







1.15.Flink state(状态)管理与恢复
1.15.1.什么是state
1.15.2.状态(State)
1.15.3.Keyed State
1.15.4.Operator State
1.15.4.1.Snapshotting Operator State
1.15.5.状态容错
1.15.6.状态容错-生成快照
1.15.7.状态容错–恢复快照
1.15.8.checkPoint简介
1.15.8.1.Barriers
1.15.8.2.Recovery
1.15.9.CheckPoint的配置
1.15.10.状态的持久性
1.15.11.State Backend(状态的后端存储)
1.15.11.1.修改State Backend的两种方式
1.15.12.Restart Strategies(重启策略)
1.15.12.1.重启策略值固定间隔(Fixed delay)
1.15.12.2.重启策略之失败率(Failure rate)
1.15.12.3.重启策略之无重启 (No restart)
1.15.12.4.保存多个Checkpoint
1.15.12.5.从Checkpoint进行恢复
1.15.12.6.savePoint
1.15.12.7.checkPoint vs savePoint
1.15.12.8.savePoint的使用
1.15.Flink state(状态)管理与恢复
1.15.1.什么是state
虽然数据流中的许多操作一次只查看单个事件(例如an event parser),但有些操作记住跨多个事件的信息(例如window operators)。这些操作称为有状态操作。
一些有状态操作的例子:
当应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
当按分钟/小时/天聚合事件时,状态将保存挂起的聚合。
当通过stream of data points训练机器学习的模型时,state保留着当前版本的模型参数。
当历史数据需要被管理的时候,该状态允许对过去发生的事件进行有效访问。
使用checkpoint和savepoints保证容错的时候需要知道state。
state的状态,还有助于对Flink应用程序进行调整,这意味着Flink可以在并行实例间重新分布状态。
queryable state允许您在运行时从Flink外部访问状态。
在使用状态时,读取有关Flink的state backends也可能很有用。Flink提供了不同的state backend,用于指定状态存储的方式和位置。
1.15.2.状态(State)
我们前面写的word count的例子,没有包含状态管理。如果一个task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义上(at least once,exactly once),Flink引入了state和checkpoint。
首先区分一下两个概念
- state一般指一个具体的task/operator的状态【state数据默认保存在java的堆内存中】
- 而checkpoint【可以理解为checkpoint是把state数据持久化存储了】,则表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态。
- 注意:task是Flink中执行的基本单位。Operator指算子(transformation)
State可以被记录,在失败的情况下数据还可以恢复
Flink中有两种基本类型的State - Keyed State
- Operator State
Keyed State和Operator State,可以以两种形式存在: - 原始状态(raw state)
- 托管状态(managed state)
托管状态是由Flink框架管理的状态
而原始状态,由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。
