







用vllm本地部署qwen3满血版
作者建议
我将文档发布到了多个平台,不同的平台阅读体验不同,排版也可能有区别,本人强烈建议直接点击下面的链接查看原始文档,因为下面的链接是原始文档,阅读体验极佳,排版美观,有目录结构,您可以很容易找到您想要阅读的章节。另外,文档一直持续更新,不断完善,内容更加准确且与时俱进。原始文档始终是最新版本的,其它平台中的文档可能已经过时了。
单击查看原始文档:《用vllm本地部署qwen3满血版》
原创不易,如果对您有帮助,还请您一键三连[抱拳]
有任何问题都可以联系作者,文末有作者联系方式,欢迎交流。
以下是正文
qwen3介绍
今天(2025年4月29日)凌晨,阿里发布了最新的开源大模型qwen3系列,详细信息可以查看官方的公告https://mp.weixin.qq.com/s/NrS8SR9_FMq5GW-SJQPn8w
qwen3系列最大的特点是它是混合推理模型,Qwen3 引入了**“思考模式”和“非思考模式”**,使模型能够在不同场景下表现出最佳性能。在思考模式模式下,模型会进行多步推理和深度分析,类似于人类在解决复杂问题时的“深思熟虑”。(eg:在回答数学题或编写复杂代码时,模型会反复验证逻辑并优化输出结果。)
在非思考模式模式下,模型优先追求响应速度和效率,适用于简单任务或实时交互。(eg:在日常对话或快速问答中,模型会跳过复杂的推理步骤,直接给出答案。)
