
当![]() 取上图右边边的
取上图右边边的![]() 值时,斜率为正(导数为正),按照上述公式,
值时,斜率为正(导数为正),按照上述公式,![]() 将会变小,所以会越来越接近损失函数的最小值;
将会变小,所以会越来越接近损失函数的最小值;
以上是介绍的一个参数的情况,只有一个![]() ,当有多个参数时,应该怎么办呢?
,当有多个参数时,应该怎么办呢?
那就求偏导呗,也就是梯度;每次求一个点的偏导,按照这个方向,迈出一小步,直到逼近最小值。
3.欠/过拟合:
欠拟合:拟合度不好,误差较大;(参数太少,不足以表示样本特征。)
过拟合:函数曲线对原始数据拟合太好了( ![]() ),但丧失了一般性,导致对新的待预测样本的预测效果差;(参数过多,函数曲线过每个样本点,波动性太大,导致丧失泛化能力。)
),但丧失了一般性,导致对新的待预测样本的预测效果差;(参数过多,函数曲线过每个样本点,波动性太大,导致丧失泛化能力。)
解决过拟合方法:正则化 (L1正则化、L2正则化)在原来损失函数的基础上,加上正则项。
, 
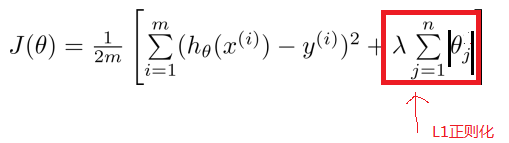
4.逻辑回归:解决分类问题
首先理解一下边界函数,如下面,两个图所示


线性判定边界:

sigmoid函数:阈值函数,将变量映射到0,1之间。用于解决分类问题,特殊点(0,0.5),当x>0时,y>0.5(概率大于0.5)

非线性判定边界:

损失函数:

举例:当取正样本时,,即y=1的情况,当你计算出的概率![]() =0.01,即计算出为负样本时,这时候,计算出的cost损失函数会很大,当
=0.01,即计算出为负样本时,这时候,计算出的cost损失函数会很大,当![]() =0.99,即计算出为正样本时,损失函数接近于0
=0.99,即计算出为正样本时,损失函数接近于0
整合后:

最小化损失函数:利用梯度下降法
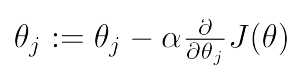
5.工业应用:

样本量太大怎么办?
a.离散后用one-hot编码处理成0,1; b.如果要用连续值,可以采用scaling(幅度变化); c.spark MLlib ;d.采样(日期\用户\行为,随机取误差太大,可能会破坏原本的分布)
注意样本的平衡:
a.LR对样本分布敏感; b.下采样(样本量足),上采样(样本数量不足:做镜像、旋转等);c、修改loss function,给不同的权重(若负样本数量少,可以把负样本权重加大)
关于算法调优:
a.选择合适的正则化(L1,L2,L1+L2);b.正则化系数C(太大导致原始的模型权重太少,太小导致模型还是过拟合);c.收敛的阈值e,迭代论述;d.调整loss function给定不同权重;e,Bagging或其他方式的模型融合;
f,最优化算法选择(‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’)。小样本用liblinear,大样本用sag,多分类用‘newton-cg’和‘lbfgs’
注:liblinear其实是一个库,高维度离散化特征,是以线性方式来逼近非线性,而且准确率逼近非线性切分。















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