1.15.3.Keyed State
顾名思义,就是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state。
stream.keyBy(…)
保存state的数据结构
- ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过value()方法获取状态值。
- ListState:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable来遍历状态值。
- ReducingState:这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值。
- MapState<UK,UV>:即状态值为一个map。用户通过put或putAll方法添加元素。
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄。
Keyed state在嵌入式的key/value存储中进行维护。该状态是与有状态操作符(stateful operators)读取的流一起严格分区和分发的。因此只有在keyed Stream流中访问key/value的state,对齐流和状态的键可以确保所有的状态更新都是本地操作,从而保证没有事务开销的一致性。这种对齐还允许Flink透明地重新分配状态和调整流分区。

Keyed State被进一步组织成所谓的Key Groups。Key Groups是Flink能够重新分配keyed State的原子单元(atomic unit),key Group的数量和定义的最大的并行度的数量是一致的。在执行每个并行的keyed operator的实例,在执行期间,key operator 的每个并行实例与一个或多个key Group的键一起执行。
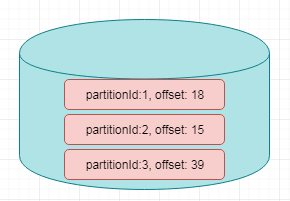
1.15.4.Operator State
与Key无关的State,与Operator绑定的state,整个operator只对应一个state
保存state的数据结构
ListState
举例来说,Flink中的Kafka Connector,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射。
1.15.4.1.Snapshotting Operator State
当operators包含任何形式的状态,该状态也必须是快照的一部分。
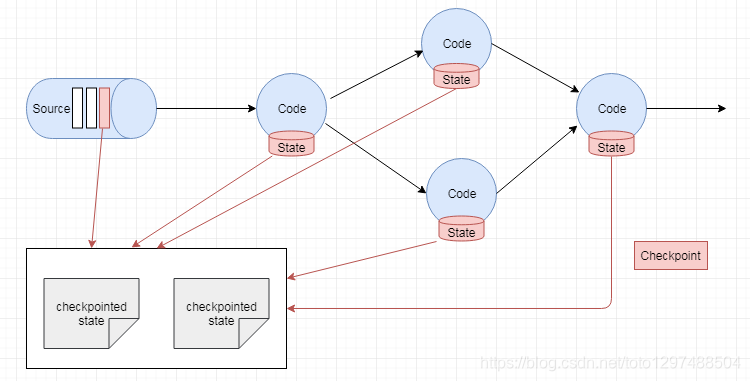
operators在从输入流接收到所有快照barriers的时间点,以及向输出流发出barriers 之前,对其状态进行快照。届时,将在进行barriers 之前从记录对状态进行所有更新,并且没有依赖于应用barriers之后的记录来进行状态更新。由于快照的状态可能很大,因此将其存储在可配置状态backend中。默认情况下,这是JobManager的内存,但对于生产用途,应配置分布式可靠存储(例如HDFS)。存储状态后,operator 确认检查点,将快照operator 发送到输出流中,然后继续。
现在生成的快照包含:
对于每个并行流数据源,启动快照时流中的偏移量/位置
对于每个运算符,一个指向作为快照一部分存储的状态的指针
为了保证state的容错性,Flink需要对state进行checkpoint。
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
Flink的checkpoint机制可以与(stream和state)的持久化存储交互的前提:
- 持久化的source,它需要支持在一定时间内重放事件。这种sources的典型例子是持久化的消息队列(比如Apache Kafka,RabbitMQ等)或文件系统(比如HDFS,S3,GFS等)
- 用于state的持久化存储,例如分布式文件系统(比如HDFS,S3,GFS等)