部署
我是在一台高性能服务器上部署的,有8张H20显卡,内存有2TB,4个固态硬盘,每个固态硬盘可用容量为3.5TB
qwen3发布后,我立马就用vllm部署了,而且是部署参数量最大的模型,有2350亿参数。
命令如下:
vllm serve "Qwen/Qwen3-235B-A22B"
下载了半天才下载好,太大了。
GPU使用情况
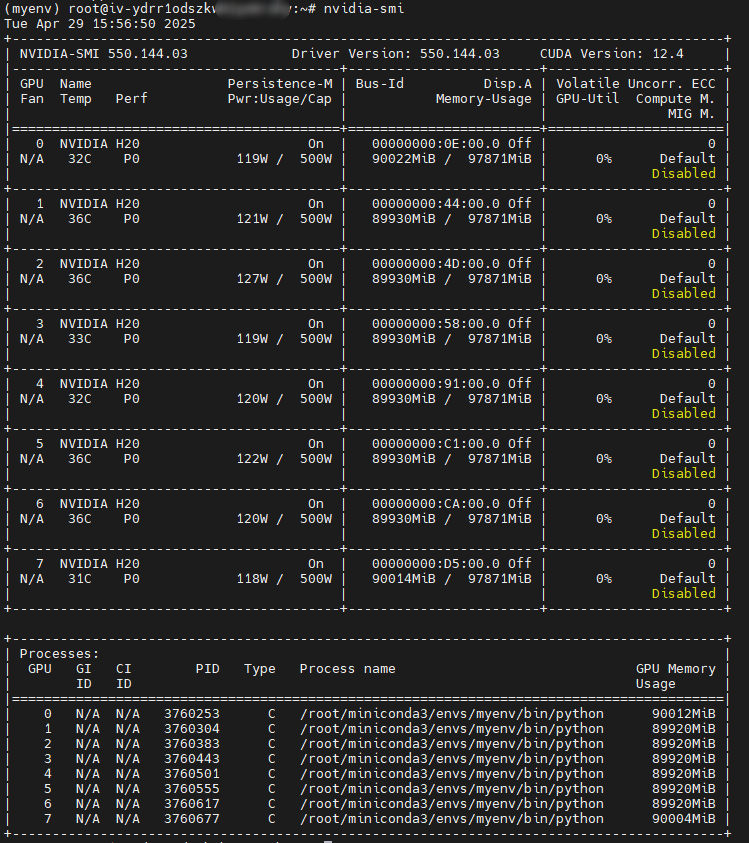
可以看到8张H20显存基本都吃光了
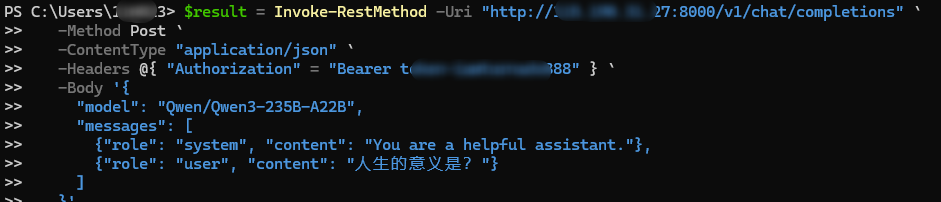
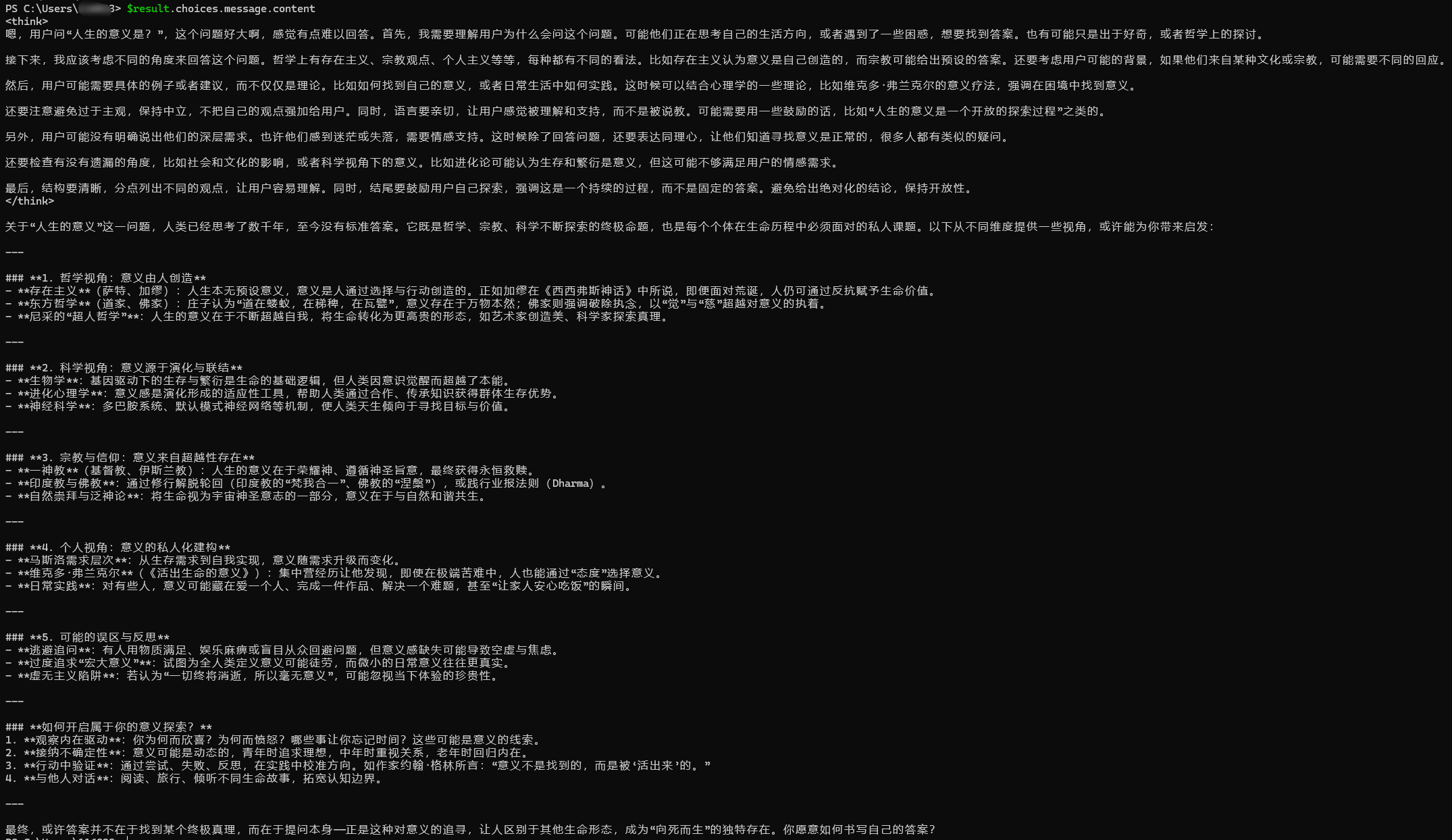
验证
用curl命令调用api与qwen3对话

响应速度挺不错的,每秒49.5个tokens

也可以用Powershell与大模型对话
关注我们,获取更多IT开发运维实用工具与技巧!
github用户名: iamtornado
github个人首页: https://github.com/iamtornado
电子邮箱: 1426693102@qq.com
个人微信:tornadoami(也可以通过下面的二维码加我,之后我将您邀请进入AI技术交流群)

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