1.15.5.状态容错
依靠checkPoint机制
保证exectly-once
- 只能保证Flink系统内的exactly-once
- 对于source和sink需要依赖外部的组件一同保证
1.15.6.状态容错-生成快照
1.15.7.状态容错–恢复快照
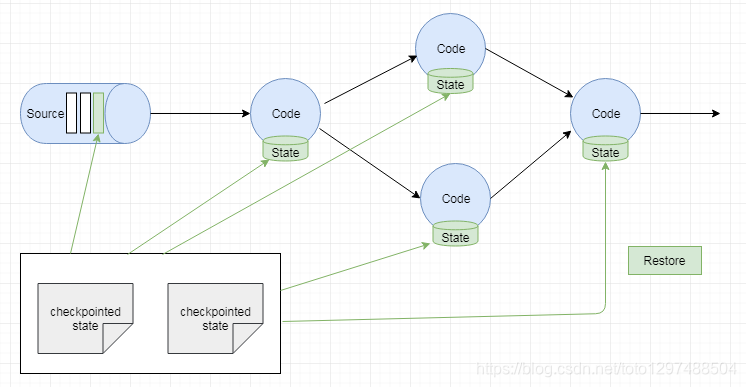
1.15.8.checkPoint简介
Flink容错机制的核心部分是绘制分布式数据流和operator state的一致快照。这些快照充当一致的检查点,如果发生故障,系统可以回退到这些检查点。Flink绘制这些快照的机制在“Lightweight Asynchronous Snapshots for Distributed Dataflows”(https://arxiv.org/abs/1506.08603)中进行了描述。它受用于分布式快照的标准Chandy-Lamport算法的启发, 并且专门针对Flink的执行模型进行了量身定制。
请记住,与检查点有关的所有操作都可以异步完成。检查点barriers 不会在锁定步骤中传播,并且操作可以异步快照其状态。
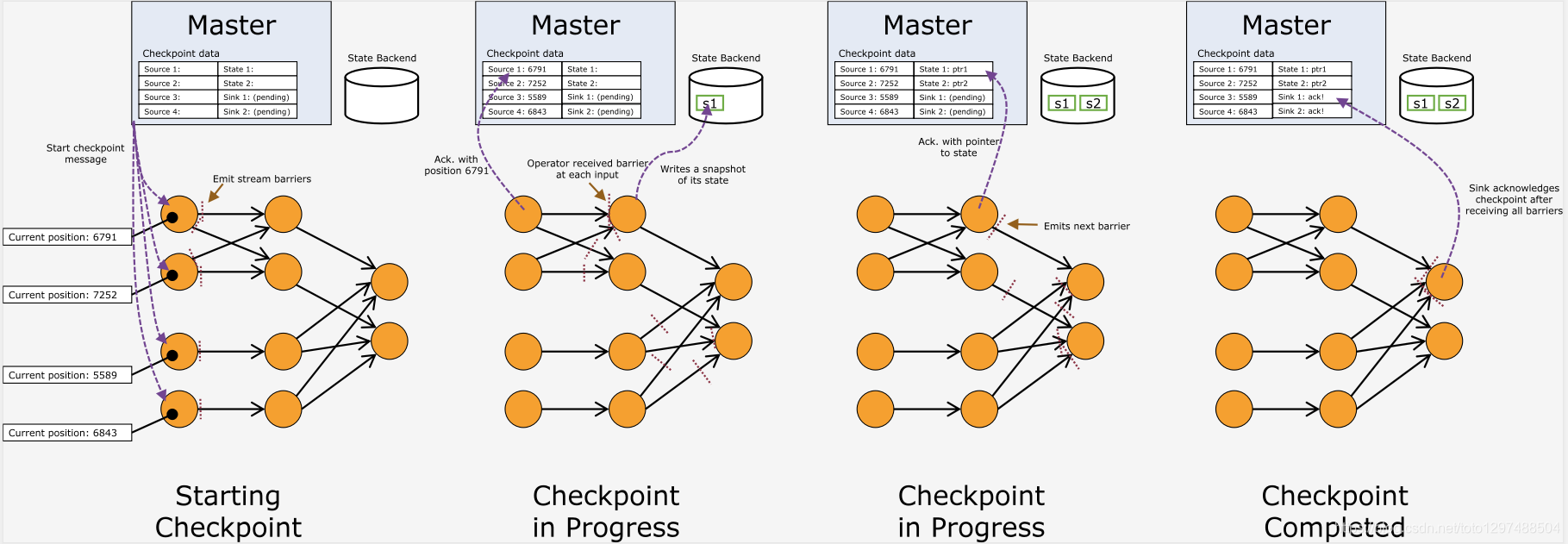
1.15.8.1.Barriers
stream barriers是Flink分布式快照中的核心元素。这些barriers将注入到数据流中,并与记录一起作为数据流的一部分流动。Barriers 从不overtake 记录,它们严格按照顺序进行。barrier将数据流中的记录分为进入当前快照的记录集和进入下一个快照的记录集。每个barrier都带有快照的ID,快照的记录已推送到快照的前面。Barriers不会中断流的流动,因此非常轻便。来自不同快照的多个barriers可以同时出现在流中,这意味着各种快照可能同时发生。
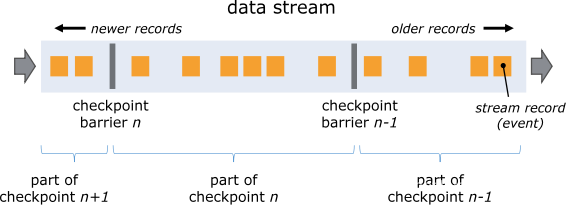
Stream barriers在 stream sources处注入并行数据流中。快照n的barriers 被注入的点(我们称其为 S n)是快照覆盖数据的source stream中的位置。例如,在Apache Kafka中,此位置将是分区中最后一条记录的offset 。该位置S n 被报告给 checkpoint coordinator (Flink的JobManager)。
barriers 然后顺流而下。当中间operator 从其所有输入流中收到快照n的barrier时,它会将快照n的barrier 发射到其所有输出流中。sink operator(streaming dag的末尾)从其所有输入流接收到barrier n之后,便将快照n确认给checkpoint coordinator。所有接收器都确认快照后,就认为快照已完成。
一旦快照n完成,作业将不再向源请求来自Sn之前的记录,因为此时这些记录(及其后代记录)将通过整个数据流拓扑。
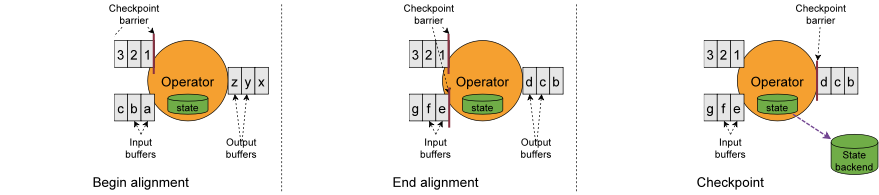
接收到多个输入流的操作员需要在快照barriers上对齐输入流。上图说明了这一点:
operator一旦从传入流接收到快照barrier n,就无法处理该流中的任何其他记录,直到它也从其他输入接收到barrier n为止。否则,它将混合属于快照n的记录和属于快照n + 1的记录。
报告barrier n的流被暂时搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区中。
一旦最后一个流接收到barriers n,operator 将发出所有未决的传出记录,然后自身发出快照n barriers 。
最后,operator 将状态异步写入到state backend。
1.15.8.2.Recovery
这种机制下的恢复非常简单:当出现故障时,Flink选择最新完成的检查点k,然后系统重新部署整个分布式数据流,并给每个operator 状态快照作为检查点k的一部分。sources 被设置为从位置Sk开始读取流。例如,在Apache Kafka中,这意味着告诉consumer开始从offset Sk进行获取数据。
如果state是增量快照,operators 从最新的完整快照的状态开始,然后对该状态应用一系列增量快照更新。
1.15.9.CheckPoint的配置
默认checkpoint功能是disabled的,想要使用的时候需要先启用。
checkpoint开启之后,默认的checkPointMode是Exactly-once
checkpoint的checkPointMode有两种,Exactly-once和At-least-once
Exactly-once对于大多数应用来说是最合适的。At-least-once可能用在某些延迟超低的应用程序(始终延迟为几毫秒)
默认checkpoint功能是disabled的,想要使用的时候需要先启用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
1.15.10.状态的持久性
Flink通过结合流重播(stream replay)和 检查点(checkpointing)来实现容错。检查点标记每个输入流中的特定点以及每个operators的对应状态。通过恢复operators 的状态并从检查点开始重播记录,可以在保持一致性(一次处理语义)的同时从检查点恢复流式数据流。
检查点间隔(checkpoint interval)是在执行过程中权衡容错开销与恢复时间(需要重播的记录数)的一种手段。
容错机制连续绘制分布式流数据流的快照。对于状态较小的流应用程序,这些快照非常轻量级(light-weight),可以在不影响性能的情况下频繁绘制。流应用程序(streaming applications)的状态通常存储在分布式文件系统中的可配置位置。
如果发生程序故障(由于机器,网络或软件故障),Flink将停止分布式流数据流。然后,系统重新启动operators ,并将其重置为最新的成功检查点。输入流将重置为状态快照的点。确保作为重新启动的并行数据流的一部分处理的任何记录都不会影响以前的检查点状态。
**[注意]**默认情况下,检查点是禁用的。有关如何启用和配置检查点的详细信息,请参见检查点。
**[注意]**为了使该机制实现其全部保证,数据流源(例如消息队列或代理)必须能够将流后退到定义的最近点。Apache Kafka具有此功能,Flink与Kafka的连接器利用了这一功能。有关Flink连接器提供的保证的更多信息,请参见数据源和接收器的容错保证。
**[注意]**由于Flink的检查点是通过分布式快照实现的,因此我们可以交替使用快照和检查点一词。通常,我们也使用快照一词来表示检查点或保存点。
1.15.11.State Backend(状态的后端存储)
存储键/值索引的确切数据结构取决于所选择的state backend。一个state backend存储数据在内存中的hash map,another state backend使用RocksDB作为键/值存储。除了定义保存状态的数据结构外,state backends还实现了获取键/值状态的时间点快照并将该快照存储为检查点的一部分的逻辑。可以在不更改应用程序逻辑的情况下配置State backends。
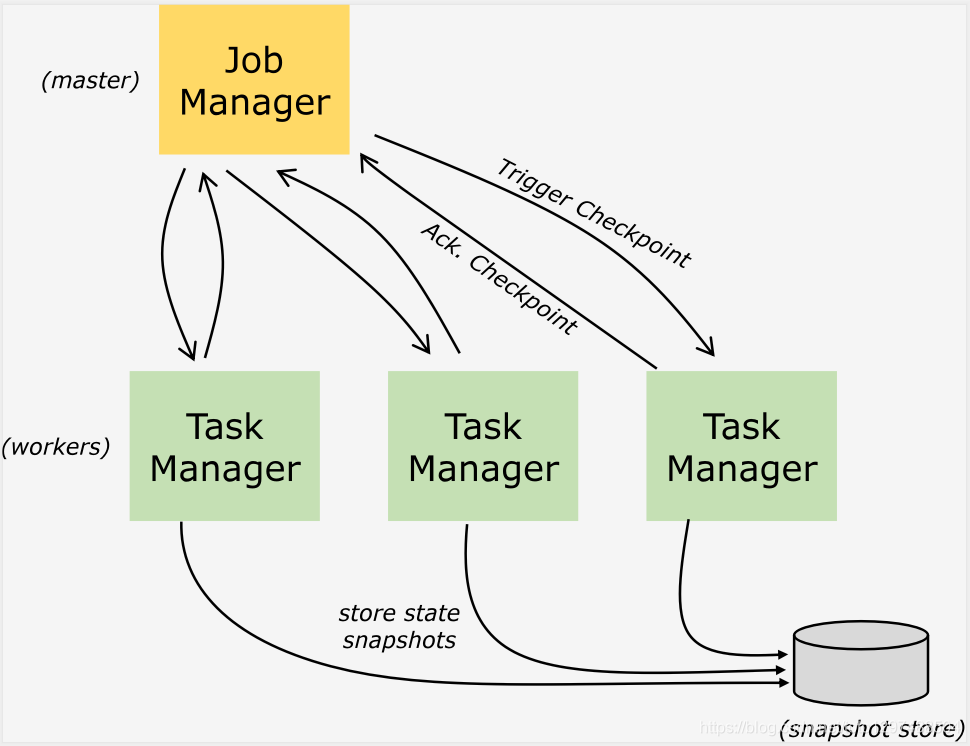
默认情况下,state会保存在taskmanager的内存中,checkpoint会存储在JobManager的内存中。
state 的store和checkpoint的位置取决于State Backend的配置。
env.setStateBackend(…)
一共有三种State Backend
MemoryStateBackend
- state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中。
- 基于内存的state backend在生产环境下不建议使用
FsStateBackend
- state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中。
- 可以使用hdfs等分布式文件系统。
RocksDBStateBackend (RocksDB是一个为更快速存储而生的,可嵌入的持久型的key-value存储)
- RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。
- RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
1.15.11.1.修改State Backend的两种方式
第一种:单任务调整
- 修改当前任务代码
- env.setStateBackend(new FsStateBackend(“hdfs://namenode:9000/flink/checkpointsk”))
- 或者new MemoryStateBackend()
- 或者new RocksDBStateBackend(filebackend,true);需要添加第三方依赖
第二种:全局调整 - 修改flink-conf.yaml
- state.backend: filesystem
- state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
- 注意:state.backend的值可以是下面几种:jobmanager(MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
注意:
如果想使用RocksDBStateBackend使用,需要引入以下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.6.1</version>
</dependency>
1.15.12.Restart Strategies(重启策略)
Flink支持不同的重启策略,以在故障发生时控制作业如何重启
集群在启动时会伴随一个默认的重启策略,在没有定义具体重启策略时会使用该默认策略。如果在工作提交时指定了一个重启策略,该策略会覆盖集群的默认策略。
常用的重启策略
- 固定间隔 (Fixed delay)
- 失败率 (Failure rate)
- 无重启 (No restart)
如果没有启用 checkpointing,则使用无重启 (no restart) 策略。
如果启用了 checkpointing,但没有配置重启策略,则使用固定间隔 (fixed-delay) 策略,其中 Integer.MAX_VALUE 参数是尝试重启次数。
重启策略可以在flink-conf.yaml中配置,表示全局的配置。也可以在应用代码中动态指定,会覆盖全局配置。
1.15.12.1.重启策略值固定间隔(Fixed delay)
第一种:全局配置flink-conf.yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
第二种:应用代码设置
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 间隔
));
1.15.12.2.重启策略之失败率(Failure rate)
第一种:全局配置 flink-conf.yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
第二种:应用代码设置
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 一个时间段内的最大失败次数
Time.of(5, TimeUnit.MINUTES), // 衡量失败次数的是时间段
Time.of(10, TimeUnit.SECONDS) // 间隔
));
1.15.12.3.重启策略之无重启 (No restart)
第一种:全局配置 flink-conf.yaml
restart-strategy: none
第二种:应用代码设置
env.setRestartStrategy(RestartStrategies.noRestart());
1.15.12.4.保存多个Checkpoint
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前。
Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数。
- state.checkpoints.num-retained: 20
这样设置以后就查看对应的Checkpoint在HDFS上存储的文件目录
- hdfs dfs -ls hdfs://namenode:9000/flink/checkpoints
- 如果希望回退到某个Checkpoints点,只需要指定对应的某个Checkpoint路径即可实现。
1.15.12.5.从Checkpoint进行恢复
如果Flink程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个Checkpoint点进行恢复
bin/flink run -s hdfs://namenode:9000/flink/checkpoints/467e17d2cc343e6c56255d222bae3421/chk-56/_metadata flink-job.jar
程序正常运行后,还会按照Checkpoint配置进行运行,继续生成Checkpoint数据。
1.15.12.6.savePoint
所有使用检查点的程序都可以从保存点恢复执行。保存点允许在不丢失任何状态的情况下更新程序和Flink集群。保存点是手动触发的检查点,以程序的快照,写出来state backend。它们依赖于常规的检查点机制。
保存点与检查点类似,除了它们是由用户触发的,并且不会在完成新的检查点时自动过期。
Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断。
全局,一致性快照。可以保存数据源offset,operator操作状态等信息。
可以从应用在过去任意做了savepoint的时刻开始继续消费。
1.15.12.7.checkPoint vs savePoint
checkpoint
- 应用定时触发,用于保存状态,会过期
- 内部应用失败重启的时候使用
savePoint
用户手动执行,是指向Checkpoint的指针,不会过期
在升级的情况下使用
注意:为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐程序员通过 uid(String) 方法手动的给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变就能从保存点(savepoint)将程序恢复回来。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动的设置 ID。
1.15.12.8.savePoint的使用
1:在flink-conf.yaml中配置Savepoint存储位置
- 不是必须设置,但是设置后,后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置。
- state.savepoints.dir: hdfs://namenode:9000/flink/savepoints
2:触发一个savepoint【直接触发或者在cancel的时候触发】 - bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
- bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
从指定的savepoint启动job - bin/flink run -s savepointPath [runArgs]















 5636
5636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











